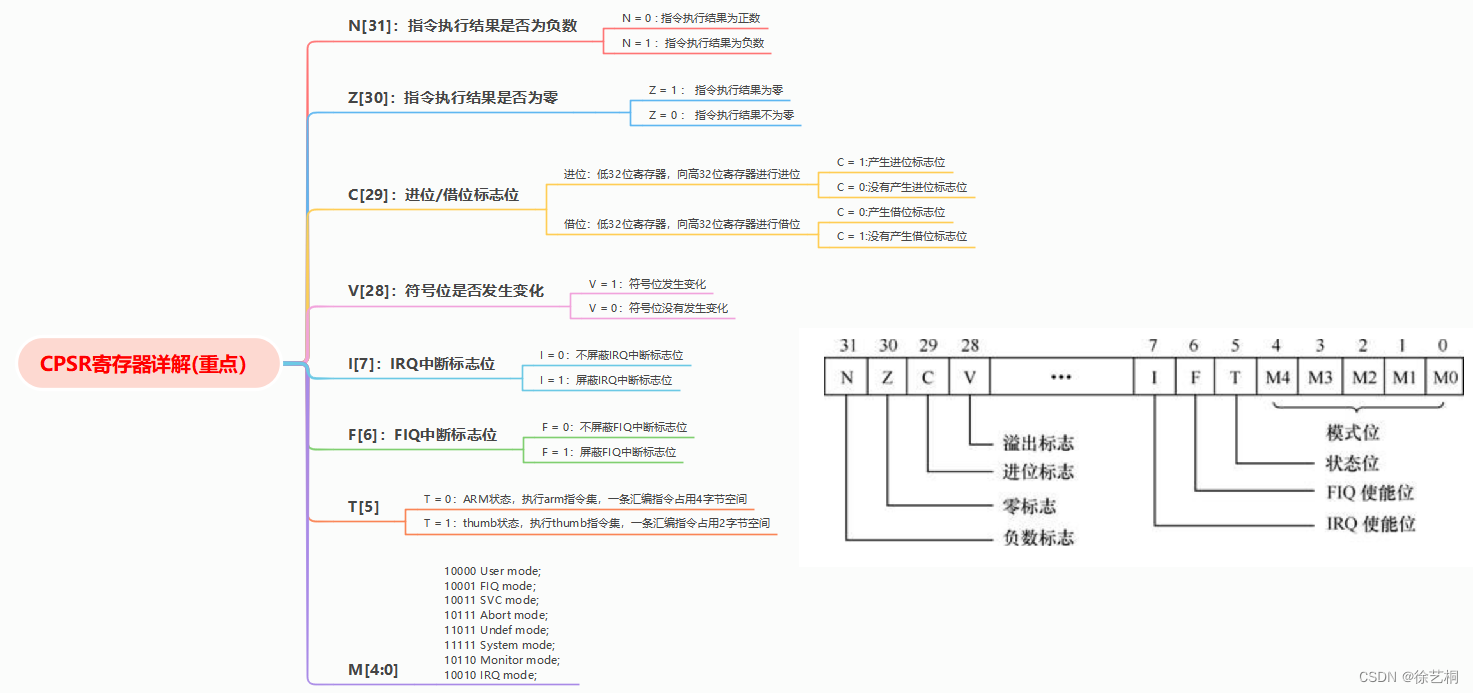
大数据的特征可以浓缩为五个英文单词,Volume(大量)、Variety(多样性)、Velocity(速度)、Value(价值)、Veracity(准确性)。因为是5个特征都是以“V”开头的英文单词,又叫大数据5V特征。
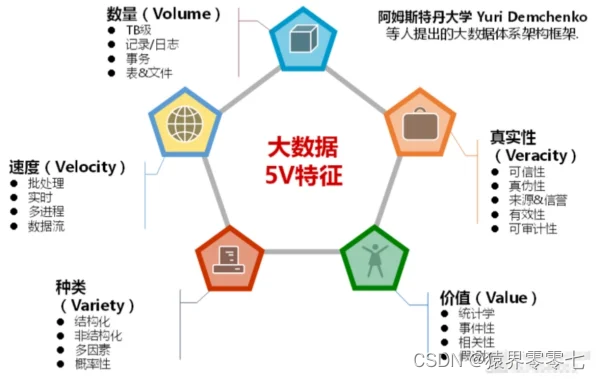
概述:
1、Volume(大量)
即可从数百TB到数十数百PB、甚至EB的规模
2、Variety(多样性)
即大数据包括各种格式和形态的数据
3、Velocity(速度)
数据增长速度快,处理速度也快,获取数据的速度也要快
4、Value(价值)
数据价值密度低,但是商业价值高
5、Veracity(准确性)
即处理的结果要保证一定的准确性
详细描述:
1、Volume
中文翻译是“大量”的意思,顾名思义,就是数据量非常的庞大。而这也是大数据的字面含义。我们知道在表示数据大小的时候,生活中常见的计量单位有KB、MB、GB、TB等,但是在此之上还有其他的单位,例如: PB、EB、ZB、YB、BB、NB、DB等。这些单位之间的换算率都是1024,也正是因此,人们会把每年的10月24日定为程序员节。我们每一个人在互联网上进行各种各样的行为,都会留下数据,而这些数据量虽然不算大,但是在庞大的用户基数下,累计起来的还是非常庞大的。在一个中大型企业中,需要处理的数据规模是很容易达到PB、EB的级别的,而这也正是大数据的第一个特征: 大量。
2、Variety
中文翻译是“多样化”的意思。我们知道学习大数据就是来处理庞大的数据集的,那么组成这个庞大的数据集的数据是可以分为不同的类型的。我们把这些数据大致分为三类:结构化的数据、半结构化的数据和非结构化的数据。
结构化的数据,一般指的是关系型数据库中的数据,例如MySQL、Oracle中的表中的数据。这些数据中,每一行的数据都保持着相同的数据格式,有规律可循,非常容易处理。
半结构化的数据,指的是有一定的结构性,但是比起关系型数据库表中的结构化的数据来说,结构不是那么清晰,处理起来也比结构化的数据略微麻烦。常见的半结构化的数据有json、xml、html等。
非结构化的数据,指的就是没有丝毫结构性可言的数据了。数据没有固定的格式,通常需要我们单独设计程序来处理这些数据,从中提取出来有价值的信息。
