3D视觉是计算机视觉的终极体现形式
2D视觉技术主要在二维空间下完成工作,三维信息基本上没有得到任何利用,而三维信息才真正能够反映物体和环境的状态,也更接近人类的感知模式。近年来,学术界和工业界推出了一系列优秀的算法和产品,被广泛应用到各个领域。
学术界:CVPR、ECCV、ICCV三大顶会每年和3D视觉相关主题的文章数量保持在十分之一左右,主要关注3D点云的识别与分割、单目图像深度图的生成、3D物体检测、语义SLAM、三维重建、结构光等。
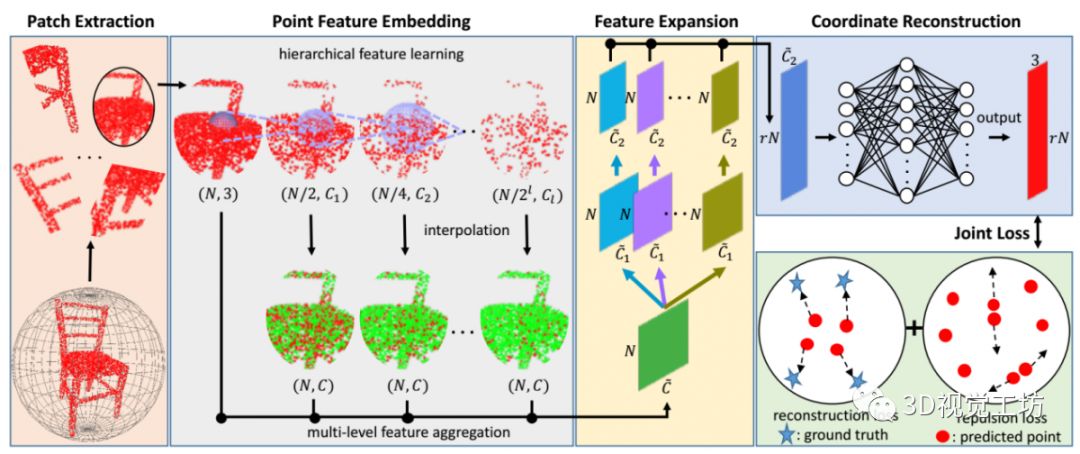

 工业界:3D视觉技术被广泛应用到人脸识别、智能机器人、自动驾驶、AR等领域,国内外相关公司推出了一系列产品。OPPO、华为和苹果等公司推出的3D+AI识别功能,通过扫描人脸三维结构完成手机解锁;自动驾驶领域通过分析3D人脸信息,判断司机驾驶时的情绪状态;SLAM方式通过重建周边环境,完成建图与感知;AR领域通过三维重建技术完成目标的重现。
工业界:3D视觉技术被广泛应用到人脸识别、智能机器人、自动驾驶、AR等领域,国内外相关公司推出了一系列产品。OPPO、华为和苹果等公司推出的3D+AI识别功能,通过扫描人脸三维结构完成手机解锁;自动驾驶领域通过分析3D人脸信息,判断司机驾驶时的情绪状态;SLAM方式通过重建周边环境,完成建图与感知;AR领域通过三维重建技术完成目标的重现。


 3D视觉技术学习的难点?
3D视觉技术学习的难点?
3D视觉是一个范围较广的概念,涉及到硬件选型、离散数学、非线性优化、最优化理论、矩阵论、多视图几何、空间变换、点云处理、计算机视觉、SLAM、深度学习等相关知识点,对初学者来说,几乎没有一个完整明确的学习路线可以参考,入门较为困难,难以深入,许多人走了很多弯路还是没有取得较好结果。然而,有价值的东西一般都很难,如果能够完全掌握,一定会非常有竞争力。
如何更好地入门且系统化学习3D视觉呢?
首先,我们先来看看入门3D视觉需要哪些知识,以及3D视觉的知识体系包含哪些。
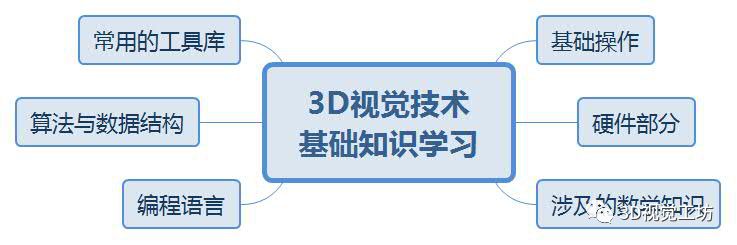
基于3D视觉领域缺少完整的知识路线,我和几个朋友共同完成了3D视觉技术学习路线总结,并以思维导图的形式呈现出来,主要包括0~16个小结,其中每个小结代表特定区域的知识点。学习路线的总结,需要较宽的知识面,由于自身有一定的知识盲区,若有缺漏之处还望指出,后续将会不断更新维护该学习路线~

