langchain2之Agent以及Wandb
- langchain
- 1.概念
- 2.主要模块
- 模型输入/输出 (Model I/O)
- 数据连接 (Data connection)
- 链式组装 (Chains)
- 代理 (Agents)
- 内存 (Memory)
- 回调 (Callbacks)
- 3.Agent
- Action Agent:
- Plan-and-Execute-Agent:
- 搜索工具
- 4.wandb
- 1.注册
- 2.安装
- 3.登录
- 4.使用
- 5.打开网址查看
- 6.在langchain中使用
langchain
1.概念
什么是LangChain?
源起:LangChain产生源于Harrison与领域内的一些人交谈,这些人正在构建复杂的LLM应用,他在开发方式
上看到了一些可以抽象的部分。一个应用可能需要多次提示LLM并解析其输出,因此需要编写大量的复制粘贴。
LangChain使这个开发过程更加简单。一经推出后,在社区被广泛采纳,不仅有众多用户,还有许多贡献者参
与开源工作。
还有大模型本身的问题,无法感知实时数据,无法和当前世界进行交互。
LangChain是一个用于开发大语言模型的框架。
主要特性:
\1. 数据感知:能够将语⾔模型与其他数据源进⾏连接。
\2. 代理性:允许语⾔模型与其环境进⾏交互。可以通过写⼯具的⽅式做各种事情,数据的写⼊更新。
主要价值:
1、组件化了需要开发LLM所需要的功能,提供了很多工具,方便使用。
2、有一些现成的可以完整特定功能的链,也可以理解为提高了工具方便使用。
2.主要模块
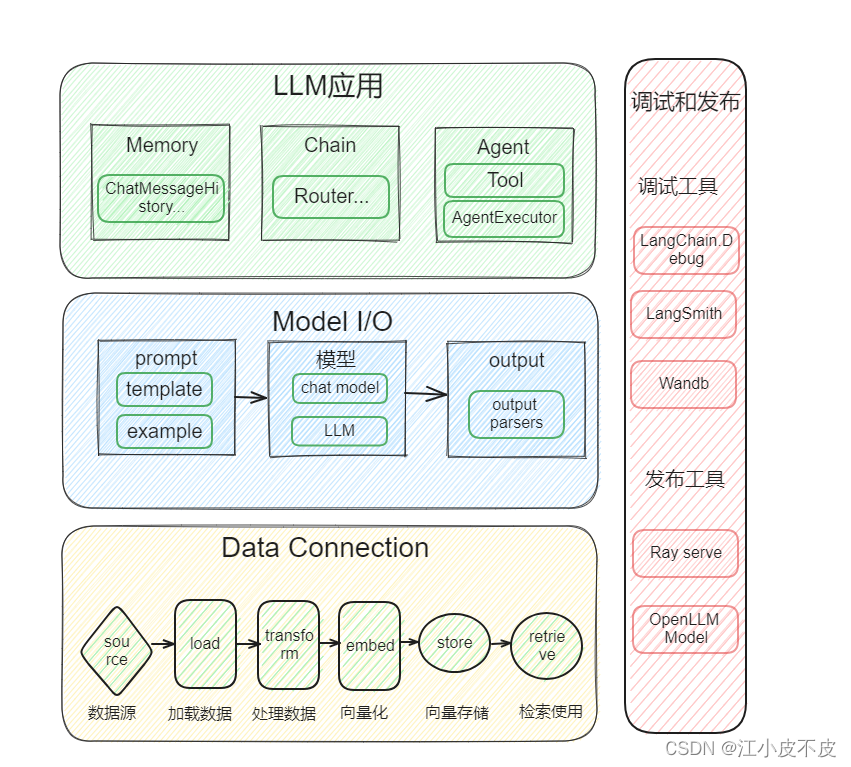
LangChain 为以下模块提供了标准、可扩展的接口和外部集成,按照复杂程度从低到高列出:
模型输入/输出 (Model I/O)
与语言模型进行接口交互
数据连接 (Data connection)
与特定于应用程序的数据进行接口交互
链式组装 (Chains)
构造调用序列
代理 (Agents)
根据高级指令让链式组装选择要使用的工具
内存 (Memory)
在链式组装的多次运行之间持久化应用程序状态
回调 (Callbacks)
记录和流式传输任何链式组装的中间步骤
3.Agent
Agent:这是一个类,负责决定下一步要采取什么行动。它由语言模型和提示驱动。提示可以包括agent的性格、背景上下文以及用于引发更好推理的提示策略等。
Tools:这些是agent调用的函数。这里有两个重要的考虑因素:给agent提供正确的工具,以及以最有帮助的方式描述这些工具。
Toolkits:这是一组工具,用于完成特定的目标。LangChain提供了一系列的toolkits。
AgentExecutor:这是agent的运行时环境。它实际上调用agent并执行其选择的动作。
⼏个关键组件:
• Agent:这是负责决定下⼀步要采取什么⾏动的类,即⽤什么Tool,做决定。
• Tools:Tools是agent调⽤的函数、内置的⼯具有搜索、⽹络请求、Shell、数学…
• Toolkits:⽤于完成特定⽬标所需的⼯具组。⼀个toolkit通常包含3-5个⼯具。
• AgentExecutor:AgentExecutor是agent的运⾏时环境。这是实际调⽤agent并执⾏其选择的动作的部分
Agent使⽤LLM来决定应采取哪些⾏动(Tool)以及⾏动的顺序。⾏动可以是使⽤⼯具并观察其输出,或者向⽤户返回响应。下⾯是可⽤的Agent类型:
Action Agent:
• Zero-shot ReAct:仅根据⼯具的描述来确定使⽤哪个⼯具。要求为每个Tool提供⼀个描述,不限制Tool数量
• Structured input ReAct:能够使⽤多输⼊⼯具,结构化的参数输⼊。
• Conversational:为对话设置设计的Agent,使⽤Memory来记住之前的对话交互。
• Self ask with search:⾃问⾃答,会使⽤Google搜索⼯具。
