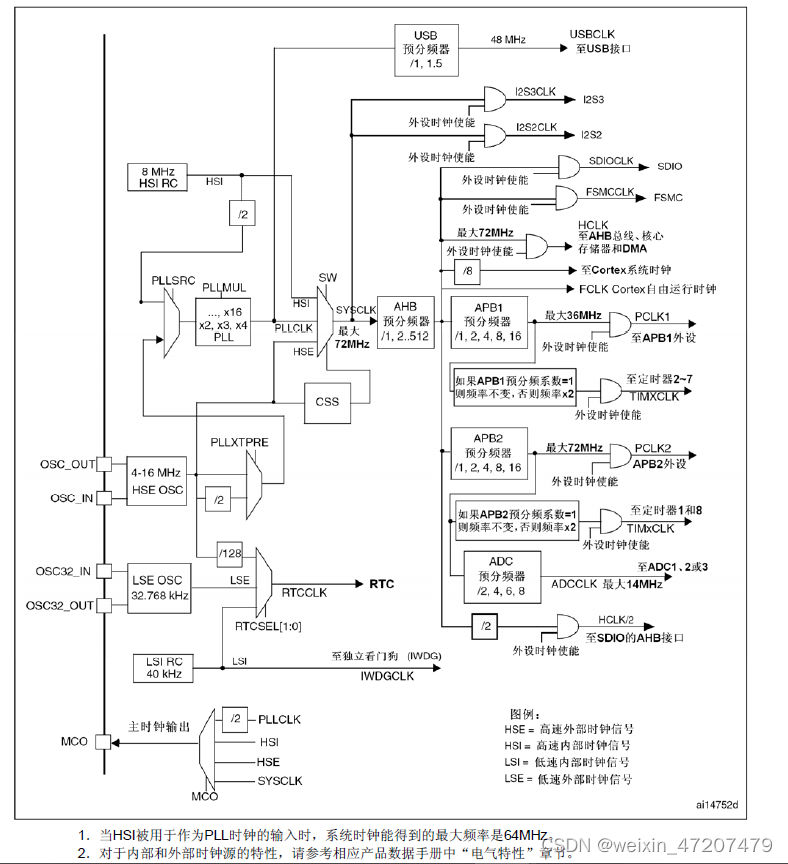
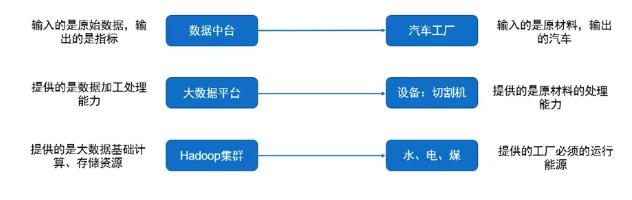
数据中台
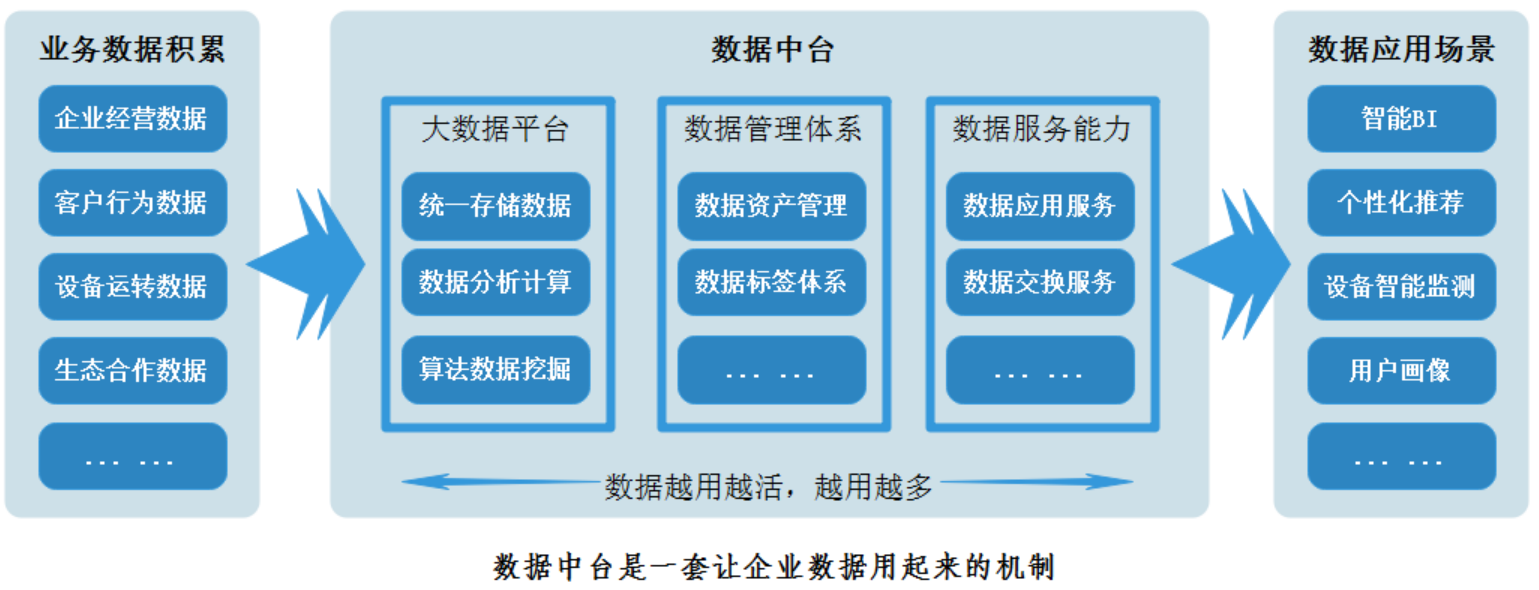
数据中台(Data Midway)是一个用于集成、存储、管理和分析数据的中心化平台或架构。它的目标是将组织内散布在各个系统、应用程序和数据源中的数据整合到一个可统一访问和管理的中心位置,以支持数据驱动的决策制定和业务需求。
数据中台具备异构数据统一计算、存储的能力,同时让分散杂乱的数据通过规范化的方式管理起来。
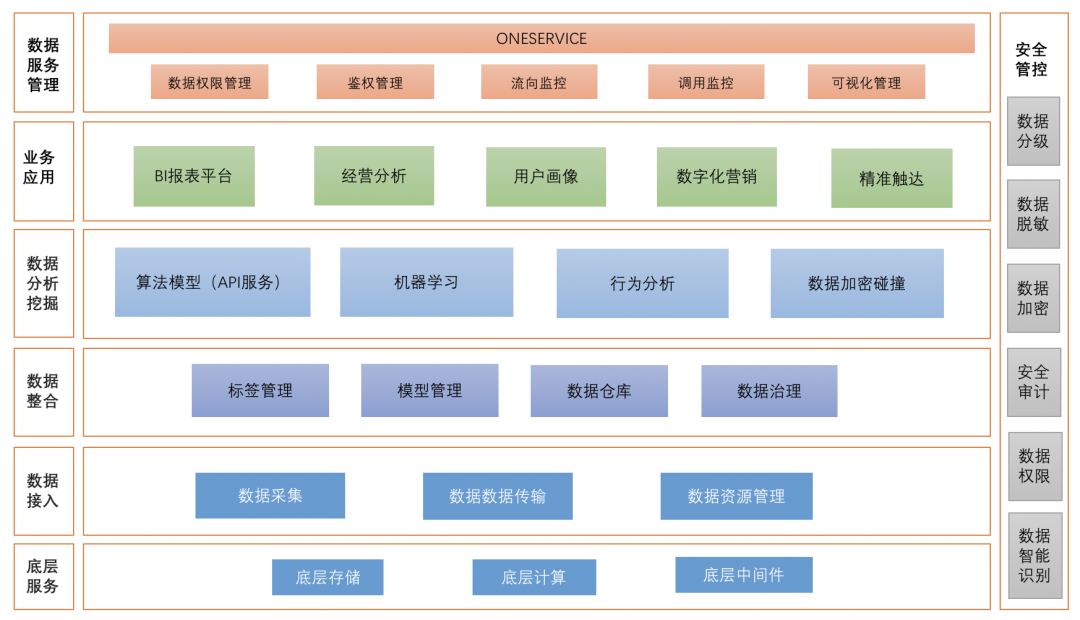
数据中台依赖于大数据平台完成数据研发全流程,同时增加了数据治理和数据服务化以及数据资产内容。
将企业的数据统一采集整合起来,借助大数据平台统一加工处理后,对外提供数据服务的一套机制。
其实,数据中台与大数据平台最本质的区别在于:
数据中台是具备业务属性的,输入的是原始业务数据,而输出的是指标,而大数据平台提供的是数据加工处理的能力。
一个数据中台包括的关键功能:
1、数据采集和集成:
- 确定数据来源:首先,确定要从哪些数据源收集数据,包括内部系统、外部数据源、传感器、数据库、日志、外部API等。
- 建立数据采集管道:创建数据采集和集成管道,用于定期或实时地从数据源中提取数据。
- 数据转换和清洗:对采集到的数据进行清洗、转换和规范化,以确保数据的质量和一致性。
2、数据存储和管理:
选择合适的数据存储,可以是数据湖或者数据仓库。
3、确保数据安全和合规性:
在数据平台中,数据的安全性和合规性至关重要。因此,您需要实施安全措施,包括数据加密、身份验证和授权,以及遵守相关的合规性法规。
- 数据加密:加密数据,确保数据在传输和存储过程中的安全性。
- 身份验证和授权:实施身份验证和授权机制,以限制对数据的访问。
4、建立数据目录和元数据管理:
为了让用户能够轻松找到和理解数据,建立数据目录是很重要的。同时,维护元数据也有助于记录数据的含义、来源和质量。
- 数据目录维护:建立数据目录,记录数据资源的描述、来源和用途,帮助用户查找所需数据。
- 元数据管理:维护元数据存储,记录数据的元数据信息,如字段定义、数据质量规则等。
5、提供数据访问和共享:
确保用户和应用程序能够方便地访问数据。这可能涉及提供数据访问接口、API,以及支持数据共享和协作的机制。
- 数据接口和API:提供数据访问接口和API,以便用户和应用程序能够查询和访问数据。
- 数据共享:支持数据共享和协作,确保不同部门和团队能够访问需要的数据。
6、支持自助数据服务:
使非技术用户能够自己进行数据查询、报告创建和数据探索。这有助于提高数据的可用性和可理解性。
- 自助查询和报告:提供工具和平台,使非技术用户能够创建自定义查询、报告和可视化。
- 数据探索工具:帮助用户发现数据关系和洞察力,支持数据自发现。
7、进行数据分析和提取洞察力:
在数据中台中集成数据分析工具,以便用户能够从数据中提取有价值的洞察力,包括数据挖掘、机器学习和可视化。
- 分析工具集成:集成数据分析工具和数据科学平台,以支持数据挖掘、机器学习和高级分析。
- 可视化:创建数据可视化报告和仪表板,以便用户能够从数据中提取洞察力。
8、管理数据质量:
确保数据平台中的数据质量,包括监控数据质量问题并采取纠正措施。
- 数据质量监控:实施数据质量监控,检测和报告数据质量问题。
- 数据清洗和纠正:提供数据清洗工具和策略,以确保数据质量。
9、支持数据共享和API:
提供API和数据集市,以便内部和外部合作伙伴能够访问和共享数据。同时,支持数据发布和订阅模式。
- API和数据集市:提供API和数据集市,以便内部和外部合作伙伴能够访问和共享数据。
- 数据发布和订阅:支持数据实时同步和传输。
10、性能优化和监控:
为了确保数据平台能够高效运行,实施性能优化策略,并使用监控工具监视平台性能和可用性。
- 性能优化:实施性能优化策略,确保数据平台能够处理大规模数据和高并发查询。
- 监控和报警:部署监控工具,监视数据平台的性能、可用性和安全性,并采取适当的行动。
11、数据治理和合规性:
建立数据治理策略,确保数据合法性和道德性,并遵守相关法规和政策。
- 数据治理策略:建立数据治理策略,包括数据所有权、访问控制和合规性规定。
- 合规性管理:确保数据平台的合法性和道德性,遵守相关法规和政策。
不同行业的数据中台应用需求
不同行业的不同企业在不同阶段,其数据应用的需求也是不一样的,数据中台的建设是一个持续完善的过程,在这个过程中,不同阶段支撑的场景数据也需要不断迭代。那么,不同行业对数据中台所支撑应用的主要需求有哪些可以参考?通过对多个行业不同企业的调研,大致总结以下几个行业所处的阶段以及各行业对数据中台的共性需求,
