一、ChatGLM2-6B Lora 微调
LoRA 微调技术的思想很简单,在原始 PLM (Pre-trained Language Model) 增加一个旁路,一般是在 transformer 层,做一个降维再升维的操作,模型的输入输出维度不变,来模拟 intrinsic rank,如下图的 A 和 B。训练时冻结 PLM 的参数,只训练 A 和 B ,,输出时将旁路输出与 PLM 的参数叠加,进而影响原始模型的效果。该方式,可以大大降低训练的参数量,而性能可以优于其它参数高效微调方法,甚至和全参数微调(Fine-Tuning)持平甚至超过。
对于 A 和 B 参数的初始化,A 使用随机高斯分布,B 使用 0 矩阵,这样在最初时可以保证旁路为一个 0 矩阵,最开始时使用原始模型的能力。

对于 lora 微调的实现可以使用 HuggingFace 开源的 PEFT 库,地址如下:
https://github.com/huggingface/peft
下载依赖:
pip install peft -i https://pypi.tuna.tsinghua.edu.cn/simple
使用方式也很简单,例如先查看 ChatGLM2-6B 的模型结构:
from transformers import AutoModel
model_name = "chatglm-6b"
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
print(model)
输出结果:
ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(in_features=4096, out_features=4608, bias=True)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)
可以看出 ChatGLM 主要由 28 层的 GLMBlock 进行提取和理解语义特征,下面借助 PEFT 库将 Lora 旁路层注入到模型中,主要关注下 query_key_value 层的变化:
from transformers import AutoTokenizer, AutoModel, AutoConfig
from peft import LoraConfig, get_peft_model, TaskType
model_name = "chatglm-6b"
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
config = LoraConfig(
peft_type="LORA",
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=16,
lora_dropout=0.1,
fan_in_fan_out=False,
bias='lora_only',
target_modules=["query_key_value"]
)
model = get_peft_model(model, config)
print(model)
其中 r 就是 lora 中秩的大小。
输出结果:
PeftModelForCausalLM(
(base_model): LoraModel(
(model): ChatGLMForConditionalGeneration(
(transformer): ChatGLMModel(
(embedding): Embedding(
(word_embeddings): Embedding(65024, 4096)
)
(rotary_pos_emb): RotaryEmbedding()
(encoder): GLMTransformer(
(layers): ModuleList(
(0-27): 28 x GLMBlock(
(input_layernorm): RMSNorm()
(self_attention): SelfAttention(
(query_key_value): Linear(
in_features=4096, out_features=4608, bias=True
(lora_dropout): ModuleDict(
(default): Dropout(p=0.1, inplace=False)
)
(lora_A): ModuleDict(
(default): Linear(in_features=4096, out_features=8, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=8, out_features=4608, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
)
(core_attention): CoreAttention(
(attention_dropout): Dropout(p=0.0, inplace=False)
)
(dense): Linear(in_features=4096, out_features=4096, bias=False)
)
(post_attention_layernorm): RMSNorm()
(mlp): MLP(
(dense_h_to_4h): Linear(in_features=4096, out_features=27392, bias=False)
(dense_4h_to_h): Linear(in_features=13696, out_features=4096, bias=False)
)
)
)
(final_layernorm): RMSNorm()
)
(output_layer): Linear(in_features=4096, out_features=65024, bias=False)
)
)
)
)
可以对比下原始的 ChatGLM 模型结构, query_key_value 层中已经被加入下 lora 的 A、B 层,下面可以通过 model.print_trainable_parameters() 打印可训练的参数量:
trainable params: 2,078,720 || all params: 6,245,533,696 || trainable%: 0.03328330453698988
可以看到可训练的参数量只有 0.03328330453698988 。
下面依然借助前面文章使用的医疗问答数据集,在 ChatGLM2 lora 微调下的效果。
对该数据集不了解的小伙伴可以参考下面这篇文章:
ChatGLM2-6B P-Tuning v2 微调训练医疗问答任务
二、ChatGLM2-6B Lora 微调
解析数据,构建 Dataset 数据集 qa_dataset.py:
# -*- coding: utf-8 -*-
from torch.utils.data import Dataset
import torch
import json
import numpy as np
class QADataset(Dataset):
def __init__(self, data_path, tokenizer, max_source_length, max_target_length) -> None:
super().__init__()
self.tokenizer = tokenizer
self.max_source_length = max_source_length
self.max_target_length = max_target_length
self.max_seq_length = self.max_source_length + self.max_target_length
self.data = []
with open(data_path, "r", encoding='utf-8') as f:
for line in f:
if not line or line == "":
continue
json_line = json.loads(line)
content = json_line["content"]
summary = json_line["summary"]
self.data.append({
"question": content,
