可视化训练曲线
- wandb
- 基本流程
- 离线运行wandb
- 保存最佳结果及模型
- 界面
- tensorboard
- 基本流程
- SummaryWriter 所提供的其他方法
wandb
基本流程
-
安装wandb
pip install wandb -
注册wandb账号
然后在wandb官网注册一个账号,然后获取该账号的私钥。然后在命令行执行:wandb login然后根据提示输入私钥即可。
-
导入必要的库
import torch import torch.nn as nn import torch.optim as optim import wandb -
初始化wandb
在脚本开始部分,需要调用 wandb.init() 来初始化一个新的wandb运行,基础的调用:wandb.init(project="my_project", name="my_custom_run_name")可以通过
name来自定义本次运行保存的子目录名称,project名称相同的运行结果会在Weights & Biases服务器自动被分在同一个project下, -
记录变量
在训练循环的每个epoch或每个batch后,使用 wandb.log 记录相应的loss或其他任何你想跟踪的metrics。简单的例子如下:for epoch in range(epochs): for batch in dataloader: # 进行你的模型训练和计算 # ... # 假设在某个时刻,你得到了以下的loss和accuracy值 loss = ... accuracy = ... # 通过dict记录多个变量 wandb.log({ "loss": loss.item(), "accuracy": accuracy }) -
结束
在训练结束后,调用 wandb.finish() 来通知wandb你的运行已经结束,并将所有日志数据上传到wandb:wandb.finish()
离线运行wandb
如果服务器网络不佳,或者不想立即上传训练日志到Weights & Biases服务器时,可以使用W&B的离线模式。下面是如何使用W&B进行离线训练的步骤:
- 设置W&B为离线模式:
在你的代码中,初始化W&B之前,设置环境变量或使用settings参数将W&B设置为离线模式:
(1)使用环境变量:
(2)使用settings参数:import os os.environ["WANDB_MODE"] = "dryrun"
在"dryrun"模式下,所有的日志、模型检查点等都会保存在本地wandb目录下的一个新的子目录中,并不会上传到W&B的服务器。import wandb wandb.init(project="my_project", settings=wandb.Settings(mode="dryrun")) - 上传训练结果
当你准备好上传你的训练结果时(例如,当你再次有互联网连接时),你可以使用命令行工具wandb sync。进入到包含wandb目录的路径,然后执行:
其中wandb sync path_to_run_directorypath_to_run_directory是你的训练日志被保存的具体目录。在W&B(Weights & Biases)中,当你启动一个新的运行时,它会在本地的wandb目录下创建一个新的子目录来保存该运行的所有日志和相关文件。默认情况下,该子目录的名称是‘run-[DATE]_[TIME]’,例如‘run-20230818_123456’。
保存最佳结果及模型