金融行业:业务强依赖于数据,是数据使用最深的行业,对中台是真实的强需求。基本都有自己的数仓和垂直数据应用,也有较完善的技术团队,希望自助可控,对中台服务商要求较高。
零售:一般都是多端多渠道,包含门店、App、小程序、服务号、电商等。对多渠道的数据整合运营有强需求,需要数据中台的能力支撑。大多看中短期收益,不注重建设完整的数据中台能力。
央企:业务多元化,集团形态业务板块多元,数据跨业态。信息化基础好,规模较大且业务复杂,建设数据中台的起点高。且有样板案例,龙头型央企已经开始着手建设。
数据中台的应用
我目前的理解就是,数据中台是整个企业以及各个业务数据服务的提供方。将企业的数据统一采集整合起来,借助大数据平台统一加工处理后,对外提供数据服务的一套机制。
数据中台依赖于大数据平台完成数据研发全流程,同时增加了数据治理和数据服务化以及数据资产内容。

提供销售报表
- 数据中台可以用于生成业务智能(Business Intelligence,BI)报表和仪表板。这些报表提供了数据可视化和汇总,有助于业务用户了解关键性能指标、趋势和洞察力。
- 例如,销售团队可以使用数据中台生成销售报表,监测销售额、库存情况和市场份额。
用户营销分析
对用户数据进行挖掘和分析是电商数据中台实现个性化营销和推荐的关键步骤。以下是一个通用的流程,描述了如何在电商数据中台中实施个性化营销和推荐:
-
数据采集和存储:
- 采集用户行为数据,包括用户浏览历史、购买记录、点击数据、搜索记录等。
- 存储这些数据以供后续分析使用,可以使用数据仓库或大数据存储解决方案。
-
数据清洗和预处理:
-
对采集的数据进行清洗、去重和去噪声,确保数据的质量。
-
进行数据预处理,包括填充缺失值、转换数据格式、标准化等。
-
ETL是将业务系统的数据经过抽取、清洗转换之后加载到数据仓库的过程,目的是将企业中的分散、零乱、标准不统一的数据整合到一起,为企业的决策提供分析依据, ETL是BI(商业智能)项目重要的一个环节。
-
-
用户行为分析:
- 使用数据分析工具和技术,对用户行为数据进行分析,了解用户的兴趣、偏好和购买习惯。
- 探索数据,查找潜在的用户群体和特征。
-
用户画像构建:
- 基于用户行为数据,构建用户画像,包括用户的兴趣标签、购买历史、地理位置等信息。
- 使用机器学习算法或用户聚类方法来创建个性化用户画像。
