本篇文章介绍C语言的基础知识,使读者对C语言能够有一个大概的认识. 不会细写每一个知识点, 但是能够入门C语言, 进行初步的C语言代码阅读.
首先, 什么是语言?
对于人和人之间进行交流的语言, 我们知道, 可以通过汉语, 英语, 日语等语言进行交流.
那么对于人和计算机交流就需要用 计算机语言, 这个时候就有 C/C++, Java, Python等计算机语言.
目前已知的计算机语言大约有上千种. 那么我们接下来要聊的C语言只是众多计算机语言中的一种. 当然, C语言是一门非常普及, 应用广泛的语言.
1. 什么是C语言
C语言是一门通用计算机编程语言,广泛应用于底层开发。C语言的设计目标是提供一种能以简易的方式编译、处理低级存储器、产生少量的机器码以及不需要任何运行环境支持便能运行的编程语言。
什么是底层开发?
我们所见到的电脑是属于硬件层次级别的, 那么当我们使用电脑时, 所接触到的就是操作系统(Operating System, 简称OS. 常见的操作系统有Windows, Linux, Mac等), 而OS就通过驱动层操作我们的硬件.
于是我们可以在OS上安装软件, 也就是我们日常所使用的微信, QQ, 百度网盘等各种应用软件.
对于我们普通用户来说, 我们可能更多的只关注应用软件, 那么我们一般把应用软件叫做上层软件, 把包含操作系统在内的更关注于底层原理的叫做下层软件(或者底层软件).
我们的C语言所处的层次就是从操作系统开始往下的一系列层次, 如图所示.

不过也并不代表C语言不能写应用软件, 最早的一批应用软件就是C语言写的.
1.1 计算机语言的发展
计算机语言的发展是经过一系列从低级向高级演变的一个过程.
最早期的时候, 我们使用二进制的指令(10001010)和计算机进行交流, 通过复杂的二进制序列操作计算机.
后面由于太过复杂就出现了汇编指令, 也叫助记符(即帮助我们记忆的一些符号, 比如将前面的二进制序列起名为ADD, 那么以后当看到ADD, 就代表是序列10001010.
但是汇编指令写代码依然十分复杂, 后面就演变成了B语言, 最后演变成较为方便的C语言. 那么前面的汇编指令以及二进制指令则是低级语言, 后面就是高级语言了.
为了避免各开发厂商用的C语言语法产生差异, 出现了C语言的一系列国际标准: ANSI C, C89, C90, C99, C11......也正是由于C语言的标准化, 才得以在国际上流行起来.
那么最初的标准就是ANSI C. 当然我们现在用的最普遍的标准是C89, C90标准, 包括很多编译器也是支持C99, C11的标准. 当前最新的C语言标准是C17(也被称为是C18).
1.2 常见的编译器
C语言是一门面向过程的计算机编程语言,与C++,Java等面向对象的编程语言有所不同。
其编译器主要有Clang、GCC、WIN-TC、MSVC、Turbo C等
我们后面主要使用 VS2019来进行代码的编写与运行. VS2019的底层就是MSVC.
什么是编译器?
C/C++是编译型的语言.
比如我们写了test.c文件, 当我们写完这个文件之后进行运行, 此时就会被编译器生成test.exe文件进行运行. 那么这个生成过程为: test.c -> 编译 -> 链接 -> test.exe
2. 第一个C语言程序
2.1 打开VS2019, 创建项目
打开VS2019, 选择创建新项目;

