Hadoop生态圈中的数据同步工具SQOOP
- 一、sqoop的概念
- 二、sqoop的核心功能
- 1、数据导入import
- 2、数据导出export
- 三、sqoop的底层实现
- 四、sqoop的安装和部署
- 五、sqoop的基本操作
- 1、sqoop查看RDBMS中有哪些数据库
- 2、sqoop查看某一个数据库下有哪些数据表
- 3、通过sqoop执行sql语句
- 六、sqoop的核心功能操作
- 1、数据导入import
- 2、数据导出export
)
一、sqoop的概念
在大部分常见的软件中,比如淘宝、拼多多…,网站都会产生大量的数据
电商网站:订单数据、商品数据、分类数据、用户信息数据、用户行为数据等等
课程网站:订单数据、视频数据、课程数据、用户信息数据等等
…
虽然说不同领域的数据格式和数据含义不一样,但是他们都有一个公共点:数据大部分都是在RDBMS关系型数据库进行存放的。如果我们要对某一个领域的数据进行大数据的统计分析,首先我们必须先把数据从非大数据环境同步到大数据环境中。
大部分数据都是在RDBMS存放的,大数据环境大部分都是HDFS、Hive、HBase。我们需要把RDBMS的数据同步到大数据环境中。
SQOOP软件是Apache开源的顶尖项目,sqoop.apache.org 被设计用来在RDBMS和Hadoop(Hive、HDFS、HBase)之间进行数据传输的工具
因此sqoop的适用场景限制就非常大,因此这个技术基本很少更新了。软件基本已经从apache退役
二、sqoop的核心功能
1、数据导入import
指的是将数据从RDBMS(MySQL\ORACLE\SQL SERVER)导入到Hadoop环境(HDFS、HBASE、Hive)中
导入的作用就是将数据从非大数据环境导入到大数据环境通过大数据技术做统计分析的
2、数据导出export
指的是将数据从Hadoop环境(HDFS、Hive、HBase)导出到RDBMS中
将数据统计分析完成得到结果指标,指标在大数据环境存放的,如果对指标做可视化展示,数据在大数据环境下很难进行可视化展示的,因此我们需要把数据从大数据环境导出到非大数据环境RDBMS中进行可视化展示等后续操作
三、sqoop的底层实现
sqoop技术也是Hadoop生态的一部分,因为Sqoop进行导入和导出数据时,需要编写针对的导入和导出命令,但是这个命令底层也会转换成为MapReduce程序进行运行。
SQOOP运行基于MapReduce和YARN进行运行
四、sqoop的安装和部署
因此sqoop底层是基于Hadoop的,因此sqoop也是安装一个单节点的即可,sqoop也是提供了一个可以导入和导出数据的命令行客户端。
sqoop软件安装三部曲:
- 1、上传解压
- 2、配置环境变量 —— vim /etc/profile
- 3、修改软件的配置文件
- sqoop-env.sh文件

- 4、sqoop的特殊配置
- sqoop可以数据把数据在大数据和非大数据环境之间进行迁移的,非大数据环境主要是RDBMS关系型数据库
- sqoop连接RDBMS 底层也是基于JDBC进行连接的,因此如果要使用sqoop连接rdbms,我们需要把对应数据库的jdbc驱动程序jar包放到sqoop的lib目录下
- 需要把mysql-connector-java.jar 放到sqoop的lib目录下即可
五、sqoop的基本操作
需要跟数据库的连接参数
--connect jdbcurl
