顺序覆盖算法的步骤
顺序覆盖算法的目标是提取一个分类规则,该规则覆盖训练集中大量正例,没有或仅覆盖少量反例。
整个过程包含以下四个步骤:
- 规则增长
- 规则评估
- 停止准则
- 规则剪枝
顺序覆盖算法的第一步——规则增长
一般到特殊(通常采用的策略)
- 从初始规则r: {}→y开始
- 反复加入合取项,得到更特殊的规则,直到不能再加入
特殊到一般(适用于小样本情况) - 随机地选择一个正例作为初始规则
- 反复删除合取项,得到更一般的规则,直到不能再删除
从一般到特殊的规则生成策略中,每次只考虑一个最优的(属性,值)这显得过于贪心,容易陷入局部最优麻烦
为了缓解该问题,可以采用一种“束状搜索“的方式
- 具体做法为:每次选择添加的(属性,值)时,可以保留前k个最优的(属性,值) ,而不是只选择最优的那个,然后对这k个最优的(属性,值)继续进行下一轮的(属性,值)添加。
顺序覆盖算法的第二步——规则评估
常用的度量
- 准确率
- 似然比
- 准确率的平滑Laplace
- FOIL信息增益

然而r2并未覆盖反例,因此r2并不准确,然而r2的准确率高于r1,因此只看准确率去评估规则并不准确.



顺序覆盖算法的第三,四步
停止条件:
- 计算增益
- 如果增益不显著, 则丢弃新规则
规则剪枝: - 类似于决策树后剪枝
- 降低错误剪枝 :
- 删除规则中的合取项
- 比较剪枝前后的错误率
- 如果降低了错误率,则剪掉该合取项
急切学习 vs 惰性学习
急切学习(积极学习):
是指在利用算法进行判断之前,先利用训练集数据通过训练得到一个目标函数,在需要进行判断时利用已经训练好的函数进行决策。
两步过程: (1) 归纳 (2) 演绎
惰性学习(消极学习):
把训练数据建模过程推迟到需要对样本分类时
策略:死记硬背-记住所有的训练数据,仅当待测记录的属性值与一个训练记录完全匹配才对它分类.
最近邻分类算法(KNN):使用“最近”的 k 个点 (最近邻) 进行分类。
最近邻分类器:
基本思想:
存在一个样本数据集,且样本集中每个数据都存在类别标签,即我们知道样本集中每个数据与所属分类的对应关系。
需要对没有标签的待测数据进行分类时,将待测数据的每个特征与样本集中的数据对应的特征进行比较,然后通过算法提取样本集中最相似的数据(最近邻)的分类标签作为待测数据的类别。
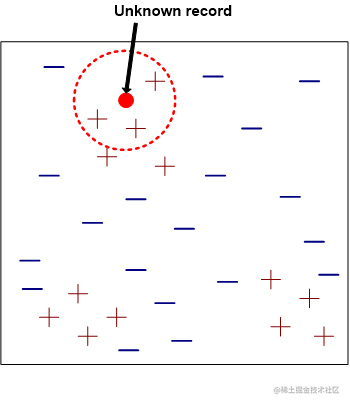
KNN算法中的基本要素:
- 计算记录间距离的度量
- k值的确定
常用的距离度量: - 欧几里得距离
- 曼哈顿距离
- 余弦距离
k值的确定:
如果 k 太小, 则对噪声点敏感;如果 k 太大, 邻域可能包含很多其他类的点;
可设定不同的k值进行训练,取分类误差率最小的k值。
KNN算法的步骤:
计算距离:给定测试对象,计算它与训练集中每个训练样本的距离。
寻找邻居:圈定距离最近的k个训练样本,作为测试对象的近邻。
进行分类:根据这k个近邻所属的主要类别,对测试对象进行分类。
KNN算法的具体实现:
- 先从训练集中随机选取k个样本作为初始的最近邻样本;
- 分别计算测试数据到这k个训练样本的距离,并按距离大小排成一个队列Q;
- 依次遍历训练集,计算当前训练样本与测试数据的距离L,如果L大于队列Q中的最大距离,则舍去当前样本;如果L小于队列Q中的最大距离,则删除队列Q中距离最大的训练样本,再将当前训练样本插入队列Q。
- 直到训练集遍历完毕,最后队列Q中的k个样本即为k个最近邻。
- 依据最终的k个最近邻样本的类别作为测试数据的类别。
K最近邻(KNN)的特点:
- 是一种基于实例的惰性学习 ,需要一个大量样本的训练集;
- 不需要建立模型,但分类一个测试样例开销很大
- 需要计算待测数据到所有训练实例之间的距离
- 基于局部信息进行预测,对噪声非常敏感;
- 简单,易于实现。