选择空项目, 点击下一步;
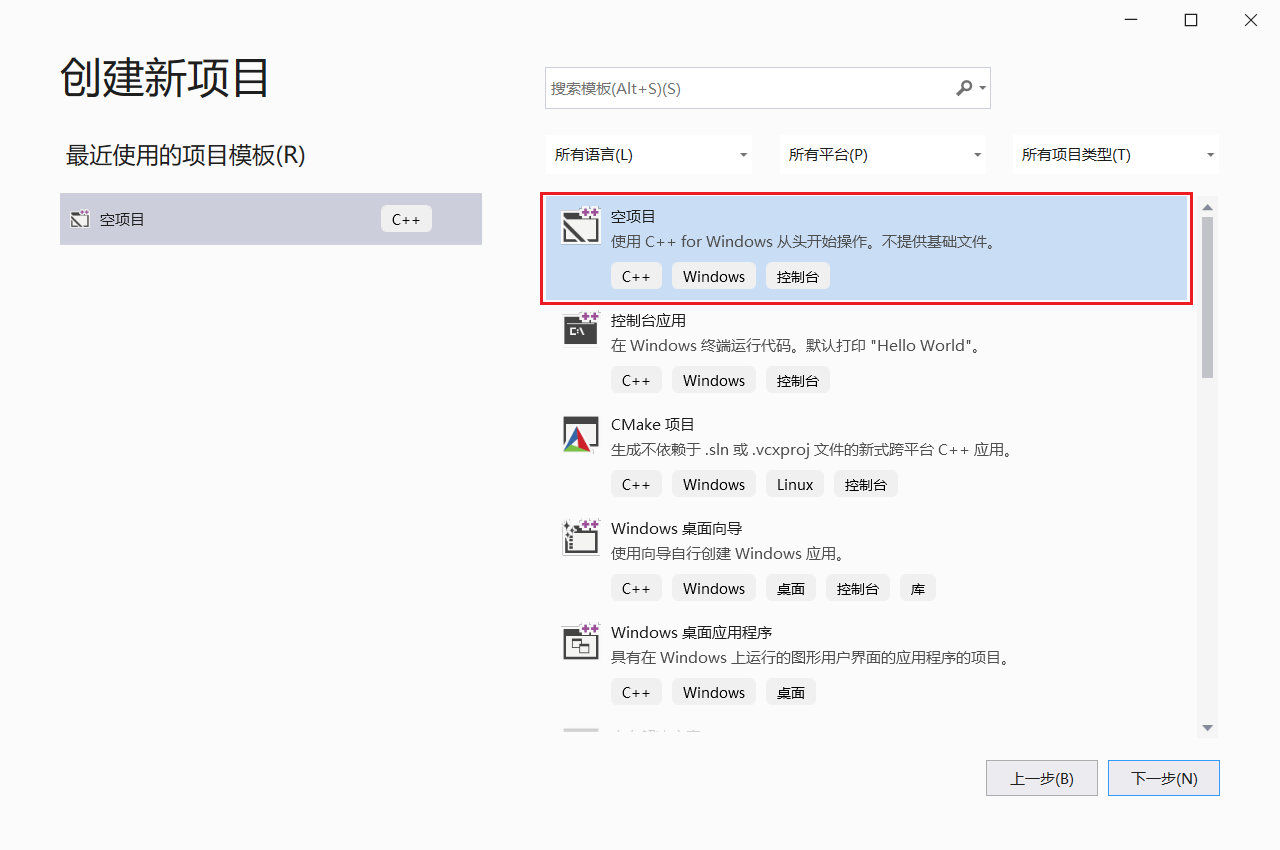
给项目起名字, 点击创建;