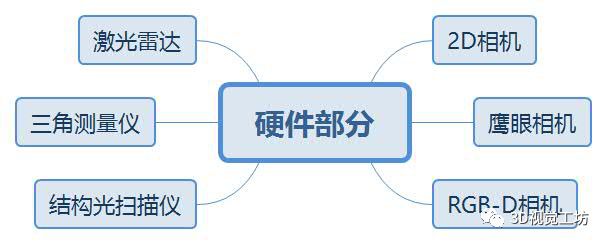

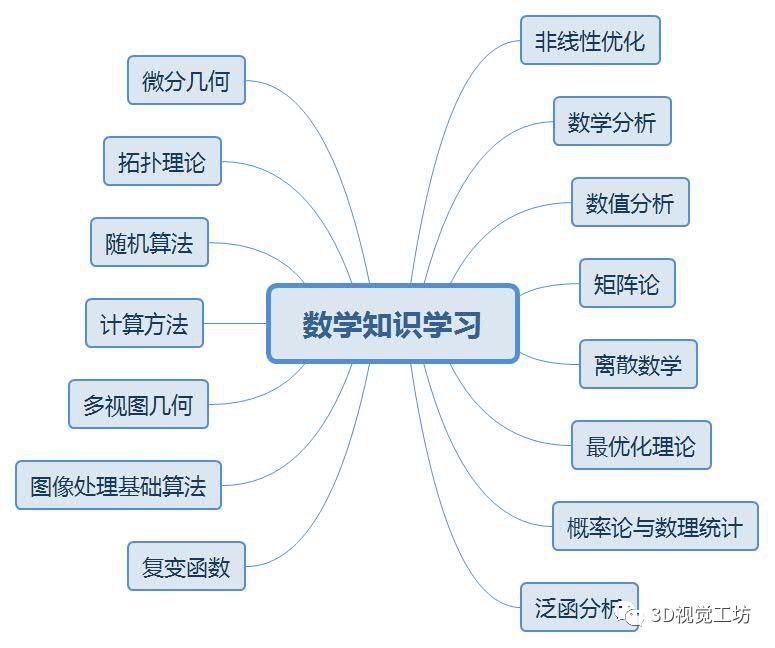
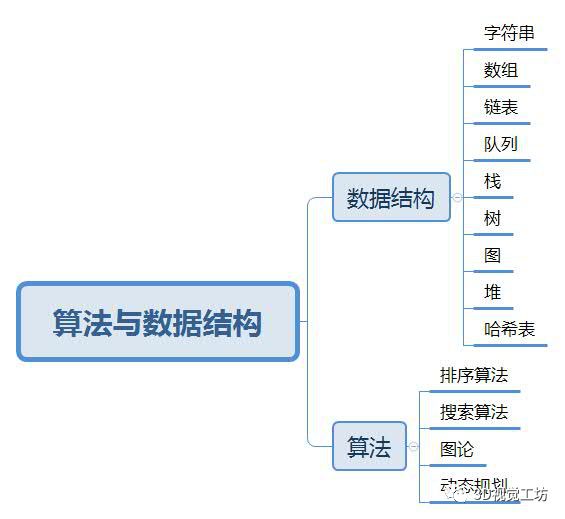
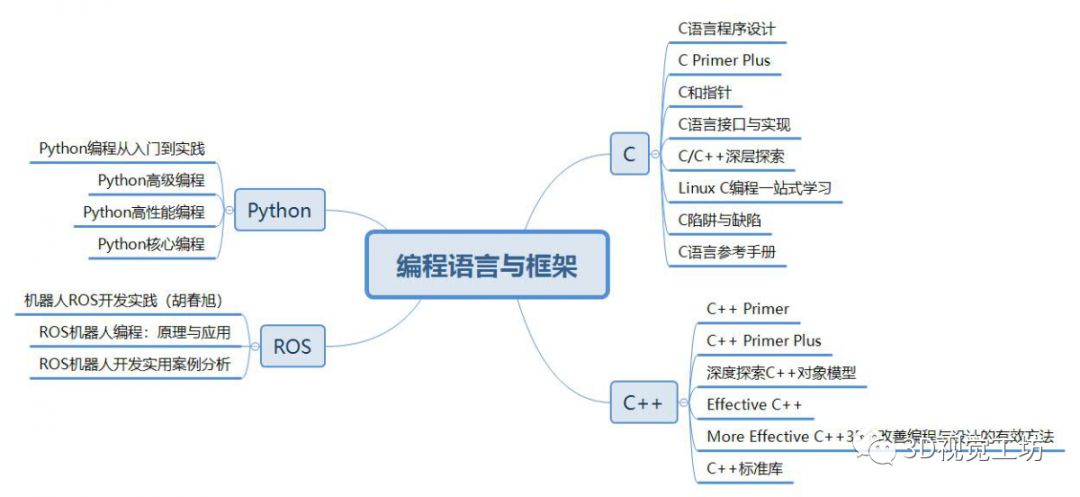
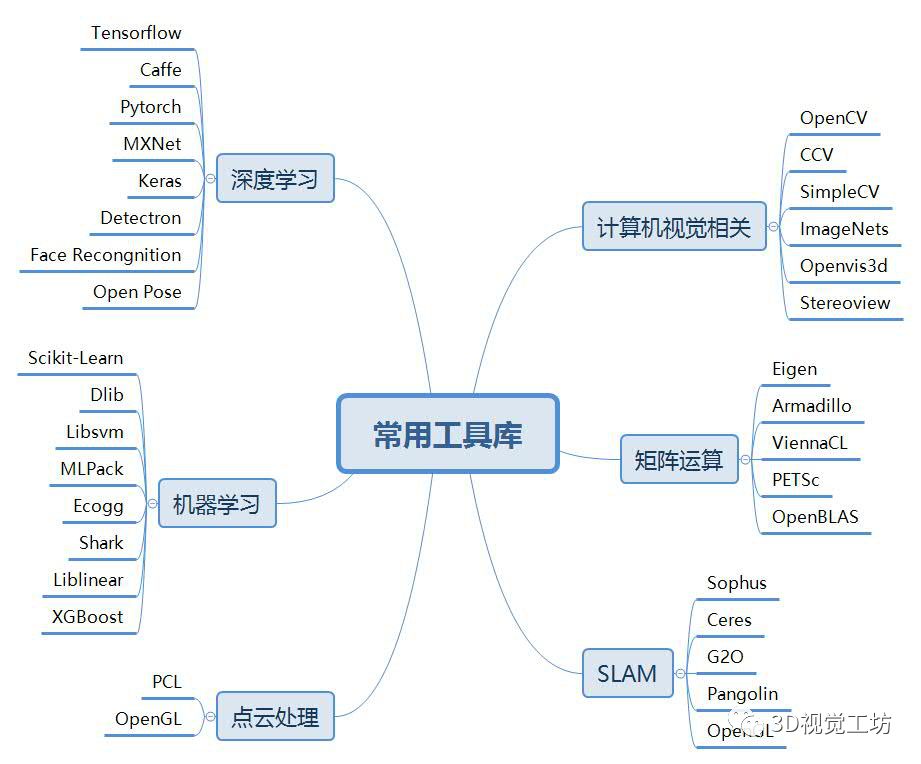