而我们在工作中要处理的数据,往往都是以半结构化和非结构化的居多。
3、Value
中文翻译是“价值”的意思。这里其实有两点体现:价值密度低、商业价值高。
大数据相关的技术体系,需要处理的数据量是非常庞大的,动辄PB、EB规模的数据,但是真正具有价值的数据却非常稀少,只有100M,甚至更少。我们就需要从这么庞大的数据集中提取出来这些密度非常低的有价值的数据进行处理。
但是,也就是这些密度非常低的数据,能够发挥出来巨大的商业价值。这点其实也是来推动大数据发展的重要的特征之一,因为这些大数据相关的技术体系可以给商人带来巨大的利益,老板才愿意培养人来从事这个行业;越来越多的人涌入到这个行业,才能够推动这门技术不断的向前发展。
4、Velocity
中文翻译是“速度”的意思。我们要处理的数据集在很多情况下,并不是一潭死水,而是在不断增长的。对于一个企业来说,每天都会新增庞大的数据,这些数据可能来自于用户的操作、可能来自于智能家居、可能来自于各种传感器等,数据的来源非常多,而且数据量的增速也是非常可怕的。以淘宝、京东这类的电商来说,每日新增的数据量达到几百个GB是很正常的事情。在这样快速的数据增长的情况下,也对我们处理数据的速度有了较高的要求了。我们一定要优化我们的业务逻辑,提高处理的速度,才不会造成数据积压。
5、Veracity
中文翻译是“真实性”的意思。大规模的数据量,在处理的时候,对技术体系是有较高的要求的。在还没有形成现有的技术体系的年代,人们在处理庞大的数据集的时候,往往束手无策,要么实效性非常差,要么干脆无法处理。那个时代甚至流行一种做法:随机抽样。随机的从庞大的数据集中抽取一部分出来进行处理,以这样的处理结果,作为整个数据集的处理结果。追求真实性的,可能会多随机几次。但是这个结果其实是不准确的,并不能够体现出这些数据完整的价值,甚至还可能得到错误的结论。但是现在大数据的技术体系相对成熟,我们不再使用这样的随机抽样的方式了。我们就是要对所有的数据进行高效的处理,得出的结论自然也是正确的。
大数据的5V特征是Volume、Velocity、Variety、Veracity和Value,这些特征描述了大数据的规模、速度、多样性、真实性和价值,对于理解和应用大数据具有重要意义。