Part11-Join Algorithms
Why Do We Need to Join?
Join其实是关系数据库和范式化表时候所产生的副产物。
也就是说我们范式化表是为了减少冗余信息,而我们使用join就是为了去重建reconstruct 这些原本的tuple
Join Algorithms
主要关注两表的inner equijoin algorithms
通常,较小的表作为左表(left table / outer table)进行join,右表叫做inner table
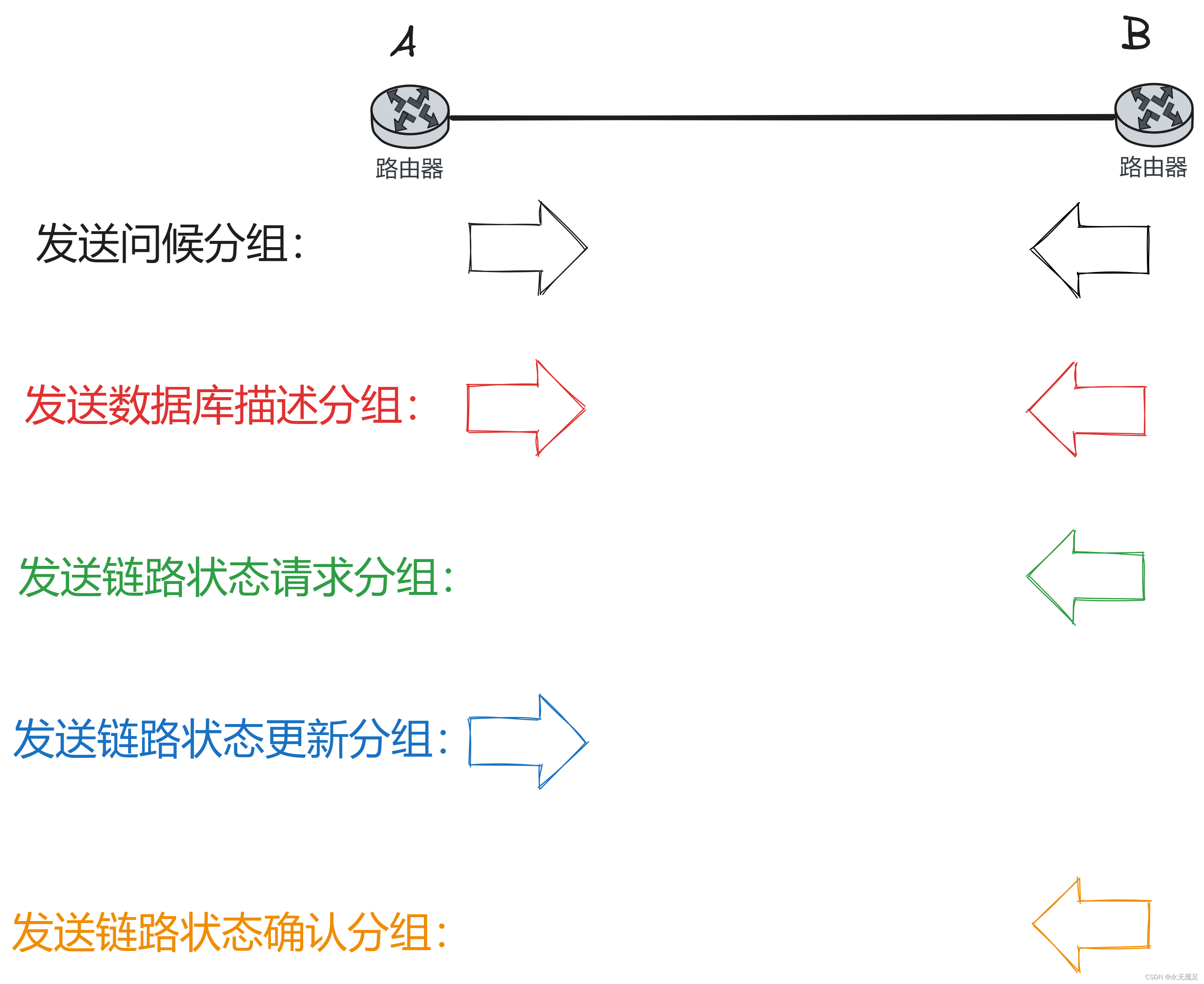
Join Operators
在叶子节点处对表访问,将表中的tuple作为输入传给父节点的operator。
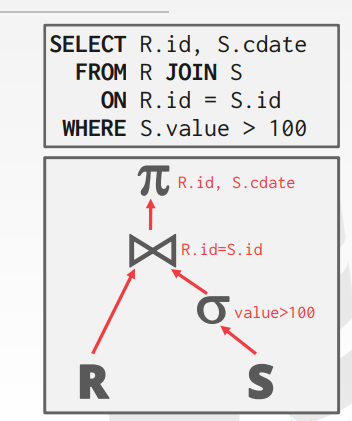
考虑1. output 查询计划生成树join算子之间传递的是什么 2. 如何判断算法的优劣——Cost Analysis Criteria
-
对于两个表R,S的tuple r,s进行join 级联操作,生成一个新的tuple,具体的内容取决于
- 查询处理模型 Query processing model (多个tuple)
- 存储模型 Storage model ,row / column 存
- 具体的query
关于算子之间的输出传递,可以直接级联的结果进行传递,如果很多列则代价很大,可能进行一个预先的投影操作。还有就是only copy joins keys along with record ids.(特别针对列存) 叫做Late Materialization