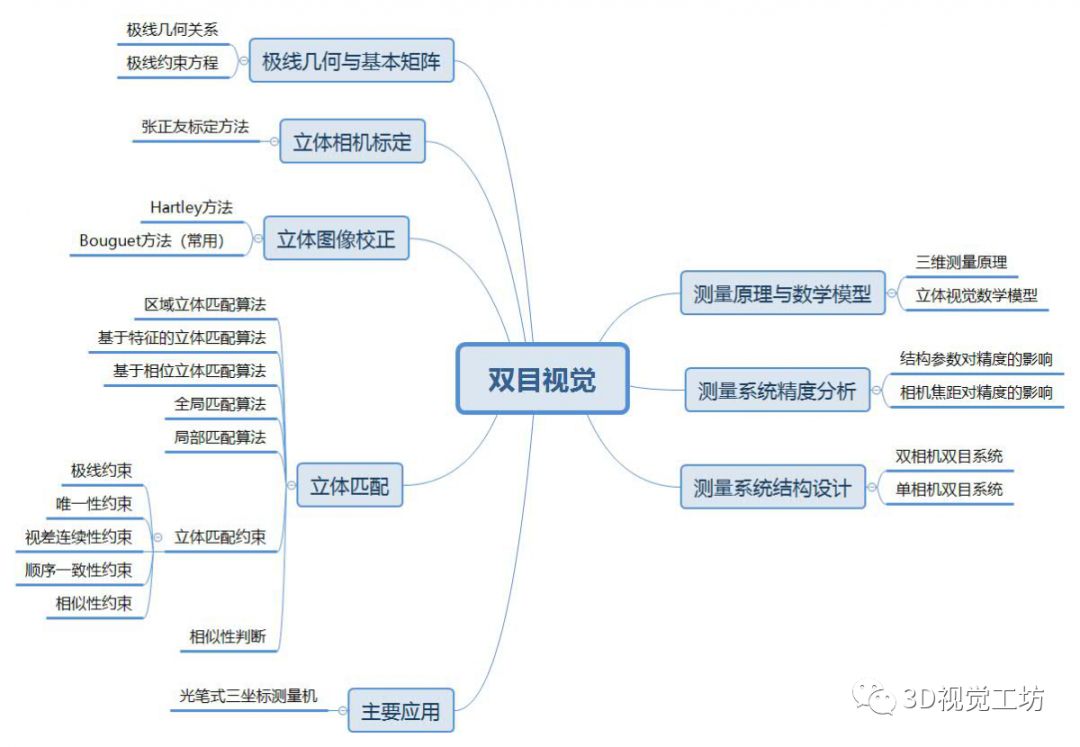


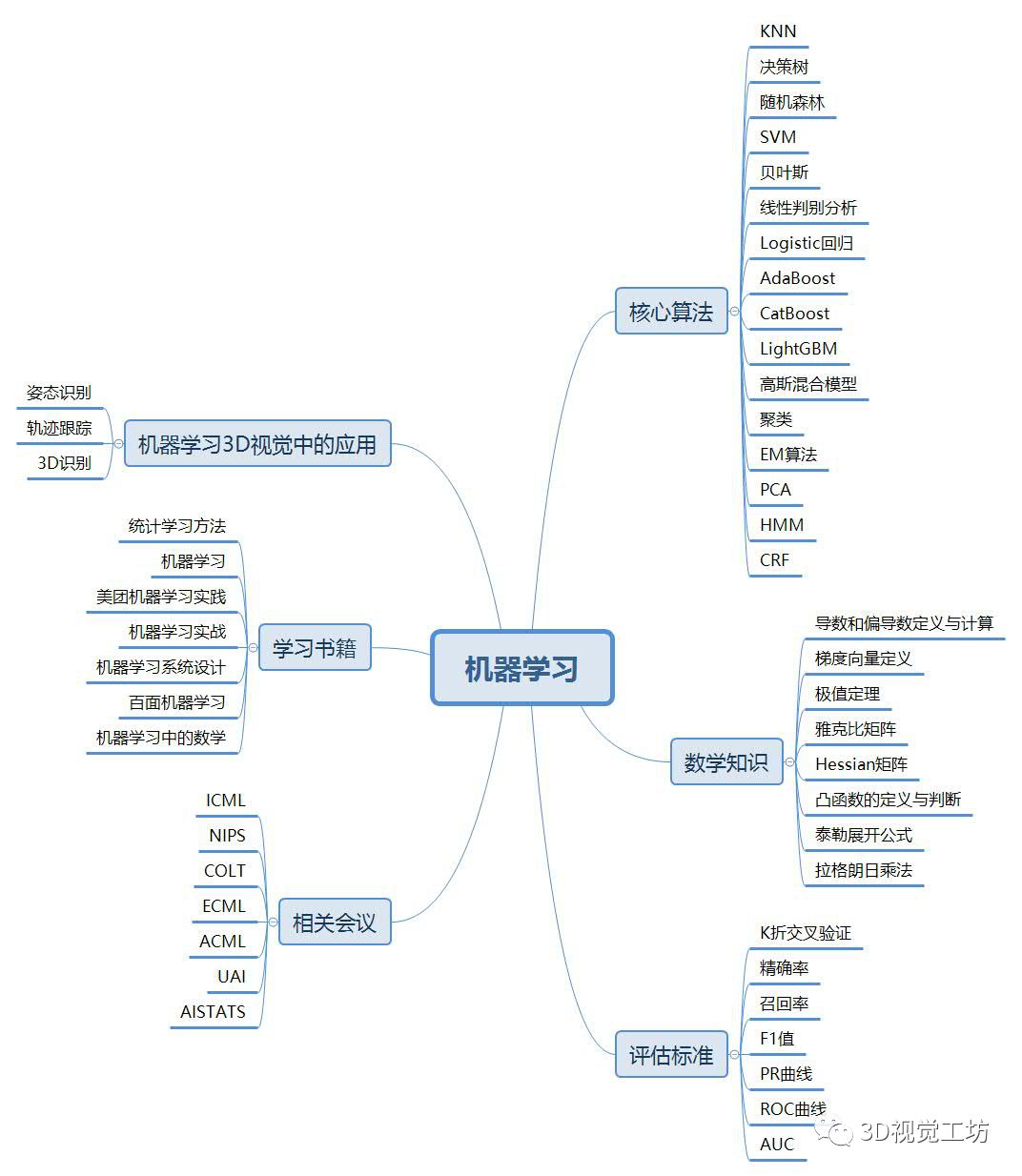


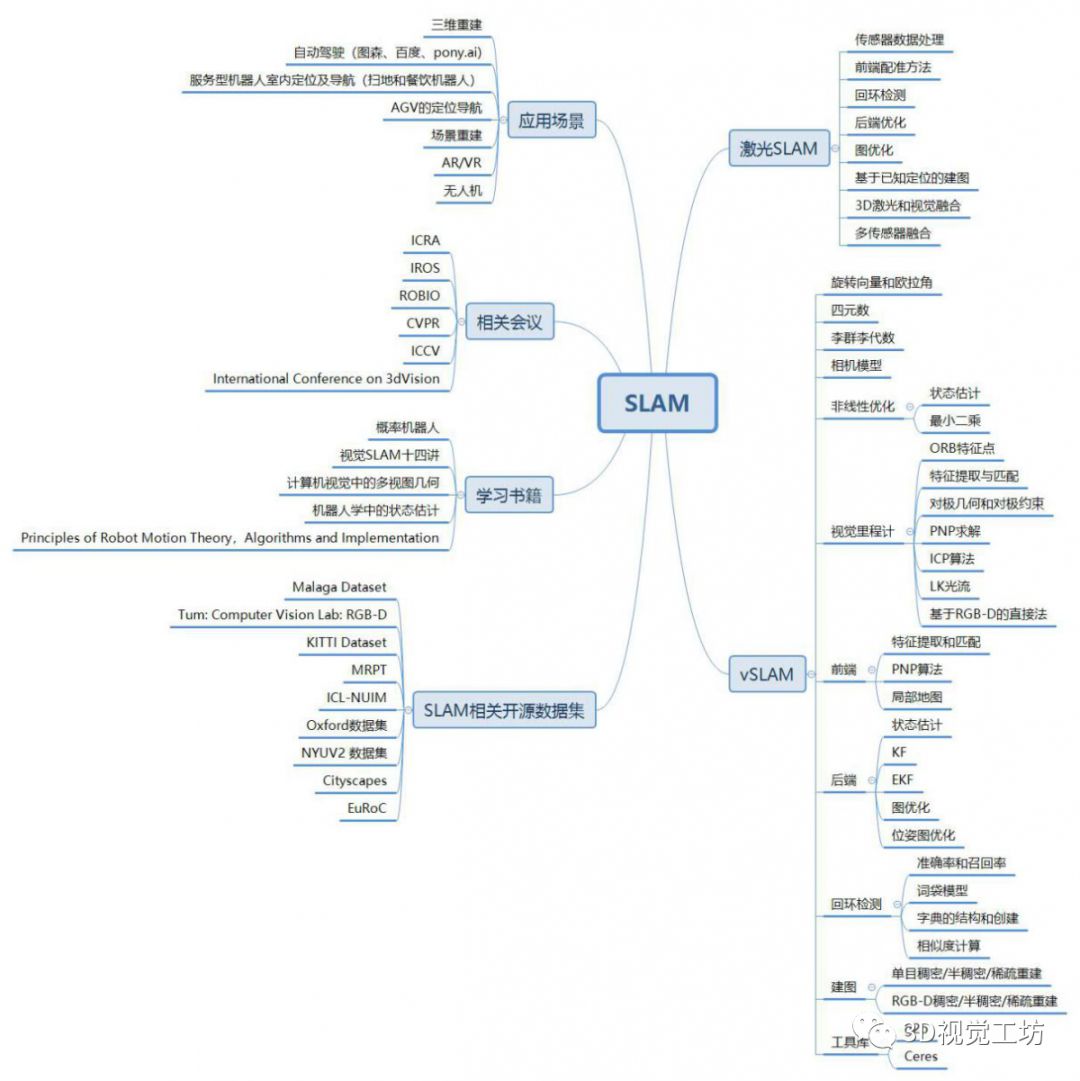
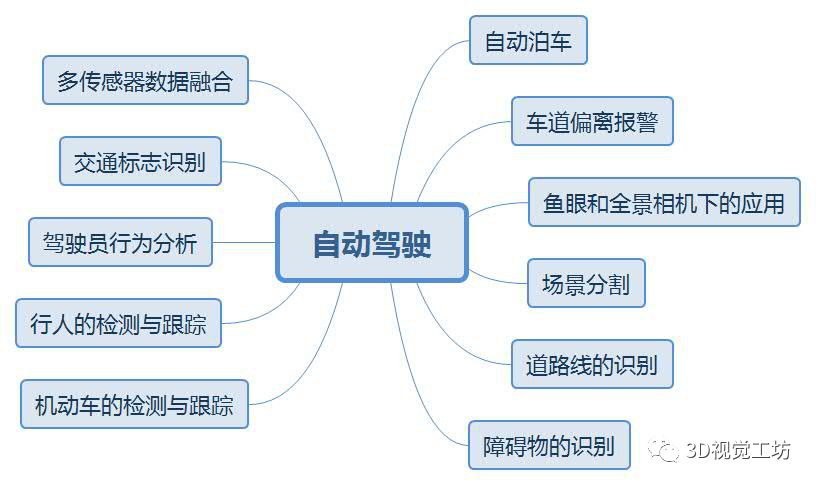
问题集锦
点云处理篇
-
点云补全有哪些常用的算法?
-
常用的点云分割算法有哪些?
-
如何对点云进行线面拟合?有哪些方式?
-
点云配准的常用方法有哪些?哪一种算法在速度和精度上占优势?
-
点云的特征提取方式有哪些?有哪些描述子?
-
基于深度学习的点云分割算法有哪些?精度如何?
-
常用的点云分类算法有哪些?准确率如何?
-
怎么测量点云的体积?如何测量点云拟合平面的面积?
-
您好,请问有有关3D点云的缺陷检测和点云补全的资料吗?
-
想问下有没有三维激光雷达点云配准拼接的代码工程之类的?
-
现在有没有对于sfm或者slam之后得到的点云进行补全处理的工作啊?
-
你好,请问点云表面重建有哪些方法呀?
-
请问怎么把点云投影到一个以点云平均点为圆心的球面上,然后再对球面进行三角网格化。
-
请问一下,有没有关于点云增强方面的综述性质的文章或者帖子呢?针对点云增强这一
-
点云和深度图怎么转换呢?
-
请问如果想要为点云图中某个物体的边界处的稀疏点云进行加密,通俗一点说就是使物体边界处的点云更加稠密,有什么相关的论文和方法吗?
-
点云增强这个领域,除了点云补全,还有哪些具体的方向呢?
……
SLAM
-
请问现在比较新且效果较好的Visual SLAM /Visual+Inertial SLAM 算法有哪些呢?如果能支持双目RGB或RGB-D的更好!
-
请问怎么用单目普通相机的slam来做三维重建呢,对比sfm改做何区别比较好?
-
您好,我想问下视觉惯性vio非线性优化这块,原理不是很懂,想知道他到底做了什么事?
-
大佬好,最近又遇到难题了。项目需求是有轨小车的障碍物检测项目,需要检测小车四周是否有障碍物,并输出障碍物的距离值,距离值精度要求很低。目前的困难是相机视场角太小,怎样才能做到类似全景检测?请大佬给个思路,谢谢您。
-
想请问下有没有无人机三维建模的开源项目?
……
三维重建篇
-
基于图像的三维重建中,由稀疏点云获得稠密点云的原理和实现的技术方式都是什么呢?
-
可以用MATLAB做基于多视角图片的三维重建吗?就是用SFM+MVS。或者,老师有推荐的建模工具吗?
-
使用mvsnet做三维重建,在估计自采数据的深度范围时,有合适的取值范围参考吗?
-
近期,室内三维重建融合语义的开源方案有哪些?
-
老师让我做的课题是用给定视频进行水下的场景重建。但是水下场景颜色比较单一,用colmap进行重建时候数据集中能用在重建的图片较少,导致点云相比实际有误差。那这种情况下要怎么对点云进行矫正和漏洞补全呢?
-
有近景摄影测量相关的公式推导吗?比如前方交会,后方交会,相对定向等?
-
