蒸馏(Knowledge Distillation)是一种将一个模型(通常称为教师模型)学习到的知识迁移到另一个模型(通常称为学生模型)的技术。通常,教师模型是一个复杂而准确的模型,而学生模型则是一个简化版本,旨在在减少模型复杂性的同时保持良好的性能。蒸馏方式可以大体分为三种:Response-based(基于输出的蒸馏),Feature-based(基于特征的蒸馏)和Relation-based(基于关系的蒸馏)。
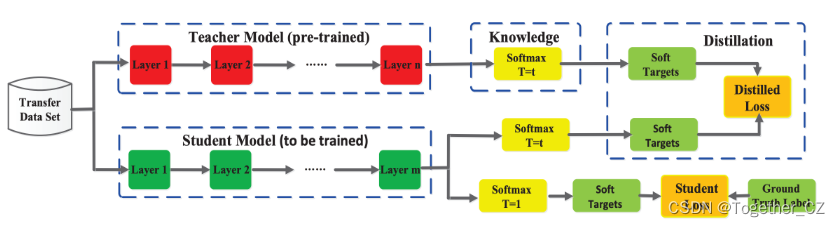
1)Response-based蒸馏:在Response-based蒸馏中,教师模型的输出被用作指导学生模型的训练目标。通常,这是通过将教师模型的输出概率分布(通常是软性目标)作为学生模型的训练目标来实现的。学生模型被训练以最小化其输出与教师模型输出之间的差异。这种方式的目标是使学生模型能够学习到教师模型的预测能力和知识。
优点:Response-based蒸馏相对简单,易于实现。通过使用教师模型的输出作为目标,可以帮助学生模型更好地拟合训练数据和教师模型的预测。
缺点:Response-based蒸馏仅利用了教师模型的输出,忽略了教师模型内部的知识表示。由于仅基于输出进行蒸馏,可能无法完全捕捉到教师模型的知识。
2)Feature-based蒸馏:在Feature-based蒸馏中,教师模型的隐藏层特征被用作指导学生模型的训练目标。学生模型被训练以最小化其隐藏层特征与教师模型隐藏层特征之间的差异。这种方式的目标是使学生模型能够学习到教师模型的表示能力和知识。
优点:Feature-based蒸馏可以帮助学生模型更好地理解输入数据,并从教师模型的隐藏层特征中获得更多的知识。通过使用教师模型的隐藏层特征,可以传递更丰富的信息给学生模型。
缺点:Feature-based蒸馏可能需要更多的计算资源和时间来训练学生模型,因为需要对教师模型和学生模型的隐藏层特征进行比较和匹配。
3)Relation-based蒸馏:在Relation-based蒸馏中,教师模型和学生模型之间的关系被用作指导学生模型的训练目标。这种方式的目标是通过最小化教师模型和学生模型之间的关系损失,使学生模型能够学习到教师模型的关系和知识。
优点:Relation-based蒸馏可以帮助学生模型更好地学习到教师模型的关系和知识。通过关系损失的最小化,学生模型可以更好地模仿教师模型的行为和决策。
缺点:Relation-based蒸馏可能需要更复杂的模型和训练过程,以建立和优化教师模型和学生模型之间的关系。这可能需要更多的计算资源和时间。
这些是蒸馏中常用的三种方式,每种蒸馏(Knowledge Distillation)是一种将一个模型(通常称为教师模型)学习到的知识迁移到另一个模型(通常称为学生模型)的技术。通常,教师模型是一个复杂而准确的模型,而学生模型则是一个简化版本,旨在在减少模型复杂性的同时保持良好的性能。
如果从构建策略的差异来进行划分的话,蒸馏策略则可以分为:
1)online distillation
2)offline distillation
3)self distillation接下来整体总结对比一下上述三种不同的蒸馏策略对应的原理与优缺点。
Online Distillation(在线蒸馏):
在线蒸馏是一种训练过程中进行知识蒸馏的方法。它通过将教师模型(T模型)的输出作为目标,动态地指导学生模型(S模型)的学习。
* 原理实现:在训练过程中,教师模型对每个输入进行预测,并将预测结果作为标签提供给学生模型。然后,学生模型通过最小化其预测与教师模型的预测之间的差异(如Kullback-Leibler散度或均方误差)来更新其参数。
* 优点:可以动态地指导学习过程,允许学生模型在训练过程中适应教师模型的策略。此外,由于教师模型是实时参与训练的,因此可以随时更新和优化教师模型的性能。
* 缺点:需要教师模型实时参与训练,因此增加了计算开销。此外,如果教师模型的性能较差,可能会影响学生模型的最终性能。Offline Distillation(离线蒸馏):
