文章目录
- ES中关于segment的小结
- ES中segment相关的原理
- 在Lucene中的产生segment的过程。(Lucene commit过程)
- ES为了实现近实时可查询做了哪些
- 缩短数据可被搜索的等待时长
- 增加数据的可靠性
- 优化segment的数量 段合并
- 自动合并
- 强制合并
- 相关配置
- translog
- 合并策略相关
- 合并调度相关
- 相关API
- 手动refresh
- 手动flush
- 强制合并API
ES中关于segment的小结
segment对于索引的影响
-
segment数量过多会导致搜索的效率降低,主要是搜索需要遍历全部segment文件。
-
segment过大会导致,多次读取磁盘才找到数据,加剧IO和GC
-
segment数量过少会降低并发数
需要根据不同的场景控制segment的数量,单个segment的大小最大就是索引单个分片的大小,大小最大不超过50GB。
本文图片均来自elasticsearch官网
ES中segment相关的原理
一个Lucene的索引即ES中索引的一个分片
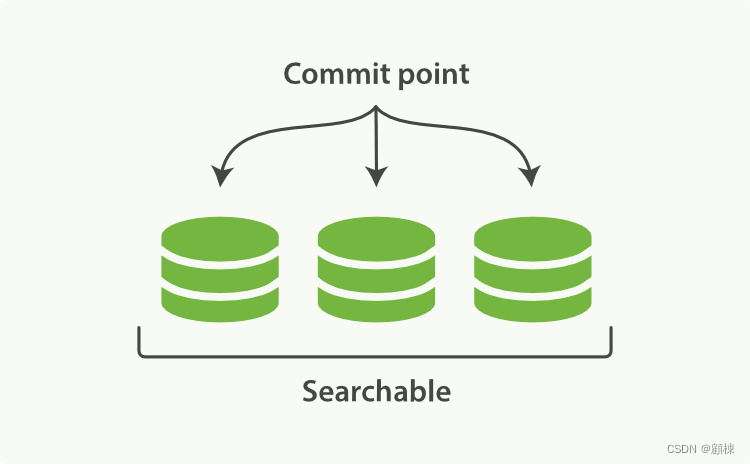
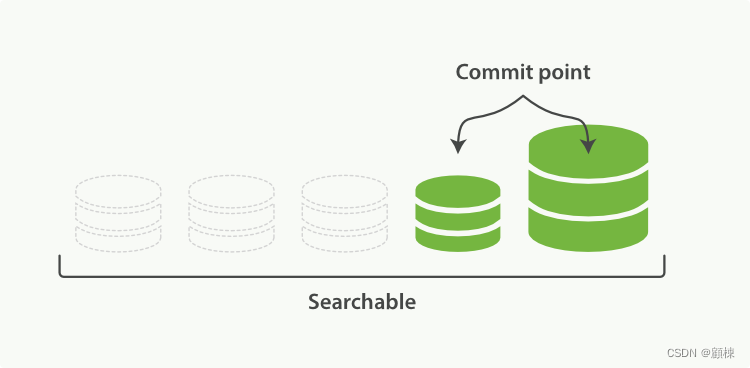
Elasticsearch底层依赖的Lucene,引入了按段查询(per-segment search)的概念。一个段(segment)是有完整功能的倒排索引,但是现在Lucene中的索引指的是段的集合,再加上提交点(commit point,即记录所有分段的文件)。当在这个commit point上进行搜索,就是在这个提交点下面的所有的segment文件中搜索,每个segment返回结果,然后汇总返回给用户。
一个Lucene索引的是示意图
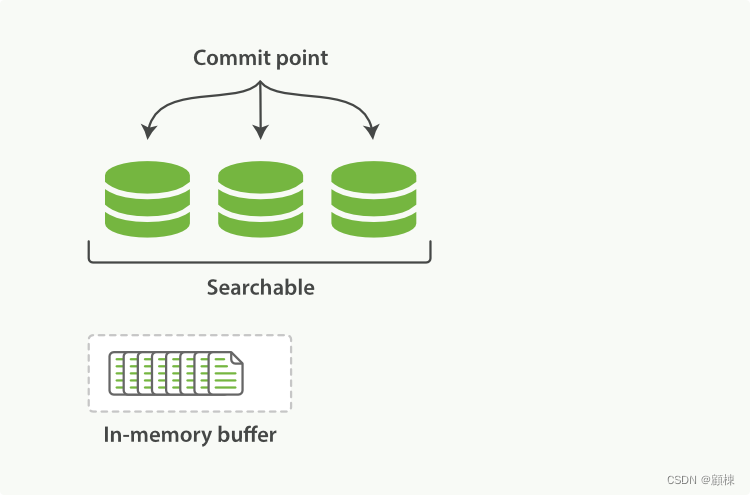
在Lucene中的产生segment的过程。(Lucene commit过程)
-
新的文档被写入内存中。
-
当内存中的文档数达到一定数量或者达到一定时长。缓存会被提交。
a. 生成一个新的segment文件,写入磁盘。
b. 生成一个新的commit point文件,记录当前可用的所有segment。
c. 通过同步方式,等待数据写入磁盘。