我想请问一下在单目三维重建过程中,对投影仪的标定,一般用什么来评价所用方法对投影仪标定精度的有效性?
……
姿态估计篇
-
目前做物体6D姿态估计的网络中,有没有应用深度补全来提升精度以及提升遮挡下的识别效果的呢?
-
如何自己制作6D位姿估计的深度学习的数据集?
-
请问谁有论文A method for 6D pose estimateof free-form rigid objects using point pair features on range data 的复现代码?
-
请问有人有做过基于RGB-D的目标定位和位姿估计?
-
现有基于RGB、RGBD、点云数据的姿态估计算法都有哪些?
-
深度学习方式的姿态估计算法有哪些?精度怎么样?可以应用到工业上吗?
-
PPF算法的改进点有哪些?有哪些改进算法?
-
机器人视觉引导中的姿态识别思路是什么?计算速度怎么样?
……
结构光篇
-
为什么有的格雷码三维重建的方法需要投射水平和竖直条纹呢,而有的只需要竖直条纹呢?
-
最近研究生导师让我研究一下结构光编码相关的内容,请问您在空间编码和时序编码这两方面,重点是空间编码这边有什么论文或资料推荐嘛?
-
想请问一下在结构光单目三维重建中有没有不标定投影仪而实现标定的,我目前的课题是由一个高速相机和一个投射光栅条纹的激光器组成的系统,传统逆向标定投影仪的方法不能使用,所以希望大佬们给一些标定上的建议。
-
我使用的是格雷码+相移编码光栅,在经过解码得到绝对相位后,怎么计算得到深度图?
-
立体匹配,三维重建后发现类似摩尔纹的情况,请问这种情况怎么处理?
-
请问有关于线结构光传感器标定的综述论文可以推荐吗?
-
目前在做双目结合结构光(格雷码)的三维重建,该怎么把格雷码和双目立体匹配融合呢?
-
您好!想问一下这个结构光检测缺陷时候,图像和激光点云的关系是怎么样的,他和普通的基于图像的检测有什么不同吗?
-
用双目结构光多频外差单视角重建出来的点云有分层现象,是什么原因呢?是深度方向分辨率低吗?
-
刚开始学习双目结构光,不是很清楚应该如何学习,有没有什么书籍视频资料之类的希望能给推荐一下?
……
双目视觉篇
-
一直搞不懂,双目拍得一组的两幅图像,提取特征点、立体匹配、三维重建之后。这一组图片结果与其他组图片结果,用什么方法融合在一起呀?
-
请问有没有什么经典的双目估计深度的文章可以推荐一下?
-
双目视觉,对于遮挡区域的视差估计或者遮挡区域的深度补全,有比较新的论文推荐吗?
-
有没有双目三维目标检测的实战算法?
-
双目视觉三维重建时,想要获得点云是左右视差图都要用到吗?
-
双目视觉的瓶颈在哪里?如何改进?
-
你好,最近看到一些基于深度学习方式的双目重建,速度很快,这种方式有应用价值吗?
-
立体视觉的匹配速度有哪些改进的方式?
……
深度估计篇
-
请问有没有什么经典的双目估计深度的文章可以推荐一下?
-
请问深度估计输出的深度值,是点到相机平面的垂直距离,还是到相机镜头的距离?
-
对于双目深度估计任务端到端,非端到端模式区别在哪里?
-