• ReAct document store :⽤于和⽂档进⾏交互的Agent。必须提供两个Tool:⼀个搜索⼯具和⼀个查找⼯具。搜索⼯具应该搜索⽂档,⽽查找⼯具应该在最近找到的⽂档中查找⼀个术语。
• OpenAI Functions:某些OpenAI模型(如gpt-3.5-turbo-0613和gpt-4-0613)已经明确地进⾏了微调,如果使⽤
这些模型,可以考虑使⽤OpenAI Functions 的AgentType。
Plan-and-Execute-Agent:
计划和执⾏agent 计划和执⾏agent通过⾸先计划要做什么,然后执⾏⼦任务来完成⽬标。这个想法主要受到BabyAGI和"Plan-and-Solve"论⽂的启发。
from langchain.agents import OpenAIFunctionsAgent
# 定义用来控制Agent的模型
from langchain.chat_models import ChatOpenAI
llm = ChatOpenAI(temperature=0)
# 定义一个Tool,这个Tool是用来计算单单词的长度
from langchain.agents import tool
@tool
def get_word_length(word: str) -> int:
"""返回单词的长度。"""
return len(word)
tools = [get_word_length]
# 创建提示,设定Agent的特点和擅长点
from langchain.schema import SystemMessage
system_message = SystemMessage(content="你是一个非常强大的助手,但是在计算单词长度方面不擅长。")
prompt = OpenAIFunctionsAgent.create_prompt(system_message=system_message)
# 定义Agent
from langchain.agents import OpenAIFunctionsAgent
agent = OpenAIFunctionsAgent(llm=llm, tools=tools, prompt=prompt)
# 创建AgentExecutor - 我们的agent的运行时环境。
from langchain.agents import AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.run("单词educa有多少个字母?")
agent_executor.run("那是个真正的单词吗?")

from langchain.prompts import MessagesPlaceholder
# 给Agent加上会话状态
from langchain.memory import ConversationBufferMemory
MEMORY_KEY = "chat_history"
prompt = OpenAIFunctionsAgent.create_prompt(
system_message=system_message,
extra_prompt_messages=[MessagesPlaceholder(variable_name=MEMORY_KEY)]
)
memory = ConversationBufferMemory(memory_key=MEMORY_KEY, return_messages=True)
# 加上状态Memory
agent = OpenAIFunctionsAgent(llm=llm, tools=tools, prompt=prompt)
agent_executor = AgentExecutor(agent=agent, tools=tools, memory=memory, verbose=True)
agent_executor.run("单词educa有多少个字母?")
agent_executor.run("那是个真正的单词吗?")

