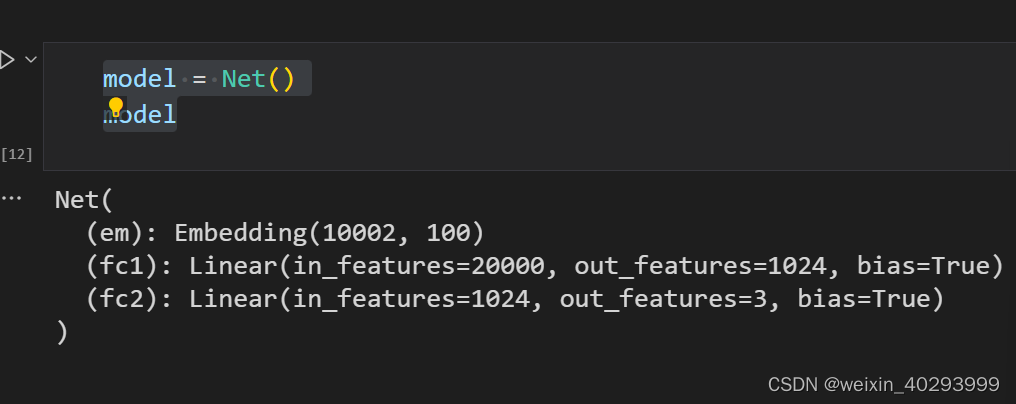
首先简单介绍下cgroup限制cpu的使用率,写一段代码如下:
#include <stdio.h>
#include <pthread.h>
int main()
{
int i = 0;
for(;;)i++;
return 0;
}
很明显,这里面是单核拉满,然后top看下进程的cpu使用率,如下所示:
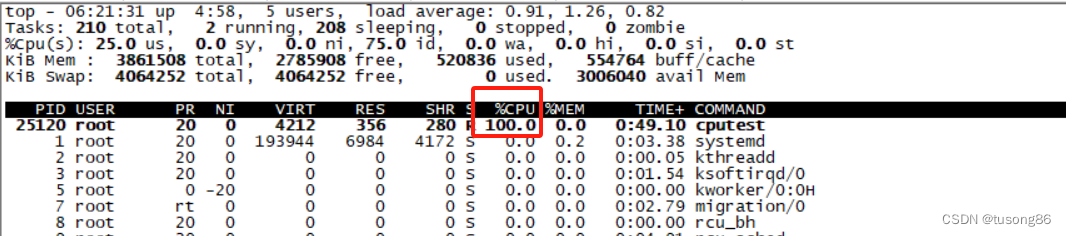
很明显,截图中的cpu使用率是正常的,现在限制cpu的使用率。
进入到目录/sys/fs/cgroup/cpu,创建目录cputest,进入到cputest,执行命令:
echo 200000 > cpu.cfs_quota_us
echo 1000000 > cpu.cfs_period_us
echo 25120 > tasks
这三句话中,前两句是限制cpu使用率为20%,第三句是设置进程,设置后的截图如下:
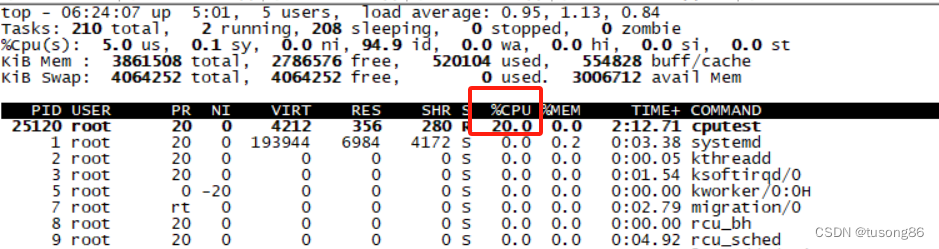
很明显,截图符合咱们的预期。
现在来限制内存:
写代码如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
int i = 0;
int size = 500 * 1024 * 1024;
char *p = (char *)malloc(size);
memset(p, 0, size);
while(1)
{
for(i = 0; i < size; i++)
p[i]=i;
sleep(1);
}
return 0;
}
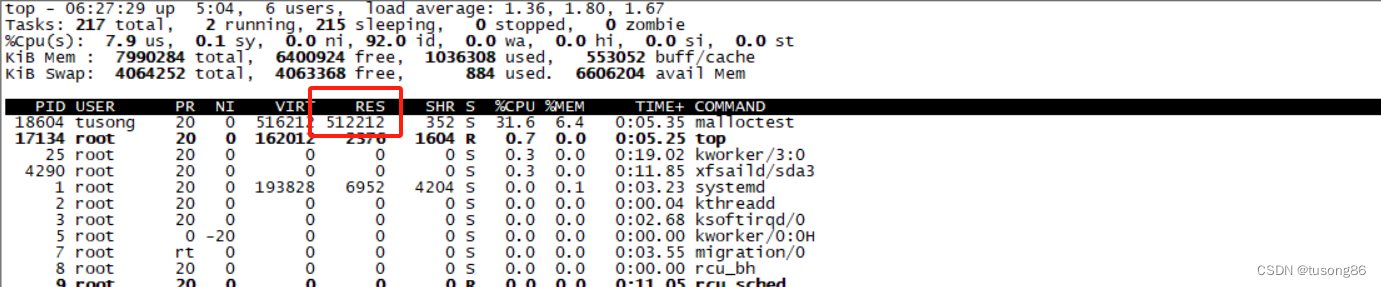