有哪些自监督方式的单目深度估计算法?
-
请问现在关于单目图像深度估计比较领先的算法和开源工具有哪些?哪些算法在特征点很少的图像中表现比较更好?
-
打算用无监督学习来做深度估计,但是数据集没有真值,这样做出来的结果怎么做定量评估呢?有没有除了真值以外的评价深度估计算法效果的方法呢?
-
我想请问一下,现在基于深度学习的单目视觉估计能够应用在工业实际项目中了?
-
如何解决单目深度估计远距离误差大的问题?
……
3D检测篇
-
我想问一下有哪种比较好落地的3D目标检测算法,最后实现的效果是能获取目标的姿态估计这样的效果
-
基于Lidar点云数据的3D检测算法有哪些?
-
基于双目和单目的3D检测算法有哪些?
-
基于多模态数据融合的3D检测算法有哪些?
-
如何使用Radar和Camera融合数据进行3D检测?
……
自动驾驶与多传感器融合篇
-
Lidar和Camera的标定方式和工具有哪些?
-
Lidar和Radar的标定方式有哪些?
-
多相机标定方式有哪些?
-
Lidar和双目相机标定融合的paper有推荐吗?
-
激光雷达、Camera、毫米波雷达融合怎么做融合?
-
手眼标定方式有哪些?
-
Laser和相机的标定方式?
-
IMU、Camera的融合代码有吗?
……
百篇综述paper
-
双目视觉的匹配算法综述
-
基于立体视觉深度估计的深度学习技术研究(综述)
-
单目图像的深度图估计:综述
-
机器视觉表面缺陷检测综述
-
最新机器人抓取点检测、物体6D姿态估计paper汇总:堆叠场景、遮挡场景、单目图像、深度学习方式等
-
基于视觉的机器人抓取,从目标定位、姿态估计、抓取检测到运动规划类综述
-
超详细的3D Machine Learning教程:涉及数据集集合、三维模型、三维场景、三维姿态估计、单目标分类、多目标检测、场景/对象语义分割、三维几何合成/重建;
-
A Review on Object PoseRecovery: from 3D Bounding Box Detectors to Full 6D Pose Estimators
-
A Survey on Deep Learning forLocalization and Mapping:Towards the Age of Spatial Machine Intelligence
-
A survey of variational andCNN-based optical flow techniques
-
Multisensor data fusion: Areview of the state-of-the-art
-
A Review of Data FusionTechniques
-
Review: deep learning on 3Dpoint clouds
-
3D indoor scene modeling fromRGB-D data:a survey
-
Automatic Target Recognition onSynthetic Aperture Radar Imagery: A Survey