Structured tool chat
可以使用args_schema计算动作的输入,约定输入的结构。在使用structured-chat-zero-shot-react-description 或者 AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION是有用的。
import requests
from pydantic import BaseModel, Field
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.agents import initialize_agent
from langchain.tools import StructuredTool
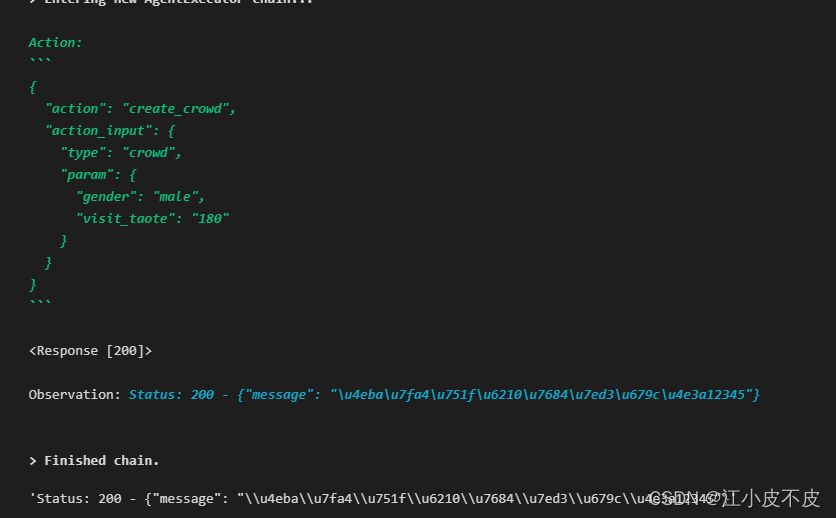
def create_crowd(type: str, param: dict) -> str:
"""
该工具可以用来进行人群生成:
当需要生成人群、分析画像、咨询问题时,使用如下的指示:url 固定为:http://localhost:3001/
如果请求是生成人群,请求的type为crowd; 如果请求是分析画像,请求的type为analyze; 如果是其他或者答疑,请求的type为question;
请求body的param把用户指定的条件传进来即可
只要请求有结果,你就说人群正在生成中就行
"""
result = requests.post("http://localhost:3001/", json={"type": type, "param": param})
print(result)
return f"Status: {result.status_code} - {result.text}"
tools = [
StructuredTool.from_function(func=create_crowd, return_direct=True)
]
llm = OpenAI(temperature=0) # Also works well with Anthropic models
# memory = ConversationBufferMemory(memory_key="chat_history", return_messages=True)
agent_chain = initialize_agent(tools,
llm,
agent=AgentType.STRUCTURED_CHAT_ZERO_SHOT_REACT_DESCRIPTION,
verbose=True,
# memory=memory
)
agent_chain.run("我想生成一个性别为男并且在180天访问过淘特的人群?")
搜索工具
https://serpapi.com/
复制key
1.配置key
import os
import openai
#搜索
os.environ["OPENAI_API_KEY"] = ""
openai.api_key = ""
os.environ["SERPAPI_API_KEY"] = ""
#代理
os.environ["http_proxy"] = "127.0.0.1:7890"
os.environ["https_proxy"] = "127.0.0.1:7890"
2.封装工具
from langchain.agents import Tool
from langchain.agents import AgentType
from langchain.memory import ConversationBufferMemory
from langchain import OpenAI
from langchain.utilities import SerpAPIWrapper
from langchain.agents import initialize_agent
search = SerpAPIWrapper()
tools = [
Tool(
name="Current Search",
func=search.run,