离线蒸馏是一种在训练结束后,使用教师模型和学生模型的输出来计算知识蒸馏损失的方法。
* 原理实现:在训练结束后,教师模型和学生模型都会对每个输入进行预测。然后,通过比较这两个模型的预测结果(如Kullback-Leibler散度或均方误差)来计算损失,并使用该损失来优化学生模型的参数。
* 优点:可以在训练结束后进行知识蒸馏,因此教师模型和学生模型都可以使用任何训练策略或算法。
* 缺点:由于训练完成后进行蒸馏,因此无法在训练过程中实时指导学习。此外,如果训练完成后教师模型的性能较差,那么蒸馏的效果也会受到影响。Self Distillation(自我蒸馏):
自我蒸馏是一种特殊类型的蒸馏技术,它通过训练学生模型来复制其自身的行为。
* 原理实现:首先,学生模型对输入进行预测,并将预测结果存储为“教师”标签。然后,学生模型尝试复制“教师”标签的行为,通过最小化其自身预测和“教师”标签之间的差异(如交叉熵损失)来进行训练。
* 优点:不需要外部教师模型,可以完全独立地进行训练。此外,由于学生模型复制其自身的行为,所以它可以适应其自身的策略和决策方式。
* 缺点:由于没有外部教师模型的指导,所以可能需要更多的训练时间和计算资源。此外,学生模型的性能可能受到其自身能力的限制。按照蒸馏算法的不同可以分为:
1)adversarial distillation
2)multi-teacher distillation
3)cross-modal distillation
4)graph-based distillation
5)attention-based distillation
6)data-free distillation
7)quatized Distillation
8)lifelong distillation
9)nas distillation 接下来来对应详细分析下各种算法的详细构建方法:
1)对抗蒸馏(Adversarial Distillation):
对抗蒸馏是一种将教师模型的知识迁移到学生模型的蒸馏方法。其主要思想是引入对抗训练过程,以提高知识传递的效果。关键在于使用一个鉴别器网络来区分教师模型的软标签和学生模型的预测结果。学生模型被训练生成预测结果,使得鉴别器难以区分其与教师模型的预测结果。
优点:
- 对抗蒸馏鼓励学生模型生成更加真实的预测结果,提高了知识的迁移效果。
- 通过引入对抗性训练,可以增强学生模型对教师模型知识的理解和学习能力。
缺点:
- 对抗蒸馏方法的训练过程相对较复杂,需要同时训练学生模型和鉴别器网络,增加了计算和训练的开销。
2)多教师蒸馏(Multi-Teacher Distillation):
多教师蒸馏是一种将多个教师模型的知识结合到学生模型中的蒸馏方法。在多教师蒸馏中,多个教师模型共同为学生模型提供指导和知识。
优点:
- 多教师蒸馏可以结合不同教师模型的优点,提供更多样化和全面的知识指导。
- 多个教师模型之间可以相互补充,提高了知识的覆盖范围和准确性。
缺点:
- 多教师蒸馏可能增加了计算和存储的开销,因为需要同时处理多个教师模型的知识。
- 教师模型之间的差异可能导致知识的冲突,需要进行适当的融合和处理。
3)跨模态蒸馏(Cross-Modal Distillation):
跨模态蒸馏是一种将不同模态(如图像和文本)之间的知识迁移到学生模型中的蒸馏方法。通过跨模态蒸馏,可以将一个模态中的知识迁移到另一个模态中,实现模态之间的知识共享和迁移。
优点:
- 跨模态蒸馏可以利用不同模态之间的相关性,提高学生模型在不同模态下的表现。
- 跨模态蒸馏可以实现模态间的知识迁移,减少在不同模态下的数据需求和训练成本。
缺点:
- 跨模态蒸馏可能需要额外的模态间对齐和融合方法,增加了蒸馏过程的复杂性。
- 不同模态之间的差异和特点可能导致知识的丢失或不准确性。
4)基于图的蒸馏(Graph-based Distillation):
基于图的蒸馏是一种利用图结构来表示和迁移知识的蒸馏方法。通过构建图结构,将教师模型的知识编码为图中的节点和边,然后将这些知识迁移到学生模型对应的图结构中。