创建完成之后如下图所示.
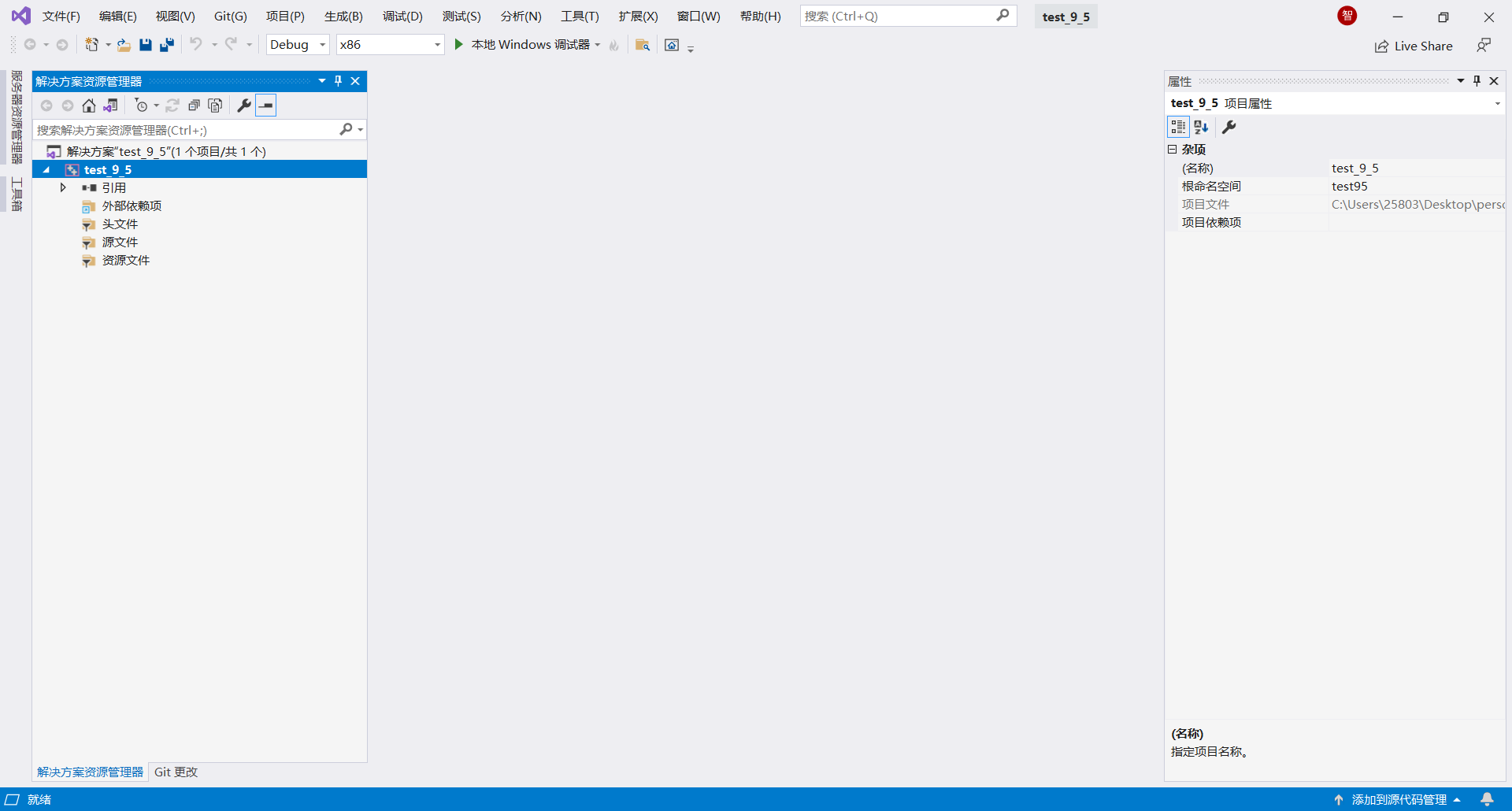
2.2 创建源文件
C语言中, .c后缀为源文件, .h后缀为头文件.
右键点击源文件 -> 添加 -> 新建项;
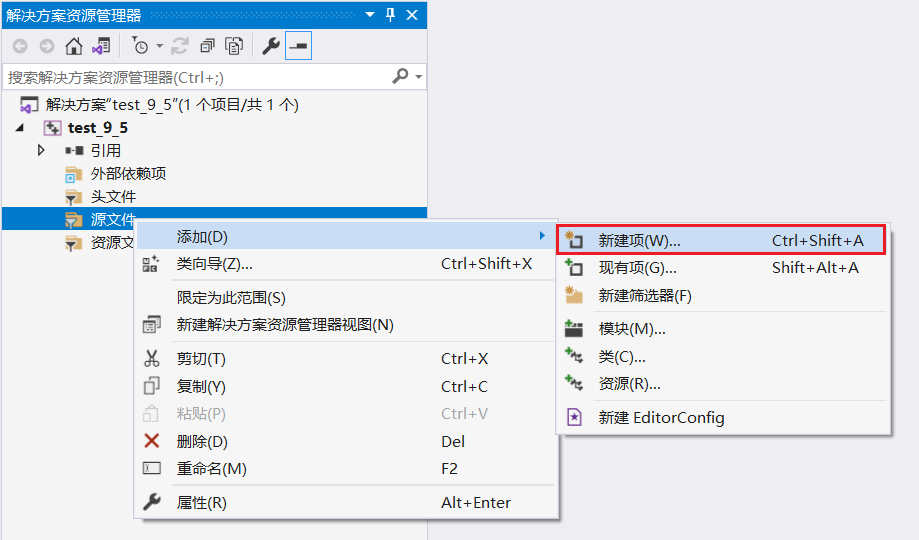
选择C++文件, 再编写文件名.

.cpp-> 编译器会按照C++的语法来编译代码
.c -> 编译器会按照C的语言来编译代码

2.3 写代码
#include<stdio.h>
int main()
{
printf("hehe\n");
return 0;
}按下键盘Ctrl + F5, 即可运行代码.