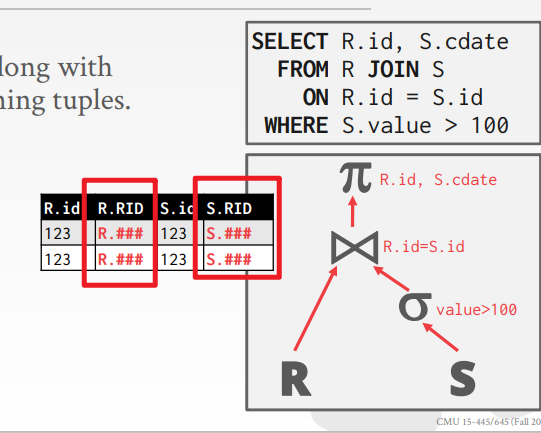
-
I/O Cost Analysis
计算join过程必须使用的I/O次数来估计成本。只关心join操作的成本,不关心最后输出结果或者其他因素。
M pages in table R m tuples in R N pages in table S n tuples in S
Join VS Cross-Product
cross-product 交叉连接
Join Algorithms
包括Nested Loop Join、Sort-Merge join、Hash Join
Nested Loop Join
for each tuple r in R // outer table
for each tuple s in S: // inner table
emit,if r and s match
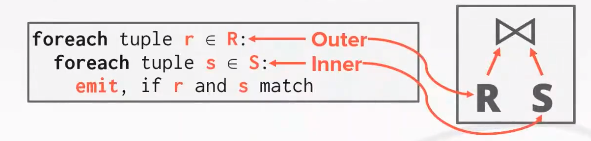
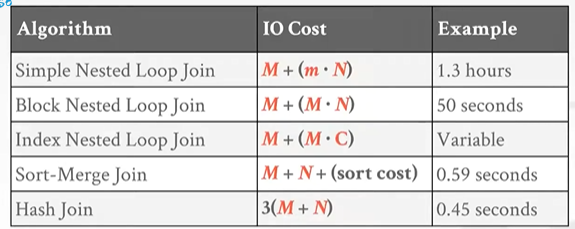
stupid ! Cost: M + m* N 左表M个pages,然后m个tuple每次都扫描一次右表N个pages,代价就是M+m*N
优化:
-
小表作为左表
-
Block Nested Loop Join
使用block、page,可以多个tuple一个block/page,让outer table的一个block中所有tuple 完成和inner table中所有tuple的join,再去取下一个inner table的block。

