SI Message Queue代码位于src/backend/storage/ipc/sinvaladt.c和src/backend/storage/ipc/sinval.c文件中,属于PostgreSQL数据库IPC进程间通信的一种方式【之前介绍过PostgreSQL数据库PMsignal——后端进程\Postmaster信号通信也是作为PostgreSQL数据库IPC进程间通信的一种方式,主要用于进程间信号通信】,主要用于POSTGRES shared cache invalidation共享缓存失效,分为POSTGRES shared cache invalidation communication code(sinval.c)和POSTGRES shared cache invalidation data manager(sinvaladt.c)。 详细解释为:在 PostgreSQL中,每一个进程都有属于自己的共享缓存(shared cache)。例如,同一个系统表在不同的进程中都有对应的Cache来缓存它的元组(对于RelCache来说缓存的是一个RelationData结构)。同一个系统表的元组可能同时被多个进程的Cache所缓存,当其中某个Cache中的一个元组被删除或更新时 ,需要通知其他进程对其Cache进行同步。在 PostgreSQL的实现中,会记录下已被删除的无效元组 ,并通过SI Message方式(即共享消息队列方式)在进程之间传递这一消息。收到无效消息的进程将同步地把无效元组(或RelationData结构)从自己的Cache中删除。

本篇主要集中介绍POSTGRES shared cache invalidation data manager(sinvaladt.c)。首先阅读一下注释:Conceptually, the shared cache invalidation messages are stored in an infinite array, where maxMsgNum is the next array subscript to store a submitted message in, minMsgNum is the smallest array subscript containing a message not yet read by all backends, and we always have maxMsgNum >= minMsgNum. (They are equal when there are no messages pending.) For each active backend, there is a nextMsgNum pointer indicating the next message it needs to read; we have maxMsgNum >= nextMsgNum >= minMsgNum for every backend. 从概念上讲,共享缓存无效消息存储在一个无限数组中,其中maxMsgNum是存储提交消息的下一个数组下标,minMsgNum是包含尚未被所有后端读取的消息的最小数组下标,并且我们总是maxMsgNum>=minMsgNumber。(当没有挂起的消息时,它们是相等的。)对于每个活动后端,都有一个nextMsgNum指针,指示它需要读取的下一条消息;对于每个后端,我们都有maxMsgNum>=nextMsgNum>=minMsgNum。【译者注:这里是多个生产者,多个消费者操作SI Message Queue,生产者通过移动maxMsgNum来获取队列空间,写入消息;而消费者则通过四月的读游标nextMsgNum,来记录自己将要读取的消息】
(In the current implementation, minMsgNum is a lower bound for the per-process nextMsgNum values, but it isn’t rigorously kept equal to the smallest nextMsgNum — it may lag behind. We only update it when SICleanupQueue is called, and we try not to do that often.) (在当前的实现中,minMsgNum是每个进程nextMsgNumber值的下限,但它并没有严格保持等于最小的nextMsgNum-它可能会滞后。我们只在调用SICleanupQueue时更新它,我们尽量不经常这样做。)
In reality, the messages are stored in a circular buffer of MAXNUMMESSAGES entries. We translate MsgNum values into circular-buffer indexes by computing MsgNum % MAXNUMMESSAGES (this should be fast as long as MAXNUMMESSAGES is a constant and a power of 2). As long as maxMsgNum doesn’t exceed minMsgNum by more than MAXNUMMESSAGES, we have enough space in the buffer. If the buffer does overflow, we recover by setting the “reset” flag for each backend that has fallen too far behind. A backend that is in “reset” state is ignored while determining minMsgNum. When it does finally attempt to receive inval messages, it must discard all its invalidatable state, since it won’t know what it missed. 实际上,消息存储在MAXNUMMESSAGES条目的循环缓冲区中。我们通过计算MsgNum%MAXNUMMESSAGES将MsgNum值转换为循环缓冲区索引(只要MAXNUMMESPAGES是常数且为2的幂,这就应该很快)。只要maxMsgNum不超过minMsgNum加上MAXNUMMESSAGES,缓冲区中就有足够的空间。如果缓冲区确实溢出,我们将通过为落后太多的每个后端设置“重置”标志来恢复。在确定minMsgNum时,将忽略处于“重置”状态的后端。当它最终尝试接收inval消息时,它必须放弃所有无效状态,因为它不知道错过了什么。
To reduce the probability of needing resets, we send a “catchup” interrupt to any backend that seems to be falling unreasonably far behind. The normal behavior is that at most one such interrupt is in flight at a time; when a backend completes processing a catchup interrupt, it executes SICleanupQueue, which will signal the next-furthest-behind backend if needed. This avoids undue contention from multiple backends all trying to catch up at once. However, the furthest-back backend might be stuck in a state where it can’t catch up. Eventually it will get reset, so it won’t cause any more problems for anyone but itself. But we don’t want to find that a bunch of other backends are now too close to the reset threshold to be saved. So SICleanupQueue is designed to occasionally send extra catchup interrupts as the queue gets fuller, to backends that are far behind and haven’t gotten one yet. As long as there aren’t a lot of “stuck” backends, we won’t need a lot of extra interrupts, since ones that aren’t stuck will propagate their interrupts to the next guy. 为了降低需要重置的可能性,我们向任何似乎远远落后的后端发送一个“追赶”中断。正常的行为是,一次最多有一个这样的中断在飞行中;当后端完成对追赶中断的处理时,它会执行SICleanupQueue,如果需要,它会发出下一个最落后于后端的信号。这避免了来自多个后台的过度争用,所有后台都试图同时赶上。然而,最后面的后端可能会陷入无法追赶的状态。最终它会被重置,所以除了它自己,它不会给任何人带来任何问题。但我们不想发现其他一些后端现在太接近重置阈值而无法保存。因此,SICleanupQueue被设计为在队列变得更满时偶尔向远远落后且尚未获得的后端发送额外的追赶中断。只要没有太多“卡住”的后端,我们就不需要太多额外的中断,因为没有卡住的后端会将中断传播给下一个人。