可以看到, 在控制台中打印了hehe, 符合代码预期结果.
接下来我们来逐一介绍这个函数的语句.
首先, C语言中必须要有main函数, 也就是主函数, 它是程序的入口, 并且有且只能有一个. 下面是C语言标准的主函数写法.
int main()
{
return 0;
}上面的写法中有一个"呼应"的关系.
return 0;, 也就是返回0, 这里的意思就是返回一个整数;
在main()前有一个int, 这个int代表一个整型类型;
()为函数的参数.
我们在main中打印字符串hehe:
printf("hehe\n");上面用双引号引起的"hehe\n"是一个字符串, 其中\n是转义字符, 表示换行, 整个代码printf表示把hehe这句话打印在屏幕上,并换行一次.
printf是一个C语言中的库函数, 专门用于打印数据, 那么它并不是我们自己创造的一个函数, 是C语言所提供给我们的, 所以在使用的时候需要在代码前面声明到它的头文件即#include<stdio.h>
通俗来说就是告诉C语言的库, 我们需要这个函数, 说一声, 就可以拿来用了.
stdio.h中std就是标准的意思,i即input,o即output.
如果不包含头文件, 直接运行会报错:


所以必须包含头文件.

3. 数据类型
下面的数据类型是C语言中较为常见的数据类型:
char // 字符数据类型
short // 短整型
int // 整型
long // 长整型
long long // 更长的整型
float // 单精度浮点数
double // 双精度浮点数- 为什么要有这么多数据类型?
首先我们写代码是为了解决生活中的问题, 比如购物, 点餐, 看电影等等, 此时涉及到了所花的价格, 比如66, 或者66.6, 那么66就是整数, 66.6就是小数, 如果我们想写代码描述这两个数字, 就会需要不同的数据类型. 对于小数C语言就抽象出来浮点数的概念, 对于整数则是整型. 所以我们的编程, 我们的计算机是源于生活的.
- 每种类型的大小是多少?
我们使用sizeof()返回的是参数类型在内存中所占的大小.
pringf中, 使用%可以指定打印的格式, 比如%d就是指定打印整型, %zu是用于用于格式化输出size_t类型的变量.size_t是一个无符号整数类型,通常用于表示内存分配、数组索引、字符串长度等与内存大小相关的值。
printf("%d\n", 100);
printf("%zu\n", sizeof(char));
printf("%zu\n", sizeof(short));
printf("%zu\n", sizeof(int));
printf("%zu\n", sizeof(long));
printf("%zu\n", sizeof(long long));
printf("%zu\n", sizeof(float));
printf("%zu\n", sizeof(double));
可以看到, 打印了各种数据类型在内存中的大小, 那么这里他们的单位为字节.
计算机中的单位
bit(比特位):计算机中最小的数据单位,表示0或1。
byte(字节):计算机中常用的数据单位,通常由8个比特位组成。
kb(千字节):等于1024字节。
mb(兆字节):等于1024千字节,即1024 * 1024字节。
gb(千兆字节):等于1024兆字节,即1024 * 1024 * 1024字节。
tb(太字节):等于1024千兆字节,即1024 * 1024 * 1024 * 1024字节。
pb(拍字节):等于1024太字节,即1024 * 1024 * 1024 * 1024 * 1024字节。
这些单位常用于描述存储容量或数据传输速度。例如,当我们谈论硬盘的容量时,通常会使用GB或TB作为单位;当我们谈论文件大小时,通常会使用KB、MB或GB作为单位;当我们谈论网络传输速度时,通常会使用Mbps(兆比特每秒)或Gbps(千兆比特每秒)作为单位。
C语言规定: sizeof(long) >= sizeof(int)
3.1 类型的使用
类型是用于创建变量的, 创建变量的本质是向内存申请空间.
int age = 20;
double price = 66.6;类型 变量名 = 值;向内存申请了空间, 把值存放进这些空间中.
4. 变量, 常量
生活中的有些值是不变的 (比如: 圆周率,性别,身份证号码,血型等等);
有些值是可变的 (比如: 年龄,体重,薪资).
不变的值,C语言中用常量的概念来表示,变得值C语言中用变量来表示.
4.1 定义变量的方法
short age = 20; // 年龄
int high = 10; // 身高
float weight = 88.5 // 体重4.2 变量的分类
- 局部变量
- 全局变量
如下所示, 可以看到, 变量b定义在{}外, 它的范围更广, 而a定义在{}里面, 它的范围受到了一定的限制. 所以全局变量就是定义在{}外部定义的变量, 局部变量就是定义在{}内部的变量.
#include<stdio.h>
int b = 20; // 全局变量
int main()
{
int a = 10; // 局部变量
return 0;
}注意点
- 在同一个范围内, 变量不能重复定义;
输入以下代码并运行:

可以看到, 当重复定义了相同的变量之后, 执行C程序, 会直接报错.
- 全局变量和局部变量的名字是可以相同的, 并且当全局变量和局部变量名字相同的情况下, 局部变量优先使用.

