🔎大家好,我是Sonhhxg_柒,希望你看完之后,能对你有所帮助,不足请指正!共同学习交流🔎
📝个人主页-Sonhhxg_柒的博客_CSDN博客 📃
🎁欢迎各位→点赞👍 + 收藏⭐️ + 留言📝
📣系列专栏 - 机器学习【ML】 自然语言处理【NLP】 深度学习【DL】
🖍foreword
✔说明⇢本人讲解主要包括Python、机器学习(ML)、深度学习(DL)、自然语言处理(NLP)等内容。
如果你对这个系列感兴趣的话,可以关注订阅哟👋
文章目录
什么是 TensorFlow Lite?
演练:创建模型并将其转换为 TensorFlow Lite
步骤 1. 保存模型
步骤 2. 转换并保存模型
第 3 步. 加载 TFLite 模型并分配张量
步骤 4. 执行预测
演练:迁移学习图像分类器并转换为 TensorFlow Lite
步骤 1. 构建并保存模型
步骤 2. 将模型转换为 TensorFlow Lite
步骤 3. 优化模型
概括
在到目前为止,在本书的所有章节中,您一直在探索如何使用 TensorFlow 创建机器学习模型,这些模型可以在没有显式规则编程的情况下提供计算机视觉、自然语言处理和序列建模等功能。相反,使用标记数据,神经网络能够学习将一件事与另一件事区分开来的模式,然后可以将其扩展到解决问题中。对于本书的其余部分,我们将换档看看如何在常见场景中使用这些模型。我们将介绍的第一个也是最明显也可能是最有用的主题是如何在移动应用程序中使用模型。在本章中,我将介绍使在移动(和嵌入式)设备上进行机器学习成为可能的底层技术:TensorFlow Lite。然后,在接下来的两章中,我们将探讨在 Android 和 iOS 上使用这些模型的场景。
TensorFlow 精简版是一套补充 TensorFlow 的工具,可实现两个主要目标。首先是使您的模型适合移动设备。这通常涉及减小它们的尺寸和复杂性,尽可能减少对其准确性的影响,以使它们在电池受限的环境(如移动设备)中更好地工作。二是为不同的移动平台提供运行时,包括Android、iOS、移动Linux(例如Raspberry Pi)和各种微控制器。请注意,您无法使用 TensorFlow Lite训练模型。您的工作流程将是使用 TensorFlow 对其进行训练,然后将其转换为 TensorFlow Lite 格式,然后使用 TensorFlow Lite 解释器加载和运行它。
什么是 TensorFlow Lite?
TensorFlow 精简版最初是针对 Android 和 iOS 开发人员的 TensorFlow 移动版本,目标是成为满足他们需求的有效 ML 工具包。在计算机或云服务上构建和执行模型时,电池消耗、屏幕尺寸和移动应用程序开发的其他方面等问题都不是问题,因此当以移动设备为目标时,需要解决一组新的限制条件。
这首先是移动应用程序框架需要轻量级。与用于训练模型的典型机器相比,移动设备的资源有限得多。因此,开发人员必须非常注意不仅由应用程序使用的资源,而且还要注意应用程序框架使用的资源。事实上,当用户浏览应用程序商店时,他们会看到每个应用程序的大小,并且必须根据他们的数据使用情况来决定是否下载它。如果运行模型的框架很大,模型本身也很大,这会使文件大小膨胀并让用户失望。