-
打开新建的segment文件,使其可供搜索。
-
清空内存。
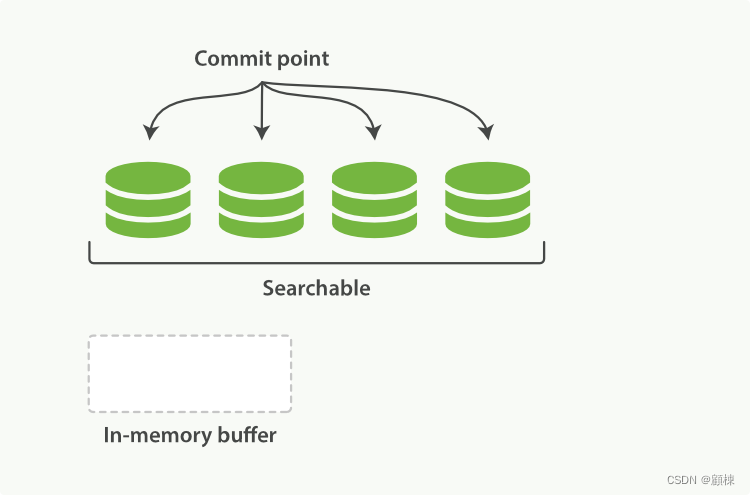
Lucene中的分段一旦创建完成,是无法变更的。优点:
- 没有必要给逆向索引加锁,因为不允许被更改,只有读操作,所以就不用考虑多线程导致互斥等问题。
- 索引一旦被加载到了缓存中,大部分访问操作都是对内存的读操作,省去了访问磁盘带来的io开销。
- 因为逆向索引的不可变性,所有基于该索引而产生的缓存也不需要更改,因为没有数据变更。
- 使用逆向索引可以压缩数据,减少磁盘io及对内存的消耗。
ES为了实现近实时可查询做了哪些
缩短数据可被搜索的等待时长
Lucene commit实现了数据的持久化(数据存入磁盘),这是一个高代价的操作,耗时且占资源。所以ES旨在减少Lucene commit的次数。
由于Lucene 允许新段被写入和打开—使其包含的文档在未进行一次完整提交时便对搜索可见。所以在文件系统的缓存中新建一个segment,将内存中的数据写入其中,并打开此segment,这样就使得数据可以快速的被搜索。此代价比直接commit的代价要小。
为了增加对上述操作的可操控性,ES提供了refresh操作。此操作就是,将内存中的文档写入新segment(文件系统缓存中),再打开这个segment的轻量的过程。通过减少refresh的间隔时间,会是数据近实时可搜索。
增加数据的可靠性
但是这个segment是临时的,在进程退出或者机器断电的情况下,数据会丢失。为了增加数据的可靠性。ES就提供了translog和flush操作,这个flush操作就是类似ucene的commit操作。
文档索引的过程
- 文档在被写入Lucene的内存区域的同时会被写入Translog文件中。先写Lucene,再写translog,在写Lucene时会进行数据的检查,写入会失败,先写Lucene可以避免对translog的回滚处理。
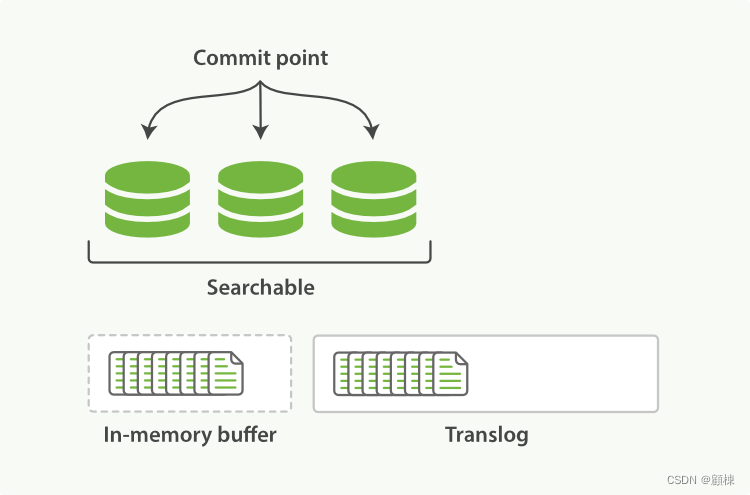
- 在refresh执行后,会将内存中的数据写入文件系统缓存中的segment中。
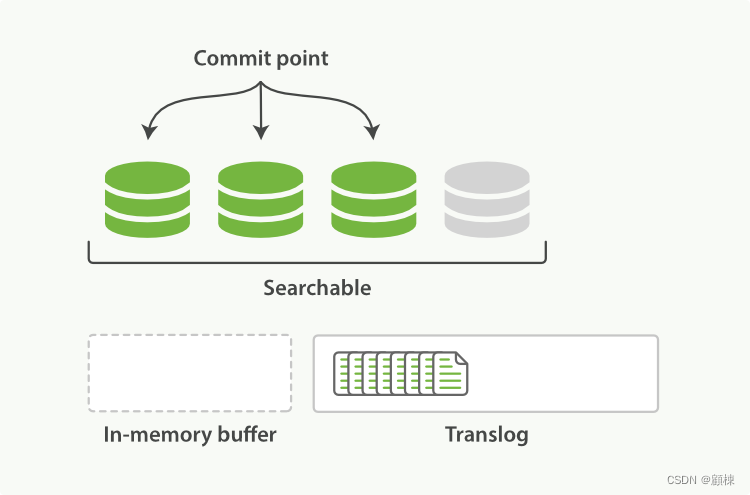
-
不同写入和refresh,数据不断的写入到内存和translog中。
