剑指offer刷题笔记
文章目录
- 剑指offer刷题笔记
- 注意内容
- 时间复杂度
- C++ 语法知识补充:
- 优先级
- new 和 delete
- 树的遍历
- 算法模板
- string类判断字符串为空
- 归并
- 递归
- 整数二分算法模板
注意内容
- map 是 O(logn) ,底层实现是平衡树,unorder_map 是 O(1),哈希表。
- 树 - 节点, 链表 - 结点
(*p).num改用p->num来代替,它表示*p所指向的结构体变量中的num成员,同样,(*p).name等价于p->name。- 补充:
A & B | A & C = A & (B | C) - cur是cursor的缩写,译为光标。
- 深度优先遍历一般是通过递归来实现的,广度优先遍历一般是通过队列来实现的。
- C++中判断指针是否为空
if (root == nullptr) return nullptr;if (!root) return NULL;
- 下面两种写法等价,因为只有在
i = -1时~i = 0for (int i = n - 1; ~i; i--)for (int i = n - 1; i >= 0; i--)
- 在用while做指针扫描时,要注意在每个while中进行指针是否越界的判断,因为使用while时往往会越界

时间复杂度
-
计算机1G的空间大约有 109个int,而计算机一秒能运算 107到108次,所以时间复杂度比空间复杂度更重要。
-
量级
- C++ 一秒能算 10^7 ~ 10^8 次,一千万次到一亿次
- 2^20 约等于 100万,即百万个字节约等于1M
- 2^30 约等于 10亿,即10亿个字节约等于1G
- log10^x 约等于 3x
-
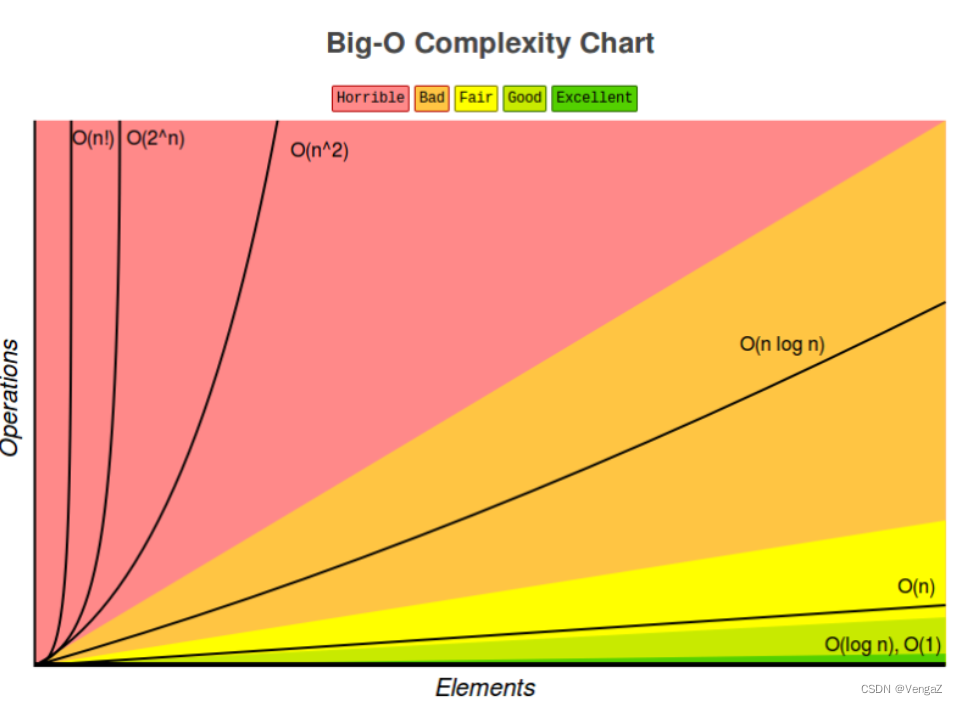
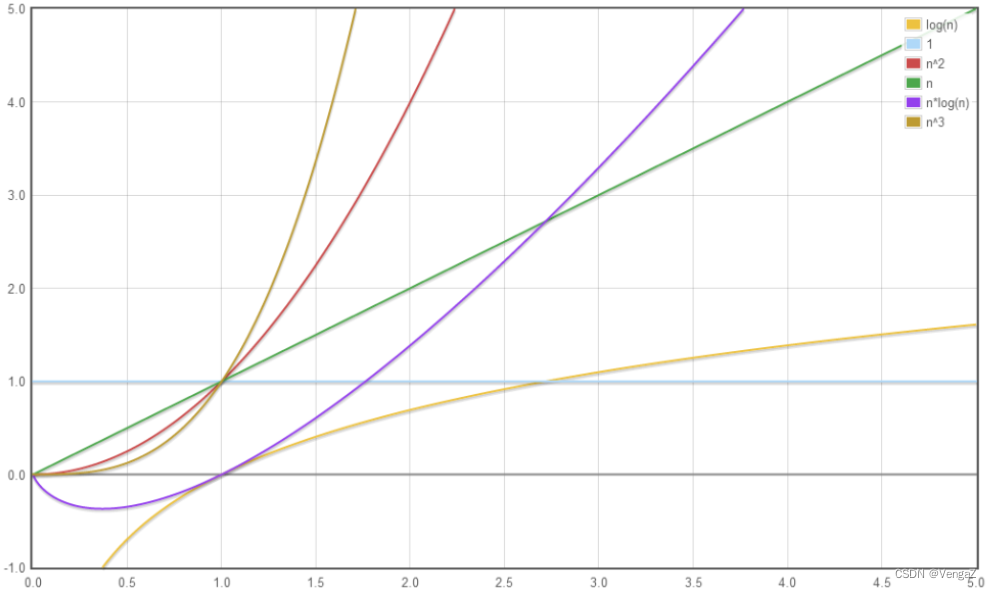
时间复杂度排序
O(1)<O(lgN)<O(N)<O(N*lgN)<O(n²)<O(n3)<O(2ⁿ)
C++ 语法知识补充:
-
erase()函数erase函数的原型如下:
(1)
string& erase(size_t pos = 0, size_t n = npos);(2)
interator erase(iterator position);(3)
iterator erase(iterator first, iterator last);有三种用法:
(1)
erase(pos, n);删除从pos开始的n个字符,例如erase( 0, 1),删除0位置的一个字符,即删除第一个字符。(2)
erase(position);删除position处的一个字符(position是个string类型的迭代器)。(3)
