urllib是一个用来处理网络请求的python内置库。
一.基本使用
二.一个类型和6个方法
2.1 一个类型
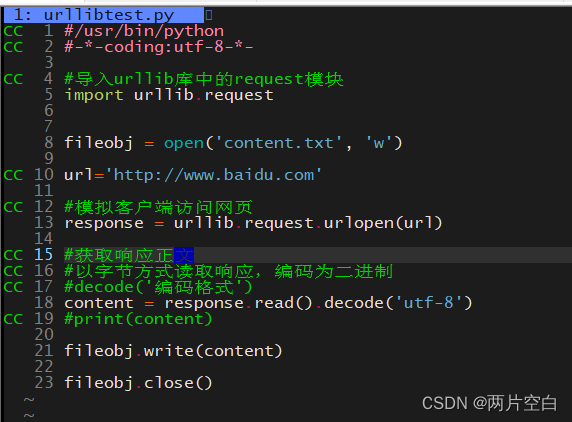
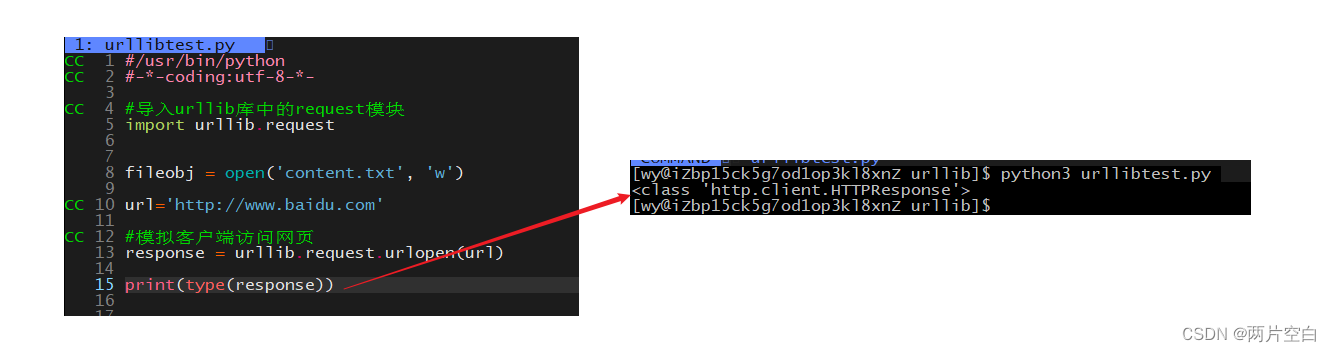
urllib的request库中urlopen方法返回的类型:<class 'http.client.HTTPResponse'>。为了与之后request库做区别。
2.2 6个方法
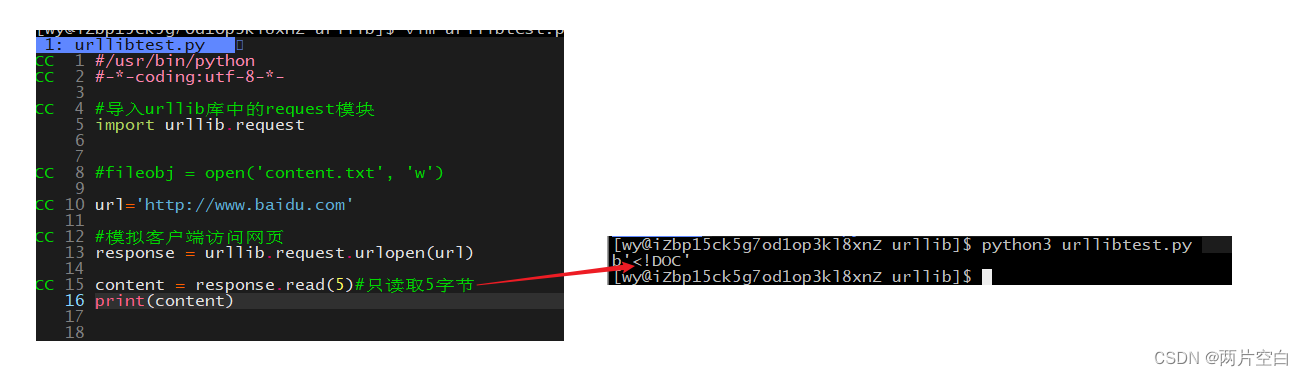
- read()方法:获得响应正文,按字节为单位读取正文(一字节字节的去读)。得到的是字节形式的二进制数据。缺点是太慢了。
- readline():按行读取响应正文。只能读取一行。返回的编码也是二进制的。
- readlines():循环按照行去读取响应正文。直到读完。编码是二进制的。
- getcode():获得状态码。
- geturl():返回url地址。
- getheaders():获取响应报头。

三.下载资源
使用urllib.request.urlretrieve方法
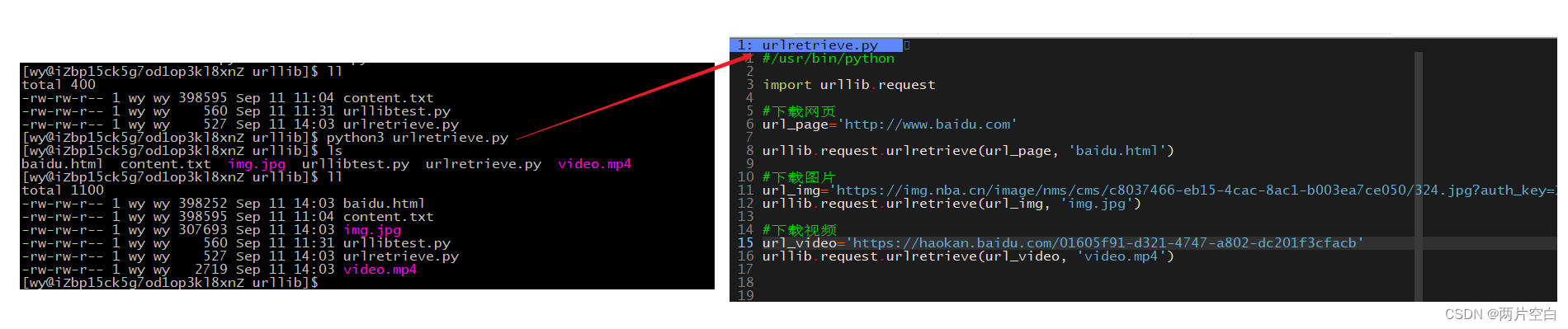