-
Event-based Vision: A Survey
-
Self-Driving Cars: A Survey
-
RGB-D Odometry and SLAM:基于RGB-D的视觉里程计和SLAM综述
-
Image-based 3D Object Reconstruction:State-of-the-Art and Trends in the Deep Learning Era4
-
Deep Learning for Image andPoint Cloud Fusion in Autonomous Driving: A Review
-
A Survey of SimultaneousLocalization and Mapping with an Envision in 6G Wireless Networks
-
Graph-based SLAM: a survey
-
Visual simultaneouslocalization and mapping a survey
-
Topological simultaneouslocalization and mapping a survey
-
Kalman Filter for Robot Vision:A Survey
-
Target-less registration ofpoint clouds: A review【点云无目标配准综述】
-
A Review of Point Cloud SemanticSegmentation#【基于点云的语义分割综述】
……
结构光概念
什么是结构光?
结构光是一组由投影仪和摄像头组成的系统结构。用投影仪投射特定的光信息到物体表面后及背景后,由摄像头采集。根据物体造成的光信号的变化来计算物体的位置和深度等信息,进而复原整个三维空间。
已知空间方向的投影光线的集合称为结构光,而3D结构光的根本就是通过光学手段获取被拍摄物体的三维结构,再通过这一信息进行更深度的应用。
原理:利用图像处理技术和可控光源设备进行测距的技术。基本思想是利用照明光源中的几何信息帮助提取景物中的几何信息。
结构光的分类
主要分为点结构光、线结构光、多线结构光、面结构光、相位法结构光。
1)点结构光:
点结构光法是简单的三角法。点结构光法的接收方向是不可变的。当实现光栅式平面扫描时,光源和探测是同步移动的。单束激光打在物体表面,由摄像机摄取其反射光点。每次只能处理一点,测量速度慢。
2)线结构光:
通过投射源投射出平面狭缝光,每次投射一个结构光条纹,每幅图像可得到一个截面的深度,通过改变投射狭缝光的角度,获得更多截面的深度,进而获得物体的深度。
3)多线结构光法:
以线结构光为基础,为了提高图像处理效率,在一幅图像内处理多条光条纹。
线扫描结构光理解
线扫描结构光较之面阵结构光较为简单,精度也比较高,在工业中广泛用于物体体积测量、三维成像等领域。
-
数学基础
先来看一个简单的二维下的情况:


