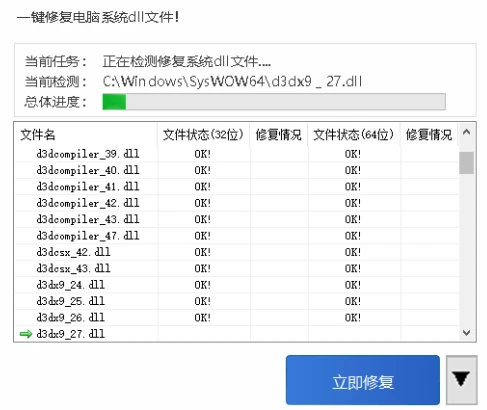
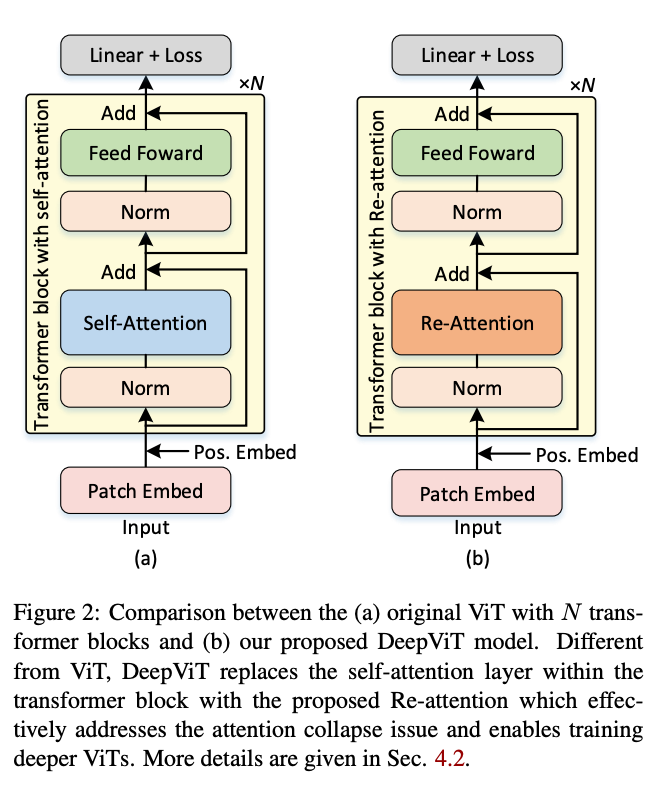
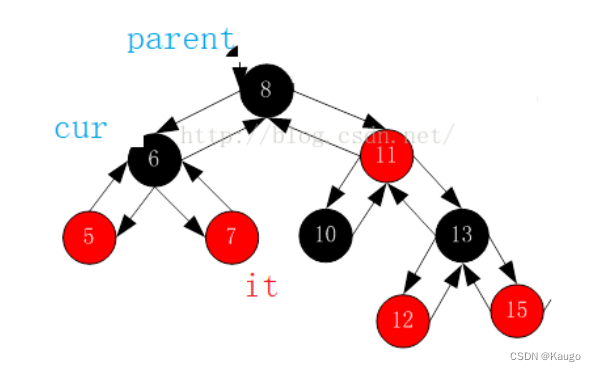
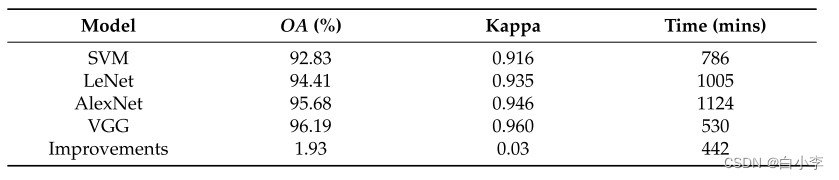
文章目录
- 概述
- 图解
- Use Case

概述
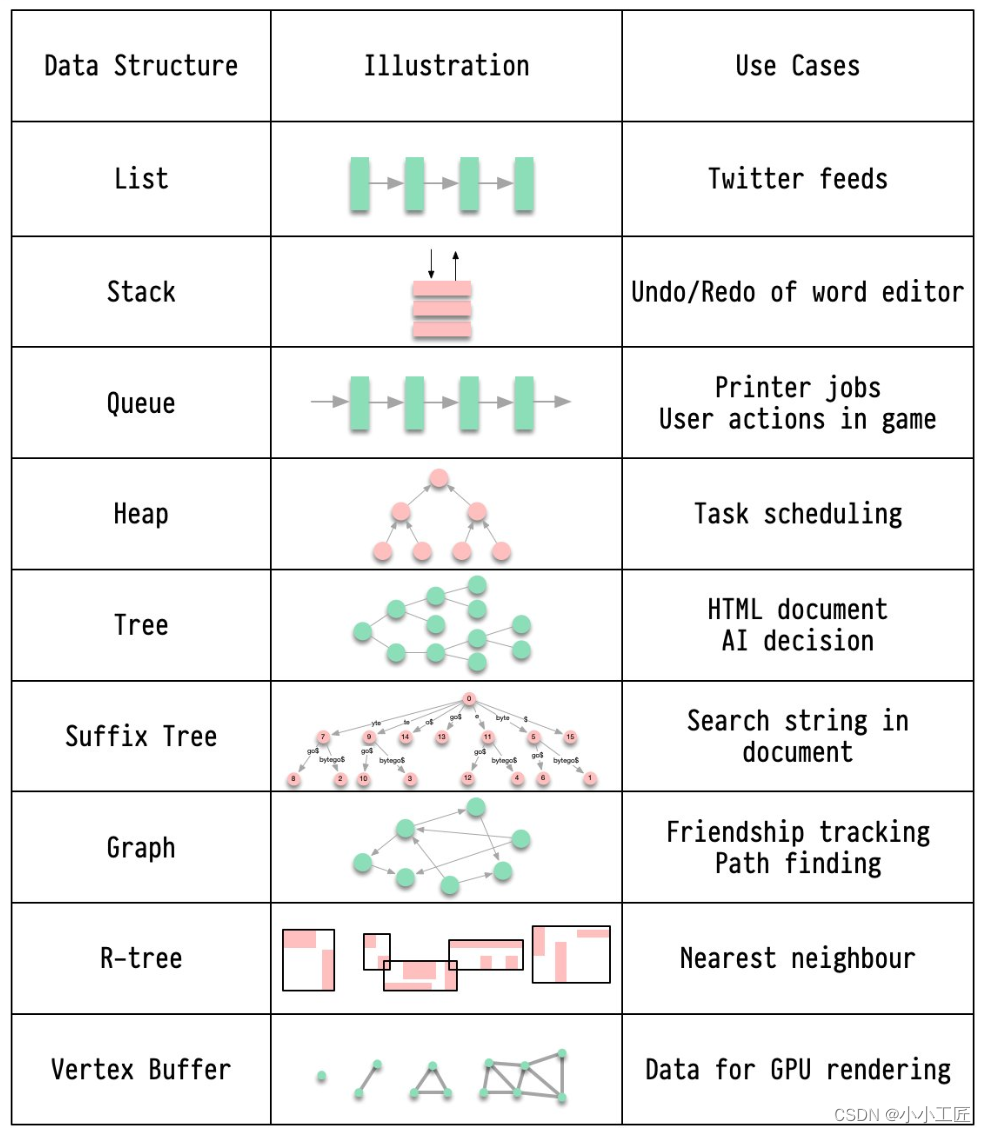
🔹 链表(List):用于保存Twitter的信息流。
🔹 栈(Stack):支持文字编辑器的撤销/重做功能。
🔹 队列(Queue):用于保存打印作业,或者在游戏中发送用户操作。
🔹 堆(Heap):用于任务调度。
🔹 树(Tree):用于保存HTML文档,或者用于人工智能决策。
🔹 后缀树(Suffix Tree):用于在文档中搜索字符串。
🔹 图(Graph):用于跟踪社交关系,或者进行路径搜索。
🔹 R树(R-Tree):用于寻找最近的邻居。
🔹 顶点缓冲区(Vertex Buffer):用于向GPU发送渲染数据。
总之,数据结构在我们的日常生活中扮演着重要角色,无论是在技术领域还是在我们的体验中。工程师们应该了解这些数据结构及其用途,以创建有效和高效的解决方案。
此外,还有一些未提及的数据结构,包括但不限于:
🔹 链表(Linked List):用于动态存储和操作数据的线性数据结构。
🔹 散列表(Hash Table):用于高效地查找和存储键-值对的数据结构。
🔹 树状数组(Binary Indexed Tree / Fenwick Tree):用于高效处理前缀和范围查询的数据结构。
