博主未授权任何人或组织机构转载博主任何原创文章,感谢各位对原创的支持!
博主链接
本人就职于国际知名终端厂商,负责modem芯片研发。
在5G早期负责终端数据业务层、核心网相关的开发工作,目前牵头6G算力网络技术标准研究。
博客内容主要围绕:
5G/6G协议讲解
算力网络讲解(云计算,边缘计算,端计算)
高级C语言讲解
Rust语言讲解
文章目录
- CUDA流
- CUDA流的概念
- CUDA流的分类
- CUDA流的创建和销毁
- 使用CUDA加速程序
- CUDA加速库
- CUDA加速库的使用方法
- 1. cuBLAS
- cuBLAS context
- Thread Safety
- Results reproducibility
- Parallelism with Streams
- Cache configuration
- 2.Thrust
- 3.CV-CUDA
- 4. NVIDIA cuNumeric
- 5.NVIDIA TensorRT
CUDA流
CUDA流的概念
- CUDA流在加速应用程序方面起到重要的作用,他表示一个GPU的操作队列,操作在队列中按照一定的顺序执行,也可以向流中添加一定的操作如核函数的启动、内存的复制、事件的启动和结束等,添加的顺序也就是执行的顺序;
- 一个流中的不同操作有着严格的顺序。但是不同流之间是没有任何限制的。多个流同时启动多个内核,就形成了网格级别的并行;
- CUDA流中排队的操作和主机都是异步的,所以排队的过程中并不耽误主机运行其他指令,所以这就隐藏了执行这些操作的开销
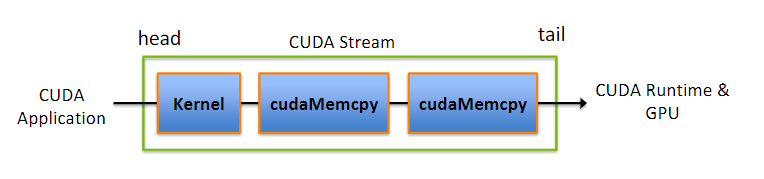
通过流可以实现:
- 重叠主机和设备计算
- 重叠主机计算和主机设备数据传输
- 重叠主机设备数据传输和设备计算
- 并发设备计算(多个设备)
但是无法实现:
- page-locked 主机内存的分配;
- 设备内存的分配;
- 将两个不同地址的数据传输到相同的设备地址;
• 任何对NULL stream的CUDA命令;
CUDA流的分类
- NULL stream:隐式分配的流;
- non-NULL stream:显示分配的流;
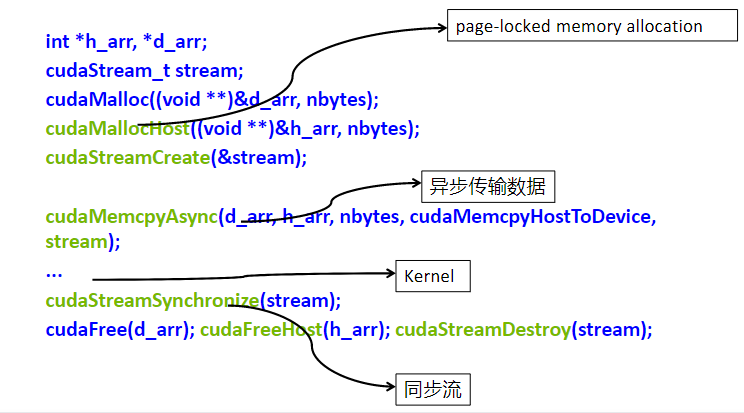
CUDA流的创建和销毁
// 定义一个流
cudaStream_t a;
// 创建一个流
cudaError_t cudaStreamCreate(cudaStream_t* pStream);
// 绑定一个流,指示在哪个流里面进行一个异步的数据传输
cudaError_t cudaMemcpyAsync(void* dst, const void* src, size_t count,cudaMemcpyKind kind, cudaStream_t stream = a);
// 指定核函数在哪个流上执行
kernel_name<<<grid, block, sharedMemSize, stream>>>(argument list);
// 销毁一个流
cudaError_t cudaStreamDestroy(cudaStream_t stream);
使用CUDA加速程序
例如,一个向量求和 A+B = C
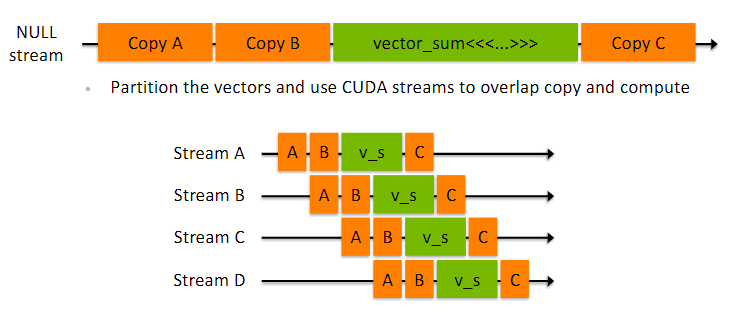
默认在NULL stream中所有操作都是串行的,通过使用多个流,将一个串行的操作并行化,可以看到上面使用了4个流,将向量求和分成了4个并行操作来执行,可以将运算速度提升4倍。
CUDA加速库
CUDA加速库的使用方法
- 创建一个库相关的handle,用于管理库相关操作的上下文信息;
- 为库函数的输入输出分配设备内存;
- 如果输入的数据格式不是CUDA库支持的格式,需要对数据格式进行转换;
- 使用支持的数据格式,初始化预分配的设备内存;
- 配置库计算的详细参数;
- 执行库计算,将计算卸载到GPU;
- 从设备内存获取计算结果;
- 可能涉及结果数据格式的转换;
- 释放CUDA资源;
- 继续执行程序剩余的操作;
1. cuBLAS
cuBLAS库是基于CUDA运行时的BLAS(Basic Linear Algebra Subprograms)实现的,cuBLAS库用于进行向量/矩阵运算,它包含两套API:
- cuBLAS API,需要用户自己分配GPU内存空间,按照规定格式填入数据;
- cuBLASXT API,可以分配数据在CPU端,然后调用函数,它会自动管理内存、执行计算;
