目录
一、理论
1.pod的资源限制
2.健康检查(探针Probe)
3.示例
二、实验
1.pod的资源限制
2.健康检查(探针Probe)
三、问题
1.生成资源报错
2.api版本错误
3.echo N>/proc/sys/vm/drop_caches如何实现清理缓存
四、总结
一、理论
1.pod的资源限制
(1)概念
① pod的计算资源
在配置Pod时,我们可以为其中的每个容器指定需要使用的计算资源(CPU和内存)。计算资源的配置项分为两种:Requests和Limits。
Requests表示容器希望被分配到的、可完全保证的资源量(资源请求量);
Limits是容器最多能使用的资源量的上限(资源限制量)。
当为Pod中的容器指定了request资源时,调度器就使用该信息来决定将Pod调度到哪个节点上。当还为容器指定了limit资源时, kubelet就会确保运行的容器不会使用超出所设的limit资源量。kubelet还会为容器预留所设的request资源量, 供该容器使用。
如果Pod运行所在的节点具有足够的可用资源,容器可以使用超出所设置的request资源量。不过,容器不可以使用超出所设置的limit资源量
资源请求量能够保证Pod有足够的资源来运行,资源限制量则是防止某个Pod无限制地使用资源,导致其他Pod崩溃。
我们创建一个pod时,可以指定容器对CPU和内存的资源请求量及资源限制量,它们并不在pod里定义,而是针对每个容器单独指定。
pod对资源的请求量和限制量是它所包含的所有容器的请求量和限制量之和。
② CPU和内存的Requests和Limits的特点
Requests和Limits都是可选的。在Pod创建和更新时,如果未设置Requests和Limits,则使用系统提供的默认值,该默认值取决于集群配置。
如果Requests没有配置,默认被设置等于Limits。
requests 是创建容器时需要预留的资源量。如果无法满足,则pod 无法调度。但是,这不是容器运行实际使用的资源,容器实际运行使用的资源可能比这个大,也可能比这个小。
Limit 是限制pod容器可以使用资源的上限。容器使用的资源无法高于这个限制任何情况下Limits都应该设置为大于或等于Requests。
(2)pod通信
同一个pod 里的容器之间通信使用IPC进行通信(进程间通信),通过localhost找到彼此
同一个node节点上的pod的通信使用虚拟网桥docker0进行通信
不同node节点上的pod 通信可以借助CNI(Container Network Interface)插件进行通信。如Flannel,calico等
(2)示例
官网示例:https://kubernetes.io/zh/docs/concepts/configuration/manage-resources-containers/
Pod和容器的资源请求和限制:
spec.containers[].resources.limits.cpu #定义cpu的资源上限
spec.containers[].resources.limits.memory #定义内存的资源上限
spec.containers[].resources.limits.hugepages-<size> #定义hugepages的资源上限
spec.containers[].resources.requests.cpu #定义创建容器时预分配的CPU资源
spec.containers[].resources.requests.memory #定义创建容器时预分配的内存资源
spec.containers[].resources.requests.hugepages-<size> #定义创建容器时预分配的巨页
(4)CPU 资源单位
CPU资源的request和limit以cpu为单位。Kubernetes中的一个cpu相当于1个VCPU (1个超线程)
Kubernetes也支持带小数CPU的请求。spec.containers [].resources.requests.cpu为0.5的容器能够获得一个cpu的一半CPU资源(类似于cgroup对CPU资源的时间分片)。表达式0.1等价于表达式100m (毫核) ,表示每1000毫秒内容器可以使用的CPU时间总量为0.1*1000毫秒。
(5)内存资源单位
内存的request和limit以字节为单位。可以以整数表示,或者以10为底数的指数的单位(E、P,T,G,M,K)来表示,或者以2为底数的指数的单位(Ei, Pi,Ti,Gi、Mi, Ki)来表示。
如: 1KB-10^3-1000, 1MB-10^6-1000000-1000KB, 1GB=10^9-1000000000-1000MB
1KiB-2^10-1024, 1MiB-2 20-1048576-1024KiB
备注:在买硬盘的时候,操作系统报的数量要比产品标出或商家号称的小一些,主要原因是标出的是以MB, GB为单位的, 1GB就是1,000,000, 000Bte ,而操作系统是以2进制为处理单位的,因此检查硬盘容量时是以MiB, GiB为单位, 1GB-2^30-1,073, 741, 824,相比较而言,1GiB要比1GB多出1,073, 741, 824-1, 000, 000, 000-73, 741, 824Byte,所以检测实际结果要比标出的少一些。
(6)示例
#先在每个节点上清空内存
echo 1 > /proc/sys/vm/drop_caches
echo 2 > /proc/sys/vm/drop_caches
echo 3 > /proc/sys/vm/drop_caches
free -m
[root@master ~]# vim demo1.yaml
apiVersion: v1
kind: Pod
metadata:
name: frontend
spec:
containers:
- name: web
image: nginx
env:
- name: WEB_ROOT_PASSWORD
value: "password"
resources:
#此容器预分配资源:内存为 64Mi ; 每个cpu 分配250m
requests:
memory: "64Mi"
cpu: "250m"
#此容器限制使用资源(最大): 内存最大使用128Mi,每个cpu最大分配500m
limits:
memory: "128Mi"
cpu: "500m"
- name: db
image: mysql
env:
- name: MYSQL_ROOT_PASSWORD
value: "abc123"
resources:
#此容器的预分配资源:内存预分配为512Mi;cpu预分配为每个cpu的50%,即1000*50%=500m
requests:
memory: "512Mi"
cpu: "0.5"
#此容器的限制使用资源配额为:内存最大使用1Gi;cpu最大使用1000m
limits:
memory: "1Gi"
cpu: "1"
#pod有两个容器,web 和db。所以,总的请求资源和限制资源为 web 和db 请求,限制资源总和。
#其中,cpu 的资源请求和限制,是以单个cpu 资源进行计算的。如果有多个cpu,则最终的结果是数值*N
[root@master ~]# kubectl apply -f demo1.yaml
[root@master ~]# kubectl get pod
[root@master ~]# kubectl describe pod frontend
# 查看pod的详细信息,查看pod被调度到了哪个node节点
[root@master ~]# kubectl get pod -o wide
#查看node01 节点的信息
[root@master ~]# kubectl describe nodes node01
2.健康检查(探针Probe)
(1)探针的三种规则
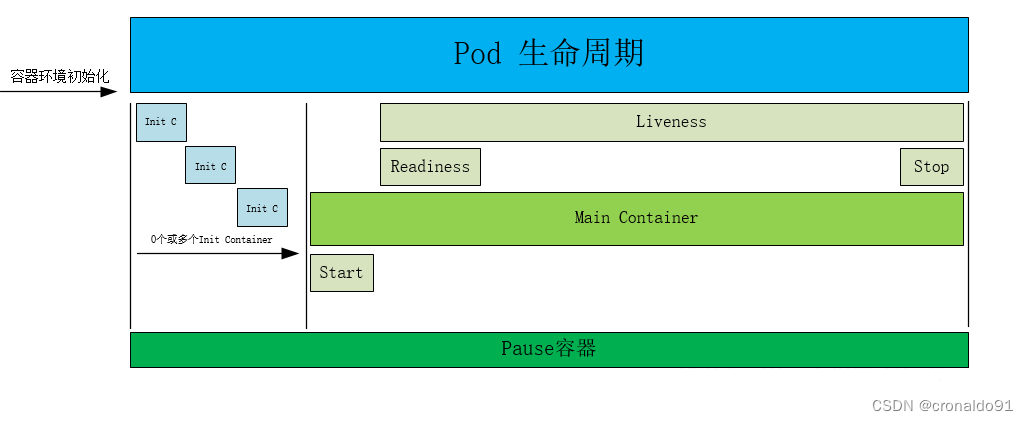
健康检查,又名 探针(Probe):探针是由kubelet对容器执行定期诊断。
探针有三种规则:
livenessProbe: 判断容器是否正在运行。如果探测失败,则kubelet会杀死容器,并且容器将根据 restartPolicy 来设置Pod状态。如果容器不提供存活探针,则默认状态为Success