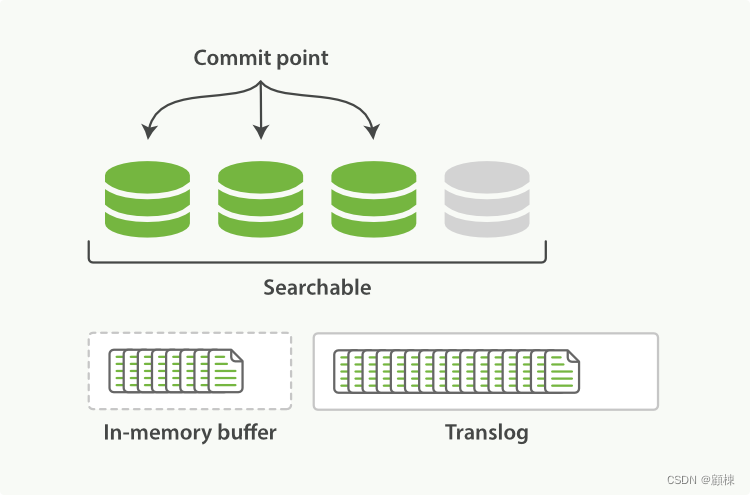
-
当达到一定的时长,或者translog达到一定大小时,会触发flush操作。
a. 生成一个新的segment文件,将内存数据写入磁盘
b. 内存缓冲区被清空。
c. 生成一个新的commit point文件,记录当前可用的所有segment。
d.文件系统缓存通过
fsync被刷新(flush),将文件系统缓存中的segment写入磁盘。e.老的 translog 被删除。
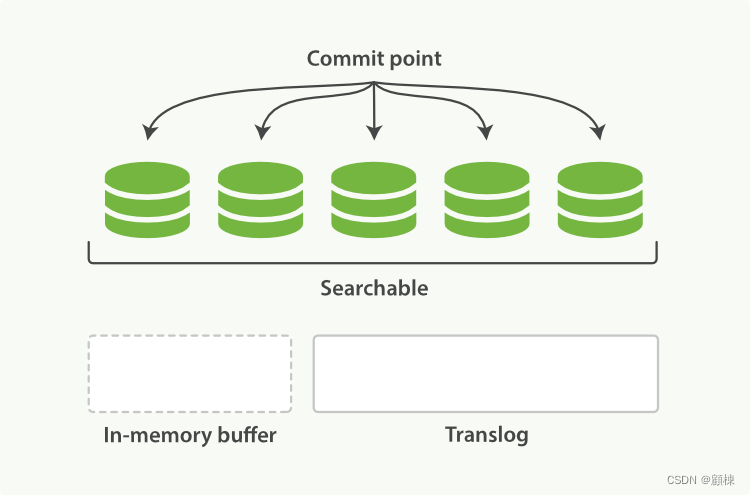
优化segment的数量 段合并
自动合并
由于自动refresh流程每个周期会创建一个新的段 ,这样会导致短时间内的段数量暴增。
段数量过多的问题:
- 资源过度消耗:占用大量的文件句柄、内存和CPU
- 降低搜索的效率:每个搜索请求都必须轮流检查每个段;所以段越多,搜索也就越慢。
ES提供了合并调度程序 (ConcurrentMergeScheduler) ,将较小的segments会定期合并为较大的段以保持索引大小并清除删除。合并过程使用自动节流来平衡合并和其他活动(如搜索)之间硬件资源的使用。
合并的方式是先复制后删除。
合并过程
-
根据策略选择合理的一组segment,新建一个大一点segment,将一组中的segment的数据写入新的segment中。
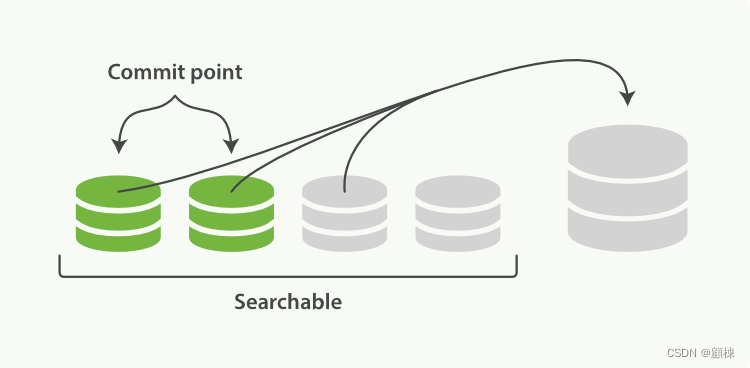
-
新的segment刷盘后,新建一个新的提交点(排除被合并的那一组segment,增加新的segment)。
-
打开新的segment,供搜索。
-
删除被合并的一组segment。
强制合并
强制合并API的源码分析
相关配置
translog
索引级别动态translog配置项:
-
index.translog.sync_intervaltranslog 被synced到磁盘并提交的频率。 默认为
5s。不允许小于100ms。 -
index.translog.durability是否在每个索引、删除、更新或批量请求后进行
fsync和提交 translog。 此设置接受以下参数:request(默认)fsync并在每次请求后提交。 在硬件故障的情况下,所有确认的写入都已经提交到磁盘。asyncfsync并在每个sync_interval后台提交。 在硬件故障的情况下,自上次自动提交以来的所有确认写入都将被丢弃。