--username 用户名
--password 密码
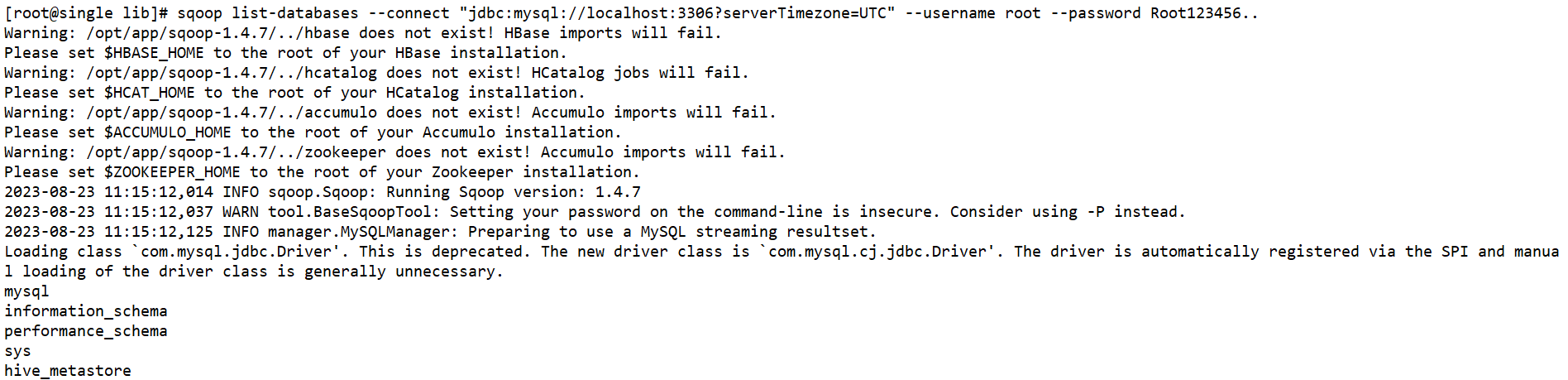
1、sqoop查看RDBMS中有哪些数据库
sqoop list-databases
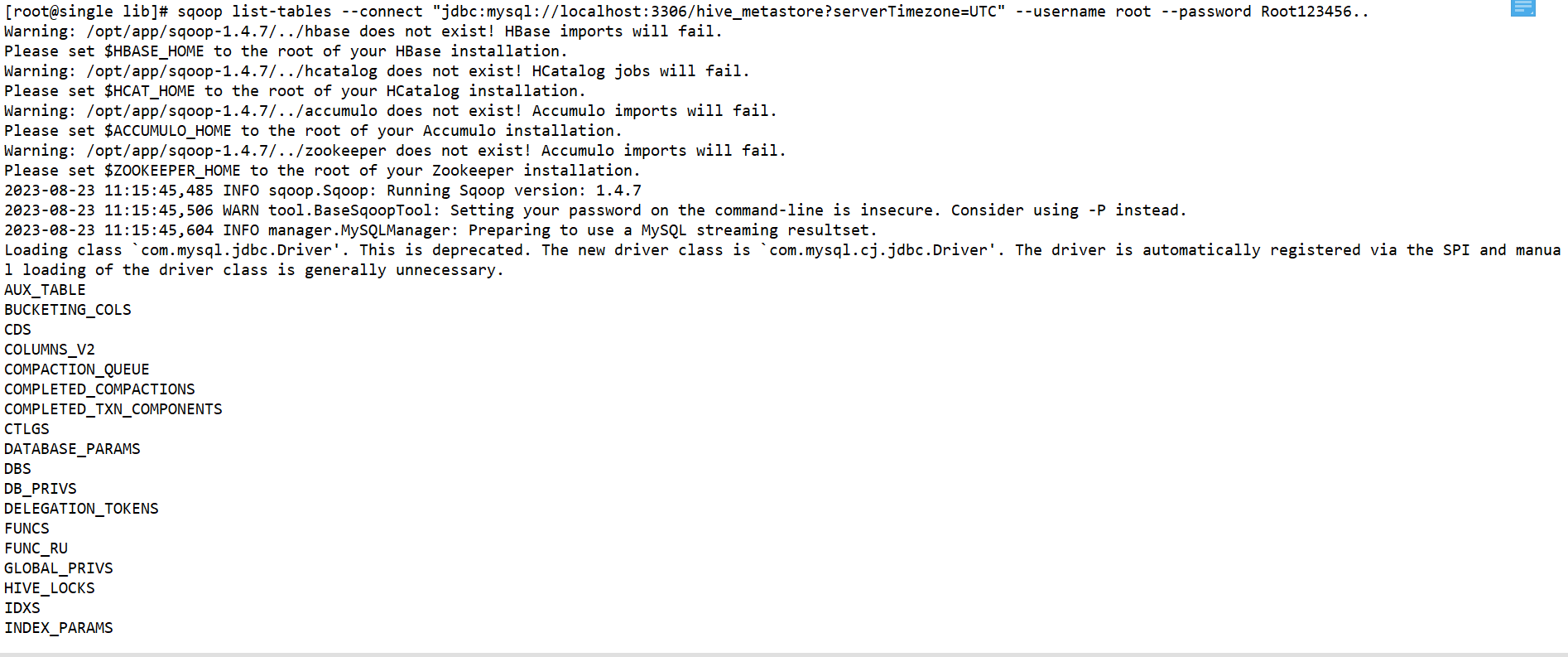
2、sqoop查看某一个数据库下有哪些数据表
sqoop list-tables
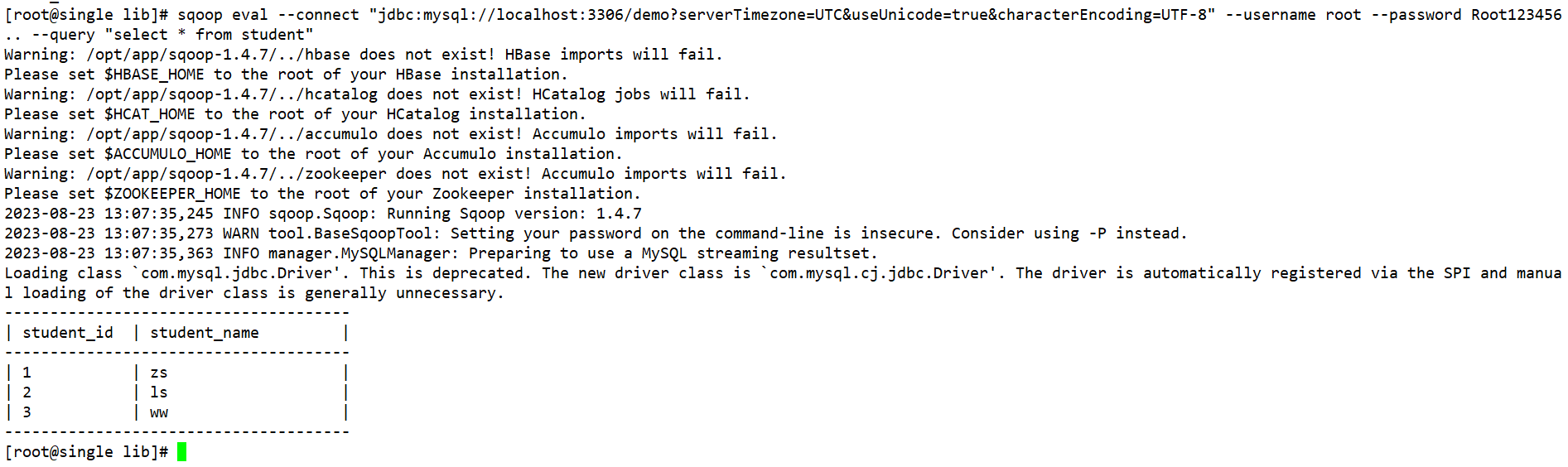
3、通过sqoop执行sql语句
sqoop eval --query | -e “sql”
六、sqoop的核心功能操作
1、数据导入import
-
指的是将数据从RDBMS关系型数据库导入到Hadoop环境中(HDFS、Hive、HBase)
-
将RDBMS的数据导入到HDFS中
不常用-
HDFS导入时连接的RDBMS的参数 --driver --connect --username --password [--table] 导入哪张数据表的数据 [--columns] 导入指定数据表的指定列的数据 [--query] 根据查询语句的结果导入数据 [--where] 筛选条件,根据指定的条件导入数据 HDFS导入的参数 --target-dir 导入到HDFS上的路径 --delete-target-dir 如果HDFS的路径存在 提前删除 [--as-textfile|sequencefile..] 导入到HDFS上的文件的格式 --num-mappers 指定导入的时候底层MapReduce启动多少个Map Task运行 --fields-terminated-by 指定导入的文件列和列的分隔符,默认是一种特殊字符,同时自动创建Hive数据表时,表的列的分隔符 --lines-terminated-by 指定导入的文件的行和行的分割符,默认就说换行符 一般是不使用这个参数的,就算我们设置了也不生效,除非我们加上一些特殊参数 --null-string:如果导入的MySQL数据表的某一个字符串类型的列的值为null,那么我们在HDFS的文件中使用什么字符替换null值 --null-non-string:如果导入的MySQL数据表的某一个非字符串类型的列的值为null,那么我们在HDFS的文件中使用什么字符替换null值 -
导入数据表的所有数据到HDFS: sqoop import --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --table student --target-dir /import --delete-target-dir --fields-terminated-by '=' --num-mappers 1 --as-sequencefile -
导入数据表的指定列的数据到HDFS: sqoop import --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --table student --columns student_name,student_age --target-dir /import --delete-target-dir --fields-terminated-by ',' --num-mappers 1 --as-textfile -
根据查询语句导入指定的数据到HDFS:
-