优点:
- 基于图的蒸馏可以更好地捕捉知识之间的关系和依赖关系,提高知识的迁移效果缺点:
- 基于图的蒸馏可能需要额外的图构建和表示方法,增加了蒸馏过程的复杂性和计算开销。
- 图结构的构建和表示可能存在一定的主观性和不确定性,影响知识的准确性和完整性。
5)基于注意力的蒸馏(Attention-based Distillation):
基于注意力的蒸馏是一种利用教师模型的注意力机制来引导学生模型学习的蒸馏方法。通过计算教师模型的注意力权重,将其作为学生模型的注意力目标,从而指导学生模型更好地学习和关注重要的特征和信息。
优点:
- 基于注意力的蒸馏可以提高学生模型对重要特征和信息的关注度,改善学生模型的性能。
- 注意力机制可以提供更细粒度的知识指导,有助于学生模型更好地理解和学习教师模型的知识。
缺点:
- 基于注意力的蒸馏可能增加了计算和存储开销,因为需要计算和传递注意力权重。
- 注意力的引导可能局限于教师模型的注意力机制,忽略了学生模型自身的特点和潜在能力。
6)无数据蒸馏(Data-free Distillation):
无数据蒸馏是一种在没有访问原始训练数据的情况下进行蒸馏的方法。通过在教师模型上生成合成数据,然后使用这些合成数据来训练学生模型,实现知识的迁移。
优点:
- 无数据蒸馏可以在没有访问原始数据的情况下进行知识迁移,解决了数据隐私和访问限制的问题。
- 通过合成数据,可以灵活地控制和调整训练样本的分布和属性,提高蒸馏的效果。
缺点:
- 无数据蒸馏方法的合成数据可能无法完全代表原始数据的分布和特征,导致知识的失真或丢失。
- 生成合成数据的过程可能需要复杂的方法和模型,增加了蒸馏过程的复杂性和计算开销。
7)量化蒸馏(Quantized Distillation):
量化蒸馏是一种将教师模型的浮点权重转化为低精度表示(如二值化或多位量化),并将这种低精度表示的权重作为学生模型的目标进行训练的蒸馏方法。
优点:
- 量化蒸馏可以减少学生模型的存储和计算开销,提高模型在资源受限环境下的效率。
- 通过将教师模型的权重量化,可以提供更紧凑和高效的知识表示,促进知识的传递和学习。
缺点:
- 量化蒸馏可能导致知识的损失和精度下降,特别是在极端量化(如二值化)的情况下。
- 量化过程可能需要设计和调整合适的量化策略和方法,增加了蒸馏过程的复杂性。
8)终身蒸馏(Lifelong Distillation):
终身蒸馏(Lifelong Distillation)是一种利用连续学习(Continual Learning)方法进行知识蒸馏的技术。在终身蒸馏中,教师模型的知识被用于指导学生模型的训练,并且这种知识的传递可以在学生模型不断接收新任务和数据时进行。
终身蒸馏的主要目标是在学生模型的训练过程中保持知识的积累和迁移。当学生模型面临新的任务时,教师模型的知识可以帮助学生模型更好地适应新任务,避免忘记之前学到的知识。
优点:
- 终身蒸馏可以实现知识的持续积累和迁移,使得学生模型能够在不断接收新任务和数据的情况下持续学习,而不会忘记之前学到的知识。
- 教师模型的知识可以指导学生模型的学习过程,帮助学生模型更快地适应新任务。
缺点:
- 终身蒸馏可能需要更复杂的模型和算法,以处理不断变化的任务和数据。
- 教师模型的知识传递可能受限于任务之间的差异性,某些任务的知识可能不太适用于其他任务。
9)NAS蒸馏(NAS Distillation):
NAS蒸馏是一种利用神经架构搜索(NAS)方法来辅助学生模型的设计和训练的蒸馏方法。在NAS蒸馏中,使用教师模型的知识来指导学生模型的神经架构搜索过程,从而得到更优的学生模型。
优点:
- NAS蒸馏可以通过引入教师模型的知识,加速神经架构搜索的过程,减少搜索空间,从而提高学生模型的性能。
- 教师模型的知识可以作为一种启发式引导,帮助学生模型更好地探索和选择适合的神经架构。
缺点:
- NAS蒸馏可能增加了计算和训练的开销,因为需要进行神经架构搜索和蒸馏过程。
- 教师模型的知识可能受限于当前搜索空间和搜索算法的限制,导致学生模型无法达到最优性能。