readinessProbe: 判断容器是否准备好接受请求。如果探测失败,端点控制器将从Pod匹配的所有service endpoints中剔除该Pod的IP地址。初始延迟之前的就绪状态默认我为Failure.如果容器不提供就绪探针,则默认状态为success。
startupProbe(1.17版本新增):判断容器内的应用程序是否已经启动,主要针对于不能确定具体启动时间应用。如果配置了startupProbe探测,则在startuProbe状态为success 之前,其他所有探针都处于无效状态,知道它成功后其他探针才起作用。如果startupProbe失败,kubelet将杀死容器你,容器将根据restartPolicy来重启。如果容器没有配置startupProbe,则默认状态为Success。
注:以上规则可以同时定义。在readinessProbe检测成功之前,Pod的running状态是不会变成ready状态。
(2)Probe支持的三种检查方法
exec: 在容器内执行命令。如果命令退出时返回码为0 ,则认为诊断成功
tcpSocket: 对指定端口上的容器IP 地址进行TCP 检查(三次握手)。 如果端口打开,则诊断被认为是成功的
httpGet: 对指定端口和路径上的容器的IP地址执行HTTPGET请求。如果响应的状态码大于等于200,且小于400,则诊断被认为是成功的。
(3)探测获得的三种结果
每次探测,都将会获得以下三种结果之一:
成功: 容器通过了诊断
失败: 容器未通过诊断
未知:诊断失败,因此不会采取任何行动3.示例
(1) 示例1 exec方式
①exec 官网示例
配置存活、就绪和启动探针 | Kubernetes
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-exec
spec:
containers:
- name: liveness
image: k8s.gcr.io/busybox
args:
- /bin/sh
- -c
- touch /tmp/healthy; sleep 30; rm -rf /tmp/healthy; sleep 600
livenessProbe:
exec:
command:
- cat
- /tmp/healthy
initialDelaySeconds: 5
periodSeconds: 5
探针可选的参数:
initialDelayseconds:容器启动多少秒后开始执行探测。最小值为0
periodSeconds:探测的周期频率,每多少秒执行一次探测默认是10秒,最小值为1
failureThreshold:探测失败后,允许再试几次。
timeoutSeconds :探测等待超时的时间。默认为1 秒,最小值为1 秒
在这个配置文件中,可以看到 Pod 中只有一个容器。
periodSeconds 字段指定了 kubelet 应该每 5 秒执行一次存活探测。
initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 5 秒。
kubelet 在容器内执行命令 cat /tmp/healthy 来进行探测。 如果命令执行成功并且返回值为 0,kubelet 就会认为这个容器是健康存活的。 如果这个命令返回非 0 值,kubelet 会杀死这个容器并重新启动它。
②编写示例,查看
[root@master ~]#vim exec.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-exec
namespace: default
spec:
containers:
- name: liveness-exec-container
image: busybox
imagePullPolicy: IfNotPresent
command: ["/bin/sh","-c","touch /tmp/live ; sleep 30; rm -rf /tmp/live; sleep 3600"]
#存活检查探针,使用exec的方式,进入容器内部,检测是否有文件或目录/tmp/live
livenessProbe:
exec:
command: ["test","-e","/tmp/live"]
initialDelaySeconds: 1
periodSeconds: 3
#创建pod
[root@master ~]# kubectl create -f exec.yaml
#跟踪查看pod 信息
[root@master ~]# kubectl get pod -o wide -w
#新开一个终端,查看pod 的详细信息
[root@master ~]# kubectl describe pod liveness-exec
(2)示例2 httpGet方式
① 官方示例
apiVersion: v1
kind: Pod
metadata:
labels:
test: liveness
name: liveness-http
spec:
containers:
- name: liveness
image: k8s.gcr.io/liveness
args:
- /server
livenessProbe:
httpGet:
path: /healthz
port: 8080
httpHeaders:
- name: Custom-Header
value: Awesome
initialDelaySeconds: 3
periodSeconds: 3
在这个配置文件中,可以看到 Pod 也只有一个容器。 periodSeconds 字段指定了 kubelet 每隔 3 秒执行一次存活探测。 initialDelaySeconds 字段告诉 kubelet 在执行第一次探测前应该等待 3 秒。 kubelet 会向容器内运行的服务(服务会监听 8080 端口)发送一个 HTTP GET 请求来执行探测。 如果服务器上 /healthz 路径下的处理程序返回成功代码,则 kubelet 认为容器是健康存活的。 如果处理程序返回失败代码,则 kubelet 会杀死这个容器并且重新启动它。
任何大于或等于 200 并且小于 400 的返回代码标示成功,其它返回代码都标示失败。
② 编写httpGet 示例
[root@master ~]# vim httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: liveness-httpget
namespace: default
spec:
containers:
- name: liveness-httpget-container
image: soscscs/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
#创建pod
[root@master ~]# kubectl create -f httpget.yaml
#删除pod里容器的文件
[root@master ~]# kubectl exec -it liveness-httpget -- rm -rf /usr/share/nginx/html/index.html
#查看pod 状态和 详细信息
[root@master ~]# kubectl get pods
[root@master ~]# kubectl describe pod liveness-httpget
(3)示例3 ,tcpSocket 方式
① 官方示例
apiVersion: v1
kind: Pod
metadata:
name: goproxy
labels:
app: goproxy
spec:
containers:
- name: goproxy
image: k8s.gcr.io/goproxy:0.1
ports:
- containerPort: 8080
readinessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 5
periodSeconds: 10
livenessProbe:
tcpSocket:
port: 8080
initialDelaySeconds: 15
periodSeconds: 20
如你所见,TCP 检测的配置和 HTTP 检测非常相似。 下面这个例子同时使用就绪(readinessProbe)和存活(livenessProbe)探测器。