🔹 哈夫曼树(Huffman Tree):用于数据压缩和解压缩。
🔹 队列(Priority Queue):用于按照优先级处理元素的数据结构。
🔹 位图(Bitmap):用于高效地表示和操作大量布尔值的数据结构。
🔹 链表树(Skip List):一种用于高效搜索和插入的数据结构,类似于平衡树。
🔹 哈希图(Hash Map):一种用于高效存储和检索键-值对的数据结构,类似于散列表但更灵活。
这些是一些常见的数据结构,它们在不同的应用中具有各自的优势和用途。
图解
Use Case
当谈到不同的数据结构时,让我们分别介绍每种数据结构以及它们在真实案例中的使用场景:
-
链表(Linked List):
- 描述:链表是一种线性数据结构,由节点组成,每个节点包含数据元素和指向下一个节点的指针。
- 使用场景:常用于实现动态数据结构,例如内存分配、嵌套数据结构等。在操作系统中,进程控制块(PCB)的链接列表用于管理进程。
-
散列表(Hash Table):
- 描述:散列表是一种数据结构,用于高效存储和检索键-值对。它使用散列函数将键映射到存储位置。
- 使用场景:常用于实现哈希映射,用于快速查找、缓存和字典。例如,数据库索引、缓存系统(如Memcached、Redis)以及编程语言中的字典数据结构都使用散列表。
-
树状数组(Binary Indexed Tree / Fenwick Tree):
- 描述:树状数组是一种用于高效处理前缀和和范围查询的数据结构,通常用于数值计算问题。
- 使用场景:常用于处理累积和问题,如统计数组中某一范围内的元素和。在编程竞赛和算法竞赛中,树状数组用于解决一类重要的计算问题。
-
哈夫曼树(Huffman Tree):