- 使用W&B 的
summary:
如果你只想记录一个最佳的值,比如, best_accuracy,而不是其变化曲线。W&B 提供了一个summary对象,你可以用它来存储训练过程中的最佳结果。这些结果会在W&B dashboard的“Summary”部分显示。import wandb wandb.init(project="my_project") for epoch in range(epochs): # 训练和评估代码 # ... # 假设当前 epoch 的准确度是 current_accuracy current_accuracy = ... # 更新最佳准确度 if current_accuracy > wandb.summary.get("best_accuracy", 0.0): wandb.summary["best_accuracy"] = current_accuracywandb.summary.get("best_accuracy", 0.0):表示使用python字典的get方法从wandb.summary中尝试获取best_accuracy的值。如果best_accuracy存在,它将返回其值;如果不存在,它将返回默认值 0.0。
- 保存最佳模型:
除了记录最佳准确度,wandb也可以用来保存达到最佳准确度的模型。这样,当你在W&B的web界面查看你的项目时,你不仅可以看到最佳准确度,还可以下载达到最佳准确度的模型。import torch import wandb wandb.init(project="my_project") best_accuracy = 0.0 model = ... for epoch in range(epochs): # 训练和评估代码 # ... # 假设当前 epoch 的准确度是 current_accuracy current_accuracy = ... if current_accuracy > best_accuracy: best_accuracy = current_accuracy torch.save(model.state_dict(), "best_model.pth") wandb.save("best_model.pth") - 使用W&B 的
Artifacts
如果想要更全面地保存与最佳准确度对应的模型状态或其他相关信息,可以使用W&B的Artifacts功能:import wandb # 初始化W&B wandb.init(project="my_project") best_accuracy = 0.0 # 假设的训练循环 for epoch in range(epochs): for batch in dataloader: # 进行模型训练和计算 # ... # 假设在某个时点你得到了这样的准确度 current_accuracy = ... # 检查是否是新的最佳准确度 if current_accuracy > best_accuracy: best_accuracy = current_accuracy # 保存与最佳准确度对应的模型 torch.save(model.state_dict(), "best_model.pth") # 创建一个Artifact并保存模型 artifact = wandb.Artifact( type="model", name="best_model", metadata={"accuracy": best_accuracy}) artifact.add_file("best_model.pth") # 上传Artifact wandb.log_artifact(artifact) # 使用wandb.log记录当前准确度 wandb.log({"current_accuracy": current_accuracy})