"answer": summary
})
print("data load , size:", len(self.data))
def preprocess(self, question, answer):
prompt = self.tokenizer.build_prompt(question, None)
a_ids = self.tokenizer.encode(text=prompt, add_special_tokens=True, truncation=True,
max_length=self.max_source_length)
b_ids = self.tokenizer.encode(text=answer, add_special_tokens=False, truncation=True,
max_length=self.max_target_length)
context_length = len(a_ids)
input_ids = a_ids + b_ids + [self.tokenizer.eos_token_id]
labels = [self.tokenizer.pad_token_id] * context_length + b_ids + [self.tokenizer.eos_token_id]
pad_len = self.max_seq_length - len(input_ids)
input_ids = input_ids + [self.tokenizer.pad_token_id] * pad_len
labels = labels + [self.tokenizer.pad_token_id] * pad_len
labels = [(l if l != self.tokenizer.pad_token_id else -100) for l in labels]
return input_ids, labels
def __getitem__(self, index):
item_data = self.data[index]
input_ids, labels = self.preprocess(**item_data)
return {
"input_ids": torch.LongTensor(np.array(input_ids)),
"labels": torch.LongTensor(np.array(labels))
}
def __len__(self):
return len(self.data)
构造 Lora 结构,微调训练 train_lora.py:
# -*- coding: utf-8 -*-
import pandas as pd
from torch.utils.data import DataLoader
from transformers import AutoTokenizer, AutoModel
from qa_dataset import QADataset
from peft import LoraConfig, get_peft_model, TaskType
from tqdm import tqdm
import torch
import os, time, sys
def train(epoch, model, device, loader, optimizer, gradient_accumulation_steps):
model.train()
time1 = time.time()
for index, data in enumerate(tqdm(loader, file=sys.stdout, desc="Train Epoch: " + str(epoch))):
input_ids = data['input_ids'].to(device, dtype=torch.long)
labels = data['labels'].to(device, dtype=torch.long)
outputs = model(
input_ids=input_ids,
labels=labels,
)
loss = outputs.loss
# 反向传播,计算当前梯度
loss.backward()
# 梯度累积步数
if (index % gradient_accumulation_steps == 0 and index != 0) or index == len(loader) - 1:
# 更新网络参数
optimizer.step()
# 清空过往梯度
optimizer.zero_grad()
# 100轮打印一次 loss
if index % 100 == 0 or index == len(loader) - 1:
time2 = time.time()
tqdm.write(
f"{index}, epoch: {epoch} -loss: {str(loss)} ; each step's time spent: {(str(float(time2 - time1) / float(index + 0.0001)))}")
def validate(tokenizer, model, device, loader, max_length):
model.eval()
predictions = []
actuals = []
with torch.no_grad():
for _, data in enumerate(tqdm(loader, file=sys.stdout, desc="Validation Data")):
input_ids = data['input_ids'].to(device, dtype=torch.long)
labels = data['labels'].to(device, dtype=torch.long)
generated_ids = model.generate(
input_ids=input_ids,
max_length=max_length,
do_sample=False,
temperature=0
)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in
generated_ids]
target = [tokenizer.decode(t, skip_special_tokens=True, clean_up_tokenization_spaces=True) for t in labels]
predictions.extend(preds)
actuals.extend(target)
return predictions, actuals
def main():
model_name = "chatglm-6b"
train_json_path = "./data/train.json"
val_json_path = "./data/val.json"
max_source_length = 128
max_target_length = 512
epochs = 5
batch_size = 1
lr = 1e-4
lora_rank = 8
lora_alpha = 32
gradient_accumulation_steps = 16
model_output_dir = "output"
# 设备
device = torch.device("cuda:0")
# 加载分词器和模型
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
# setup peft
peft_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=lora_rank,
lora_alpha=lora_alpha,
lora_dropout=0.1
)
model = get_peft_model(model, peft_config)
model.is_parallelizable = True
model.model_parallel = True
model.print_trainable_parameters()
# 转为半精度
model = model.half()
model.float()
print("Start Load Train Data...")