--table table_name --where "条件" 只能导入一张表的数据 sqoop import --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --table student --columns student_name,student_age --where "student_age<40" --target-dir /import --delete-target-dir --fields-terminated-by ',' --num-mappers 1 --as-textfile -
--query "" 可以通过连接查询同时导入多张表的数据 sqoop import --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=UTC&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --query 'select * from student where student_age<40 and $CONDITIONS' --target-dir /import --delete-target-dir --fields-terminated-by ',' --num-mappers | -n 1 --as-textfile
-
-
-
将RDBMS的数据导入到Hive数据表中 常用
-
导入参数
-
HDFS导入时连接的RDBMS的参数 --driver --connect --username --password [--table] 导入哪张数据表的数据 [--columns] 导入指定数据表的指定列的数据 [--query] 根据查询语句的结果导入数据 [--where] 筛选条件,根据指定的条件导入数据 -
导入到Hive中的参数 --hive-import 指定将数据导入到Hive的数据表,而非HDFS或者HBase --hive-database 指定将数据导入到Hive的哪个数据库中 --hive-table 指定将数据导入到Hive的哪个数据表中 --create-hive-table 如果Hive表没有提前存在,那么这个选项必须添加,会根据导入的数据自动推断创建Hive数据表,但是如果Hive中的数据表已经存在,那么这个参数一定不能添加 -
如果我们将RDBMS中的数据导入到Hive中,有两种导入模式
-
全量导入
第一次导入RDBMS的数据到Hive中- 将RDBMS对应的数据表中的数据全部导入Hive中
- –hive-overwrite参数 将RDBMS表中的所有数据(–table 如果加了–query --columns,就不是全量的问题)添加到Hive对应的数据表,而且覆盖添加。
- 一般使用在第一次将RDBMS的数据导入到Hive中,如果第一次导入不需要–hive-overwrite选项
如果不是第一次导入,还想全量导入,那么必须加–hive-overwrite选项
-
增量导入
非第一次导入RDBMS数据到Hive-
将RDBMS数据表对应增加的新的数据导入到Hive中
-
增量导入又分为两种方式:一种根据自增id导入,第二种根据一个时间戳增量导入
-
sqoop的增量导入有两种方式:append lastmodified,其中Hive的增量导入只支持append方式,HDFS增量导入支持lastmodified方式
-
--check-column RDBMS对应的列 --incremental append --last-value num上一次导入的自增的值的最后一个 -
