Part09-Multi-Threaded Index Concurrency Control
多线程下索引的并发控制
Concurrency Control
强制所有访问数据结构的线程都使用某种协议或者某种方式。并发控制协议的概念:并发控制协议是一种当并发操作作用在一个共享对象上时DBMS用来确保correct的method。关心的正确性:逻辑正确性和物理正确性。
逻辑正确性:如果我正在访问该数据结构我希望看到的数据是我想看到的。
物理正确性:如何保护数据结构的内部表示。
segmentation falut 存储器区块错误,内存越界一般是。
| — | — | — |
Latch Modes
Read Mode
- 允许多条线程在同一时间去读取同一个对象
- 即使其他线程有read mode latch,new thread也可以获得read latch
Write Mode
- exclusive latch,一次只有一个线程可以持有这个latch
- 写写冲突、写读冲突
Latch Implementations
-
Blocking OS Mutex
- std::mutex
- 具体在操作系统咋实现?Futex:fast userspace mutex,在用户空间中占据一点 1 bit 位置,来进行Compate And Swap操作,以获取这个latch,如果取到了就用,如果没取到就用OS层面mutex,速度相对慢。futex is spin latch
std::mutex m; m.lock(); // do something m.unlock(); -
Test-and-Set Spin Latch(TAS)
-
即使用一个spin latch 或者 TAS Spin Latch,非常高效,super fast,因为可以通过modern CPUS的单条指令来完成TAS动作,
-
api: std::atomic 简化:atomic_flag = atomic
std::atomic_flag latch; // ... while(latch.test_and_set(...)){ // come in when you don't get latch // retry? yiled? abort? }
-
-
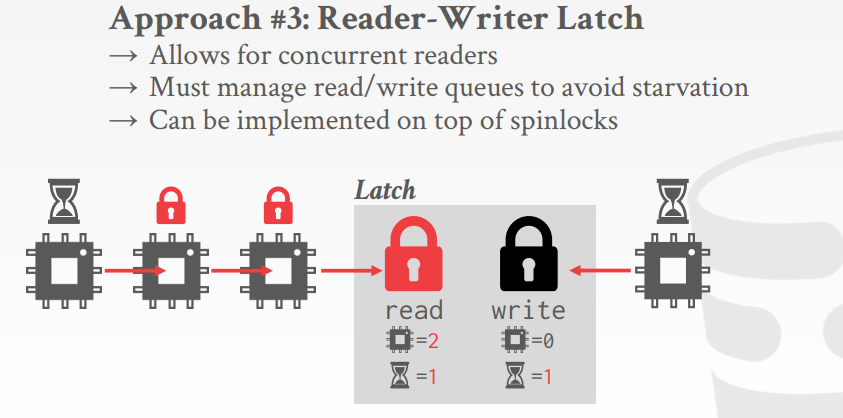
Reader-Writer Latch
-
涉及读写互斥以及读优先or写优先
-
Hash Table Latching