erase(first,last);删除从first到last之间的字符(first和last都是迭代器)。int main () { string str ("This is an example phrase."); string::iterator it; // 第(1)种用法 str.erase (10,8); cout << str << endl; // "This is an phrase." // 第(2)种用法 it=str.begin()+9; str.erase (it); cout << str << endl; // "This is a phrase." // 第(3)种用法 str.erase (str.begin()+5, str.end()-7); cout << str << endl; // "This phrase." return 0; } -
reverse函数用于反转在==[first,last)范围内的顺序(包括first指向的元素,不包括last指向的元素)== -
push_back()向容器中加入一个右值元素(临时对象)时,首先会调用构造函数构造这个临时对象,然后需要调用拷贝构造函数将这个临时对象放入容器中。原来的临时变量释放。这样造成的问题就是临时变量申请资源的浪费。 -
emplace_back()在容器尾部添加一个元素,这个元素原地构造,不需要触发拷贝构造和转移构造。而且调用形式更加简洁,直接根据参数初始化临时对象的成员。 -
stoi()把数字字符串转换成int输出,参数是const string*,不需要转化为const char* -
atoi()把数字字符串转换成int输出,参数是const char*,因此对于一个字符串str我们必须调用c_str()的方法把这个string转换成const char*类型的 -
sub_string(string str, int a)第a个字符开始截取后面所有的字符串 -
resize(n)设置大小(size)- 调整容器的长度大小,使其能容纳n个元素。
- 如果n小于容器的当前的size,则删除多出来的元素。
- 否则,添加采用值初始化的元素。
- 容器调用resize()函数后,所有的空间都已经初始化了,所以可以直接访问。
-
resize(n, t)多一个参数t,将所有新添加的元素初始化为t -
reserve()设置容量(capacity)预分配n个元素的存储空间。- reserve()函数预分配出的空间没有被初始化,所以不可访问。
-
autoC++11 auto可以在声明变量的时候根据变量初始值的类型自动为此变量选择匹配的类型。-
用auto声明的变量必须初始化(auto是根据后面的值来推测这个变量的类型,如果后面没有值,自然会报错)
-
函数和模板参数不能被声明为auto(原因同上)
-
因为auto是一个占位符,并不是一个他自己的类型,因此不能用于类型转换或其他一些操作,如sizeof和typeid。
-
定义在一个auto序列的变量必须始终推导成同一类型
auto x1 = 5, x2 = 5.0, x3='r'; *// This is too much....we cannot combine like this*
-
示例:
-
std::vector<std::string> ve; std::vector<std::string>::iterator it = ve.begin(); //用atuo来代替那个初始化类型 auto it = ve.begin();