在与低延迟合作,移动框架需要高效的模型格式。在强大的超级计算机上训练时,模型格式通常不是最重要的信号。正如我们在前面的章节中看到的,高模型精度、低损失、避免过度拟合等是模型创建者将追求的指标。但是在移动设备上运行时,为了轻量级和低延迟,还需要考虑模型格式。到目前为止,我们看到的神经网络中的大部分数学运算都是高精度的浮点运算。对于科学发现,这是必不可少的。对于在移动设备上运行,它可能不是。一个适合移动设备的框架将需要帮助您进行这样的权衡,并在必要时为您提供转换模型的工具。
因此,考虑到所有这些,创建了 TensorFlow Lite。如前所述,它不是训练模型的框架,而是一组补充工具,旨在满足移动和嵌入式系统的所有限制。
它广义上应该被视为两个主要的东西:一个转换器,它接受你的 TensorFlow 模型并将其转换为.tflite格式,缩小和优化它,以及一套用于各种运行时的解释器(图 12-1)。
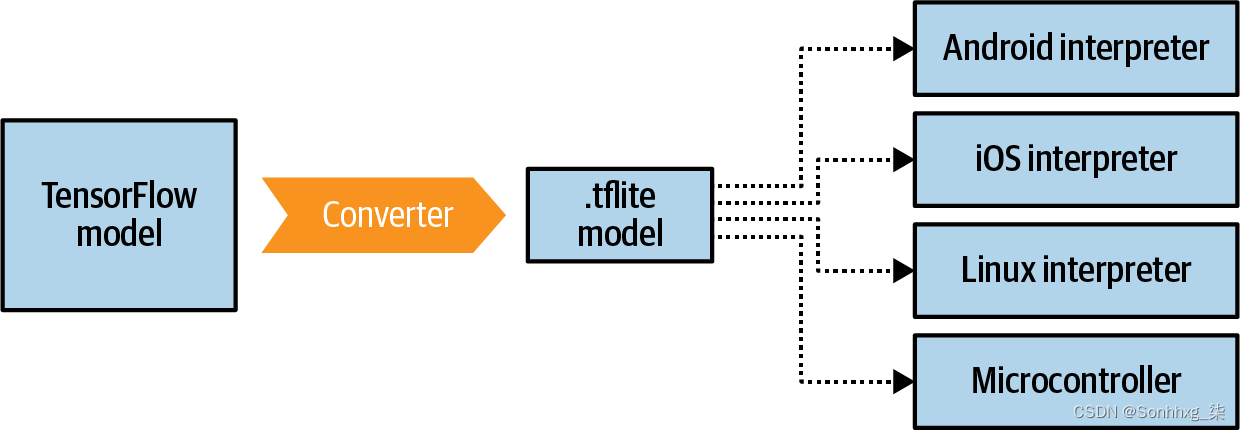
图 12-1。TensorFlow Lite 套件
解释器环境还支持其特定框架内的加速选项。例如,在 Android 上 支持神经网络 API,因此 TensorFlow Lite 可以在可用的设备上利用它。
请注意,TensorFlow Lite 或 TensorFlow Lite 转换器目前不支持 TensorFlow 中的每个操作(或“op”)。您在转换模型时可能会遇到此问题,最好查看文档以了解详细信息。正如您将在本章后面看到的,一个有用的工作流程是采用现有的移动友好模型并为您的场景使用迁移学习。你可以在TensorFlow 网站上找到经过优化以与 TensorFlow Lite 配合使用的模型列表,并且 张量流枢纽。
演练:创建模型并将其转换为 TensorFlow Lite
出色地从分步演练开始,展示如何使用 TensorFlow 创建简单模型,将其转换为 TensorFlow Lite 格式,然后使用 TensorFlow Lite 解释器。对于本演练,我将使用 Linux 解释器,因为它在 Google Colab 中很容易获得。在第 13 章中,您将了解如何在 Android 上使用该模型,在第 14 章中,您将探索如何在 iOS 上使用它。
回到第 1 章,您看到了一个非常简单的 TensorFlow 模型,该模型学习了最终为 Y = 2X – 1 的两组数字之间的关系。为方便起见,完整代码如下:
l0 = Dense(units=1, input_shape=[1])
model = Sequential([l0])
model.compile(optimizer='sgd', loss='mean_squared_error')
xs = np.array([-1.0, 0.0, 1.0, 2.0, 3.0, 4.0], dtype=float)
ys = np.array([-3.0, -1.0, 1.0, 3.0, 5.0, 7.0], dtype=float)
model.fit(xs, ys, epochs=500)
print(model.predict([10.0]))
print("Here is what I learned: {}".format(l0.get_weights()))一旦训练完成,如您所见,您就可以做到model.predict[x]并获得预期的y. 在前面的代码中,x=10模型y将返回给我们的值接近 19。
由于此模型很小且易于训练,我们可以将其用作我们将转换为 TensorFlow Lite 以展示所有步骤的示例。
步骤 1. 保存模型