-
个性化推荐:
- 基于用户画像和行为历史,实施个性化推荐算法,例如协同过滤、内容推荐、深度学习推荐等。
- 推荐系统可以推荐商品、内容、活动或广告。
-
A/B测试:
- 针对不同的个性化推荐策略进行A/B测试,以评估推荐的效果和用户反馈。
- 根据测试结果优化个性化推荐算法。
-
实时个性化推荐:
- 构建实时个性化推荐引擎,能够在用户与电商平台互动时提供实时的个性化推荐。
- 使用流处理技术来处理实时数据流。
-
营销活动个性化:
- 基于用户画像和购买历史,设计个性化的营销活动和优惠券。
- 发送个性化的电子邮件、推送通知或短信,以吸引用户互动和购买。
-
反馈和监控:
- 监控个性化推荐和营销活动的效果,收集用户反馈。
- 根据反馈和数据分析结果,不断改进个性化策略。
-
隐私保护:
- 确保用户数据的隐私和安全,遵守相关隐私法规和政策。
- 提供用户选择的机会,允许他们控制个人数据的使用。
通过实施上述流程,电商数据中台可以实现个性化的营销和推荐,提高用户体验和购买转化率。个性化推荐和营销可以更好地满足用户需求,增加用户忠诚度,并提高交易量和收入。不断优化和改进个性化策略是保持电商竞争力的重要因素之一。
模型训练(算法模型)
数据中台可以集成数据科学和机器学习模型 ,训练处一个算法模型供业务或其他服务调用。
届时这个模型可以根据性别、年龄和城市算出兴趣标签。当你想要根据用户的性别、年龄和城市分析他们的兴趣标签时,你需要进行一系列数据分析和建模步骤 :
-
数据收集和准备:
- 收集用户数据,包括userId、name、email、age、gender、location、interests字段。
- 使用数据处理工具(如Python的Pandas库)进行数据清洗,处理缺失值和异常值。
-
特征工程:
机器学习模型通常需要输入数值数据,而不是原始文本、图像或其他格式的数据。通过提取特征,可以将非结构化或半结构化数据转化为数值特征,使模型能够理解和分析数据。- 从数据中提取有用的特征。在这个案例中,你可以使用性别、年龄和城市作为特征。
- 对分类特征(性别、城市)进行独热编码或使用嵌入向量表示。
-
数据分割:
-
将数据分割为训练集和测试集,以便模型训练和评估。
-