但是建议不要将全局变量和局部变量的名字写成一样的
4.3 变量的使用
小Tips: 创建变量的时候便将其赋值, 即 初始化.
因为不初始化编译器就会警告, 并且里面放的是一个随机值.
来看如下示例: 写一个代码, 计算两个整数的和:
int main()
{
int num1 = 0; // 初始化
int num2 = 0; // 初始化
// 输入两个整数
scanf("%d %d", &num1, &num2);
// 求和
int sum = num1 + num2;
// 输出
printf("%d\n", sum);
return 0;
}scanf()是一个输入函数
printf()是一个输出函数
当运行之后我们预期为输入两个数字, 由程序求和并输出, 但是实际运行结果则不然:

可以看到, 程序报错了,错误位置为scanf , 错误说明的中文意思为:
'scanf': 此函数或变量可能不安全。请考虑改用scanf_s。要禁用弃用,请使用_CRT_SECURE_NO_WARNINGS
那么要解决这个问题, 只需要在源代码第一行使用_CRT_SECURE_NO_WARNINGS, 就不会报错了, 即:
#define _CRT_SECURE_NO_WARNINGS 重新运行程序之后, 输入100 200, 并按下回车, 可以看到程序按照预期结果执行了加法操作.

scanf_s 这个函数是VS编译器自己提供的函数
非标准C提供的函数,那也就是只有VS编译器认识
其他编译器不认识!建议是使用scanf
如果读者非要使用scanf_s,请读者研究一下再使用!
可以在VS的安装路径下配置newc++file.cpp 文件, 以此实现每次新建一个c文件的时候都会自动添加#define _CRT_SECURE_NO_WARNINGS .
因为在VS工程中创建新的.c或者.cpp文件的时候,都是拷贝了newc++file.cpp这个文件.
我们找到该文件,

并用记事本的方式打开,

然后复制#define _CRT_SECURE_NO_WARNINGS 到文件中并保存.
如果不能保存, 可以将该文件拷贝一份到任意目录下, 并编辑, 再将写好的文件替换放到该文件目录.
保存了之后, 以后创建新的c文件就都会有该声明代码了.
例如新建add.c文件

注: 可以通过everything快速找到该文件.