将之推广至三维空间中:


-
应用

如上图,相机与投影器等相对位姿都经过了精确的校正,并且选取了测量台上的一角作为原点建立物方坐标系。因此,激光投影器所投射的线激光在物方坐标系中可以通过一个平面方程来描述:
而相机光心的位姿通过几何校正也已知,可以通过找到线激光在图像中的对应像素重建出光心与像素的射线,射线和激光平面的交点即为待求的三维空间点。
由小孔成像模型有,代入平面方程中,可得

一、序言
在介绍结构光编码方案之前,先介绍一下目前常见的三维测量方法,从原理上来讲分为以下几类:

大家可以看到,结构光属于主动式光学测量的一类,而常见的光学三维测量可以分为以下三类,右边是它们各自的原理图:

二、结构光分类
接下来进入主题,正式介绍结构光编码方案。结构光三维重建按照所投影的图案一般可以分为以下三类,点结构光、线结构光和面结构光,其中面结构光按照编码原理又可以基于时域编码的结构光和基于空域编码的结构光。
1、点结构光
其光源一般是激光器,测量时将光束投射到被测物表面形成光点,相机拍摄被测物图像,如下图所示,之后通过空间三角关系获得被测物光点照射位置的三维坐标。
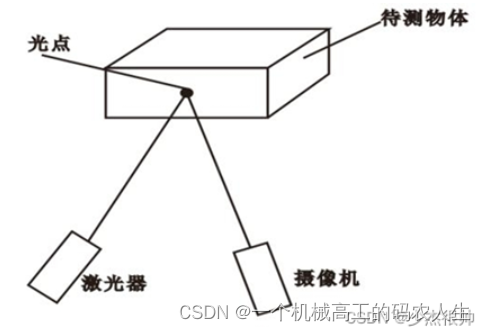
优点:逐点扫描被测物表面,每个点都要采集一张图片,可以获取较高密度的点云,精度最高。
缺点:需要采集大量的图片,导致效率低下。
2、线结构光
线结构光是对点结构光的扩充改进,它将扫描点变成扫描线,测量时激光器发出的光线以一条线的形式扫描被测物表面,之后还是用相机采集扫描的图片,通过空间三角关系获得被测物光点照射位置的三维坐标。
优点:对比点结构光方法,只需进行一维扫描就可获得物体的深度,简化了点结构光的复杂度。
缺点:效率较低。
3、面结构光
面结构光也叫编码结构光,典型的硬件组成由投影仪—相机对表示,如下图所示。投影仪将编码图案投射到被测物表面,然后由相机进行同步采集。其基本原理是投射的编码图案经过被测物表面调制,此时物体表面的高低信息便储存在了调制后的编码图案中,然后用相机从一个或多个角度采集这些变形的图案,找到相机和投影仪像素之间的对应点,利用三角法原理求出被测物表面的三维坐标。
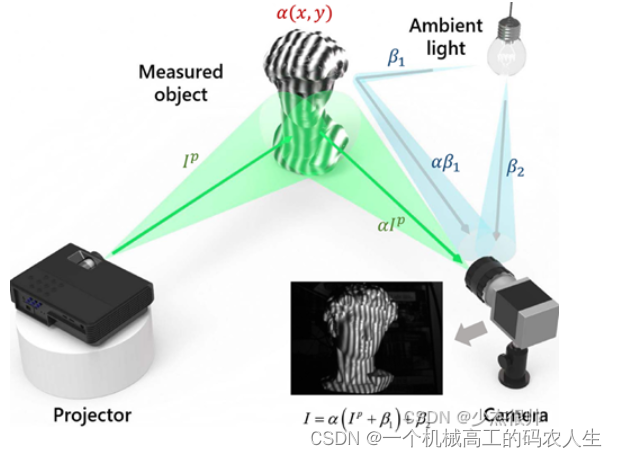
按照不同的编码方法,面结构光可以分为多类:
A、时域编码
时域编码是一种常用的编码策略,该方法将一系列的简单图案按时间先后顺序投影到被测物表面,一个给定像素的编码就是该位置在时间上随投影图案的明暗变化。
优点:这种编码方案在三维测量上有很高的测量精度,且易于在工程上实现。
缺点:速度较慢,无法对动态物体进行实时重建。
接下来介绍几种常见的时域编码:
① Binary Code (二进制编码)
二进制编码使用黑白条纹形成一系列投影图案,这样物体表面上的每个点都拥有一个独特的二进制代码。N个图案可以编码2 N 2^N2 个条纹。
优点:精度比较高,对表面特征不太敏感,因为所有像素中只存在二进制值。
缺点:为了获得高的空间分辨率,需要投影大量的序列图案,而且场景中的所有对象都必须保持静止,级数较高的二进制码图片条纹密集,解码容易出错。