- 所有的线程move同一个方向,一次只获取一个page 或者 slot。
- 不会发生死锁
- resize table的时候,会对header page加一个全局latch on the entire table,以保证在resize调整结束之前,组织别人对该table进行读写操作。
latch 粒度:
- Approach #1: Page Latches
- 在每一个page上面使用一个reader writerlatch 来保护整个内容
- 当线程访问page的时候,需要事先获得一个read or write latch
- Approach #2: Slot Latches
- 每个slot有一个自己的latch
- 可以使用一个single mode latch来减少meta-data and 计算代价
B+ Tree Latching
可能会遇到的问题:
- 多个线程同时修改一个节点的内容
- 一个线程正在遍历,而另外一个则导致了树结构的变化。
解决方案:latch crabbing/ coupling
允许多线程访问修改B+ Tree。
基本思想:
- 当我们使用一个节点的时候,就需要加一个latch,不管是write/read latch
- 想要访问子节点,要拿子节点的latch(下一个访问的latch)
- 如果移动到子节点是安全的,将父节点latch释放就是OK的
- Safe Node:进行一次修改的话,我们所在的节点无需拆分或者合并
- 该节点not full(可以插入)
- more than half-full(可以删除)
Find:
- 获得 Read Latch on child
- unlatch parent
Delete:
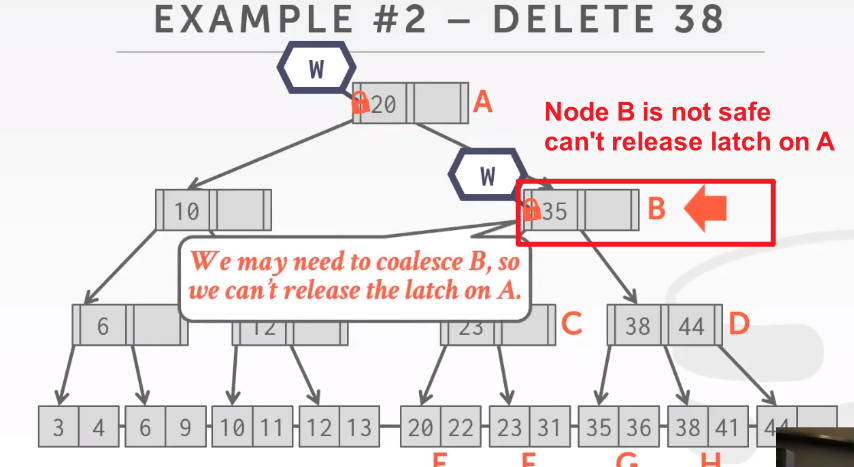
再到D的话,删除38,则D是安全状态,然后可以释放AB的latch
线程向下进行遍历的时候,会用stack来保存一路上所持有的latch。
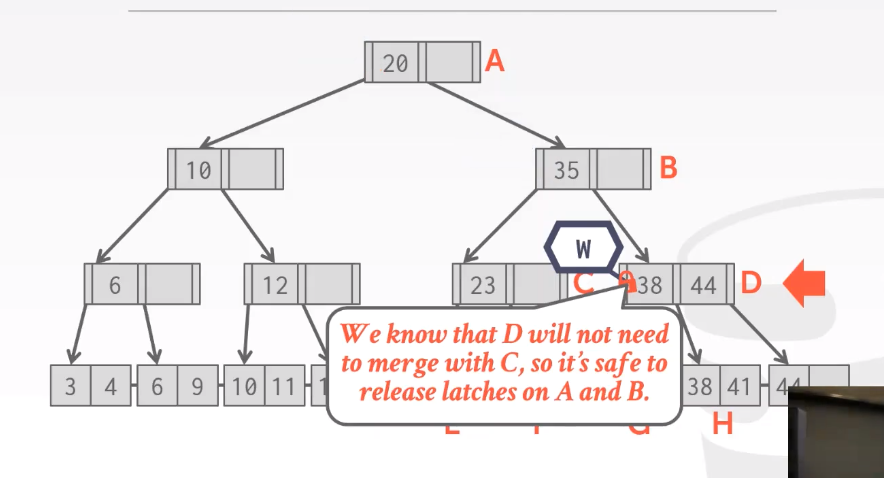
Insert:
对于插入来说 B是安全的,可以释放A的latch
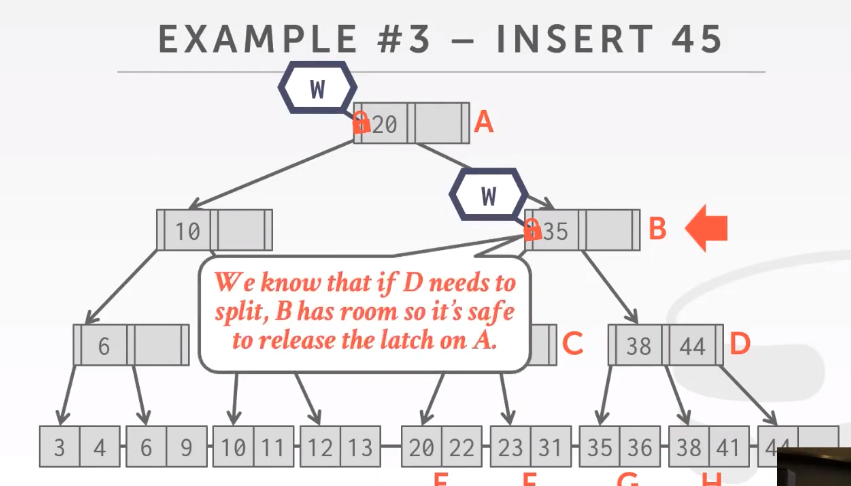
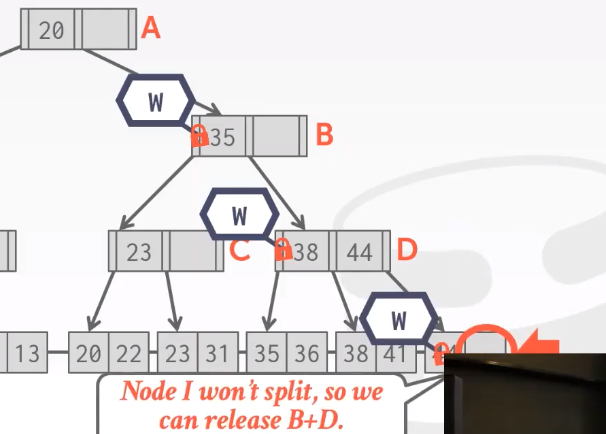
在D的时候不可以释放B,到最后插入的时候可以释放B and D。先B再D,提高效率
what’s the first step that all the update examples did on the B+ Tree?在Root上使用独占模式的latch或者写模式的latch进行加锁。 独占性(exclusive)