4.4 变量的作用域和生命周期
作用域
作用域 (scope) 是程序设计概念,通常来说,一段程序代码中所用到的名字并不总是有效/可用的
而限定这个名字的可用性的代码范围就是这个名字的作用域
- 局部变量的作用域是变量所在的局部范围。
- 全局变量的作用域是整个工程.
生命周期
变量的生命周期指的是变量的创建到变量的销毁之间的一个时间段
- 局部变量的生命周期是: 进入作用域生命周期开始,出作用域生命周期结束。
- 全局变量的生命周期是: 整个程序的生命周期。
4.5 常量
常量就是描述不变的量.
C语言中的常量分为以下以下几种:
- 字面常量
const修饰的常变量- #define 定义的标识符常量
- 枚举常量
#define _CRT_SECURE_NO_WARNINGS
#include<stdio.h>
int main()
{
// 1. 字面常量
30; // 直接写个数字就是字面常量, 不能被改
3.14; // 字面浮点数常量
'w'; // 字符
"abc"; // 字符串常量
// 2. const 修饰的常变量
int a = 10; // 此时 a 为变量, 可以修改
//const int a = 10; // 此时编译就会报错: "左值指定const对象", 也就是 a 编译器不让改.
// C语言中, const修饰的a, 本质是变量, 但是不能直接修改, 有常量的属性.
a = 20;
printf("%d\n", a); // 20
// 证明 a 为变量
int arr[10] = { 0 }; // 创建一个数组, 这一块数组为一个连续的空间, 它里面可以存放十个整型.
int n = 10;
int arr[n] = { 0 }; // 报错: 表达式必须含有常量值; 应输入常量表达式.
// 此处n为变量, 变量不能放在 [] 中.
// 如果给变量n加上const, n本质上还是变量, 所以会报和上面相同的错.
const int n = 10;
int arr[n] = { 0 };
// 所以前面的a具有了常属性, 是不可修改的
return 0;
}注: 以上代码是会直接报错, 无法运行
// 3. #define 定义的标识符常量
#define MAX 100
#define STR "abcdef"
int main()
{
printf("%d\n", MAX); // 100
int a = MAX;
printf("%d\n", a); // 100
printf("%s\n", STR); // abcdef
MAX = 200; // 报错: 表达式必须是可修改的左值.
return 0;
}// 4. 枚举常量
enum Color {
// 枚举常量
// 三原色的可能取值, 也就是三个列出来的枚举常量
RED,
GREEN,
BLUE
// 此时我们就说, Red Green Blue 是 Color 的可能取值.
}; // 这是一段代码, 此时这个枚举类型还没有创建对象. 在 main 中创建对象
int main()
{
// 列出"三原色"
// Red Green Blue
enum Color c = RED; // 创建 Color 类型的一个变量为 c, 赋值为 RED
//RED = 20; // err
return 0;
}5. 字符串+转义字符+注释
5.1 字符串
我们能通过键盘输入很多东西, 比如: "#QWERTY$"..... 那么我们C语言就是通过char字符类型来描述字符, 同样也给了我们一种描述字符常量的形式单引号, 比如'a'. 如果要把这个字符常量存起来就需要一个字符的变量.
int main()
{
char ch = 'w';
return 0;
}我们也可以使用双引号来描述一个字符串.
"acbdef"; // 一对双引号引起的叫做字符串这种由双引号(Double Quote) 引起来的一串字符称为字符串字面值 (String Literal) ,或者简称字符串。
输入以下代码
int main()
{
// 存字符串: 存到字符数组中
char arr[] = "abcdef";
// [] 中间可以写也可以不写, 当没有写的时候, 就会根据后面的内容确定字符数组的大小.
return 0;
}我们来看一下 "abcdef" 往 arr[] 中放的时候, arr[] 是放了什么, 按下F10进行调试.
在VS2019的菜单栏调试中有监视窗口.
监视窗口,
那么我们可以输入arr, 此时可以看到arr中每个元素都放的是什么.

注意到arr[6]有一个\0, 但是我们的代码中是没有\0的, 那么此处是因为字符串的结束标志是一个\0的转义字符。在计算字符串长度的时候\0是结束标志,不算作字符串内容。
关于 '\0'是字符串结束标志的说明(重要)
- 例一
int main()
{
char arr1[] = "abcdef"; // 7个字符
char arr2[] = { 'a','b','c','d','e','f' }; // 主动放字符到数组中.
return 0;
}在调试中查看arr1和arr2的区别.
第一种形式用字符串的形式来初始化, 由于隐藏了\0, 所以在监视中看到是arr1中有'\0'.
第二种形式是主动将字符一个一个放到数组中, 此时就没有'\0', 这是两者形式上的区别.

那么使用上有何差异? 我们使用如下代码查看.
printf("%s\n", arr1);
printf("%s\n", arr2);
我们知道, 上面的arr都是在内存的一部分空间进行使用, 而内存是非常大的一块空间, 并且它是连续的, 所以当对arr1打印的时候, 遇到末尾的'\0'就会直接停止, 而arr2会一直往后进行, 直到遇到'\0'才会停止.

所以, 当主动加上'\0'之后, arr1和arr2两者的打印效果就一样了.

- 例二
C语言中有一个库函数是strlen()(String length), 是求字符串有效长度的一个函数, 参数可以是字符串, 也可以是字符数组名, 然后会返回一个int类型的结果. (该库函数使用时需要包含头文件string.h)
#include<stdio.h>
#include<string.h>
int main()
{
int len = strlen("abc");
printf("%d\n", len);
char arr1[] = "abcdef";
char arr2[] = { 'a','b','c','d','e','f','\0' };
printf("%d\n", strlen(arr1));
printf("%d\n", strlen(arr2));
return 0;
}
删掉arr2的'\0'后:

5.2 转义字符
转义字符的意思就是转变原来字符的意思.
先来看一下换行符.