② Gray Code (格雷码)
格雷码是二进制码的一种改进,它的任意俩个相邻代码只有一位二进制数不同,最大数和最小数之间也仅有一位数不同即“首尾相连”,又称“循环码”。
优点:精度高,相邻状态变换是仅有一位发生改变,鲁棒性好。
缺点:速度慢,无法达到实时

③ Phase Shift (相移码)
投影多幅具有相位差的结构光图像来获得相位信息,常见的几种算法有三步相移法、四步相移法和五步相移法。编码图案的强度按照正弦函数分布,沿平行于编码轴的线的每个点都可以用唯一的相位值来表征。任何非平面3D形状都会导致记录的图案相对于投影图案发生变形,并记录为相位偏差,此相位偏差可以提供被测物体的形状信息。
优点:速度较快,三步相移法只需要投影三幅图片即可,测量精度也较高。
缺点:投影的非线性问题、包裹相位展开问题、相位误差补偿问题。

④ Hybrid:Phase Shift + Gray Code (相移+格雷码)
格雷码和相移码可以混合使用,利用各自的优点进行更好的编码解码方案。
优点:格雷码在没有任何模糊性的情况下确定相位的绝对范围,而相移提供的亚像素分辨率超过了格雷码提供的条纹数。
缺点:混合方法需要更多的投影,并且不适合动态对象的三维成像。

B、空域编码
空域编码和时域编码最显而易见的不同就是时域编码需要投射多幅图案而空域编码只需投射一幅图案。唯一的编码图案中每点的码字从该点周围点提供的信息(例如像素值、几何形状等)中得到。
优点:该编码方法在测量过程中只投影和采集一幅图像,计算量比时域编码方法显著降低,可用于实时的三维场景测量。
缺点:空域编码分辨率不高,且在解码阶段会有空间临近点的信息丢失,最终计算得到的的场景三维点与时域编码相比精度较低。
接下来介绍几种常见的空域编码:
① One-shot method based on point-pattern
使用单个点或一组点来解决相机和投影仪之间的对应问题。有了足够多的点,就可以鲁棒地测量物体的三维形状。
优点:简单、高效、精度高、抗外界光干扰强。
缺点:重建分辨率低,具体应用通常需要特定的图像处理方法。
② One-shot method based on line-pattern:
使用一组线条或条纹来解决相机和投影仪之间的对应问题,因为设计图案中的所有线条都是平行的,深度是通过相机和投影仪之间的线对线三角测量计算的。
优点:简单、高效、精度高、分辨率相对较高、抗外部光干扰能力强
缺点:特定的应用通常需要特定的图像处理方法。

③ One-shot method based on crossed-line-pattern
使用一组交叉线或交叉条纹来解决相机和投影仪之间的对应问题。通常,交叉线图案的水平线和垂直线采用不同的颜色,以便于识别线。设计图案中相同颜色的所有线条都是平行的,深度是通过相机和投影仪之间的水平线到水平线三角测量和垂直线到垂直线三角测量计算的。
优点:简单、高效、精度高、分辨率相对较高、抗外部光干扰能力强
缺点:特定的应用通常需要特定的图像处理方法。

三、补充:
Light coding method

激光束投射到扩散表面后,衍射斑随机形成。这些衍射点是高度随机的,并且随着距离的变化而改变图案。在三维空间中,不同位置的图案总是不同的。产生的散斑图案取决于激光的波长、激光束的大小以及扩散面与观察面之间的距离。下图显示了Kinect v1和其它文献中分别产生的两种不同散斑图案。由于散斑图案的高度随机性,其图像处理精度远低于处理精心设计的图案,因为精确的数学模型可用于已知形状的图案。与其他结构光方法相比,光编码方法的测量精度要低得多。与其他方法相比,它具有成本低、通用性好等优点。