kubelet 会在容器启动 5 秒后发送第一个就绪探测。 这会尝试连接 goproxy 容器的 8080 端口。 如果探测成功,这个 Pod 会被标记为就绪状态,kubelet 将继续每隔 10 秒运行一次检测。
除了就绪探测,这个配置包括了一个存活探测。 kubelet 会在容器启动 15 秒后进行第一次存活探测。 与就绪探测类似,会尝试连接 goproxy 容器的 8080 端口。 如果存活探测失败,这个容器会被重新启动。
② 编写tcpSocket 方式示例
[root@master ~]# tcpsocket.yaml
apiVersion: v1
kind: Pod
metadata:
name: probe-tcp
spec:
containers:
- name: nginx
image: soscscs/myapp:v1
livenessProbe:
initialDelaySeconds: 5
timeoutSeconds: 1
tcpSocket:
port: 8080
periodSeconds: 3
[root@master ~]# kubectl create -f tcpsocket.yaml
#查看容器里的端口(查看有无8080端口)
[root@master ~]# kubectl exec -it probe-tcp -- netstat -natp
#查看pod的状态和详细信息
[root@master ~]# kubectl get pods
[root@master ~]# kubectl describe pod probe-tcp
(4)示例4 配置就绪探测 httpGet的方式
[root@master ~]# vim readiness-httpget.yaml
apiVersion: v1
kind: Pod
metadata:
name: readiness-httpget
namespace: default
spec:
containers:
- name: readiness-httpget-container
image: soscscs/myapp:v1
imagePullPolicy: IfNotPresent
ports:
- name: http
containerPort: 80
readinessProbe:
httpGet:
port: 80
path: /index1.html
initialDelaySeconds: 1
periodSeconds: 3
livenessProbe:
httpGet:
port: http
path: /index.html
initialDelaySeconds: 1
periodSeconds: 3
timeoutSeconds: 10
# 创建pod
[root@master ~]# kubectl create -f readiness-httpget.yaml
#查看pod的详细信息
[root@master ~]# kubectl get pod -w
[root@master ~]# kubectl describe pod readiness-httpget
#此时,因为容器里没有 index1.html文件,所以,httpGet的就绪探测失败
[root@master ~]# kubectl exec -it readiness-httpget -- ls /usr/share/nginx/html
#进入容器,创建index1.html,让就绪探测成功
[root@master ~]# kubectl exec -it readiness-httpget sh
/ # cd /usr/share/nginx/html/
/usr/share/nginx/html # ls
50x.html index.html
/usr/share/nginx/html # echo abc > index1.html
/usr/share/nginx/html # exit
[root@master ~]# kubectl get pods
(5) 就绪探测示例2
[root@master ~]# vim readiness-myapp.yaml
apiVersion: v1
kind: Pod
metadata:
name: myapp1
labels:
app: myapp
spec:
containers:
- name: myapp
image: soscscs/myapp:v1
ports:
- name: http
containerPort: 80
readinessProbe:
httpGet:
port: 80
path: /index.html
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 10
---
apiVersion: v1
kind: Pod
metadata:
name: myapp2
labels:
app: myapp
spec:
containers:
- name: myapp
image: soscscs/myapp:v1
ports:
- name: http
containerPort: 80
readinessProbe:
httpGet:
port: 80
path: /index.html
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 10
---
apiVersion: v1
kind: Pod
metadata:
name: myapp3
labels:
app: myapp
spec:
containers:
- name: myapp
image: soscscs/myapp:v1
ports:
- name: http
containerPort: 80
readinessProbe:
httpGet:
port: 80
path: /index.html
initialDelaySeconds: 5
periodSeconds: 5
timeoutSeconds: 10
---
apiVersion: v1
kind: Service
metadata:
name: myapp
spec:
selector:
app: myapp
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
所有的自主式Pod,name不可以相同。但是使用同一个标签myapp。 service通过标签选择器和对应标签的pod关联:
[root@master ~]# kubectl create -f readiness-myapp.yaml
#查看这些资源的详细信息。
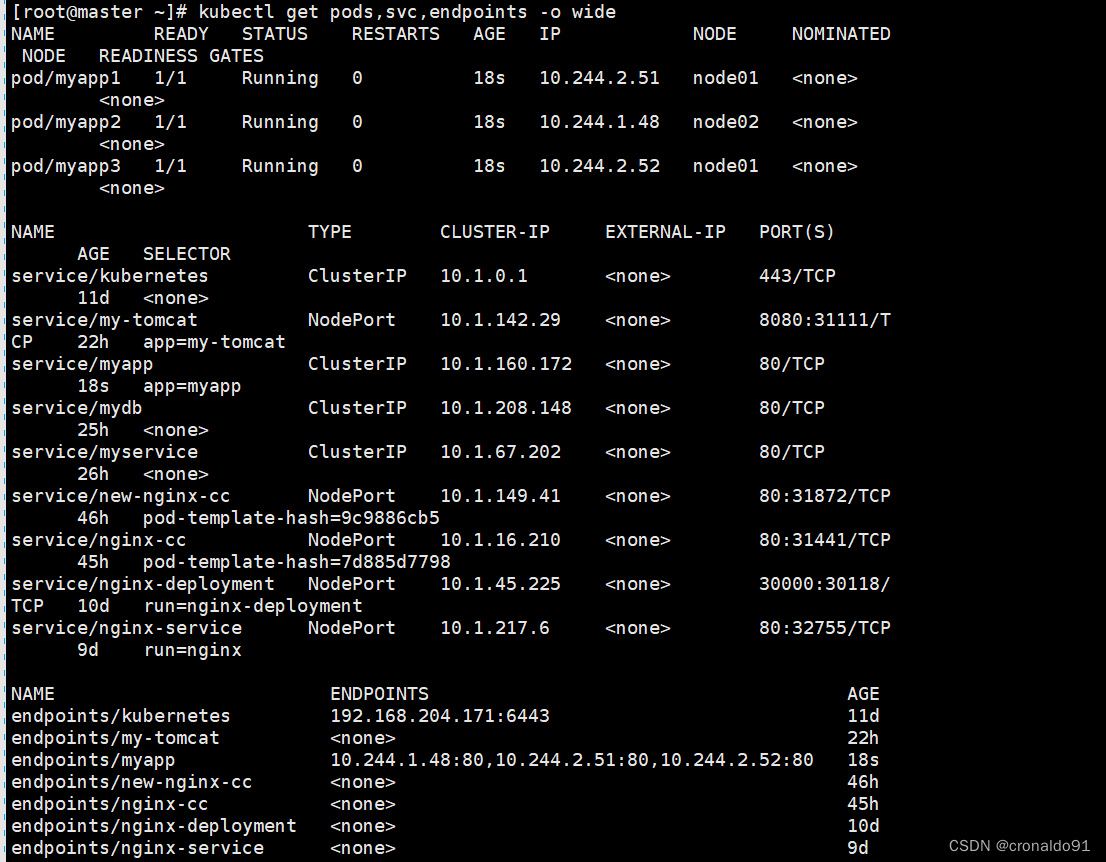
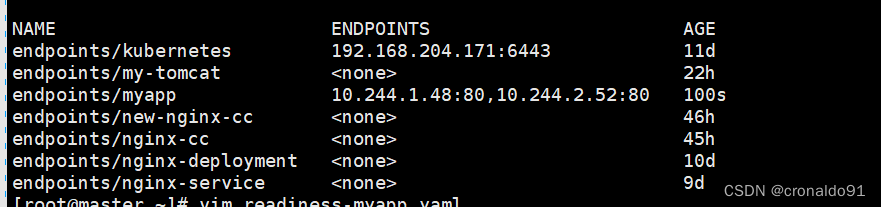
[root@master ~]# kubectl get pods,svc,endpoints -o wide
#删除myapp1的 index.html文件,让就绪探测 失败
[root@master ~]# kubectl exec -it myapp1 -- rm -rf /usr/share/nginx/html/index.html
# 查看发现,就绪探测失败的pod被从关联的service中移除ip
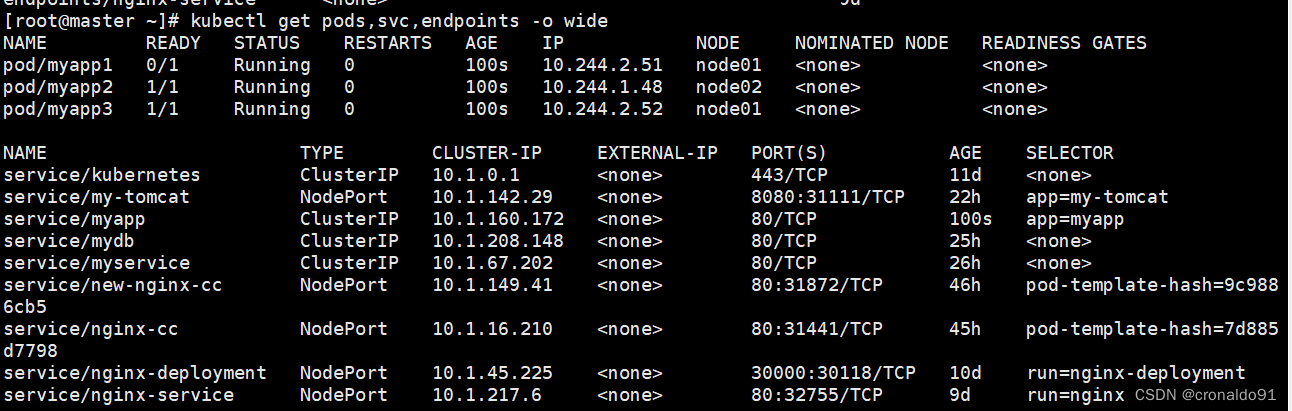
[root@master ~]# kubectl get pods,svc,endpoints -o wide
二、实验
1.pod的资源限制
(1) 先在每个节点上清空内存
master节点
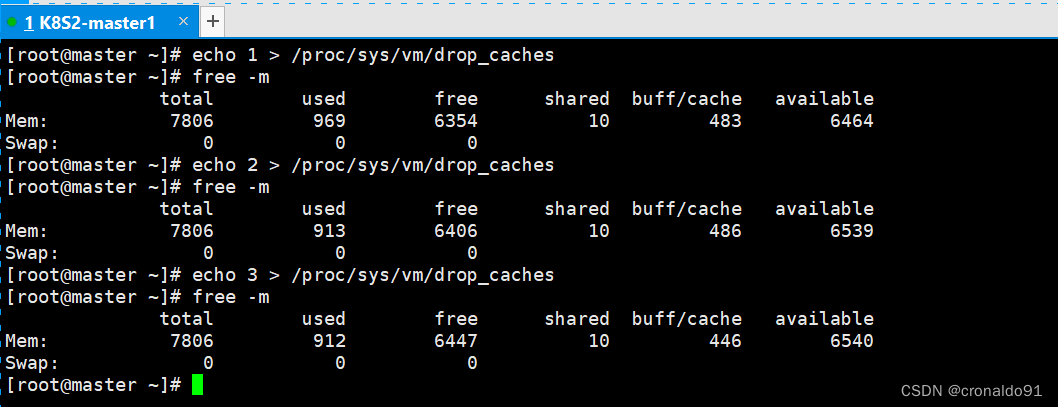
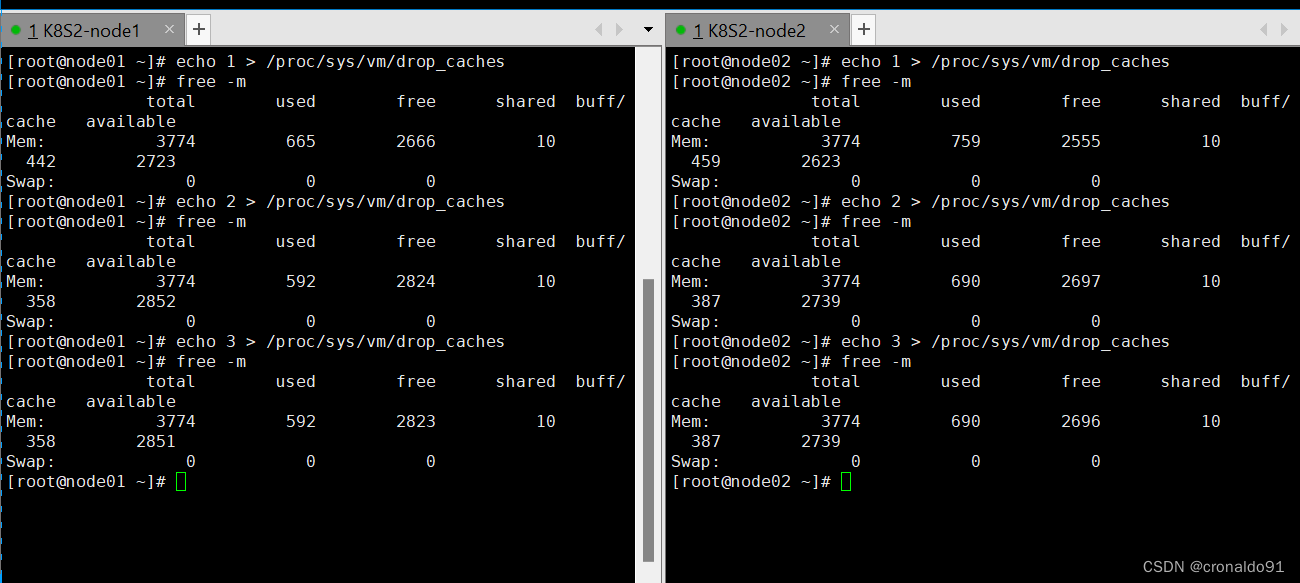
node节点
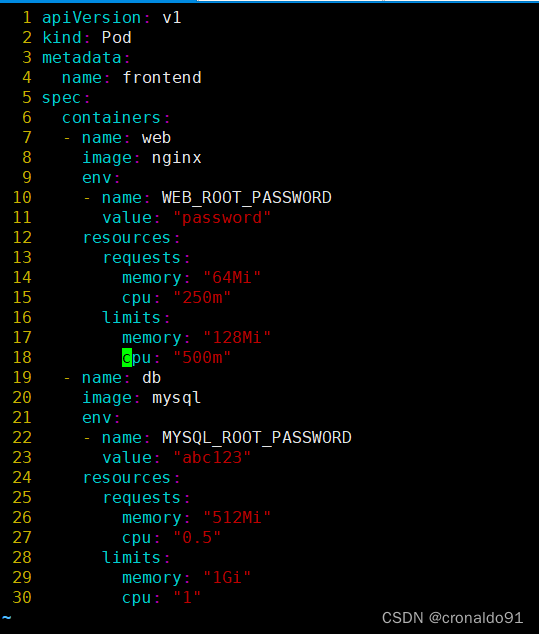
(2) 编写资源清单文件
![]()
pod有两个容器,web 和db。所以,总的请求资源和限制资源为 web 和db 请求,限制资源总和。 其中,cpu 的资源请求和限制,是以单个cpu 资源进行计算的。如果有多个cpu,则最终的结果是数值*N
(3)生成资源
创建pod