有人说,这样下载资源,我自己手动点即网页下载也行。但是,当我们需要下载成千上万个资源时,人工操作很耗时耗力。而通过爬虫很好实现。
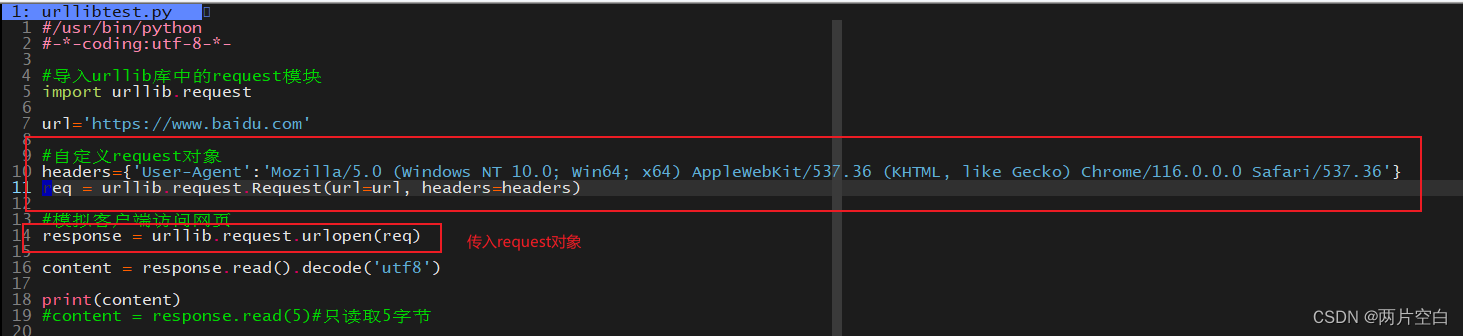
四.请求对象的定制
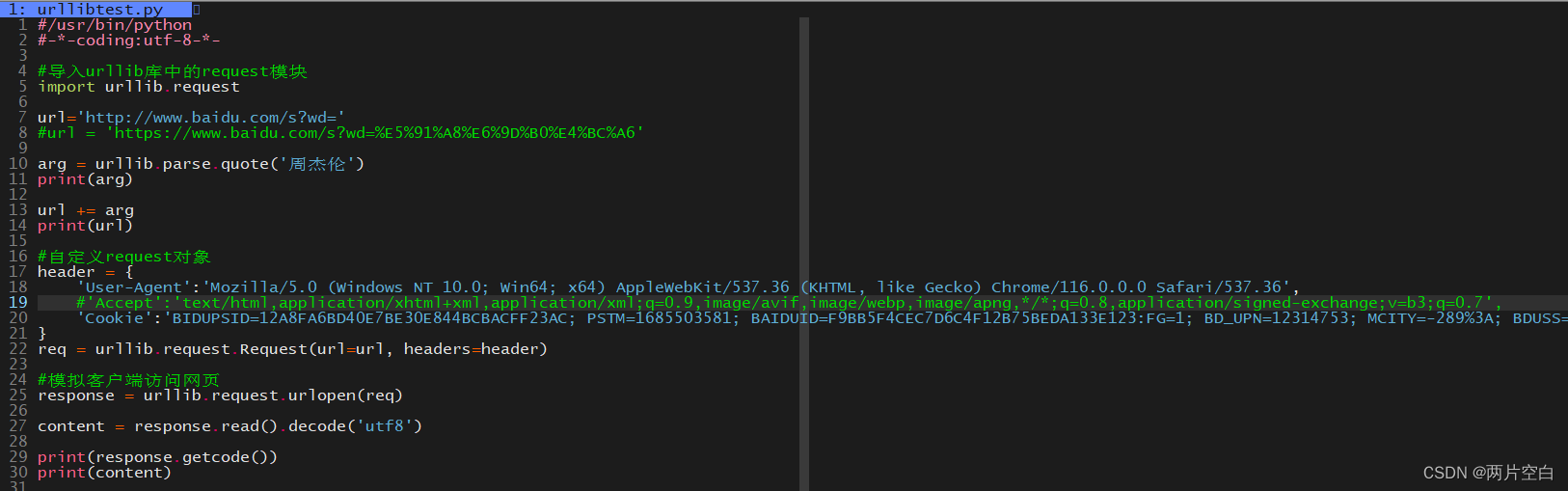
- 发现问题及其原因
请求的url为https://www.baidu.com,响应返回的信息不正确。这是因为https的反爬手段。该反爬手段会验证请求报头中的Use-Agent(用户代理)字段,该字段中包括操作系统及版本,CPU类型,浏览器及其版本,浏览器的渲染引擎,浏览器语言,浏览器插件等信息。

- 解决问题
首先介绍一下urlopen方法和Request对象:
urllib.request.urlopen(url, data=None, [timeout, ]*, cafile=None, capath=None, cadefault=False, context=None)
Open the URL url, which can be either a string or a Request object.
