Part10-Sorting and Aggregations
Part10-Sorting & Aggregations
Query Plan
查询计划指的是指令或者是数据库系统如何执行一个给定查询的方式。整个查询计划是树形结构或者有向无环图。
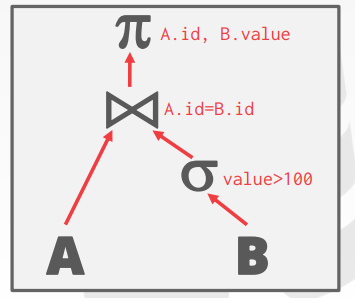
Logical Plan:先SCAN A,交给join operator,SCAN B,对B进行filter后交给join operator,然后join oper把结果传给projection operator。 使用buffer pool manager来对查询的中间结果进行落盘操作。
External Merge Sort
外部归并排序
bulk loading in B+ Tree:加载大量数据。沿着叶子节点对所有数据进行预排序,然后自下而上构建索引而不是自上而下。
#1 Sorting 将尽可能多的数据块放入内存并对他们进行排序,排完序的结果写回磁盘。#2 Merging 将这些runs合并成更大的runs
2-Way External Merge Sort
两路归并外部排序。
假设数据分成了N个页面,buffer Pool有B个pages。
working Memory:对于一个特定查询来说 working memory就是在进行中间操作的时候被允许使用的内存量。
Pass #0:每次读B个Pages到内存中排完序写入Disk中。
Pass #1,2,3,… 然后两两合并,这样需要至少三个buffer pages,两个输入page 一个输出page。Number of passes = 1+ log_2N IO cost = 2N * passes
Double Buffering Optimization
双缓冲区优化,通过prefetch 预取来最小化I/O成本,当对其他两个page进行合并的时候,可以使用shadow page/buffer来接收下一个run/page
General External Merge Sort
Pass #0: B个buffer pages,产生[N/B]个sorted run, 每个run的大小是B。
Pass #1,2,3 合并B-1轮
不太懂。
第一轮做就地排序,每个page内自己排序,然后后面需要进行合并排序,所以B-1个输入page,1个输出page。

Using B+ Trees for Sorting
如果要排序的数据有一个B+ Tree index来组织,而且要排序的key和B+ Tree 的Key是一样的,只适用于clustered B+ Tree(聚簇索引)。
clustered 意味着page中tuple的物理位置和索引中定义的顺序相匹配,可以使用B+ Tree的叶子节点来得到排序后的结果,与物理位置相同。
如果是unclustered B+ Tree Index,叶子节点不保存整条tuple数据,只保存索引对应字段数据。所需求数据的顺序和索引数据排列的顺序没关系。
Aggregations
聚合操作,简单来说就是拿到一堆值然后合并在一起生成一个标量值。
sorting做的是大量的循序访问,hashing做的是随机访问。

early filter,也就是早做projection,就可以剥离出不需要的列或者属性。
zone maps; pre-computed materialized aggregation
Alternatives to Sorting
排序的代替方案,排序自身过程代价不低,group by distinct内部也是会进行排序操作。
Hashing 聚合操作的方法是:
使用一个临时的(ephemeral transient)的hash table,把DBMS扫描表的结果插入进去,如果都在内存中的话很好办。
External Hashing Aggregate
Phase #1 - Partition:
- 将tuples拆分放到一个个bucket中,所有具有相同key的tuple都会在同一个分区。
- 如果写满了写到磁盘
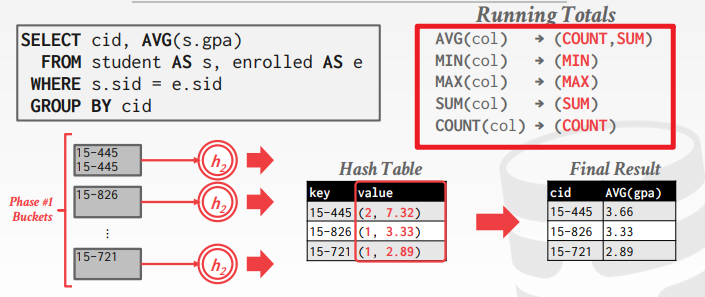
具体的:使用一个hash function h 1 h_1 h1 来进行分桶;
Phase #2 - ReHashing
- 每个分区构建一个内存中的hash table,然后进行aggregation
具体的:将磁盘的每个分区读到内存然后build a hashtable 根据的是第二个hash function h 2 h_2 h2,
这里的partition指的是一个bucket chain,一个chain 可能多个page
h 2 实际 h_2实际 h2实际用来维护聚合函数中的Running_Total?