-
-
-
int 数据范围
C中int类型是32位的,范围是-2147483648到2147483647 #define INT_MAX 2147483647 #define INT_MIN (-INT_MAX - 1)优先级
new 和 delete
-
new
-
new和delete运算符是用于动态分配和撤销内存的运算符,必须成对适用;
-
new用法——开辟单变量地址空间、开辟数组空间;
-
new作用—— 使用new运算符时必须已知数据类型,new运算符会向系统堆区申请足够的存储空间,如果申请成功,就返回该内存块的首地址,如果申请不成功,则返回零值;
-
new出来的对象用对应数据类型的指针接收——**new运算符返回的是一个指向所分配类型变量(对象)的指针。**对所创建的变量或对象,都是通过该指针来间接操作的;
-
new一般使用格式(3种)(开辟单变量地址空间)
指针类型* 指针变量名 = new 数据类型;int *a = new int将一个int类型的地址赋值给整型指针a
指针类型* 指针变量名 = new 数据类型(初值);int *a = new int(2)作用同上, 但是同时将整数空间赋值为2
指针类型* 指针变量名 = new 数据类型(内存单元个数);
-
开辟数组空间
指针类型* 指针变量名 = new 数组类型[数组元素个数];- 一维:
int *a = new int[100];//开辟一个大小为100的整型数组空间 - 二维:
int **a = new int[5][6];
-
-
delete
-
delete [] 的方括号中不需要填数组元素数,系统自知。即使写了,编译器也忽略。
-
delete用法
- 删除单变量地址空间
int *a = new int[2];delete a;//释放单个int的空间
- 删除数组空间
int *a = new int[5];delete []a;//释放int数组空间
- 删除单变量地址空间
-
树的遍历
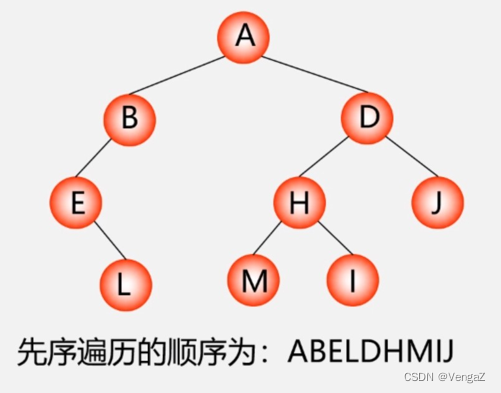
DLR–前序遍历–根左右(根在前,从左往右,一棵树的根永远在左子树前面,左子树又永远在右子树前面 )
LDR–中序遍历–左根右(根在中,从左往右,一棵树的左子树永远在根前面,根永远在右子树前面)
LRD–后序遍历–左右根(根在后,从左往右,一棵树的左子树永远在右子树前面,右子树永远在根前面)
- 前序遍历(根 左 右)
- 中序遍历(左 根 右)
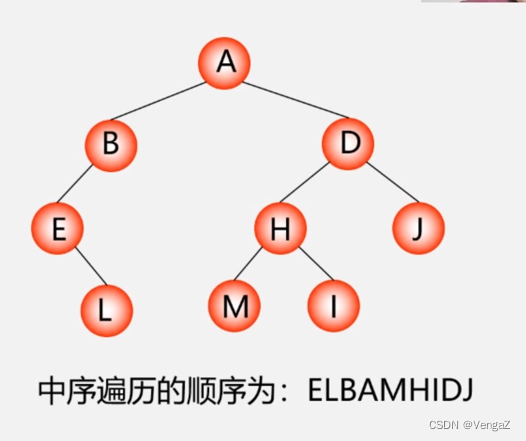
// 打印中序遍历
void dfs(Node* root) {
if(root == nullptr) return;
dfs(root->left); // 左
cout << root->val << endl; // 根
dfs(root->right); // 右
}
-
后序遍历(左 右 根)