打开URL URL,它可以是字符串或请求对象。
class urllib.request.Request(url, data=None, headers={},
origin_req_host=None, unverifiable=False, method=None)urlopen参数可以接收字符串或者Request对象,我们可以通过构建Request对象,自定义报头。在调用urlopen时请求中,会带有我们定义的信息。
五.编解码
由于计算机一开始是美国人发明的。最早只有127个字符,小写字母,大写字母,数字和一些符号被编码到计算机里。这个编码表被称为ASCII表。
而想要计算机认识中文,不能使用ASCII表,就得自己制定编码标准,而且还不能和ASCII码产生冲突。于是中国制定了GB2312编码,把中文加到计算机的编码中。
但是世界上的语言这么多,不同的语言就会需要有不同的编码和不同的标准,就会不可避免的出现冲突,冲突就是一个字符在多个标准中有对应不同值,结果就是显示出现乱码。
于是Unicode应运而生,把所有语言都统一到一套编码中。这样就不会出现乱码问题。
例子:
当我们百度一下搜索周杰伦时。
url:https://www.baidu.com/s?wd=%E5%91%A8%E6%9D%B0%E4%BC%A6
而wd=%E5%91%A8%E6%9D%B0%E4%BC%A6中等于号右边的就是周杰伦的Unicode编码。
get请求方式的参数在url中,而post的请求方式在请求正文中。
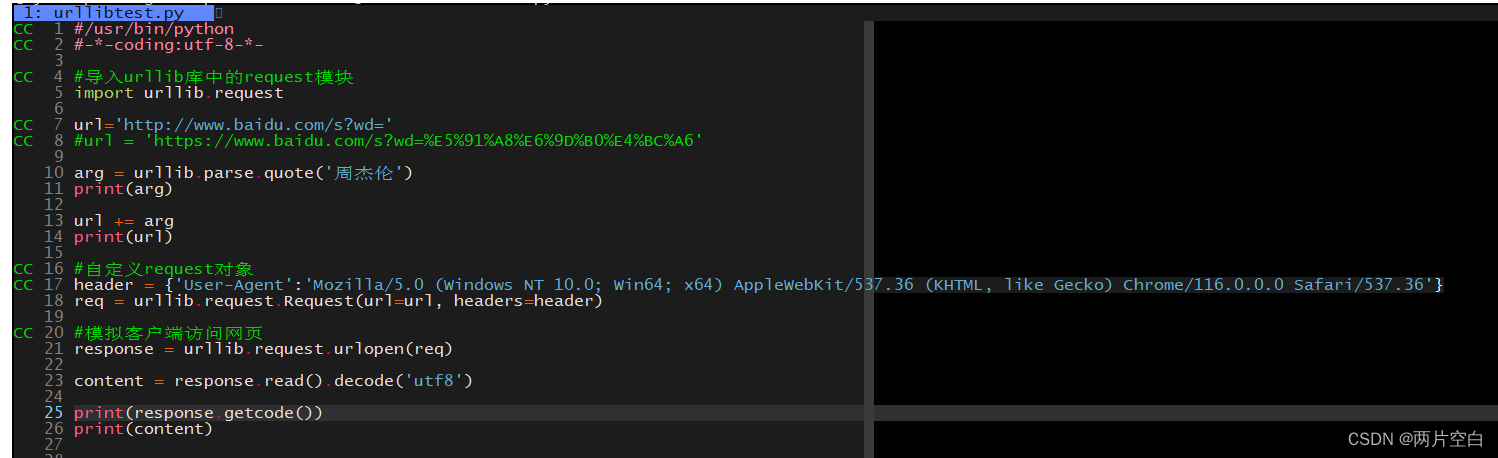
5.1 get请求方式的quote方法
方法是urllib.parse.quote()库中的,作用是将参数转化为Unicode编码。
例子:还是拿搜索周杰伦举例:
不进行编码,直接搜索。

使用quote编码后进行搜索:
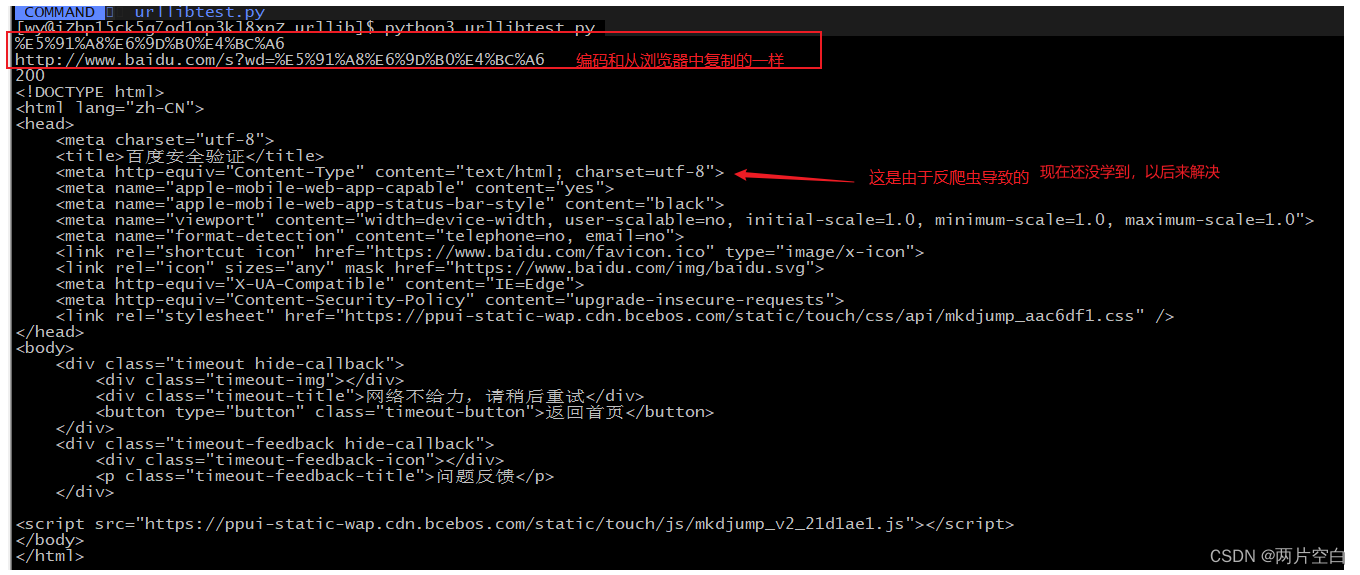
上面的现象是因为反爬导致的,是因为百度需要验证用户信息。需要在报头加上cookie。cookie可以在网页右键检查中得到:
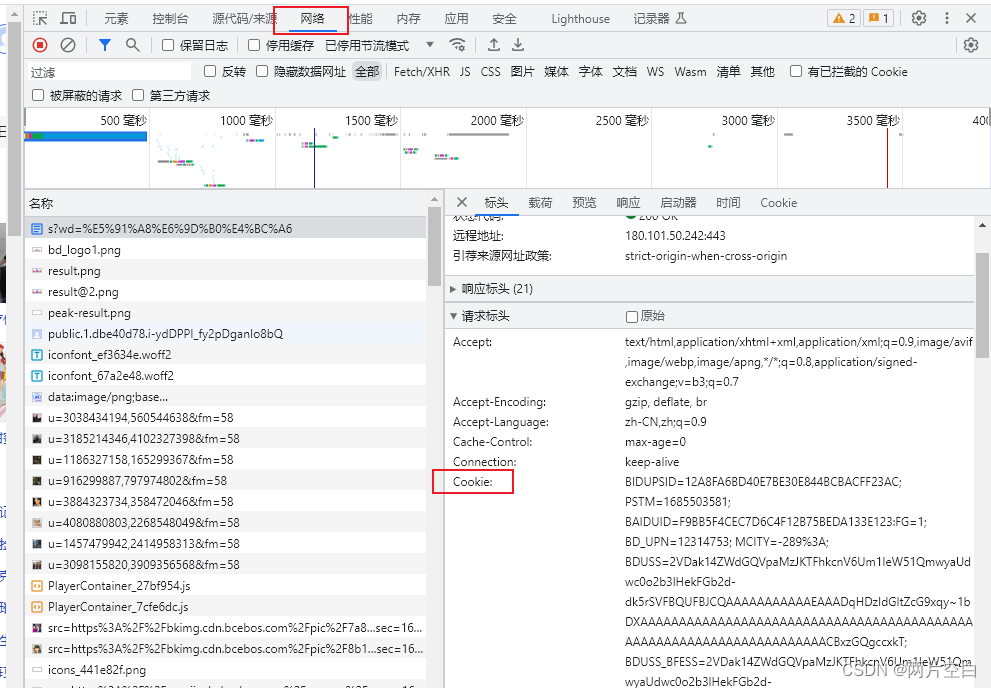
5.2 get请求方式的urlencode方法