大多数的线程不需要对叶子节点进行拆分或者合并操作,所以拿read latch 而不是 write latch,在叶子节点使用write latch,判断需不需要拆分,不需要则拿read latch。如果在拆分或者merge的时候出错,abort在根节点重启,向下遍历这次获取write latch。
到达节点过程只拿read latch,执行删除的时候才去获取当前节点的write latch。
read latch会阻止任何人对这些节点进行写入和拆分操作
write latch则是阻止除了我之外的人对这些节点进行修改
通常情况下 在Page上使用悲观锁 效果比较好
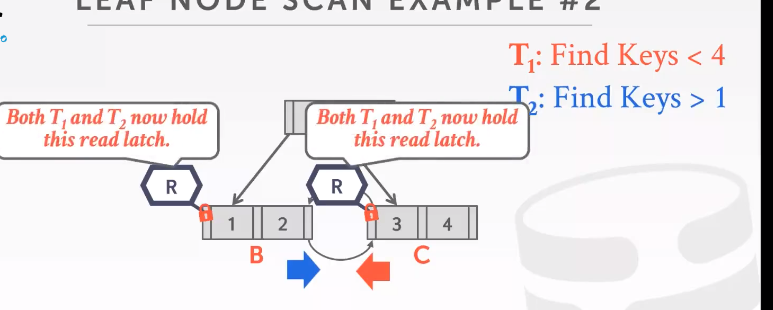
Leaf Node Scans
这些线程都是从上到下(Top-down)遍历,所以不会产生死锁。
如果是一条线程从上到下扫描,另外一条做叶子结点扫描。
和之前的crabbing一样,获得了下一个latch才释放之前拥有的。
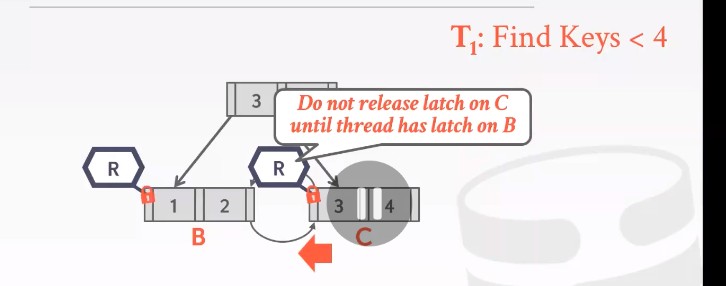
find 这种 read latch 不会deadlock
再来看T1 : delete 4 T2: find keys > 1
使用的是乐观锁机制latch coupling/crabbing 所以T1 T2都能拿到A的read latch。
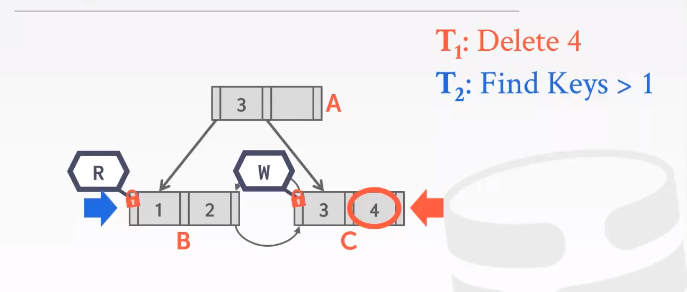
当子节点读锁和写锁冲突的时候,T2最好不要等待T1结束,因为不知道T1要多久也不知道会不会增加形成死锁的可能,所以最好的解决方案是abort and restart. /! 可能会遇到starvation的问题。
Delayed Parent Updates
处理overflow情况下可以使用的一种额外优化手段(BlinkTree 才加了兄弟指针,现在B+ tree基本都加兄弟指针了)
当任意时刻 某个叶子节点出现overflow情况,延迟对父节点的更新操作。只需要更新树中全局信息表中的一点内容,当有人遍历这棵树,再去更新父节点。
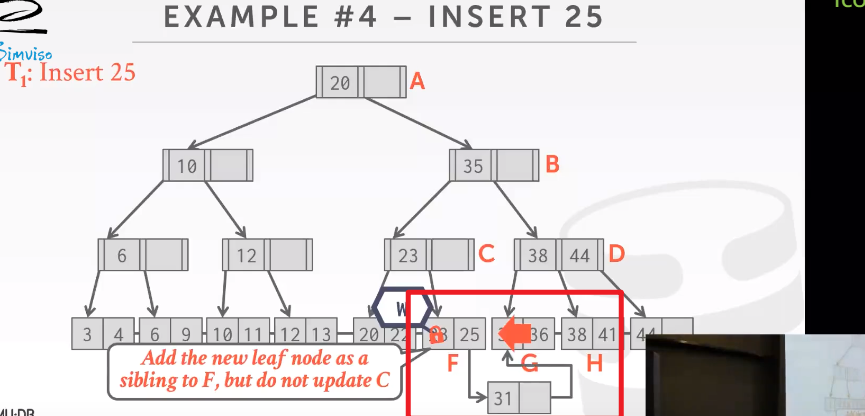
添加一个该树的全局表,有人用的时候再去执行这个ADD 31调整结构。拆分玩并且添加完新节点之后,紧接着要进行下次修改的线程会接受这个改变并且对内容进行更新。

notoriously 出名的