根据RDBMS数据表的自增id导入:
–check-column rdbms数据表的自增列名 --incremental append --last-value num append增量导入需要指定RDBMS中一个可以自增或者是数字依次变大的一个列,同时还需要指定上一次导入的时候值的大小 -
根据RDBMS数据表的一个时间字段导入:
–check-column rdbms数据表的时间列 --incremental lastmodified --last-value “上一次导入的最后一条数据的时间戳”
-
-
-
-
全量导入:
如果要做全量导入,Hive的数据表可以不用提前存在,使用create-hive-table自动创建即可-
sqoop import --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=CST&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --table student --hive-import --hive-database test --hive-table student --create-hive-table
-
-
增量导入:
如果要做增量导入,Hive数据表必须提前存在,而且还具备RDBMS对应数据表的历史数据-
按照自增id增量导入
-
sqoop import --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=CST&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --table student --hive-import --hive-database test --hive-table student --check-column student_id --incremental append --last-value 5
-
-
按照创建时间增量导入
- hive-import目前还不支持时间戳增量的方式
-
-
注意:如果将数据导入到Hive中,sqoop一共做了两步操作:1、先通过MR程序把数据上传到HDFS上,2、使用hive的load装载命令将上传到HDFS上的数据文件加载到数据表中。3、如果Hive数据表不存在,那么在导入的时候可以指定–create-hive-table创建数据表,创建的数据表的列的分隔符和–fields-terminated-by设置的HDFS上文件的列的分隔符保持一致的。
sqoop操作Hive的时候,需要Hive的依赖,但是sqoop默认是没有hive的编程依赖的,因此sqoop迁移数据到hive会报错,如果不想报错,那么我们需要把hive-common.jar包复制到sqoop的lib目录下。 -
【导入数据时间字段的问题】
- 数据导入之后,RDBMS中的时间和Hive中时间不一致,主要由于时区的问题导致的,RDBMS使用的时区和导入数据时指定的时区参数不是同一个时区导致的问题。
- 只需要保证RDBMS的时区和导入参数设置的时区serverTimezone保持一致即可。
- RDBMS的时区:select @@global.time_zone
- 默认情况下,只要我们在中国,没有改过数据库和系统的时区,数据库和系统时区默认是+0800,因此serverTimezone=Asia/Shanghai