- 描述:哈夫曼树是一种用于数据压缩和解压缩的树形数据结构,通常用于构建变长编码。
- 使用场景:广泛用于数据压缩算法,如gzip、zip等。它能够有效地压缩数据,减小存储和传输成本。
-
队列(Priority Queue):
- 描述:队列是一种线性数据结构,可以按照元素的优先级进行操作,通常使用堆来实现。
- 使用场景:常用于任务调度、最小值/最大值查询等需要优先级处理的场景。例如,操作系统中的进程调度、Dijkstra算法中的节点选取。
-
位图(Bitmap):
- 描述:位图是一种紧凑的数据结构,用于高效地表示和操作大量布尔值。
- 使用场景:常用于数据库索引、网络路由表、图像处理和压缩算法等领域。在数据库中,位图索引可用于快速过滤数据。
-
链表树(Skip List):
- 描述:链表树是一种用于高效搜索和插入的数据结构,类似于平衡树,但更简单。
- 使用场景:常用于数据库索引、有序集合的实现(如跳表集合)、分布式系统中的数据存储。
-
哈希图(Hash Map):
- 描述:哈希图是一种用于高效存储和检索键-值对的数据结构,类似于散列表。
- 使用场景:通常用于内存中数据存储、数据库索引、缓存等。编程语言中的字典数据结构(如Python的字典)也是基于哈希图实现的。
这些数据结构在不同领域和应用中发挥着重要作用,帮助工程师解决各种问题,提高效率和性能。选择正确的数据结构对于设计和优化软件系统至关重要。






![VCP-DCV VMware vSphere:安装、配置和管理[V8.x]](https://img-blog.csdnimg.cn/d411ff8169bc4e6883a328b07f076f47.png)