quato方法只能每次将一个参数转化为Unicode编码,当有多个参数时,会导致代码变得复杂。而urllib.parse模块中还提供了urlencode方法,可以将多个参数转化成Unicode编码,并且会转化成get参数的对应格式。
该方法也是urllib.parse模块中的,作用转化多个参数为Unicode编码。后面访问url时只需要将参数拼接到url中即可。

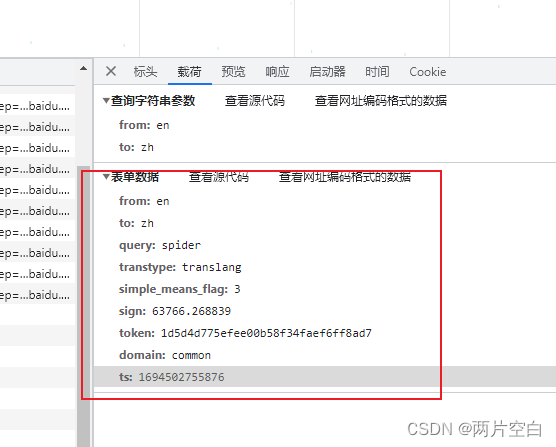
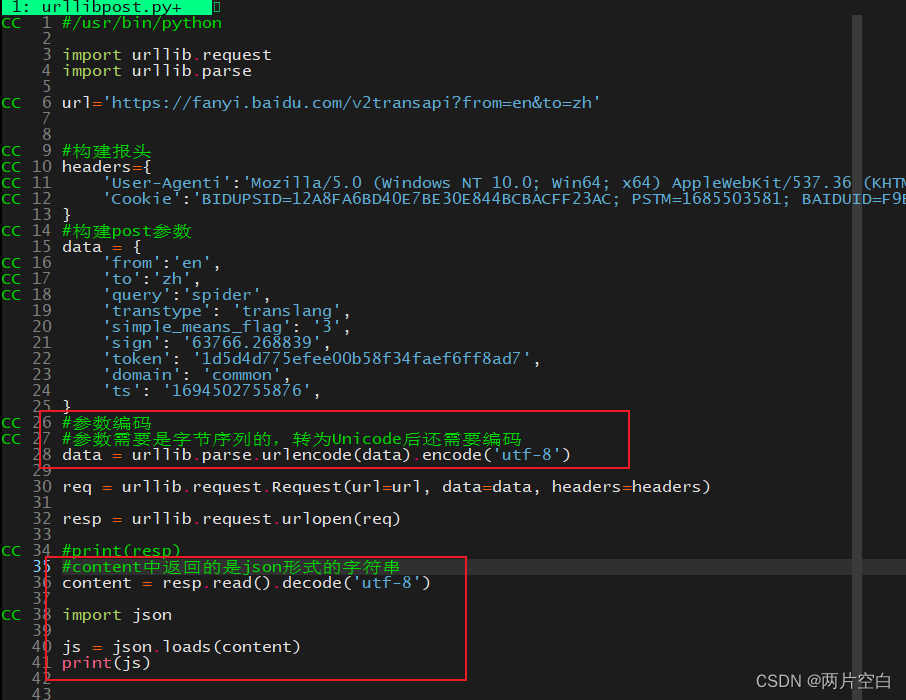
5.3 post请求方式
post请求方式和get请求方式不同在于,get请求方式的参数在url上,post的请求方式的参数在请求正文中。
使用post请求方式来获取数据时,需要将请求参数作为构建urllib.request.Request对象的参数传入。
参数在网页中可以获取:
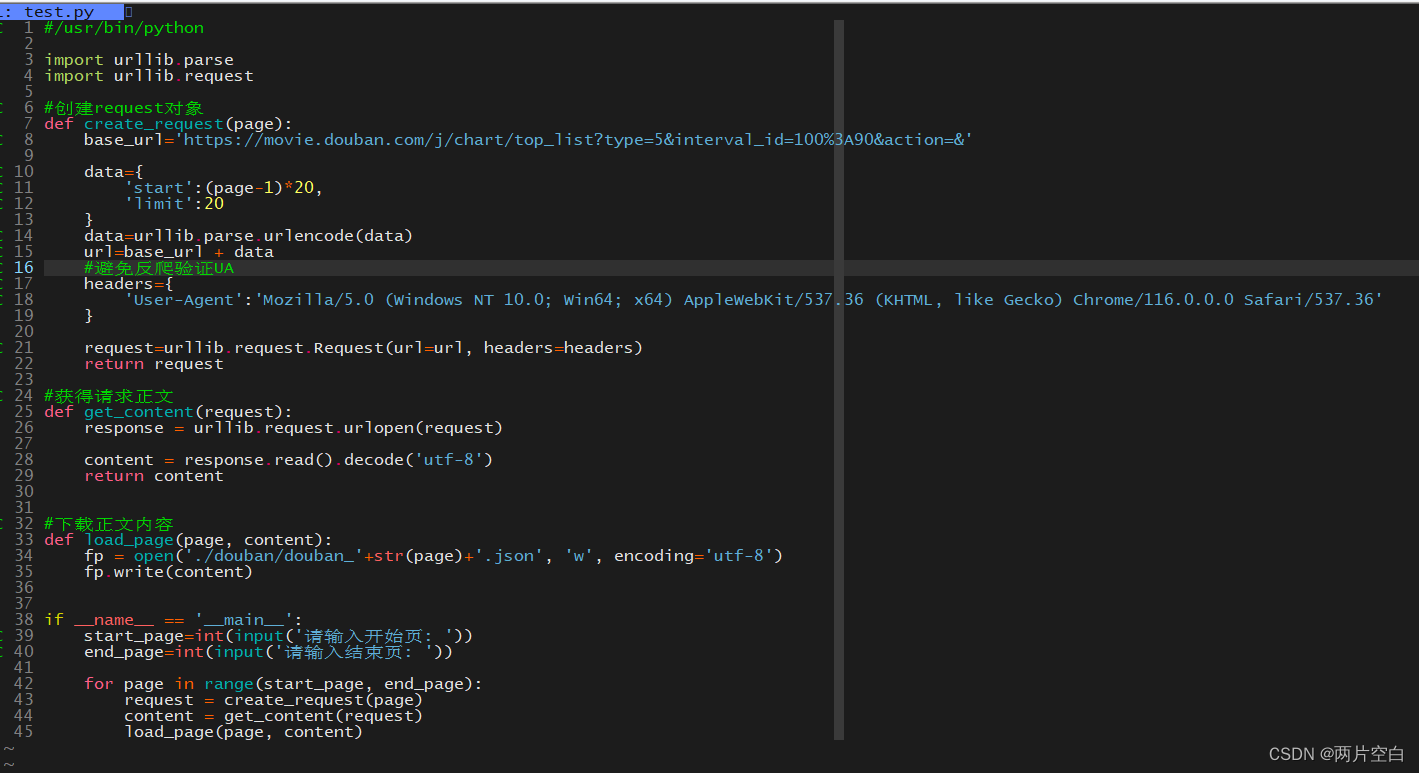
5.4 例子——ajax的get请求10页豆瓣电影