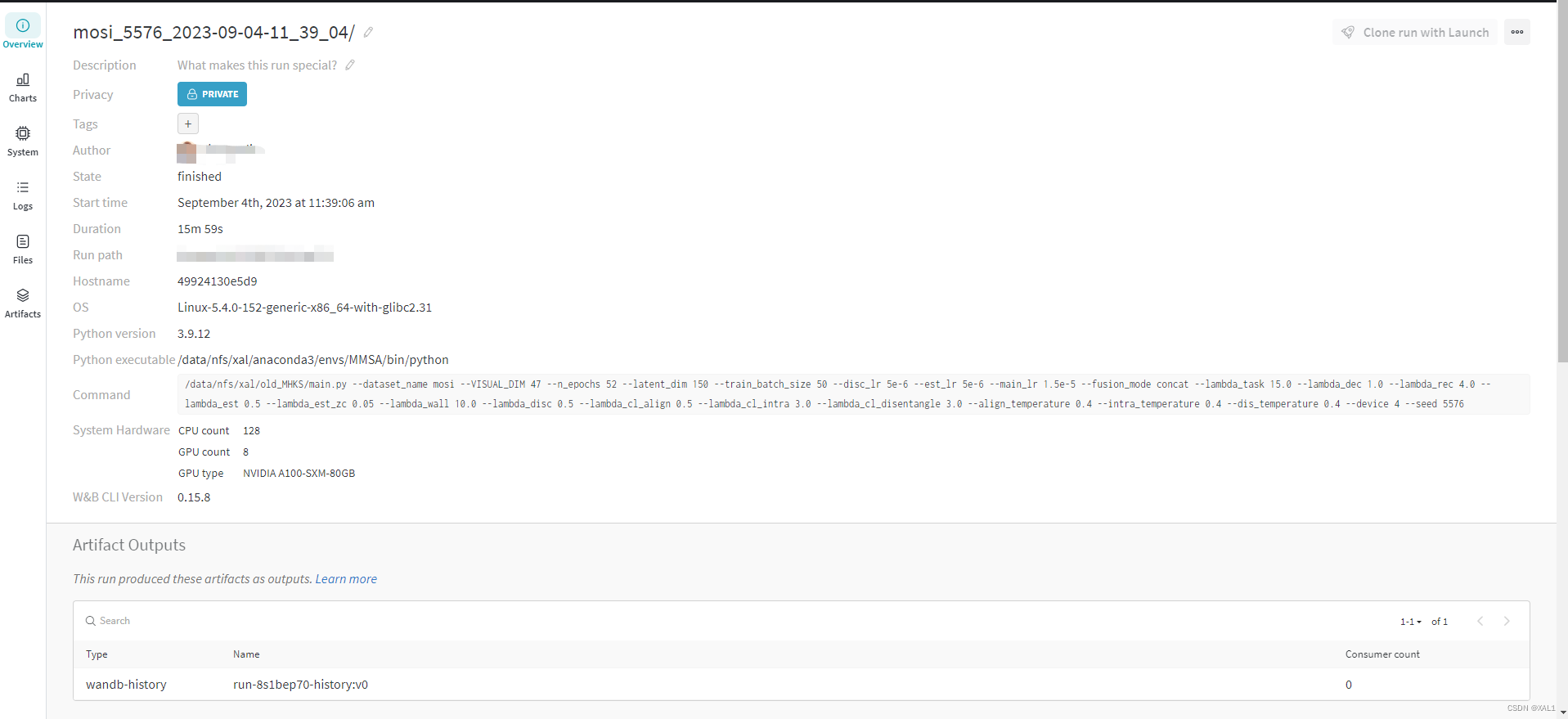
界面
- 展示出project和其下的日志:
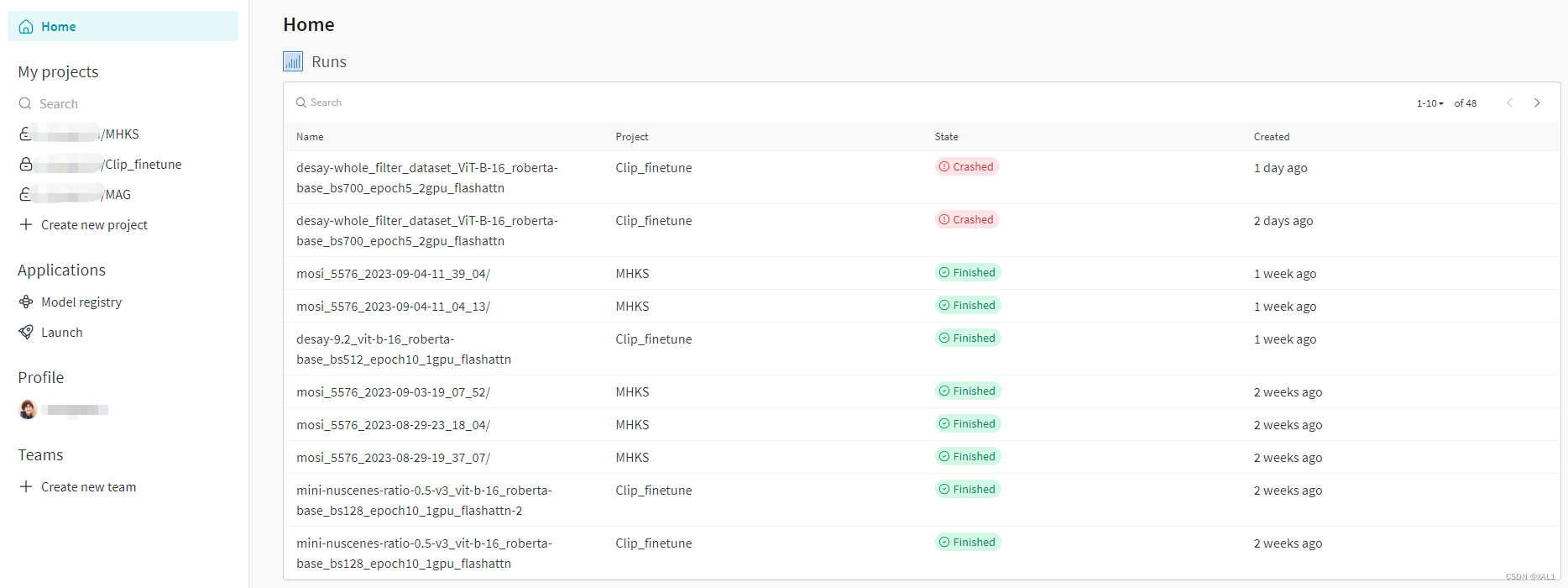
- 对应project下的每一个日志会有一个对比

- 对应的每个日志可以在
Charts里看到记录变量的曲线

- 在
Overview里可以看到具体信息,包含环境信息,运行命令,所记录的超参数以及summary记录的最佳指标等

tensorboard
基本流程
-
安装 TensorBoard
如果你还没有安装 TensorBoard,可以使用 pip 进行安装:pip install tensorboard -
在代码中导入必要的库
import torch from torch.utils.tensorboard import SummaryWriter -
创建 SummaryWriter
SummaryWriter是与 TensorBoard 交互的主要接口。你需要创建一个SummaryWriter对象,指定日志目录:writer = SummaryWriter('./runs/experiment_name') -
记录标量
在训练循环中,可以使用 writer.add_scalar 方法记录你想要跟踪的标量(如损失和准确率):for epoch in range(num_epochs): # ... training code ... loss = ... accuracy = ... writer.add_scalar('Loss/train', loss, epoch) writer.add_scalar('Accuracy/train', accuracy, epoch)特别地,名称如果采用下列形式,则3个loss会被自动保存在同一个section,2个accuracy会被保存在同一个section :
writer.add_scalar('loss/loss1', loss1, epoch) writer.add_scalar('loss/loss2', loss2, epoch) writer.add_scalar('loss/loss3', loss3, epoch) writer.add_scalar('Accuracy/train', accuracy1, epoch) writer.add_scalar('Accuracy/valid', accuracy1, epoch) -
启动 TensorBoard
另其一个命令行或终端,在命令行或终端中,运行以下命令:tensorboard --logdir=./runs/experiment_name -
查看 TensorBoard
运行上述命令之后,终端会给出一个网址,一般是http://localhost:6006/。打开浏览器并访问 http://localhost:6006/。你应该能够看到 TensorBoard 的界面,并在其中查看你记录的训练曲线。或者你可以自己指定端口号:tensorboard --logdir=./runs/experiment_name --port 8888则打开网站:http://localhost:8888/