查看pod信息

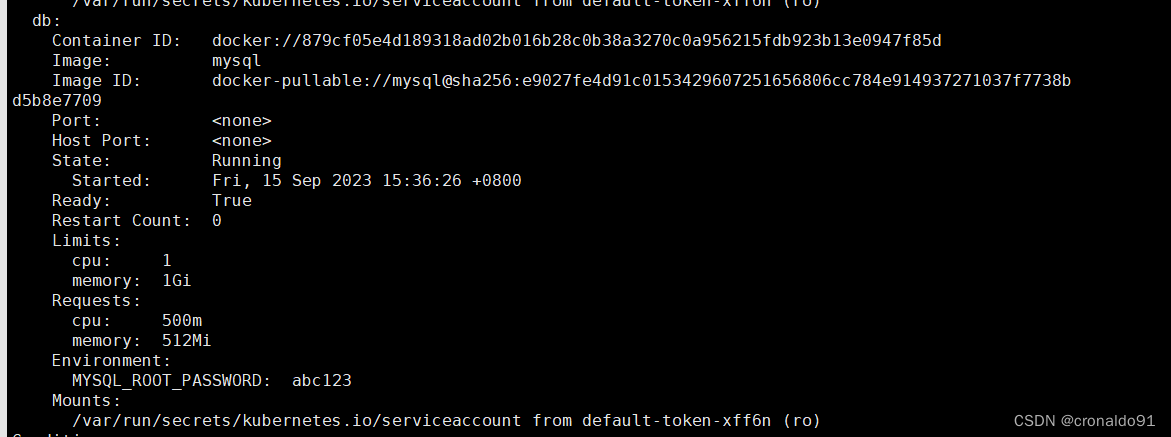
web容器里的资源限制情况:
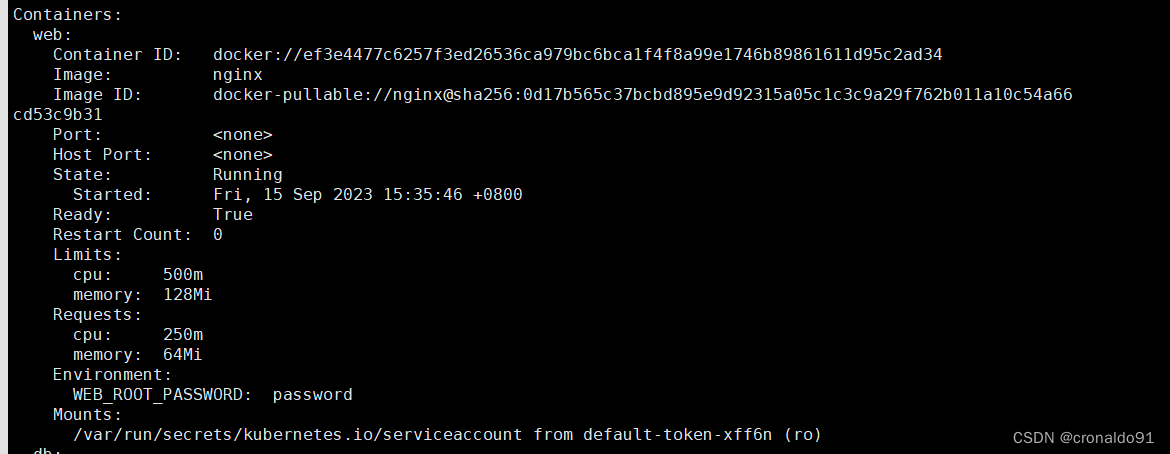
db容器里的资源限制情况:
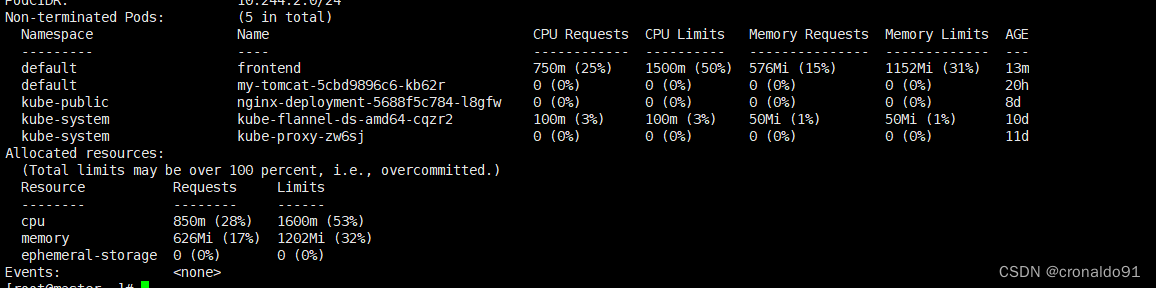
(4)查看节点信息
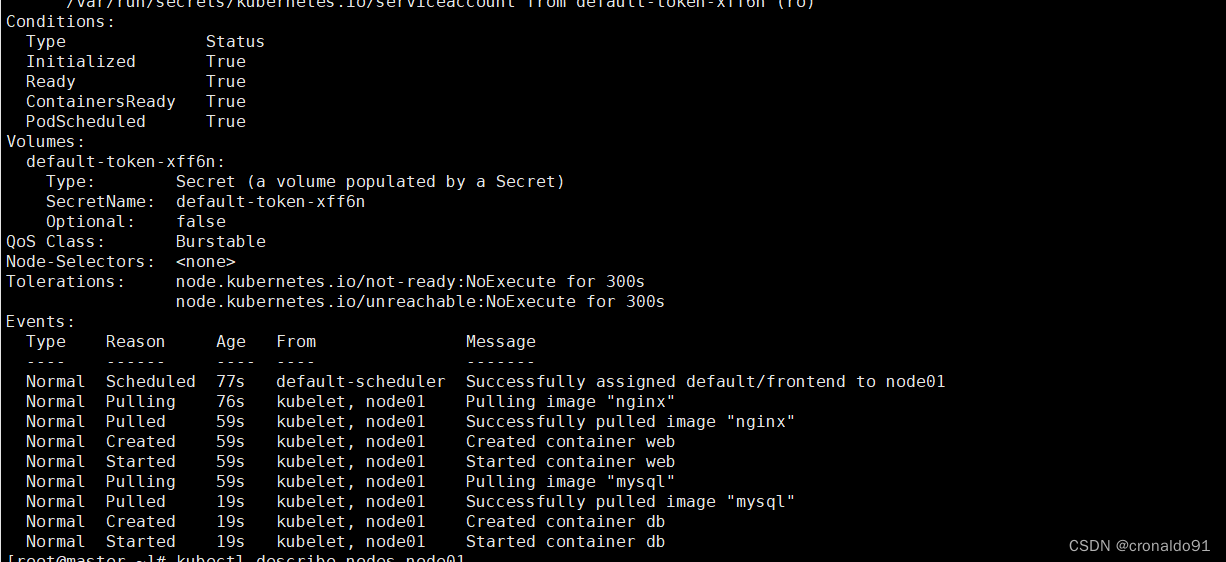
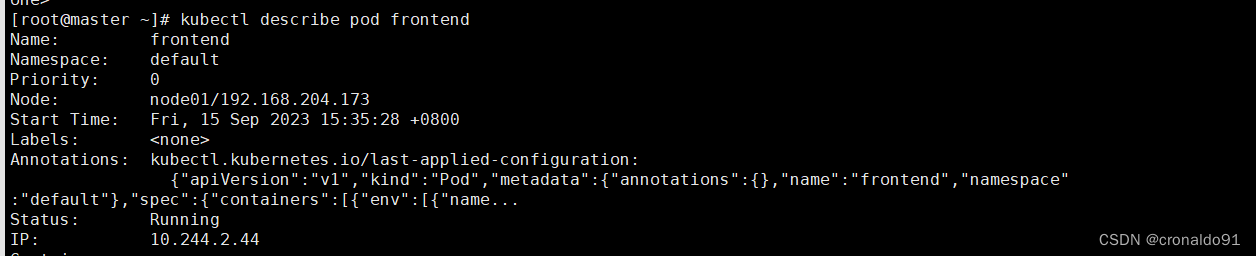
查看pod 的详细信息
此pod被调度到了node01节点,需要去node01节点查看机器资源的使用
查看node节点信息
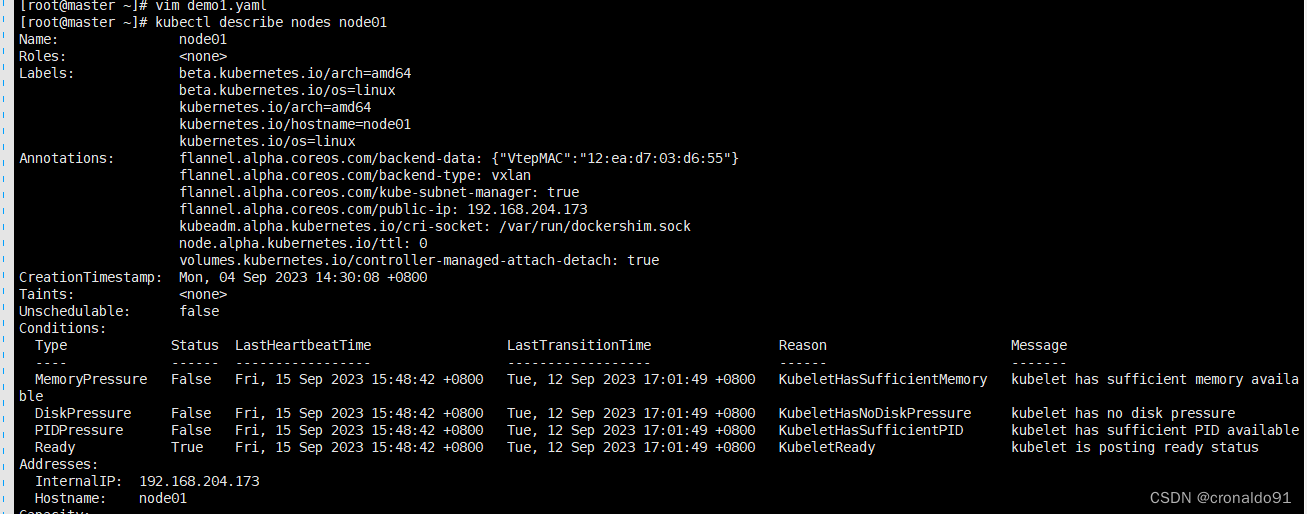
请求资源和限制资源的总数为之前设置web容器和db容器资源的总和,因为只有1个cpu,所以cpu的请求和限制的资源为 数值*1
2.健康检查(探针Probe)
(1) exec方式
①编写资源清单文件