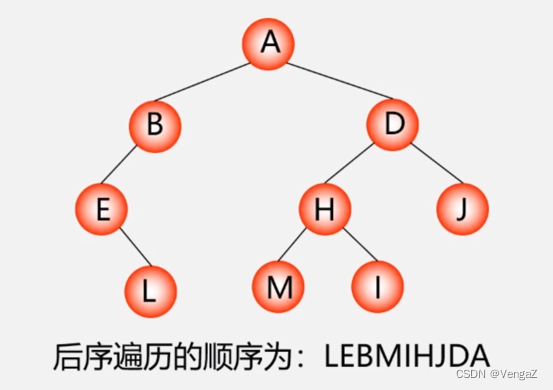
算法模板
string类判断字符串为空
1、string类有自己的成员函数empty, 可以用来判断是否为空:
string str;
if (str.empty()) //成立则为空
2、判断字符串长度。如果长度为0,则为空:
string str;
if (str.size() == 0) //成立则为空
3、与空串比较,如果相等则为空:
string str;
if(str == "") //引号里没有空格,成立则为空
几种方法中,empty函数是效率最高也是最常用的一种。
注意:
不能使用str==NULL来判断,NULL一般只拿和指针做比较或者赋给指针,string是类,传参进函数时str调用默认的构造函数已经初始化了,并且str都已经是对象了,它不可能为NULL,也不能和NULL比较。
归并
归并算法核心是分治思想:
-
分,划分成很多个小的问题,然后递归处理。
-
治,将分阶段得到的答案整合起来,即为分治思想。
步骤:
- 先确定分界点
- 然后递归处理(排序)
- 最后归并 - 合二为一
归并的每层时间复杂度都是O(n),一共logn层,所以时间复杂度为O(nlogn)
递归
常用递归方法的三种情况:
- 递归定义的数学函数
- 具有递归特性的数学结构
- 可递归求解的问题
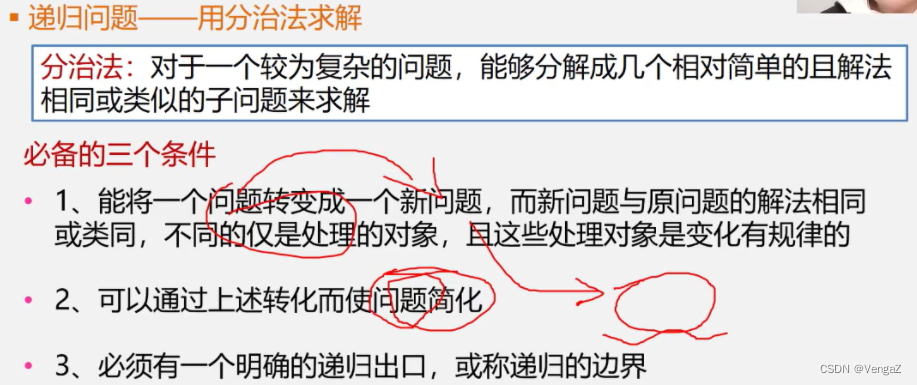
分治法求解递归问题算法的一般形式:
void p(参数表)
{
if (递归结束条件)
可直接求解步骤; //基本项
else
p(较小的参数); //归纳项
}
例如:
long Fact(long n)
{
if (n == 0)
return 1; //基本项
else
return n * Fact(n - 1); //归纳项
}
整数二分算法模板
二分模板一共有两个,分别适用于不同情况。
算法思路:假设目标值在闭区间[l, r]中, 每次将区间长度缩小一半,当l = r时,我们就找到了目标值。
版本1
当我们将区间[l, r]划分成[l, mid]和[mid + 1, r]时,其更新操作是r = mid(左半边区间)或者l = mid + 1;(右半边区间)计算mid时不需要加1。
C++ 代码模板:
int bsearch_1(int l, int r)
{
while (l < r)
{
int mid = l + r >> 1;
if (check(mid)) r = mid;
else l = mid + 1;
}
return l;
}
版本2
当我们将区间[l, r]划分成[l, mid - 1]和[mid, r]时,其更新操作是r = mid - 1(左半边区间)或者l = mid;(右半边区间),此时为了防止死循环,计算mid时需要加1。
C++ 代码模板:
int bsearch_2(int l, int r)
{
while (l < r)
{
int mid = l + r + 1 >> 1;
if (check(mid)) l = mid;
else r = mid - 1;
}
return l;
}