-
关闭 SummaryWriter
训练结束后,确保关闭SummaryWriter以释放资源:writer.close()
SummaryWriter 所提供的其他方法
- add_scalar(tag, scalar_value, global_step=None, walltime=None):
- 用于记录单个标量值,如损失或准确率。
- tag 是标量的名称。
- scalar_value 是要记录的具体数值。
- global_step 是当前的步骤或迭代次数。
- add_scalars(main_tag, tag_scalar_dict, global_step=None, walltime=None):
- 用于记录多个标量值。
- main_tag 是主标签。
- tag_scalar_dict 是一个字典,其中键是标签,值是对应的标量值。
- add_histogram(tag, values, global_step=None, bins=‘tensorflow’, walltime=None, max_bins=None):
- 用于记录值的分布,如模型权重或激活的分布。
- values 是一个张量,包含要记录的值。
- add_image(tag, img_tensor, global_step=None, walltime=None, dataformats=‘CHW’):
- 用于记录图像。
- img_tensor 是一个表示图像的张量。
- add_images(tag, img_tensor, global_step=None, walltime=None, dataformats=‘NCHW’):
- 用于记录多个图像。
- add_figure(tag, figure, global_step=None, close=True, walltime=None):
- 用于记录 matplotlib 图形。
- add_graph(model, input_to_model=None, verbose=False):
- 用于记录模型的计算图。
- model 是要记录的模型。
- input_to_model 是一个输入到模型的张量,用于推断模型的结构。
- add_text(tag, text_string, global_step=None, walltime=None):
- 用于记录文本。
- add_embedding(mat, metadata=None, label_img=None, global_step=None, tag=‘default’, metadata_header=None):
- 用于记录和可视化嵌入。
- mat 是一个包含嵌入向量的矩阵。
- add_pr_curve(tag, labels, predictions, global_step=None, num_thresholds=127, weights=None, walltime=None):
- 用于记录 PR 曲线。
- labels 和 predictions 分别是真实标签和预测的概率。
- add_mesh(tag, vertices, colors=None, faces=None, global_step=None, walltime=None):
- 用于记录3D网格数据。
- add_hparams(hparam_dict=None, metric_dict=None):
- 用于记录超参数和与之关联的指标。