ajax介绍: Ajax即Asynchronous Javascript And XML(异步JavaScript和XML)在 2005年被Jesse James Garrett提出的新术语,用来描述一种使用现有技术集合的‘新’方法,包括: HTML 或 XHTML, CSS, JavaScript, DOM, XML, XSLT, 以及最重要的XMLHttpRequest。 使用Ajax技术网页应用能够快速地将增量更新呈现在用户界面上,而不需要重载(刷新)整个页面,这使得程序能够更快地回应用户的操作。
请求第一页豆瓣电影的url:https://movie.douban.com/j/chart/top_listtype=5&interval_id=100%3A90&action=&start=0&limit=20
请求第二页豆瓣电影的url:https://movie.douban.com/j/chart/top_listtype=5&interval_id=100%3A90&action=&start=20&limit=20
请求第二页豆瓣电影的url:https://movie.douban.com/j/chart/top_listtype=5&interval_id=100%3A90&action=&start=40&limit=20
...
我们发现请求不同页数的url中只有start参数在变化,变化规律为 (page - 1) * 20
代码为:
__name__:属于Python中的内置类属性,代表对应程序名称。如果当前运行的程序是主程序,此时__name__的值就是__main__,反之,则是对应的模块名。
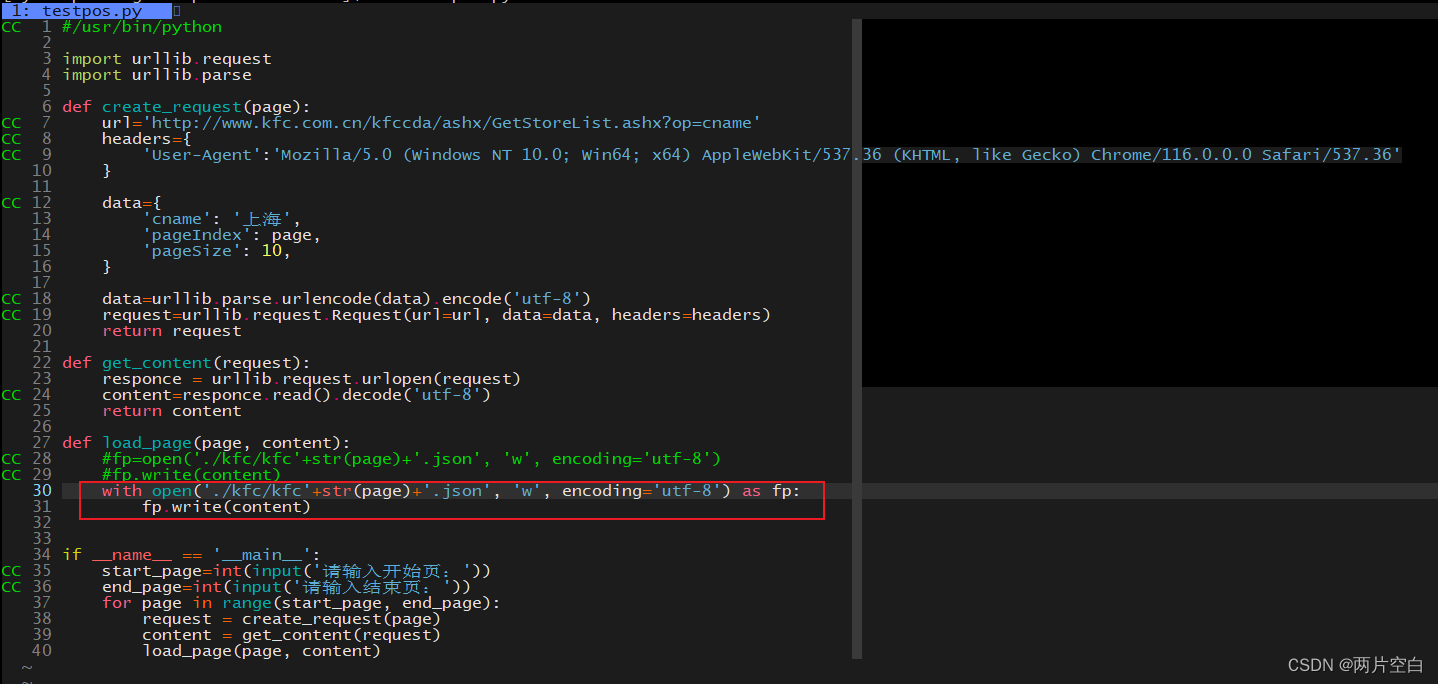
5.5 例子——ajax的post请求肯德基官网某个城市的门店
post请求的参数在请求正文中。
例子中查看参数:请求不同页数时,是参数pageindex值为对应的页数。

代码:
六.异常
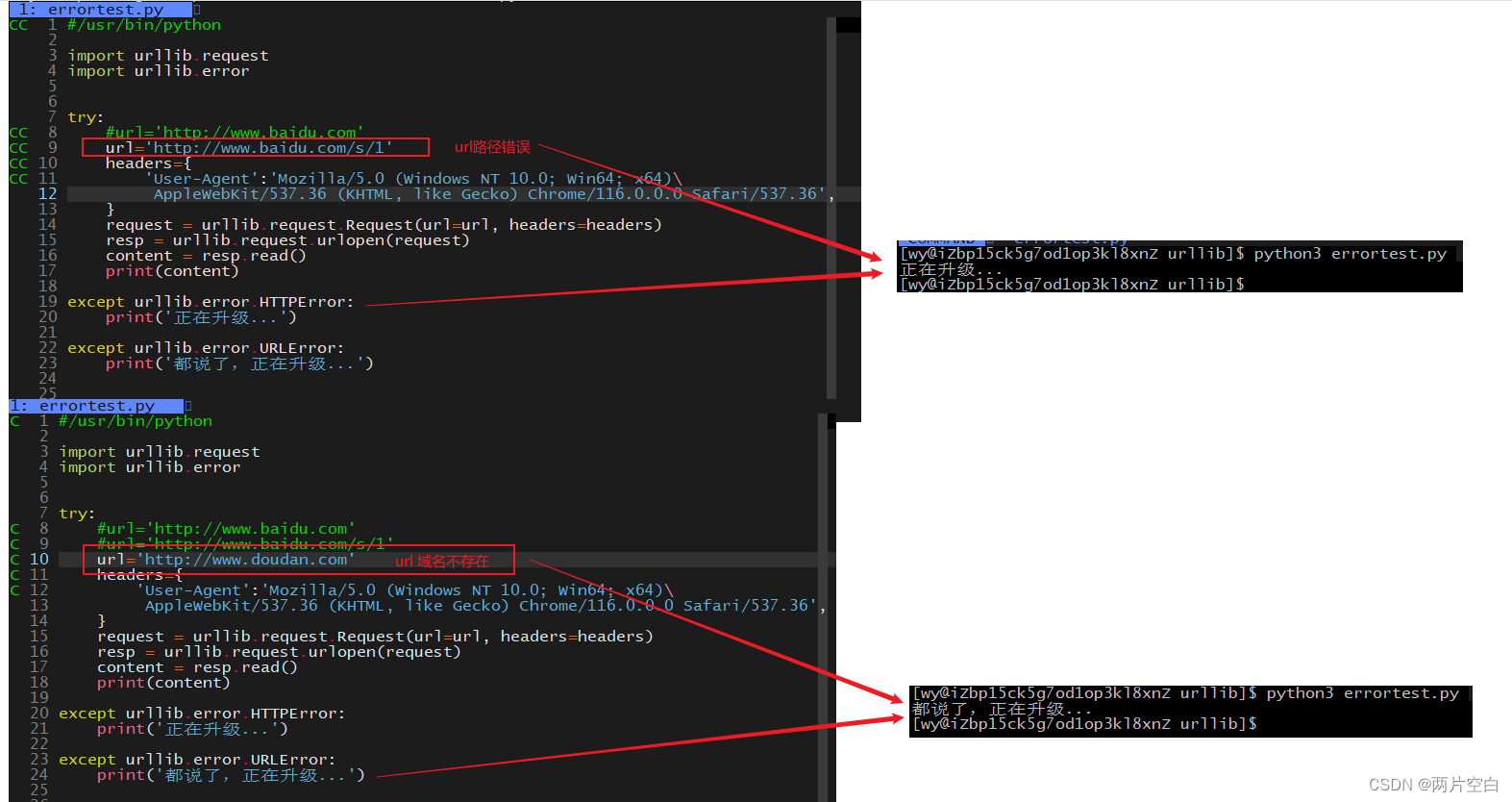
HTTP错误是针对浏览器无法连接到服务器增加的错误提示。引导使用者该页是出现了什么问题。
一般异常有两个类:UrlError/HttpError:这两个类在urllib.error模块下。