运行效果如下,很明显,占用物理内存大概为500M
现在限制该进程使用的物理内存为20M,进入到目录/sys/fs/cgroup/memory,创建目录memtest,进入到该目录。执行下列命令:
echo 20M > memory.limit_in_bytes
echo 18604 > tasks
这两句中,第一句是设置内存限制为20M,第二个是设置进程号。此时再看top截图,如下所示:
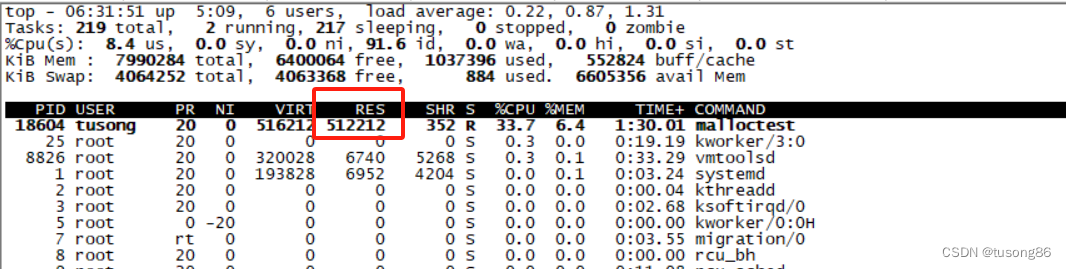
可以看到物理内存依然是500M的样子,没有减少,这跟想象中完全不一样,然后排查了几个小时,没有进展,后面尝试先在cgroup中设置进程的内存限制,再使进程开辟内存,代码如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
int i = 0;
int size = 500 * 1024 * 1024;
sleep(60);
char *p = (char *)malloc(size);
memset(p, 0, size);
while(1)
{
for(i = 0; i < size; i++)
p[i]=i;
sleep(1);
}
return 0;
}
可以看到,这里面在开辟内存之前,sleep 60秒,为此,咱们需要在这60秒之内,将进程id设置到cgroup中。
运行程序,产生进程号18837,执行命令echo 18837 > tasks,然后等待60秒结束,top信息如下所示:
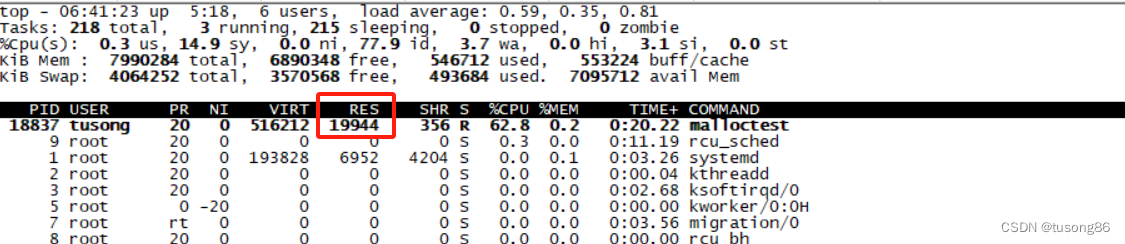
很明显,这次有效果,占用的物理内存接近20M,咱们在top界面按下f,将swap选中,再次截图如下:

此时看到SWAP内存为480M多点,这个结果完全符合咱们的期望。
以上表明,在设置进程的内存限制时,要在进程尚未开辟物理内存时设置,一旦进程开辟了很多的物理内存,再限制物理内存,使得物理内存使用量下降,已经为时已晚。
咱们再考虑多进程的情况,正常来说多进程架构比较稳,一个服务程序可能产生多个进程,而我们想控制的是这个服务程序总的内存使用量,即其产生的所有子进程的内存占用之和不要超过某个值,这该如何设置。
写一个多进程应用,代码如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
int i = 0;
int size = 500 * 1024 * 1024;
int childpid = 0;
char *p = NULL;
sleep(60);
childpid = fork();
p = (char *)malloc(size);
memset(p, 0, size);
while(1)
{
for(i = 0; i < size; i++)
p[i]=i;
sleep(1);
}
return 0;
}
可以看出,这里面创建了一个子进程,父进程和子进程都占用了500M内存,咱们等到60s后,执行top命令:

这里咱们未设置内存限制,情况完全正确。
现在限制这个应用程序(两个进程)的内存限制为20M。
重新运行该程序,查看进程号19920,注意代码中的fork在sleep之后,故而此时只有一个进程号, 在60s内。
echo 19920 > tasks。
60s之后,子进程产生了,top命令截图如下:

可以看到这两个进程占用的物理内存加起来大概20M。
但是咱们刚才只将父进程的id 19920设置到tasks文件中。
我们现在看下这个tasks文件里面的内容,截图如下:

可以看到,这里面有两个进程号,但是我只设置了19920到tasks中,另外一个是cgroup内部设置进去。
查原因,发现是有个进程组的概念,将进程组的首id设置进去,后续产生的进程id都会被cgroup设置进去。
截图如下,可以查看进程组,注意我敲的是两个命令,可以看出19931不是一个进程组,19920既是进程组id,也是该进程组的第一个进程id。子进程默认会继承父进程的进程组id。
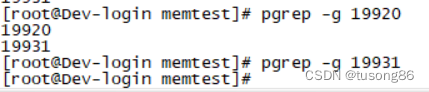
现在再考虑下应用程序里面有多个进程组的情况,默认情况下子进程会继承父进程的进程组id。但是子进程的进程组id也可以进行修改,代码如下:
#include <stdio.h>
#include <string.h>
#include <stdlib.h>
#include <unistd.h>
int main()
{
int i = 0;
int size = 500 * 1024 * 1024;
int childpid = 0;
char *p = NULL;
sleep(60);
childpid = fork();
if(childpid==0)
{
setpgid(0, getpid());
}
p = (char *)malloc(size);
memset(p, 0, size);
while(1)
{
for(i = 0; i < size; i++)
p[i]=i;
sleep(1);
}
return 0;
}
代码中,子进程的逻辑块中,用setpgid设置其进程组id为其自身id,在sleep 60秒内,产生的进程id是20098,然后执行命令: echo 20098 > tasks
过60秒后,查看进程如下:

可以看到,此时有两个进程组,top截图如下:

可以看出,两个进程的物理内存之和大概是20M,由此推断就算父进程和子进程是不同的进程组,进程限制也对整个应用程序有效。
我们再查看下tasks里面的内容:
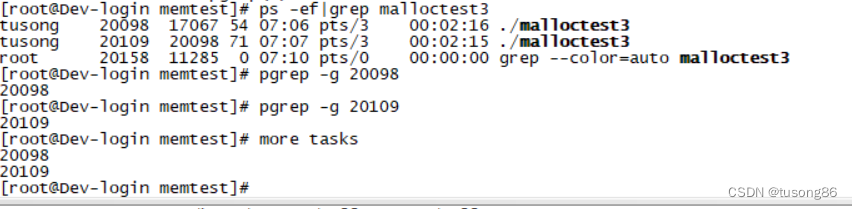
发现父子进程就算是位于不同的进程组,只要设置第一个进程id进去,cgroup会自动将子进程的id设置进去。
其实笔者在更复杂的环境中测试过,一个应用程序产生大量的进程,也是这些所有的进程的内存加起来,大致满足cgroup的受限条件,而这些进程id也会被写入到tasks中。
注意,我这里说的是所有的进程的内存加起来,大致满足,有个大致,其实我遇到过所有子进程内存加起来,超过设置的20M的情况,但是超出的不多,大概超出2M。具体原因未能明白。
![[管理与领导-96]:IT基层管理者 - 扩展技能 - 5 - 职场丛林法则 -10- 七分做,三分讲,完整汇报工作的艺术](https://img-blog.csdnimg.cn/a3dfdab67f38429fa509890817156731.png)