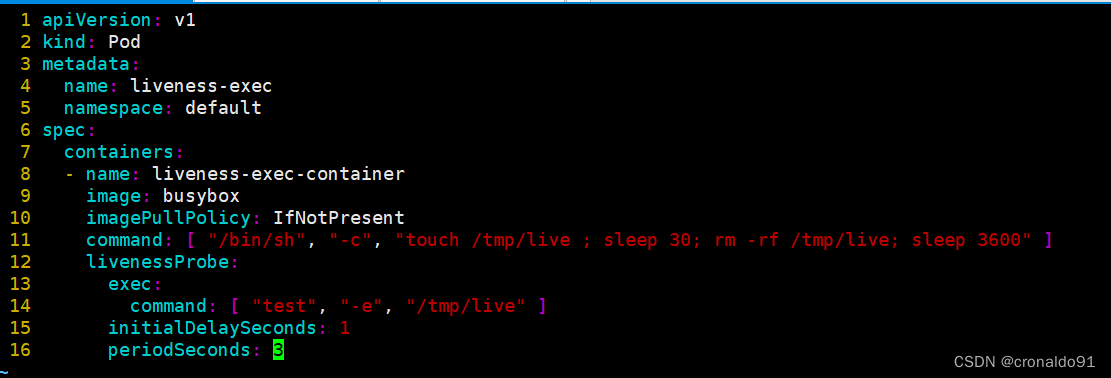
②创建pod

③跟踪查看pod 信息
因为容器的存储探测失败,所以会重启容器
 ④新开一个终端,查看pod 的消息信息
④新开一个终端,查看pod 的消息信息
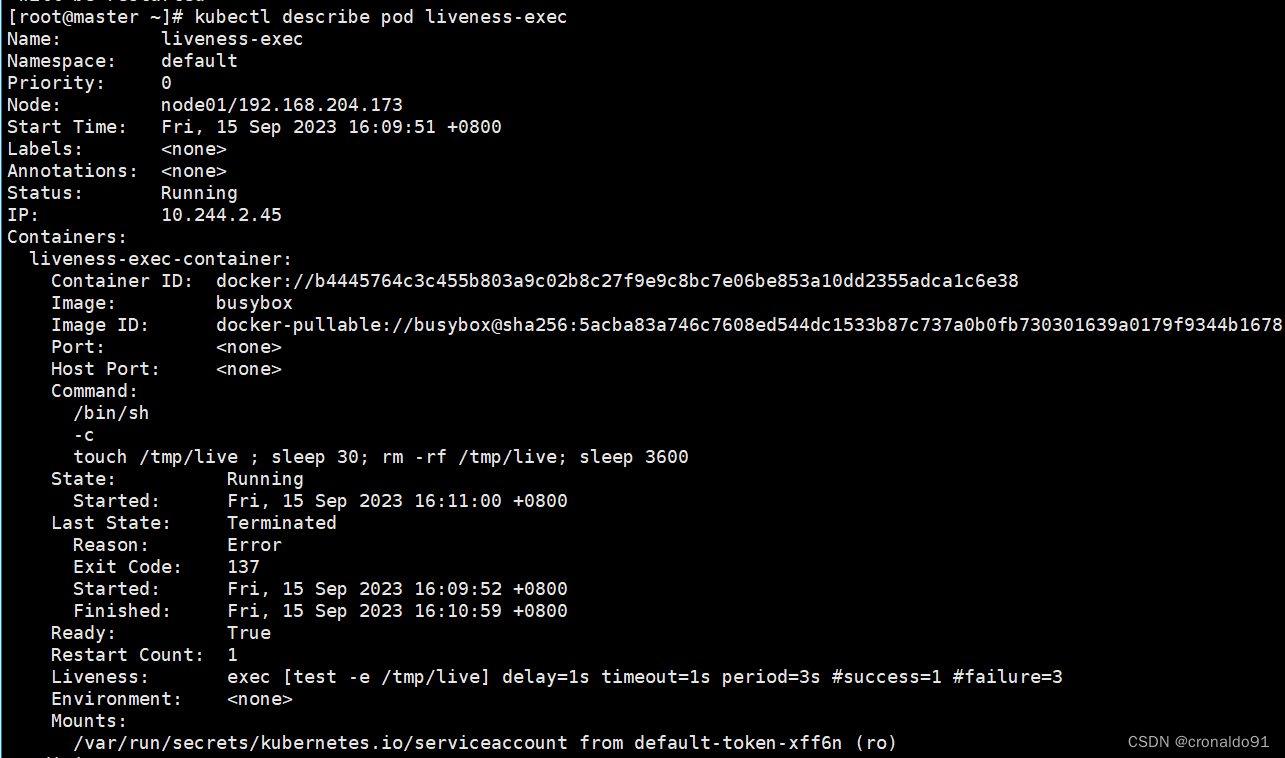
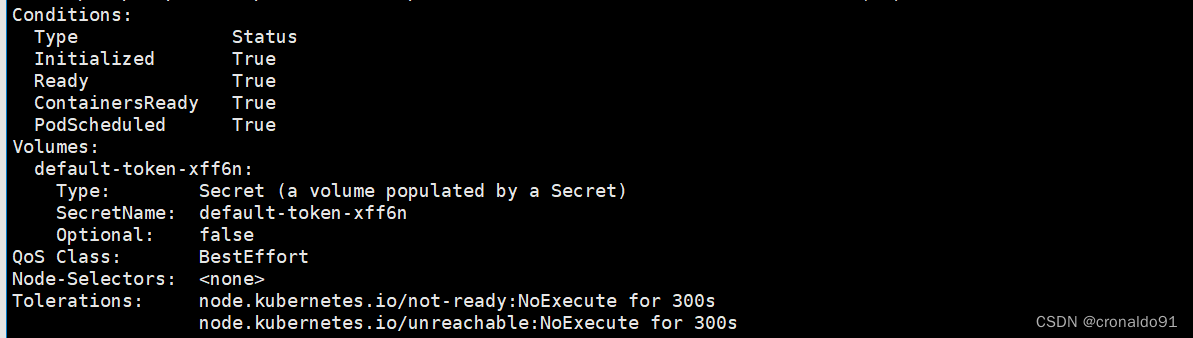
liveness probe failed显示容器存活探测失败,将会重新启动容器
Started container 表示开始重启容器
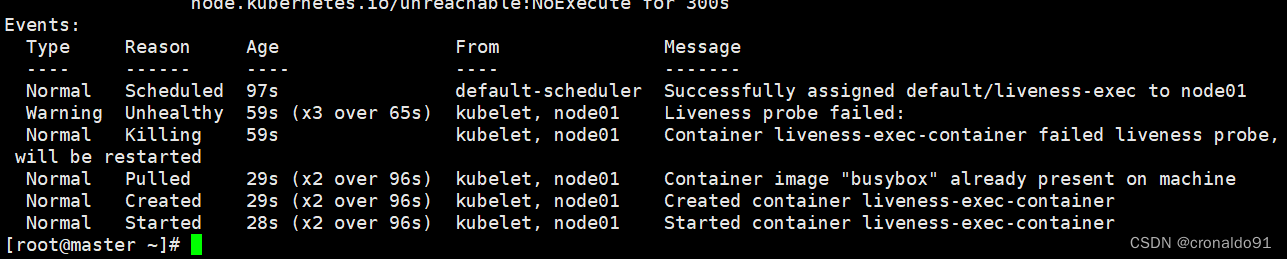
超出时间将会销毁容器