由图中的有无换行符的运行对比可以看出, 换行符就是进行了一次换行操作, 将原来"csdn"中的"n"字符转为换行符.
C语言常见转义字符
| 转义字符 | 释义 |
|---|---|
| \? | 在书写连续多个问号时使用,防止他们被解析成三字母词 |
| \' | 用于表示字符常量' |
| \" | 用于表示一个字符串内部的双引号 |
| \\ | 用于表示一个反斜杠,防止它被解释为一个转义序列符 |
| \a | 警告字符,蜂鸣 |
| \b | 退格符 |
| \f | 进纸符 |
| \n | 换行 |
| \r | 回车 |
| \t | 水平制表符 |
| \v | 垂直制表符 |
| \ddd | ddd表示1~3个八进制的数字。如: \130 X |
| \xdd | dd表示2个十六进制数字。如: x30 0 |
转义字符的使用
%d -> 打印整型
%c -> 打印字符
%s -> 打印字符串
%f -> 打印 float 类型的数据
%lf -> 打印 double 类型的数据
%zu -> 打印 sizeof 的返回值
int main()
{
// \? 使用较少 三字母词: 早期的编译器会这么解析 ??) -> ] ??( -> [
printf("%s\n", "(Are you ok\?\?)"); // (Are you ok??)
// \'
printf("%c\n", 'w'); // w
//printf("%c\n", '''); // 报错: 空字符常量
printf("%c\n", '\''); // '
// \"
printf("abcdef\n"); // abcdef
printf("\"\n"); // "
// { \\ }
printf("abc\\0def\n"); // abc\0def
printf("c:\test\test.c\n"); // c: est est.c
printf("c:\\test\\test.c\n"); // c:\test\test.c
// \a
printf("\a\n"); // (系统蜂鸣警告)
// \t
printf("abc\nd\tef\n"); // abc
// d ef
//
return 0;
}运行结果

// \ddd -> ddd表示1~3个八进制的数字。 如: \130 -> X
int main()
{
printf("%c\n", '\130');
return 0;
}
可以看到上面代码中, \后面跟了三个数字130, 这三个数字代表的是130这个八进制数字转化成十进制之后的数字作为ASCII码值代表的字符.
八进制130转换成十进制值: 逆序地分别将每个数字乘以8的从零开始的次方并相加.
所以八进制的130转换成十进制就是88.
我们键盘上能敲出很多字符, 比如abcdef, #, @, ... 要注意的是我们计算机内存的存储是二进制形式, 那么对于这些字符是不好用二进制的形式进行存储的, 于是就要对这些字符进行统一标准的编号——ASCII编码表.

那么从上表可知, 八进制数字130对应的字符即为X.
同理, 十六进制的\xdd的使用如下:
printf("%c\n", '\x60');十六进制60转化为十进制数字:
所以十六进制60对应的十进制数字为96, 96作为ASCII码值对应的字符为`.
注意不管是dd还是ddd都不能超范围, 超范围就无意义了.
一道小例题
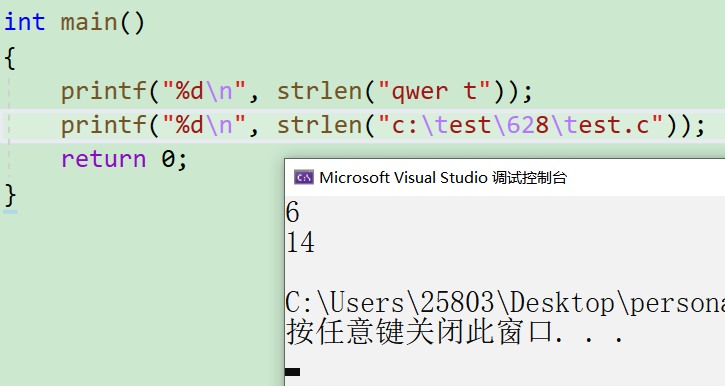
注意: \t算一个字符, \62算一个字符.
6. 注释
- 代码中有不需要的代码可以直接删除,也可以注释掉
- 代码中有些代码比较难懂,可以加一下注释文字
int main()
{
//int a = 10;
/*
int m = 0;
int n = 0;
*/
// 创建指针变量p, 并赋值为 NULL
int* p = NULL;
return 0;
}注释有两种风格:
- C语言风格的注释
/*XXXXXX*/- 缺陷: 不能嵌套注释
- C++风格的注释
//xxxxxxxx- 可以注释一行也可以注释多行