这TensorFlow Lite 转换器适用于多种不同的文件格式,包括SavedModel(首选)和凯拉斯 H5 格式。对于本练习,我们将使用SavedModel。
为此,只需指定保存模型的目录并调用tf.saved_model.save,将模型和目录传递给它:
export_dir = 'saved_model/1'
tf.saved_model.save(model, export_dir)模型将被保存为资产和变量以及saved_model.pb文件,如图 12-2所示。

图 12-2。SavedModel结构
保存模型后,您可以使用 TensorFlow Lite 转换器对其进行转换。
笔记
TensorFlow 团队建议使用 SavedModel 格式以实现整个 TensorFlow 生态系统的兼容性,包括未来与新 API 的兼容性。
步骤 2. 转换并保存模型
这TensorFlow Lite 转换器在tf.lite包中。您可以通过首先调用它来调用它来转换保存的模型 from_saved_model方法,将包含已保存模型的目录传递给它,然后调用它的convert方法:
# Convert the model.
converter = tf.lite.TFLiteConverter.from_saved_model(export_dir)
tflite_model = converter.convert()然后,您可以使用以下方法保存新的.tflite模型pathlib:
import pathlib
tflite_model_file = pathlib.Path('model.tflite')
tflite_model_file.write_bytes(tflite_model)此时,您有一个可以在任何解释器环境中使用的.tflite文件。稍后我们将在 Android 和 iOS 上使用它,但现在,让我们使用基于 Python 的解释器,以便您可以在 Colab 中运行它。同样的解释器可用于嵌入式 Linux 环境,如 Raspberry Pi!
第 3 步. 加载 TFLite 模型并分配张量
这下一步是将模型加载到解释器中,将用于输入数据的张量分配给模型进行预测,然后读取模型输出的预测。从程序员的角度来看,这就是使用 TensorFlow Lite 与使用 TensorFlow 有很大不同的地方。使用 TensorFlow,您可以直接说出并获得结果,但由于 TensorFlow Lite 没有 TensorFlow 所具有的许多依赖项,尤其是在非 Python 环境中,您现在必须获得更底层的信息并处理输入并输出张量,格式化您的数据以适合它们并以对您的设备有意义的方式解析输出。model.predict(something)
首先,加载模型并分配张量:
interpreter = tf.lite.Interpreter(model_content=tflite_model)
interpreter.allocate_tensors()然后您可以从模型中获取输入和输出的详细信息,这样您就可以开始了解它期望的数据格式,以及它将返回给您的数据格式:
input_details = interpreter.get_input_details()
output_details = interpreter.get_output_details()
print(input_details)
print(output_details)你会得到很多输出!