train_params = {
"batch_size": batch_size,
"shuffle": True,
"num_workers": 0,
}
training_set = QADataset(train_json_path, tokenizer, max_source_length, max_target_length)
training_loader = DataLoader(training_set, **train_params)
print("Start Load Validation Data...")
val_params = {
"batch_size": batch_size,
"shuffle": False,
"num_workers": 0,
}
val_set = QADataset(val_json_path, tokenizer, max_source_length, max_target_length)
val_loader = DataLoader(val_set, **val_params)
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
model = model.to(device)
print("Start Training...")
for epoch in range(epochs):
train(epoch, model, device, training_loader, optimizer, gradient_accumulation_steps)
print("Save Model To ", model_output_dir)
model.save_pretrained(model_output_dir)
# 验证
print("Start Validation...")
with torch.no_grad():
predictions, actuals = validate(tokenizer, model, device, val_loader, max_target_length)
# 验证结果存储
final_df = pd.DataFrame({"Generated Text": predictions, "Actual Text": actuals})
val_data_path = os.path.join(model_output_dir, "predictions.csv")
final_df.to_csv(val_data_path)
print("Validation Data To ", val_data_path)
if __name__ == '__main__':
main()
开始训练:

等待训练结束后,可以在输出目录看到保存的模型,仅只有 lora 层的参数,所以模型比较小:
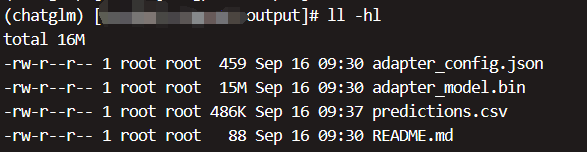
此时可以查看下 predictions.csv 中验证集的效果。
三、模型测试
from transformers import AutoTokenizer, AutoModel, AutoConfig
from peft import PeftConfig, PeftModel, LoraConfig, get_peft_model, TaskType
import torch
def load_lora_config(model):
config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
inference_mode=False,
r=8,
lora_alpha=32,
lora_dropout=0.1,
target_modules=["query_key_value"]
)
return get_peft_model(model, config)
device = torch.device("cuda:0")
model_name = "chatglm-6b"
lora_dir = "output"
model = AutoModel.from_pretrained(model_name, trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
config = PeftConfig.from_pretrained(lora_dir)
model = PeftModel.from_pretrained(model, lora_dir)
model = model.to(device)
model.eval()
response, history = model.chat(tokenizer, "5月至今上腹靠右隐痛,右背隐痛带酸,便秘,喜睡,时有腹痛,头痛,腰酸症状?", history=[])
print("回答:", response)
输出:

回答: 你好,根据你的叙述,考虑是胃炎引来的。建议你平时留意饮食规律,不要吃辛辣刺激性食物,多喝热水,可以口服奥美拉唑肠溶胶囊和阿莫西林胶囊实施救治,如果效果不好,建议去医院做胃镜仔细检查。除了及时救治胃痛外,患者朋友理应始终保持愉快的心态去直面疾病,只有这样才能令得患者及时对症救治,同时要多看重自身饮食护理,多观注自身的症状变动,认为这样一定能将胃痛撵走。