description="当你需要回答关于当前事件或世界当前状态的问题时很有用"
),
]
memory = ConversationBufferMemory(memory_key="chat_history")
llm = OpenAI(temperature=0)
agent_chain = initialize_agent(
# 工具列表
tools,
llm,
# Agent类型
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
verbose=True,
memory=memory)
3.调用agent
agent_chain.run(input="明天福州的天气怎么样? 针对明天的天气我适合买什么样的衣服")

4.wandb
W&B是机器学习平台,供开发人员更快地构建更好的模型。使用W&B的轻量级,可互操作的工具快速跟踪实验,对数据集进行版本控制和迭代,评估模型性能,重现模型,可视化结果和发现回归,并与同事共享结果。 在 5 分钟内设置 W&B,然后快速迭代您的机器学习管道,确信您的数据集和模型在可靠的记录系统中得到跟踪和版本控制。
1.注册
https://wandb.ai/
2.安装
pip install wandb
3.登录
wandb login

4.使用
import wandb
import random
# start a new wandb run to track this script
wandb.init(
# set the wandb project where this run will be logged
project="my-awesome-project",
# track hyperparameters and run metadata
config={
"learning_rate": 0.02,
"architecture": "CNN",
"dataset": "CIFAR-100",
"epochs": 10,
}
)
# simulate training
epochs = 10
offset = random.random() / 5
for epoch in range(2, epochs):
acc = 1 - 2 ** -epoch - random.random() / epoch - offset
loss = 2 ** -epoch + random.random() / epoch + offset
# log metrics to wandb
wandb.log({"acc": acc, "loss": loss})
# [optional] finish the wandb run, necessary in notebooks
wandb.finish()
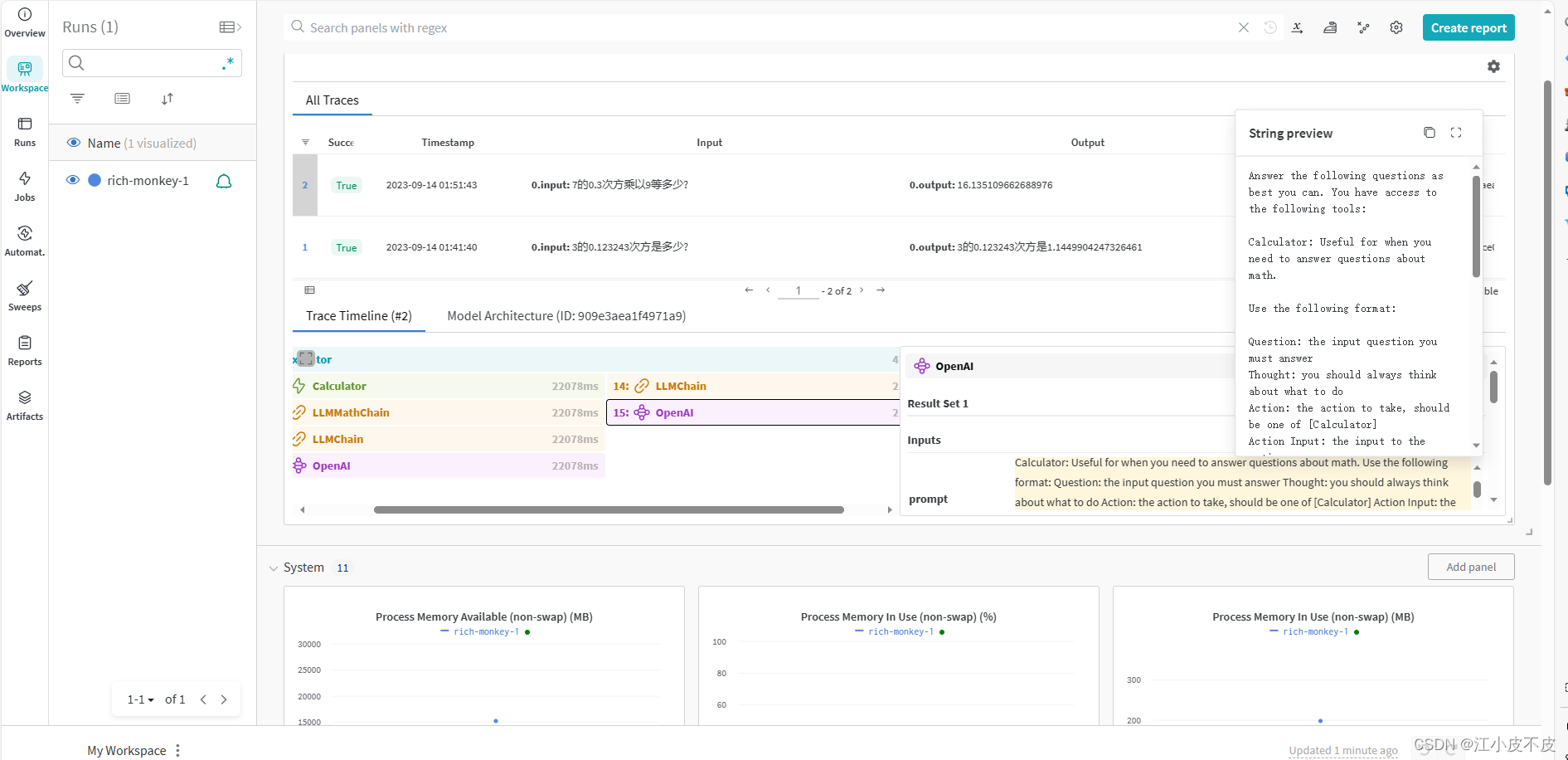
5.打开网址查看
https://wandb.ai/home
6.在langchain中使用
import os
os.environ["LANGCHAIN_WANDB_TRACING"] = "true"
os.environ["WANDB_PROJECT"] = "langchain-tracing"
from langchain.agents import initialize_agent, load_tools
from langchain.agents import AgentType
from langchain.llms import OpenAI
from langchain.callbacks import wandb_tracing_enabled
llm = OpenAI(temperature=0)
tools = load_tools(["llm-math"], llm=llm)
agent = initialize_agent(
tools,
llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
agent.run("7的0.3次方乘以9等多少?")
在wandb中查看