训练集:用于训练机器学习模型的数据子集。模型使用训练集中的数据来学习模式和关系。 测试集:用于评估训练好的模型的性能和泛化能力的数据子集。测试集是在模型开发过程中最后才使用的,以模拟模型在真实环境中的表现。 常见的数据分割比例是将数据集分为70-80%的训练集和20-30%的测试集。
-
-
使用Python的Scikit-Learn库可以轻松地完成数据分割。
-
4、选择模型:
- 选择一个适合多分类问题的机器学习模型,如多类别分类器。在这个案例中,可以选择随机森林、多层感知器(MLP)等模型。
- 使用Scikit-Learn或其他机器学习库来创建和训练模型。
5、模型训练:
- 使用训练集对选择的模型进行训练。模型将学习如何从性别、年龄和城市等特征预测用户的兴趣标签。
- 例如,使用Scikit-Learn的
fit方法来训练模型。
6、模型评估:
- 使用测试集来评估模型性能。常用的评估指标包括准确性、精确度、召回率、F1分数等。
- 使用Scikit-Learn的评估函数进行模型性能评估。
选址模型
滴滴数据中台的动态计算价格模型
- 数据收集和存储:
- 数据中台负责收集、存储和管理大量的历史数据,包括乘车记录、路线信息、交通状况、乘客行为、价格信息等。
- 这些数据被用于历史数据分析和建模,以建立动态定价算法的基础。
- 数据预处理和清洗:
- 数据中台进行数据预处理和清洗,以确保数据的质量和一致性。这包括去除噪声、填补缺失值、处理异常数据等。
- 清洗后的数据用于训练和优化价格计算模型。
- 模型训练和优化:
- 数据中台支持机器学习模型的训练和优化,以根据历史数据和实时反馈来调整计算模型的参数。
- 训练的模型将用于实时业务调用,以计算当前乘车的价格。
- 实时数据处理:
- 数据中台也支持实时数据处理,包括收集和传输实时数据,例如乘客位置、路况、乘车请求等。
- 实时数据用于实际的价格计算。
- 模型管理和部署:
- 数据中台管理和部署训练好的价格计算模型,确保它们可以在实时业务中高效运行。
- 模型的管理包括版本控制、部署监控和模型更新等方面。
- 数据监控和反馈:
- 数据中台可以监控价格计算过程中的数据流和性能,收集用户反馈,以便对系统进行调整和改进。
- 这有助于优化价格计算算法,以反映市场需求和用户行为的变化。
据中提取有用的特征。在这个案例中,你可以使用性别、年龄和城市作为特征。
- 对分类特征(性别、城市)进行独热编码或使用嵌入向量表示。
-
数据分割:
-
将数据分割为训练集和测试集,以便模型训练和评估。