-
2、数据导出export
将Hadoop平台的数据导出到RDBMS中,导出比导入简单。导出数据时,因为Hive、HBase存储的数据都在HDFS上,因此导出只需要学习如何将HDFS上的数据导出到RDBMS即可。
【导出的注意事项】:RDBMS中的数据表必须提前存在,如果不存在,会报错
导出参数
导出时和RDBMS相关的参数
--driver:JDBC的驱动类
--connect:JDBCUrl
--username:数据库的用户名
--password:数据库的密码
--table: 指定导入RDBMS中哪个数据表的数据
--columns <col,col,col...>:代表的rdbms的列名,列名必须和文件中列的顺序保持一致,防止数据串列
导出HDFS的参数
--export-dir : 导出的HDFS哪个目录下的文件数据
--num-mappers | -m : 将导出命令翻译成为n个map task任务
--input-fields-terminated-by : 很重要,指定HDFS上文件中列和列的分隔符的
--input-lines-terminated-by : 指定HDFS上文件行和行的分割符 行的分隔符\n
--update-mode:取值allowinsert和updateonly,导出数据的两种模式
allowinsert 更新已经导出的数据,同时追加新的数据 对mysql数据库目前不支持的
updateonly 只更新以前导出的数据,新的数据不会导出
--update-key:--update-mode如果想实现它的功能,必须和--update-key结合使用,而且--update-key最好指定一个RDBMS的主键字段,否则--update-mode的效果会出现混乱
【注意】如果没有指定update-mode 那么默认是追加的形式导出(会出数据重复)
如果我们想要导出数据到MySQL,而且还不想让数据重复,可以先使用sqoop eval 操作执行清空目标表数据的命令,清空成功以后再导出数据。
sqoop eval --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=CST&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --query 'delete from student'
sqoop import --driver com.mysql.cj.jdbc.Driver --connect 'jdbc:mysql://single:3306/demo?serverTimezone=CST&useUnicode=true&characterEncoding=UTF-8' --username root --password Root123456.. --table student --export-dir /user/hive/warehouse/test.db/student --input-fields-terminated-by '=' -m 1 --columns 'student_id,student_name,student_age,create_time'
导入一般是我们需要对RDBMS的数据进行大数据处理分析时,我们把RDBMS的数据通过import导入到HDFS或者Hive,导出之后我们处理完成,得到结果数据表,然后把结果数据表通过export导出到RDBMS中,用于后期的数据可视化展示。