首先,让我们检查输入参数。请注意shape设置,它是 type 的数组[1,1]。还要注意类,它是numpy.float32. 这些设置将决定输入数据的形状及其格式:
[{'name': 'dense_input', 'index': 0, 'shape': array([1, 1], dtype=int32),
'shape_signature': array([1, 1], dtype=int32), 'dtype': <class
'numpy.float32'>, 'quantization': (0.0, 0), 'quantization_parameters':
{'scales': array([], dtype=float32), 'zero_points': array([], dtype=int32),
'quantized_dimension': 0}, 'sparsity_parameters': {}}]所以,为了格式化输入数据,如果你想预测yfor ,你需要使用这样的代码来定义输入数组的形状和类型x=10.0:
to_predict = np.array([[10.0]], dtype=np.float32)
print(to_predict)周围的双括号10.0可能会引起一些混淆——我在array[1,1]这里使用的助记符是说有一个列表,给我们第一组[],而该列表只包含一个值,即[10.0],因此给出[[10.0]]。dtype=int32形状定义为,而您使用的是 ,这也可能令人困惑numpy.float32。参数是定义形状的dtype数据类型,而不是封装在该形状中的列表的内容。为此,您将使用该类。
输出细节非常相似,这里要注意的是形状。因为它也是 type 的数组[1,1],所以您可以预期答案[[y]]与输入的方式大致相同[[x]]:
[{'name': 'Identity', 'index': 3, 'shape': array([1, 1], dtype=int32),
'shape_signature': array([1, 1], dtype=int32), 'dtype': <class
'numpy.float32'>, 'quantization': (0.0, 0), 'quantization_parameters':
{'scales': array([], dtype=float32), 'zero_points': array([], dtype=int32),
'quantized_dimension': 0}, 'sparsity_parameters': {}}]步骤 4. 执行预测
至让解释器进行预测,将输入张量设置为要预测的值,告诉它要使用的输入值:
interpreter.set_tensor(input_details[0]['index'], to_predict)
interpreter.invoke()输入张量使用输入详细信息数组的索引指定。在这种情况下,您有一个非常简单的模型,它只有一个输入选项,所以它是input_details[0],您将在索引处解决它。输入详细信息项 0 只有一个索引,索引为 0,并且它需要一个[1,1]如前定义的形状。所以,你把to_predict价值放在那里。然后使用该invoke方法调用解释器。
然后,您可以通过调用get_tensor并提供您想要读取的张量的详细信息来读取预测:
tflite_results = interpreter.get_tensor(output_details[0]['index'])
print(tflite_results)同样,只有一个输出张量,因此它将是output_details[0],并且您指定索引以获取其下方的详细信息,它将具有输出值。
因此,例如,如果您运行此代码:
to_predict = np.array([[10.0]], dtype=np.float32)
print(to_predict)
interpreter.set_tensor(input_details[0]['index'], to_predict)
interpreter.invoke()
tflite_results = interpreter.get_tensor(output_details[0]['index'])
print(tflite_results)你应该看到如下输出:
[[10.]]
[[18.975412]]其中10是输入值,18.97是预测值,非常接近19,即X=10时2X-1。为什么不是19,请回头看第一章!
鉴于这是一个非常简单的例子,接下来让我们看一些更复杂的东西——在一个著名的图像分类模型上使用迁移学习,然后将其转换为 TensorFlow Lite。从那里我们也将能够更好地探索优化和量化模型的影响。
独立解释器
TensorFlow 精简版是整个 TensorFlow 生态系统的一部分,由转换训练模型和解释模型所需的工具组成。在接下来的两章中,您将分别了解如何使用 Android 和 iOS 的解释器,但还有一个基于 Python 的独立解释器,可以安装在任何运行 Python 的系统上,例如树莓派。这为您提供了一种在可运行 Python 的嵌入式系统上运行模型的方法。从句法上讲,它的工作方式与您刚才看到的解释器相同。
演练:迁移学习图像分类器并转换为 TensorFlow Lite
在本节中,我们将构建一个新版本的第3章和第4章使用迁移学习的 Dogs vs. Cats 计算机视觉模型。这将使用来自 TensorFlow Hub 的模型,因此如果您需要安装它,您可以按照网站上的说明进行操作。
步骤 1. 构建并保存模型
import numpy as np
import matplotlib.pylab as plt
import tensorflow as tf
import tensorflow_hub as hub
import tensorflow_datasets as tfds
def format_image(image, label):
image = tf.image.resize(image, IMAGE_SIZE) / 255.0
return image, label