(2) httpGet方式
① 编写httpGet 示例

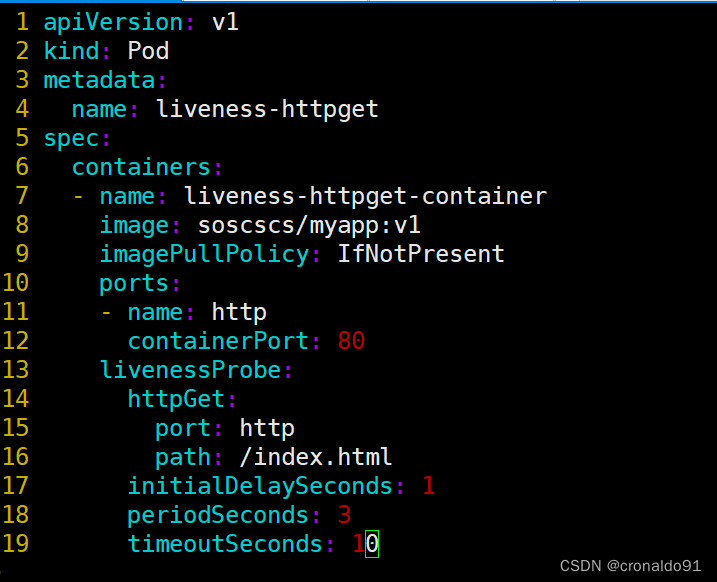
创建pod![]()
删除pod里容器的文件![]()
查看pod信息

查看pod 状态和 详细信息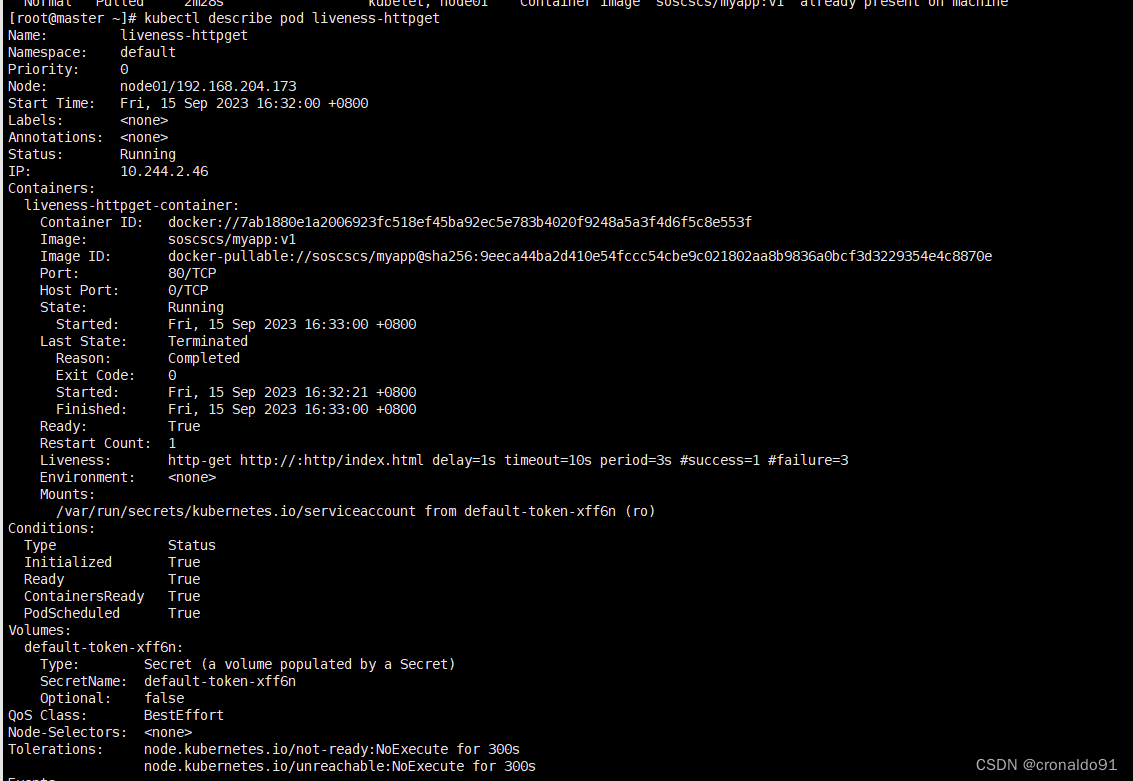
httpGet获取到的返回码是404,因此livenessProbe检测失败,将重启容器