-
训练集:用于训练机器学习模型的数据子集。模型使用训练集中的数据来学习模式和关系。 测试集:用于评估训练好的模型的性能和泛化能力的数据子集。测试集是在模型开发过程中最后才使用的,以模拟模型在真实环境中的表现。 常见的数据分割比例是将数据集分为70-80%的训练集和20-30%的测试集。
-
-
使用Python的Scikit-Learn库可以轻松地完成数据分割。
-
4、选择模型:
- 选择一个适合多分类问题的机器学习模型,如多类别分类器。在这个案例中,可以选择随机森林、多层感知器(MLP)等模型。
- 使用Scikit-Learn或其他机器学习库来创建和训练模型。
5、模型训练:
- 使用训练集对选择的模型进行训练。模型将学习如何从性别、年龄和城市等特征预测用户的兴趣标签。
- 例如,使用Scikit-Learn的
fit方法来训练模型。
6、模型评估:
- 使用测试集来评估模型性能。常用的评估指标包括准确性、精确度、召回率、F1分数等。
- 使用Scikit-Learn的评估函数进行模型性能评估。
选址模型
滴滴数据中台的动态计算价格模型
- 数据收集和存储:
- 数据中台负责收集、存储和管理大量的历史数据,包括乘车记录、路线信息、交通状况、乘客行为、价格信息等。
- 这些数据被用于历史数据分析和建模,以建立动态定价算法的基础。
- 数据预处理和清洗:
- 数据中台进行数据预处理和清洗,以确保数据的质量和一致性。这包括去除噪声、填补缺失值、处理异常数据等。
- 清洗后的数据用于训练和优化价格计算模型。
- 模型训练和优化:
- 数据中台支持机器学习模型的训练和优化,以根据历史数据和实时反馈来调整计算模型的参数。
- 训练的模型将用于实时业务调用,以计算当前乘车的价格。
- 实时数据处理:
- 数据中台也支持实时数据处理,包括收集和传输实时数据,例如乘客位置、路况、乘车请求等。
- 实时数据用于实际的价格计算。
- 模型管理和部署:
- 数据中台管理和部署训练好的价格计算模型,确保它们可以在实时业务中高效运行。
- 模型的管理包括版本控制、部署监控和模型更新等方面。
- 数据监控和反馈:
- 数据中台可以监控价格计算过程中的数据流和性能,收集用户反馈,以便对系统进行调整和改进。
- 这有助于优化价格计算算法,以反映市场需求和用户行为的变化。
[外链图片转存中…(img-4ayQh9UM-1694697788226)]