(raw_train, raw_validation, raw_test), metadata = tfds.load(
'cats_vs_dogs',
split=['train[:80%]', 'train[80%:90%]', 'train[90%:]'],
with_info=True,
as_supervised=True,
)
num_examples = metadata.splits['train'].num_examples
num_classes = metadata.features['label'].num_classes
print(num_examples)
print(num_classes)
BATCH_SIZE = 32
train_batches =
raw_train.shuffle(num_examples // 4)
.map(format_image).batch(BATCH_SIZE).prefetch(1)
validation_batches = raw_validation.map(format_image)
.batch(BATCH_SIZE).prefetch(1)
test_batches = raw_test.map(format_image).batch(1)这将下载 Dogs vs. Cats 数据集并将其拆分为训练集、测试集和验证集。
接下来,你将使用mobilenet_v2来自 TensorFlow Hub 的模型创建一个名为feature_extractor:
module_selection = ("mobilenet_v2", 224, 1280)
handle_base, pixels, FV_SIZE = module_selection
MODULE_HANDLE ="https://tfhub.dev/google/tf2-preview/{}/feature_vector/4"
.format(handle_base)
IMAGE_SIZE = (pixels, pixels)
feature_extractor = hub.KerasLayer(MODULE_HANDLE,
input_shape=IMAGE_SIZE + (3,),
output_shape=[FV_SIZE],
trainable=False)现在您有了特征提取器,您可以将其作为神经网络的第一层,并添加一个输出层,其中的神经元数量与您的类数量(在本例中为两个)相同。然后你可以编译和训练它:
model = tf.keras.Sequential([
feature_extractor,
tf.keras.layers.Dense(num_classes, activation='softmax')
])
model.compile(optimizer='adam',
loss='sparse_categorical_crossentropy',
metrics=['accuracy'])
hist = model.fit(train_batches,
epochs=5,
validation_data=validation_batches)仅需五个时期的训练,这应该给出一个在训练集上具有 99% 准确率和在验证集上具有 98% 以上准确率的模型。现在您可以简单地保存模型:
CATS_VS_DOGS_SAVED_MODEL = "exp_saved_model"
tf.saved_model.save(model, CATS_VS_DOGS_SAVED_MODEL)保存模型后,您可以对其进行转换。
步骤 2. 将模型转换为 TensorFlow Lite
作为以前,您现在可以使用保存的模型并将其转换为.tflite模型。您将其保存为converted_model.tflite:
converter = tf.lite.TFLiteConverter.from_saved_model(CATS_VS_DOGS_SAVED_MODEL)
tflite_model = converter.convert()
tflite_model_file = 'converted_model.tflite'
with open(tflite_model_file, "wb") as f:
f.write(tflite_model)一旦你有了这个文件,你就可以用它实例化一个解释器。完成后,您应该像以前一样获得输入和输出详细信息。分别将它们加载到名为input_index和output_index的变量中。这使代码更具可读性!
interpreter = tf.lite.Interpreter(model_path=tflite_model_file)
interpreter.allocate_tensors()
input_index = interpreter.get_input_details()[0]["index"]
output_index = interpreter.get_output_details()[0]["index"]
predictions = []数据集在 中有很多测试图像test_batches,所以如果你想拍摄一百张图像并测试它们,你可以这样做(随意将 更改100为任何其他值):
test_labels, test_imgs = [], []
for img, label in test_batches.take(100):
interpreter.set_tensor(input_index, img)
interpreter.invoke()
predictions.append(interpreter.get_tensor(output_index))
test_labels.append(label.numpy()[0])
test_imgs.append(img)早些时候,在读取图像时,它们被调用的映射函数重新格式化format_image为适合训练和推理的大小,因此您现在要做的就是将解释器的张量设置为图像的输入索引。调用解释器后,您可以在输出索引处获取张量。
如果您想查看预测对标签的效果如何,您可以运行如下代码:
score = 0
for item in range(0,99):