Pyculib是一个包,它提供对几个数值库的访问,这些数值库针对NVidia GPU的性能进行了优化。
cuBLAS context
- 应用程序必须通过调用cublasCreate()函数初始化cuBLAS库上下文的句柄;
- 这种方法允许用户在使用多个主机线程和多个GPU时显式控制库设置;
Thread Safety
- 这个库是线程安全的,它的函数可以从多个主机线程调用,即使使用相同的句柄;
- 当多个线程共享同一个句柄时,在更改句柄配置时需要格外小心,因为该更改可能会影响所有线程中后续的CUBLAS调用;
- 因此,不建议多个线程共享相同的CUBLAS handle;
Results reproducibility
- 按照设计,来自给定工具包版本的所有CUBLAS API例程在每次运行时在具有相同架构和相同SMs数量的gpu上执行时都生成相同的位结果;
- 然而,由于实现可能会因一些实现更改而有所不同,因此不能保证跨工具包版本的逐位重现性;
Parallelism with Streams
- 如果应用程序使用多个独立任务计算的结果,则可以使用CUDA streams来重叠这些任务中执行的计算;
cudaStreamCreate()
cublasSetStream()
Cache configuration
在某些设备上,L1缓存和共享内存使用相同的硬件资源。可以使用CUDA运行时函数cudaDeviceSetCacheConfig直接设置缓存配置。还可以使用例程cudaFuncSetCacheConfig为某些函数专门设置缓存配置。
2.Thrust
Thrust是基于标准模板库(STL)的CUDA的C++模板库。Thrust允许您通过与CUDA C完全互操作的高级接口,以最少的编程工作实现高性能并行应用程序。Thrust提供了丰富的数据并行原语集合,例如扫描、排序和规约,它们可以组合在一起,以简洁、可读的源代码实现复杂的算法。通过用这些高级抽象描述您的计算,您可以让Thrust自由地自动选择最有效的实现。因此,Thrust可用于CUDA应用程序的快速原型设计(其中程序员的生产力最为重要),也可用于生产。
#include <thrust/host_vector.h>
#include <thrust/device_vector.h>
#include <thrust/sort.h>
#include <cstdlib>
int main(void)
{
// generate 32M random numbers on the host
thrust::host_vector<int> h_vec(32 << 20);
thrust::generate(h_vec.begin(), h_vec.end(), rand);
// transfer data to the device
thrust::device_vector<int> d_vec = h_vec;
// sort data on the device
thrust::sort(d_vec.begin(), d_vec.end());
// transfer data back to host
thrust::copy(d_vec.begin(), d_vec.end(), h_vec.begin());
return 0;
}
3.CV-CUDA
CV-CUDA 是一个开源项目,使开发人员能够在云规模的人工智能 (AI) 成像和计算机视觉 (CV)工作负载中构建高效、GPU 加速的预处理和后处理管道。借助一组针对数据中心 GPU 性能进行手动优化的专用 CV 和图像处理内核,CV-CUDA 可确保使用这些内核构建的处理管道得到执行,从而在整个复杂工作负载中提供更高的吞吐量。CV-CUDA 可以提供超过 10 倍的吞吐量改进和更低的云计算成本。 CV-CUDA 将提供与 C/C++、Python 的轻松集成,以及与 PyTorch 等常见深度学习 (DL) 框架的接口。
4. NVIDIA cuNumeric
将 GPU 加速的超级计算引入 NumPy 生态系统Python 已成为数据科学、机器学习和高效数值计算中使
用最广泛的语言。NumPy 是事实上的标准数学和矩阵库,提供简单易用的编程模型,其接口与科学应用的数学需求密切相关,使其成为许多最广泛使用的数据科学和机器学习的基础 构建学习编程环境。随着数据集规模的不断扩大和程序的复杂性不断增加,越来越需要通过利用远远超出单个 CPU 节点所能提供的计算资源来解决这些问题。
5.NVIDIA TensorRT