-
URLError异常类:一般报这个异常是URL上IP或者参数出现问题
-
HTTPError异常类:一般是URL上路径出现错误。HttpError是UrlError的子类。
七.使用cookie跳过登录
现象,当我们爬微博个人主页:

查看微博登录界面的编码:
这是一种反爬手段,访问的url需要进行登录操作,或跳转到登录界面。但是登录界面的编码和访问页面编码不一样。

在http协议中有一种cookie和session机制,可以使用户在登录过一次某网站时,在访问该网站不需要再次登录。
找到需要访问网页的的cookie设置到报头中,可以跳过登录。

报头中的referer:也是一种反爬手段。判断当前网页的上一个网页是不是referer对应的url,不相等不能进入。一般情况下做图片的防盗链。
八.handler处理器
handler的作用是为了定制更加高级的请求头。主要用来处理动态cookie和代理的情况。
8.1 handler的基本使用

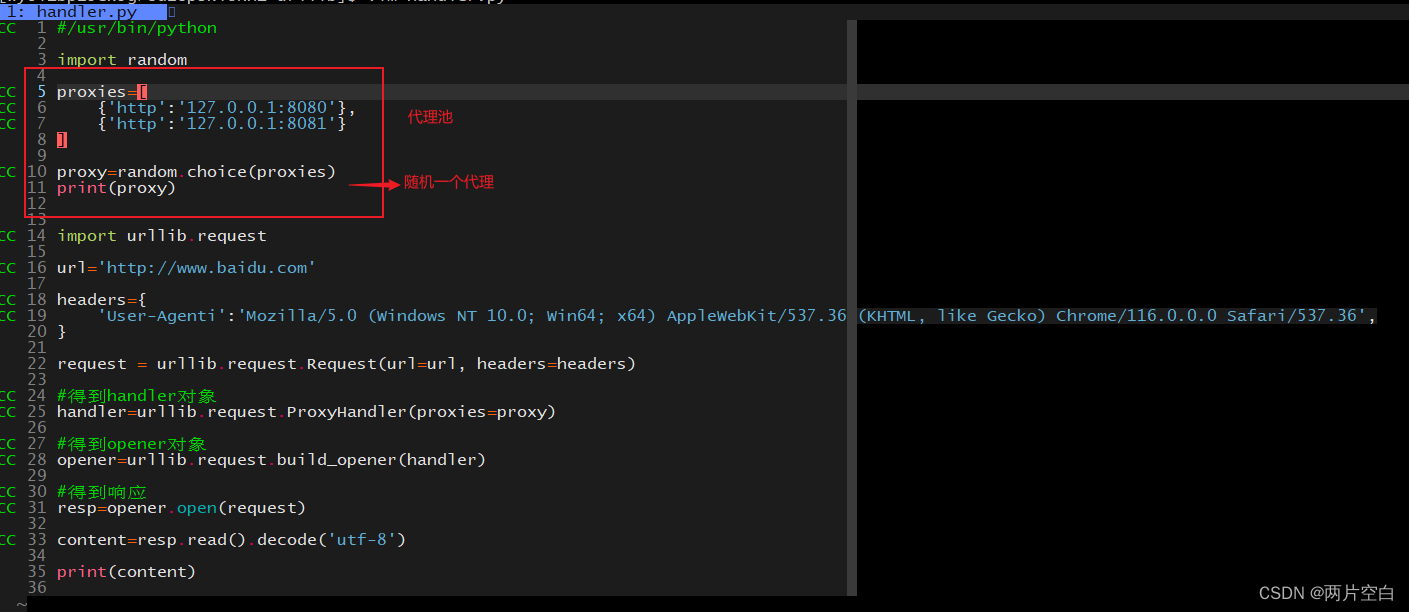
8.2 代理

8.3 代理池