prediction=np.argmax(predictions[item])
label = test_labels[item]
if prediction==label:
score=score+1
print("Out of 100 predictions I got " + str(score) + " correct")这应该会给您 99 分或 100 分正确预测。
您还可以使用以下代码根据测试数据可视化模型的输出:
for index in range(0,99):
plt.figure(figsize=(6,3))
plt.subplot(1,2,1)
plot_image(index, predictions, test_labels, test_imgs)
plt.show()您可以在图 12-3中看到其中的一些结果。(请注意,本书的GitHub 存储库中提供了所有代码,因此如果您需要,请查看那里。)

图 12-3。推理结果
这只是简单的转换模型,没有添加任何针对移动设备的优化。在下一步中,您将探索如何针对移动设备优化此模型。
步骤 3. 优化模型
现在如果您已经了解了训练、转换和使用带有 TensorFlow Lite 解释器的模型的端到端过程,让我们看看如何开始优化和量化模型。
这第一种优化称为动态范围量化,是通过optimizations在执行转换之前设置转换器的属性来实现的。这是代码:
converter = tf.lite.>TFLiteConverter.from_saved_model(CATS_VS_DOGS_SAVED_MODEL)
converter.optimizations = [tf.lite.>Optimize.DEFAULT]
tflite_model = converter.convert()
tflite_model_file = >'converted_model.tflite'
>with open(tflite_model_file, >"wb") >as f:
f.write(tflite_model)在撰写本文时,有几个可用的优化选项(稍后可能会添加更多)。这些包括:
OPTIMIZE_FOR_SIZE:执行使模型尽可能小的优化。
OPTIMIZE_FOR_LATENCY:执行优化以尽可能减少推理时间。
DEFAULT:在大小和延迟之间找到最佳平衡点。
在这种情况下,模型大小在这一步之前接近 9 MB,但之后只有 2.3 MB——减少了近 70%。各种实验表明,模型可以缩小 4 倍,加速 2-3 倍。但是,根据模型类型,准确性可能会有所下降,因此如果您像这样进行量化,最好彻底测试模型。在这种情况下,我发现模型的准确率从 99% 下降到 94% 左右。
你可以通过全整数量化或 float16 量化以利用特定硬件。全整数量化将模型中的权重从 32 位浮点数更改为 8 位整数,这(特别是对于较大的模型)会对模型大小和延迟产生巨大影响,而对准确性的影响相对较小。
要获得完整的整数量化,您需要指定一个代表性数据集,该数据集告诉转换器大致期望的数据范围。更新代码如下:
converter = tf.lite.TFLiteConverter.from_saved_model(CATS_VS_DOGS_SAVED_MODEL)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
def representative_data_gen():
for input_value, _ in test_batches.take(100):
yield [input_value]
converter.representative_dataset = representative_data_gen
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
tflite_model = converter.convert()
tflite_model_file = 'converted_model.tflite'
with open(tflite_model_file, "wb") as f:
f.write(tflite_model)拥有这些具有代表性的数据后,转换器可以在数据流经模型时检查数据,并找到最适合进行转换的位置。然后,通过设置支持的操作(在本例中为INT8),您可以确保仅在模型的那些部分量化精度。结果可能是一个稍大的模型——在这种情况下,它从convertor.optimizations仅使用时的 2.3 MB 增加到 2.8 MB。然而,准确率又回到了 99%。因此,通过执行这些步骤,您可以将模型的大小减少大约三分之二,同时保持其准确性!
用于微控制器的 TENSORFLOW LITE
用于微控制器的 TensorFlow Lite是 TensorFlow Lite 的一个正在进行的实验性版本,旨在运行在具有少量内存的设备上(机器学习领域通常称为TinyML)。鉴于其预期的运行时间,它是 TensorFlow 的一个大大简化的版本。它是用 C++ 编写的,可在常见的微控制器开发板上运行,例如 Arduino Nano、Sparkfun Edge 等。要了解更多信息,请查看由 Pete Warden 和 Daniel Situnayake (O'Reilly) 撰写的《 TinyML:Arduino 和超低功耗微控制器上的机器学习和 TensorFlow Lite 》一书。
概括
在本章中,您了解了 TensorFlow Lite 的介绍,并了解了它是如何设计用来让您的模型准备好在比您的开发环境更小、更轻的设备上运行的。其中包括移动操作系统,如 Android、iOS 和 iPadOS,以及基于 Linux 的移动计算环境,如 Raspberry Pi 和支持 TensorFlow 的基于微控制器的系统。您构建了一个简单的模型并使用它来探索转换工作流程。然后,您完成了一个更复杂的示例,使用迁移学习为数据集重新训练现有模型,将其转换为 TensorFlow Lite,并针对移动环境对其进行优化。在下一章中,您将利用这些知识并探索如何使用基于 Android 的解释器在您的 Android 应用程序中使用 TensorFlow Lite。