KMP算法与BF算法不一样的在于,当主串与子串不匹配时,主串不回溯,选择了子串回溯,大大提高了运算效率。
借用了next1【】数组,让子串回溯。get_next函数求next1【】数组,get_next函数的实现难点在于下列几行代码:
while (i < T.length)
{
if (j == 0 || T.ch[i] == T.ch[j])
{
++i, ++j;
next1[i] = j;
}
else
j = next1[j];
}
只要明确两点就容易理解:
1、Tj == Tnext[j],那么next[j+1]的最大值为next[j]+1。
2、Tj != Tnext[j],那么next[j+1]可能的次最大值为next[ next[j] ]+1,以此类推即可求出next[j+1]。
#include<iostream>
#include<string>
using namespace std;
int next1[1000];
typedef struct node
{
char ch[251];
int length=0;//串当前长度
}SString;
void get_next(SString T)
{
int i = 1;//当前串正在匹配字符串位置,也是next数组的索引
next1[1] = 0;
int j = 0;
while (i < T.length)
{
if (j == 0 || T.ch[i] == T.ch[j])
{
++i;
++j;
next1[i] = j;
}
else
j = next1[j];
}
}
int Index_KMP(SString S, SString T, int pos)//S主串,T子串,pos从主串pos位置开始匹配
{
int i = pos, j = 1;//i为主串下标,j为子串下标
while (i <= S.length && j <= T.length)
{
if (S.ch[i] == T.ch[j])//匹配,往下继续
{
i++;
j++;
}
else
j=next1[j];
}
if (j >= T.length) return i - T.length;//返回主串与子串匹配时,主串的第一个下标
else return 0;
}
int main()
{
SString s;
SString t;
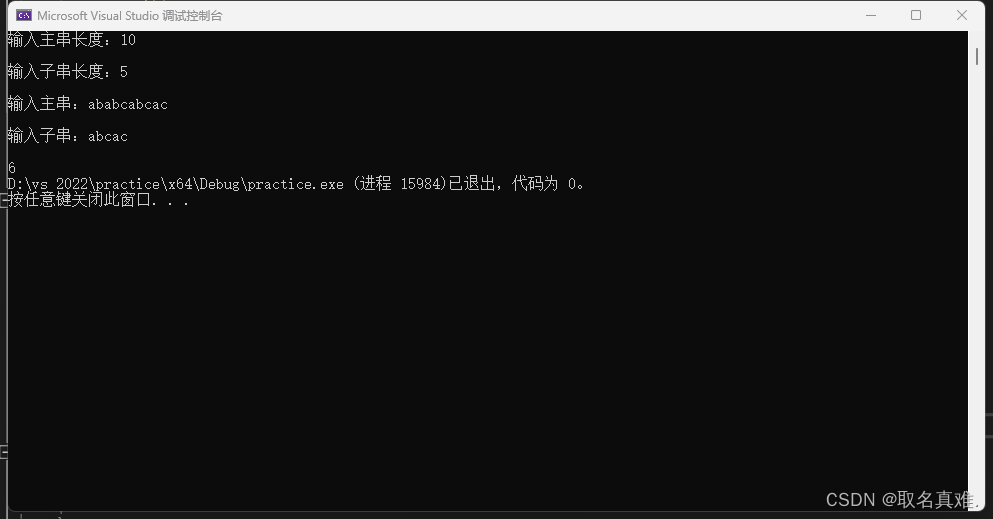
cout << "输入主串长度:" ;
cin >> s.length;
cout << endl;
cout << "输入子串长度:";
cin >> t.length;
cout << endl << "输入主串:";
for (int i = 1; i <= s.length; i++)//从下标1开始储存
{
cin >> s.ch[i];
}
cout << endl << "输入子串:";
for (int i = 1; i <= t.length; i++)
{
cin >> t.ch[i];
}
get_next(t);
int a = Index_KMP(s, t, 1);
cout <<endl<< a;
}