-
index.translog.flush_threshold_sizetranslog 一旦达到最大大小,就会发生flush,生成一个新的 Lucene 提交点。 默认为
512mb。 -
index.translog.retention.size要保留的 translog 文件的总大小。 保留更多的 translog 文件会增加在恢复副本时执行基于操作的同步的机会。 如果 translog 文件不足,副本恢复将回退到基于文件的同步。 默认为
512mb -
index.translog.retention.agetranslog 文件将被保留的最长时间。 默认为
12h。
如果集群健康状态优秀,同时可以接收数据丢失的话,可以将translog配置调整一下,增加数据写入速率。
index.translog.durability: async
index.translog.sync_interval: 120s
index.translog.flush_threshold_size: 1024mb
合并策略相关
索引级别的相关动态配置
- index.merge.policy.expunge_deletes_allowed:当调用
expungeDeletes时,我们仅在其删除百分比超过此阈值时才合并掉一个段。默认值10。 - index.merge.policy.floor_segment:小于此的段将“向上取整”到此大小,即视为合并选择的相等(下限)大小。 这是为了防止频繁刷新微小段,从而防止索引中出现长尾。默认值2MB。
- index.merge.policy.max_merge_at_once:在“normal”合并期间一次合并的最大段数。默认值
10。 - index.merge.policy.max_merge_at_once_explicit:在强制合并或 expungeDeletes 期间,一次合并的最大段数。默认值
30。 - index.merge.policy.max_merged_segment:在正常合并(not explicit force merge)期间生成的最大段。此设置是近似值:合并段大小的估计是通过对要合并的段的大小求和(补偿已删除文档的百分比)得出的。默认值