再次查看pod信息
RESTARTS值变为1了,因为httpGet检测状态码不在(大于等于200,小于等于400)的范围里,所以会重启容器

(3)tcpSocket 方式
① 编写tcpSocket 方式示例

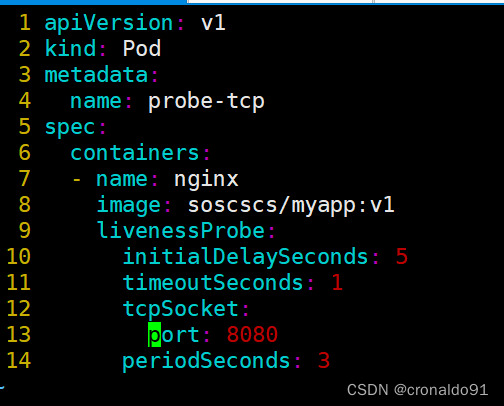
创建pod

查看容器里的端口(查看有无8080端口)
容器里无8080端口

查看pod的状态和详细信息
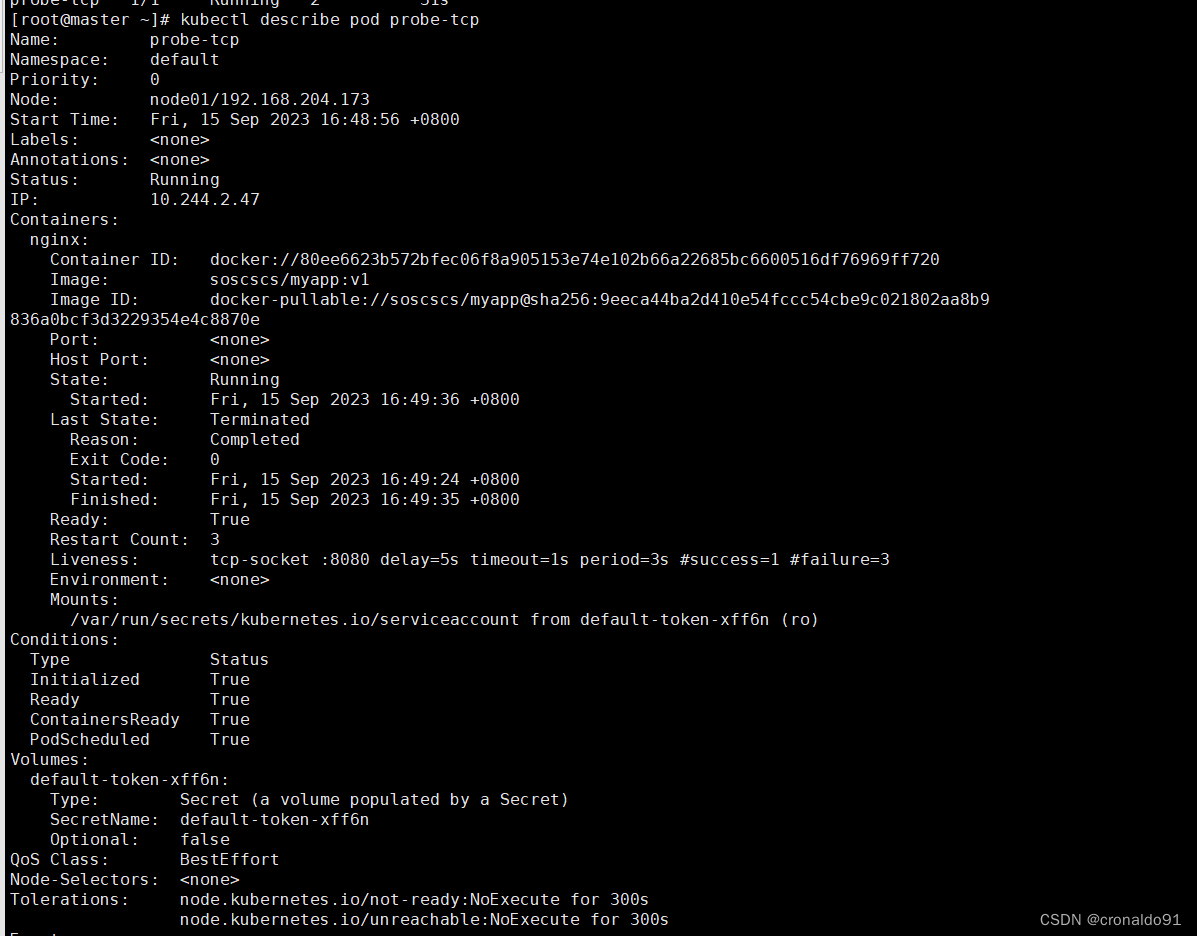
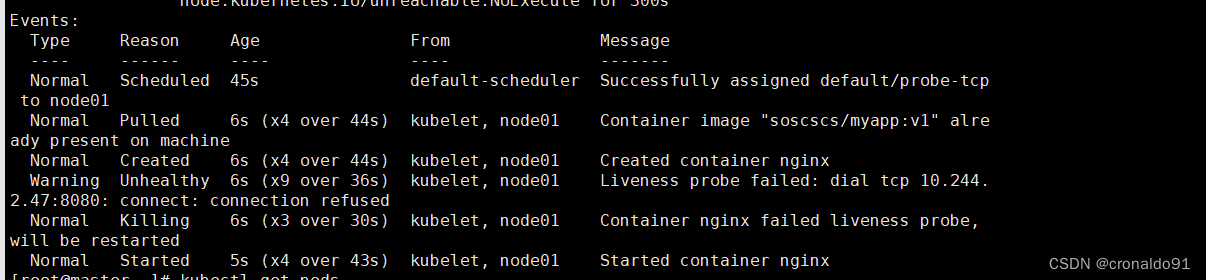
连接容器的8080端口失败,因此tcpSocket的存活探测结果是失败
(4)配置就绪探测 httpGet的方式


创建pod

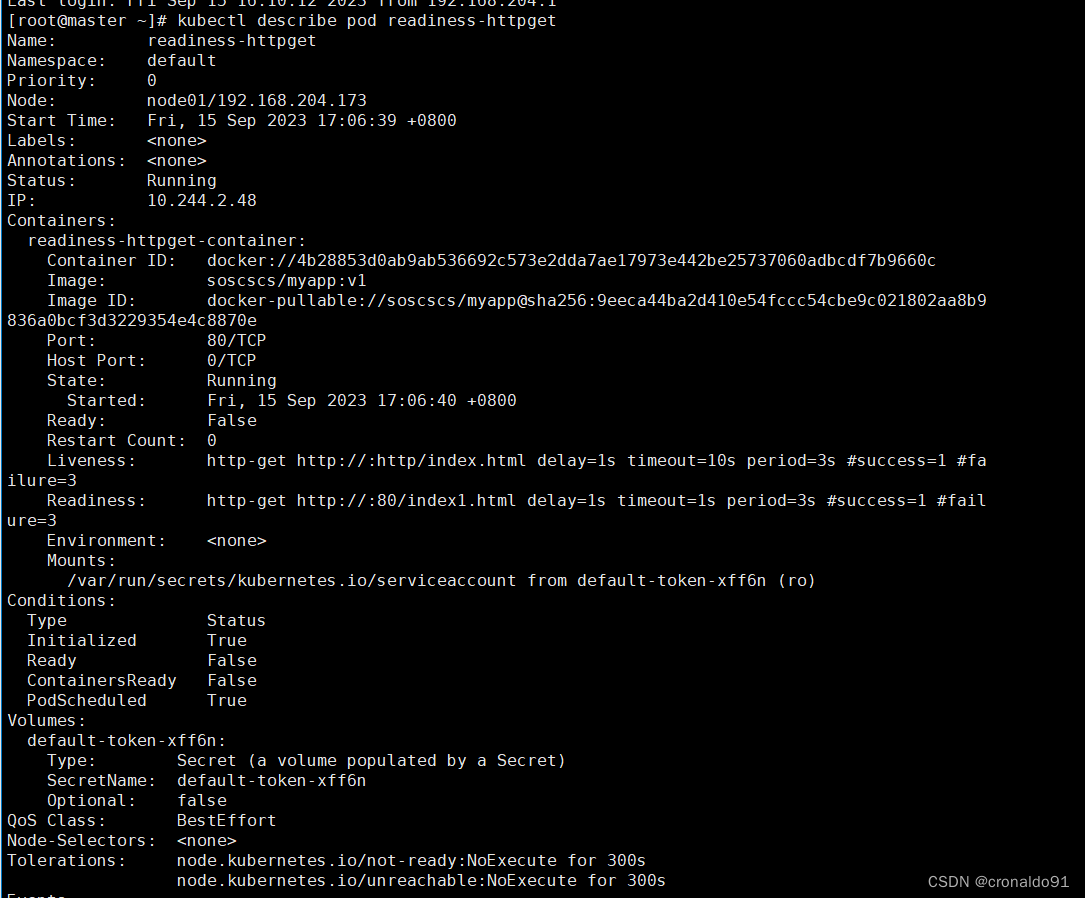
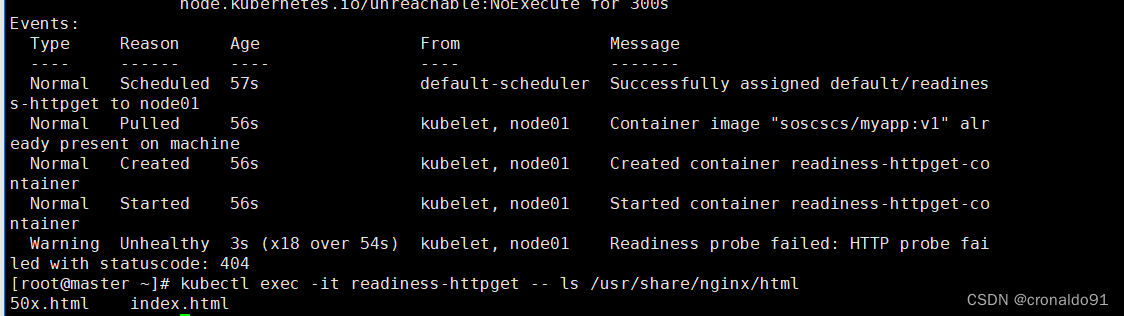
查看pod的详细信息
存活探测成功,但是就绪状态探测失败,READY状态为0/1

此时,因为容器里没有 index1.html文件,所以,httpGet的就绪探测失败
没有示例需要的index1.html文件,因此就绪探测失败
进入容器,创建index1.html,让就绪探测成功
进入容器,在网页根目录创建index1.html,使就绪状态成功

