- 扩散模型做图像生成
- 使用clip预训练好的特征去做层级式的依托于文本的图像生成
- 先生成小分辨率图像64*64然后利用一个模型上采样到256*256(迭代)
- 先训练好一个clip模型,学习到图像文本对的关系
图像生成的模型
- AE
- DAE
- VAE
- VQVAE
- DALL-E : VQGAN+CLIP
- Diffusion
- DDPM:预测梯度而非特征;
- Improved DDPM
- Diffusion beats GAN
- GLIDE:classfier free guidance;
- DALLE2: prior:扩散模型 decoder:扩散模型 CLIP+GLIDE
- Imagen : 没有中间生成图像特征这一步,直接生成图像。
- Parti:自回归模型
DALLE-2
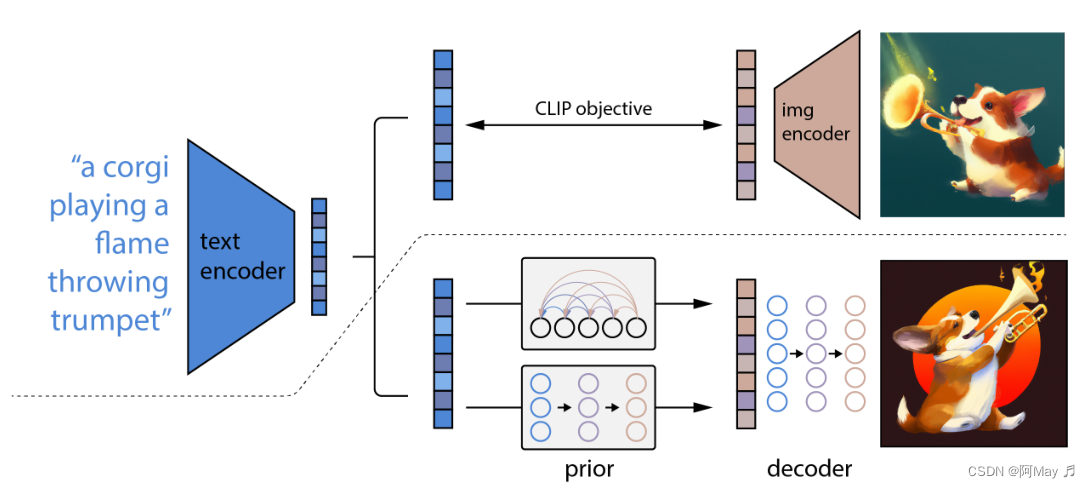
- 图像生成相似图像:图像-clip-图像特征-priorT2I-文本特征-priorI2T-图像特征-decoder-图像
- 两个图像内插
- 文本插值如图像
- 文本到图像生成
局限性
- 物体和物体的属性不能很好结合:因为用到的clip只是比较相似度,clip本身不了解“上下左右”这种。clip不能很好的区分物体和物体的属性。
- 生成带有文字的图片,不太行。生成的语言别人看不懂。
问题
组织图像和RNA的一个paired关系?单细胞层面or其他?
数据量能有多大(最重要)
DALLE2生成式模型总体思路还是clip+其他部分,思路是一致的。
考虑到图像生成基因表达的问题,方向是:
clip(frozen)+priorI2T(扩散模型)+decoderI2T(扩散模型) 两阶段
应该自己理解一下这几种生成模型基础版的训练流程