5GB。 - index.merge.policy.segments_per_tier:设置每层允许的段数。较小的值意味着更多的合并但更少的段。默认为
10。请注意,此值需要大于max_merge_at_once的值,否则您将强制发生太多合并。 - index.merge.policy.deletes_pct_allowed:控制索引中允许的已删除文档的最大百分比。较低的值会使索引的空间效率更高,但会增加 CPU 和 I/O 活动。值必须介于
20和50之间。默认值为33。
进行写入优化的时候可以将index.merge.policy.segments_per_tier适当的变大,建议:20,在降低合并的操作次数。同时降低index.merge.policy.max_merged_segment的值,建议值:2GB,来加快写入的速度。
5.X 调整
index.merge.policy.reclaim_deletes_weight增加合并含有已删除segment的权重。6已经标记为废弃。
合并调度相关
调度相关动态配置,不建议调整
index.merge.scheduler.max_thread_count:一次可以合并的最大线程数。 默认为Math.max(1, Math.min(4, Runtime.getRuntime().availableProcessors() / 2)),它适用于良好的固态硬盘 (SSD)。 如果是机械硬盘,将其减少到 1。index.merge.scheduler.auto_throttle:如果是true(默认值),则合并调度程序将根据随时间请求的合并次数将合并的 IO(写入)速率限制为自适应值。 一个低索引率的应用程序不幸突然需要一个大的合并,将会看到合并被严重限制,而一个执行大量索引的应用程序会看到限制调整的更高,以允许合并跟上正在进行的写入。index.merge.scheduler.max_merge_count:一次可以合并的最大分段数。默认值由最大线程数据+5。最小值为1。
相关API
手动refresh
POST /index1,index2/_refresh
手动flush
POST index1,index2/_flush
强制合并API
强制合并API的使用