查看pod状态
就绪探测成功,READY变为1/1

(5) 就绪探测示例2

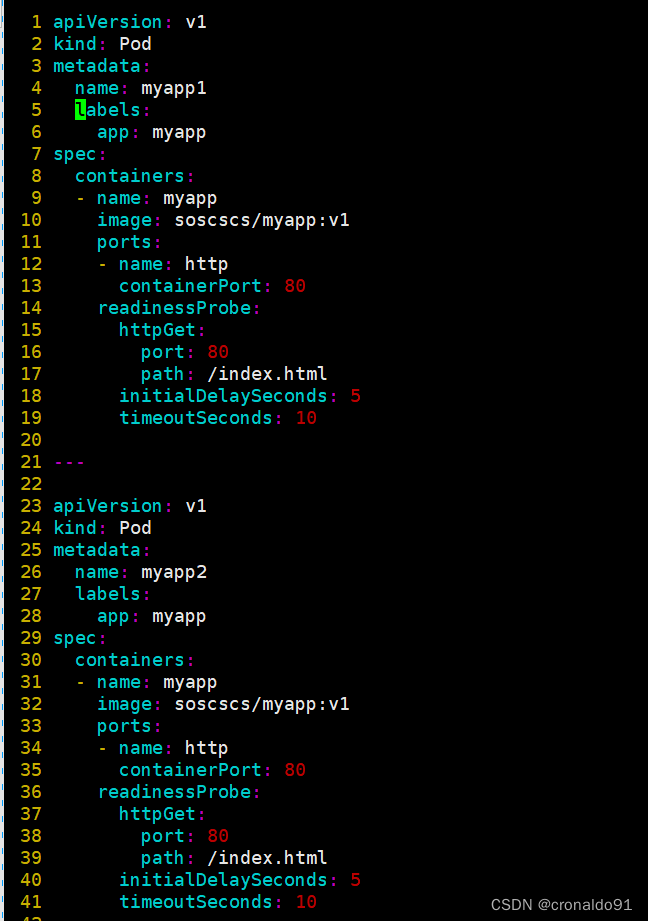
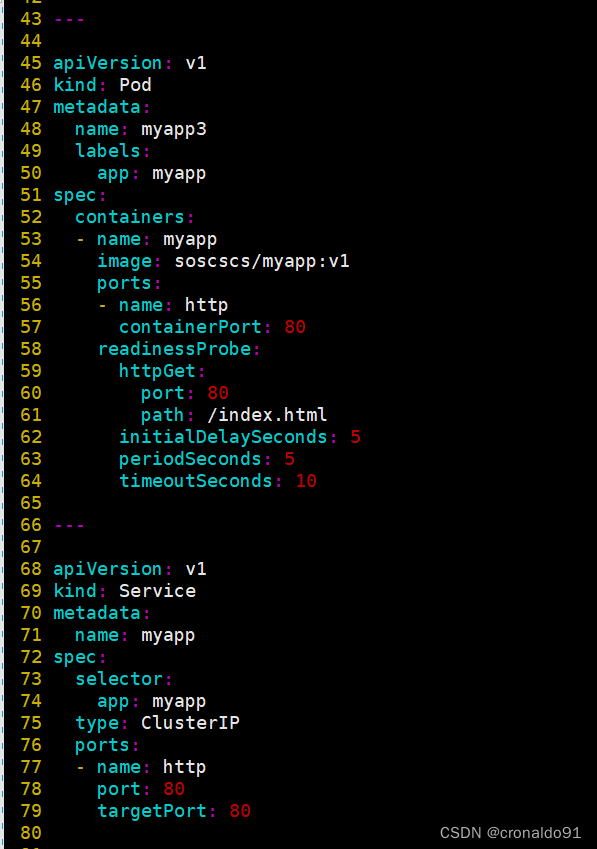
所有的自主式Pod,name不可以相同。但是使用同一个标签myapp。 service通过标签选择器和对应标签的pod关联:
创建资源:

查看这些资源的详细信息。
三个pod的就绪探测都成功,也和标签为myapp的service关联了
删除myapp1的 index.html文件,让就绪探测 失败
![]()
查看发现,就绪探测失败的pod被从关联的service中移除ip
因为是使用httpGet的就绪探测,探测的是网页Index.html,所以当没有网页时,返回码为404,就绪探测失败,READY状态变为0/1
当就绪探测失败后,端点控制器将该pod关联的所有service endpoints中移除该pod的id
三、问题
1.生成资源报错
(1)报错
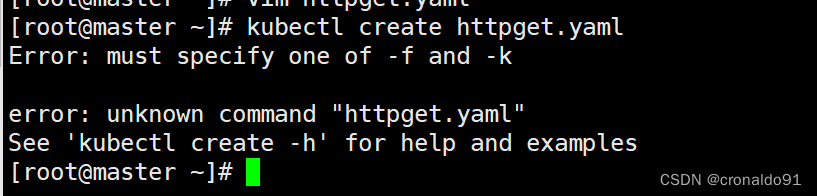
(2)原因分析
命令缺少参数:
修改前:
![]()
修改后:
![]()
2.api版本错误
(1)报错

(2)原因分析
api版本配置错误
(3)解决方法
修改api配置
修改前:

修改后:

3.echo N>/proc/sys/vm/drop_caches如何实现清理缓存
(1)原理
echo N > /proc/sys/vm/drop_caches , 当N数值不同时,free –m存在差异
首先查看/proc/sys/vm/drop_caches的默认值,以便可以修改回来
然后free-m查看此时内存使用情况,对于各字段含义,可以参考:
第一类单位参数:
1) -b, –bytes, 以Byte为单位显示内存使用情况
2) -k, –kilo, 以KB为单位, 这也是默认值
3) -m, –mega, 以MB为单位显示内容使用情况
4) -g, –giga, 以GB为单位显示内存使用情况
第二类参数:
1)、 -h, –human, 自动将数值转换为人类易读形式
2)、 -c, –count, 展示结果count次,需与-s配合使用
3)、 -s, –seconds, 动态刷新内存使用情况的间隔
free -m各字段含义
第一部分Mem行:
========================
total 内存总数: 3865M
used 已经使用的内存数: 1545M
free 空闲的内存数: 2320M
shared 多个进程共享的内存总额 196M
buffers Buffer 缓存内存数: 176M
cached Page 缓存内存数:569M
关系:total (3865M) = used(1545M) + free(2320M)
第二部分(-/+ buffers/cache):
========================
(-buffers/cache) used内存数:798M
(指的第一部分Mem行中的used – buffers – cached)
即为1545 – 176 – 569 = 800 取整时计算差异 2M
(+buffers/cache) free内存数: 3066M
(指的第一部分Mem行中的free + buffers + cached)
即为2320 + 176 + 569 = 3065 取整时计算差异 1M
第三部分是指交换分区
========================
当系统的物理内存不够用的时候,就需要将物理内存中的一部分空间释放出来,以供当前运行的程序使用。这些被释放的进程被临时保存到Swap空间中,等到那些程序要运行时,再从Swap分区中恢复保存的数据到内存中。这样,系统总是在物理内存不够时,才进行Swap交换。所以swap分区不被占用或者占用很少,说明现在系统内存够用,运行还算良好,不会影响系统运行(2)执行
执行echo 1 > /proc/sys/vm/drop_caches, 其中绿色框是标记发生改变的部分,由于buffers 和 cached数值变化,第一行free和used均发生变化

执行echo 2 > /proc/sys/vm/drop_caches, 其中绿色框是标记发生改变的部分,这次仅有buffers由0变为1,cached基本没有变化

执行echo 3 > /proc/sys/vm/drop_caches, 这次基本上,和写入2区别不大,没有什么变化

(3)drop_caches文件解析
执行echo N > /proc/sys/vm/drop_caches,再free –m查看内存使用情况,输入不同的N值,free –m内存中缓存buffers会有差异,要解释/proc/sys/vm、drop_caches, 查询这个文件到底是什么,另外可以写入哪些数值,具体适用于什么场景。
查看linux内核文档,可以得到以下信息:

(4)小结
可以看出,/proc/sys是一个虚拟文件系统,可以通过对它的读写操作做为与kernel实体间进行通信的一种手段。也就是说可以通过修改/proc中的文件,来对当前kernel的行为做出调整。那么我们可以通过调整/proc/sys/vm/drop_caches来释放内存。其默认数值为0.
向/proc/sys/vm/drop_caches中写入内容,会清理缓存。建议先执行sync(sync 命令将所有未写的系统缓冲区写到磁盘中,包含已修改的 i-node、已延迟的块 I/O 和读写映射文件)。执行echo 1、2、3 至 /proc/sys/vm/drop_caches, 达到不同的清理目的
(5)使用建议
如果因为是应用有像内存泄露、溢出的问题,从swap的使用情况是可以比较快速可以判断的,但free上面反而比较难查看。相反,如果在这个时候,我们告诉用户,修改系统的一个值,“可以”释放内存,free就大了。用户会怎么想?不会觉得操作系统“有问题”吗?所以说,既然核心是可以快速清空buffer或cache,也不难做到(这从上面的操作中可以明显看到),但核心并没有这样做(默认值是0),我们就不应该随便去改变它。
一般情况下,应用在系统上稳定运行了,free值也会保持在一个稳定值的,虽然看上去可能比较小。当发生内存不足、应用获取不到可用内存、OOM错误等问题时,还是更应该去分析应用方面的原因,如用户量太大导致内存不足、发生应用内存溢出等情况,否则,清空buffer,强制腾出free的大小,可能只是把问题给暂时屏蔽了。
排除内存不足的情况外,除非是在软件开发阶段,需要临时清掉buffer,以判断应用的内存使用情况;或应用已经不再提供支持,即使应用对内存的时候确实有问题,而且无法避免的情况下,才考虑定时清空buffer。(可惜,这样的应用通常都是运行在老的操作系统版本上,上面的操作也解决不了)四、总结
探针有3种:
livenessProbe:(存活探针)
判断容器是否正常运行,如果失败,则杀掉容器(注意,不是杀掉pod),再根据重启策略是否重启容器
readinessProbe(就绪探针)
判断容器是否能够进入ready状态。探针失败则进入noready状态,并从service的endpoints中剔除此容器
startupProbe
判断容器内的应用是否启动成功。再success状态前,其他探针都处于无效状态
检查方式3种:
exec:
使用command 字段设置命令,在容器中执行次命令,如果命令返回状态码为0,则认为探测成功。
httpget
通过访问指定端口和url 路径,执行http get 访问。如果返回的 http 状态码 为 大于 等于200 且小于400 ,则认为探测成功
tcpsock
通过tcp连接pod(podIP) 和指定端口,如果端口无误,且tcp连接成功,则认为探测成功。
探针可选的参数:
initialDelaySeconds
容器启动多少秒后开始执行探测
periodSeconds
探测的频率。每多少秒执行一次探测
failureThreshold
探测失败后,允许再试几次
timeoutSeconds
探测等待超时时间