代价是:M+M*N,这里的话小表就是page少的了 不是tuple少的
-
对于outer table使用尽可能多的内存buffer来保存他,即B-2个block 来保存左表,1 block for inner table, 1 block for output result。
Cost = M + [M / (B-2)] * N
如果buffer够大可以放开左表,那cost = M+N

-
可以避免循序扫描通过使用index来找inner table matches
- 使用一个已经存在的index on inner table
- build one on the fly(hash table, B+ Tree) 针对join的index 叫做Spooling index. 查询结束删除index

index不一定就是join on的key,也许join on col A and B,在A上有index也可以用索引探针(Index probe)来进行优化,先找A然后再匹配B列。
假设C是index查找一个tuple的一个代价,Cost = M + m*C
-
Sort-Merge Join
- 第一阶段—排序:sort both tables on the join keys;可以使用external merge sort或者内存中的快排
- 第二阶段—合并:使用游标对排好序的两个表的tuple进行逐个比较,匹配就输出。双指针。

可能会需要backtracking 回溯操作,回到该值在inner table中第一次出现的地方。只会对inner table进行backtracking。
Cost =

最差的情况:outer table中的每个值和inner table中的每个值都相等,每个tuple m都得回溯一次,COST = M * N + SORT COST
Sort-Merge join 用处:如果有一个或者俩表都on join key排好序了;或者要求order by,需要对结果排序。特别有个索引排好序 且是聚簇索引
-
Hash Join:
-
hash function是确定的,两个表相同的key hash 结果相同。
-
基于hash key来讲outer table拆分成多个分区,付出前期成本来将数据拆分以此让查找或者探测过程更快。即value hash → partition i,R tuple must be in r_i,S tuple must be in s_i。因此R tuples in r_i只需要和S tuples in s_i 比较来进行join
-
Basic Hash Join Algorithm
-
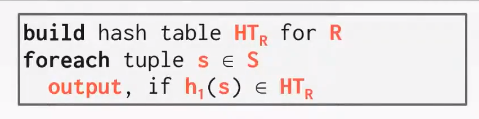
Build:循序扫描outer relation 然后pop到hashtable 使用h_1
-
Probe:对inner relation扫描,使用h_1 将每个tuple进行hash处理;会跳到相同的位置然后看有没有匹配的tuple。
-
Key:是join操作基于的属性;Value:取决于上层算子的输入。
-
Hash Table Values
- Full Tuple:避免回表IO,但是需要更多内存。
- Tuple Identifier:tuple标识符例如record id,适用于列存,
-
-
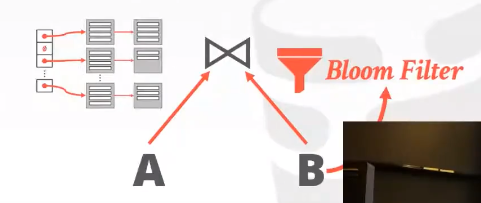
Probe Phase Optimization:再build阶段创建一个bloom filter,在没有查看hash table的情况下可以通过它来判断要查找的tuple是否在这个hashtable中。也叫做sizeways information passing横向信息传递。
- Bloom Filter:是一种概率数据结构(Probabilistic DS)(bitmap)用来处理set membership查询(近似成员查询:该key在不在我的集合中)包括操作:insert(x),Lookup(x).好处是可能会假阳性,就是实际不在但是告诉你在,但是不会逻辑上影响正确性,不会假阴性就是在但是告诉你不在,这样就是逻辑错误了这种不会出现。
- 具体的优化是构建hash table的时候可能会溢出到磁盘,为key构建一个bloom filter,super small can fit in memory。避免潜在的无用的磁盘I/O
-
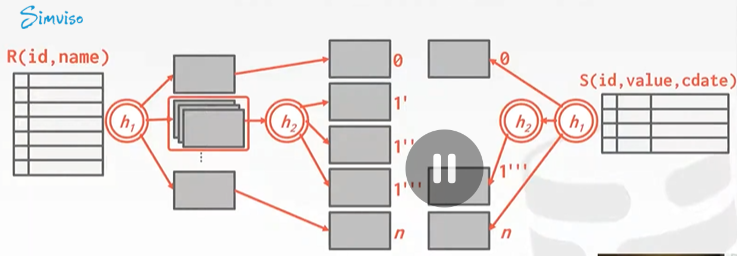
Grace(partition) Hash Join:处理Hash Join don’t fit in memory
- Build Phase:基于hash key将两张表拆分成多个分区,拆分成两个单独的hash table,outer table和inner table各自有一张hash table。
- Probe Phase:比较两张表对应分区的tuples,对匹配的分区进行nested-loop join。
bucket chain hash table而非linear probe hash table。因为想要相同的数据hash到同一位置或者映射到同一分区。一一匹配去scan。
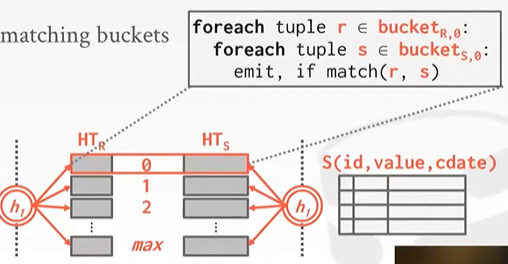
都hash到一个bucket就会出问题,用递归分区Recursive Partitioning来解决。使用另外一个hash function h2来建立bucket_r,i。如果有足够buffer,且所有数据都能放在内存中,可以跨分区进行join操作,COST = 3 *(M+N)。分区的时候要对M outertable N innertable进行一轮读和一轮写,probe一轮
-
Observation
如果DBMS直到outer table的size可以去调整hash table或者buffer size,如果可以都内存就线性hash,如果需要溢出到磁盘就bucket。如果不知道size,可以使用动态hash table(linear extendable hash table)或者允许overflow pages,但是代价会很高。
- 什么情况下会不清楚outer table的size? 回答:多个操作之间所产生的临时中间表的size
除非排好序,否则hash join永远比其他join来的好
sorting适合于non-uniform data 或者结果需要排序的情况。
range join anti join?