We would have problems if the MsgNum values overflow an integer, so whenever minMsgNum exceeds MSGNUMWRAPAROUND, we subtract MSGNUMWRAPAROUND from all the MsgNum variables simultaneously. MSGNUMWRAPAROUND can be large so that we don’t need to do this often. It must be a multiple of MAXNUMMESSAGES so that the existing circular-buffer entries don’t need to be moved when we do it. 如果MsgNum值溢出一个整数,我们就会遇到问题,因此每当minMsgNums超过MSGNUMWRAPAROUND时,我们都会同时从所有MsgNumber变量中减去MSGNUMWRAPAROUND。MSGNUMWRAPAROUND可以很大,所以我们不需要经常这样做。它必须是MAXNUMMESSAGES的倍数,以便在执行此操作时不需要移动现有的循环缓冲区条目。【译者注:MAXNUMMESSAGES为max number of shared-inval messages we can buffer. Must be a power of 2 for speed. 而MSGNUMWRAPAROUND为how often to reduce MsgNum variables to avoid overflow. Must be a multiple of MAXNUMMESSAGES. Should be large. 意思是minMsgNum和maxMsgNum可以超过MAXNUMMESSAGES,但是通过(maxMsgNum-minMsgNum)%MAXNUMMESSAGES可将MsgNum值转换为循环缓冲区索引,从而将消息存放到buffer的槽中,而最终还是需要确保minMsgNum和maxMsgNum不要太大,因此这里有一个MSGNUMWRAPAROUND限制,这些细节可以通过SICleanupQueue函数观察到】
Access to the shared sinval array is protected by two locks, SInvalReadLock and SInvalWriteLock. Readers take SInvalReadLock in shared mode; this authorizes them to modify their own ProcState but not to modify or even look at anyone else’s. When we need to perform array-wide updates, such as in SICleanupQueue, we take SInvalReadLock in exclusive mode to lock out all readers. Writers take SInvalWriteLock (always in exclusive mode) to serialize adding messages to the queue. Note that a writer can operate in parallel with one or more readers, because the writer has no need to touch anyone’s ProcState, except in the infrequent cases when SICleanupQueue is needed. The only point of overlap is that the writer wants to change maxMsgNum while readers need to read it. We deal with that by having a spinlock that readers must take for just long enough to read maxMsgNum, while writers take it for just long enough to write maxMsgNum. (The exact rule is that you need the spinlock to read maxMsgNum if you are not holding SInvalWriteLock, and you need the spinlock to write maxMsgNum unless you are holding both locks.) 对共享sinval数组的访问受到两个锁的保护,即SInvalReadLock和SInvalWriteLock。读卡器在共享模式下使用SInvalReadLock;这授权他们修改自己的ProcState,但不能修改甚至查看其他人的ProcState。当我们需要执行阵列范围的更新时,例如在SICleanupQueue中,我们以独占模式使用SInvalReadLock来锁定所有读卡器。写入程序使用SInvalWriteLock(始终处于独占模式)序列化向队列添加消息。请注意,编写器可以与一个或多个读取器并行操作,因为编写器不需要触摸任何人的ProcState,除非在需要SICleanupQueue的罕见情况下。唯一的重叠点是,编写器想要更改maxMsgNum,而读者需要读取它。我们通过设置一个自旋锁来处理这个问题,读者必须花足够长的时间才能读取maxMsgNumber,而编写器花足够长时间才能写入maxMsgNum。(确切的规则是,如果您没有持有SInvalWriteLock,则需要自旋锁来读取maxMsgNum;如果您同时持有两个锁,则需要旋转锁来写入maxMsgNumber。)
Note: since maxMsgNum is an int and hence presumably atomically readable/writable, the spinlock might seem unnecessary. The reason it is needed is to provide a memory barrier: we need to be sure that messages written to the array are actually there before maxMsgNum is increased, and that readers will see that data after fetching maxMsgNum. Multiprocessors that have weak memory-ordering guarantees can fail without the memory barrier instructions that are included in the spinlock sequences. 注意:由于maxMsgNum是一个int,因此可能是原子可读写的,所以spinlock可能看起来没有必要。之所以需要它,是为了提供一个内存屏障:我们需要确保在maxMsgNum增加之前写入数组的消息确实存在,并且读者在获取maxMsgNumber之后会看到这些数据。如果没有包含在自旋锁序列中的内存屏障指令,具有弱内存排序保证的多处理器可能会失败。
共享内存结构
CreateSharedInvalidationState函数由postmaster守护进程的CreateSharedMemoryAndSemaphores函数调用以为SI Message Queue创建共享内存。主要关注procState数组大小为maxBackends,和后端进程数量限制一致,确保每个后端进程可以获取到槽。这里还引入了和队列清理阈值相关的两个参数:CLEANUP_MIN: the minimum number of messages that must be in the buffer before we bother to call SICleanupQueue;CLEANUP_QUANTUM: how often (in messages) to call SICleanupQueue once we exceed CLEANUP_MIN. Should be a power of 2 for speed. CLEANUP_MIN即队列存储最少多少消息时需要考虑清理;队列超过CLEANUP_MIN之后,下次消息数量增量达到CLEANUP_QUANTUM倍数时考虑清理。这两个参数主要用于作为nextThreshold值,当当前消息数与将要插人消息数之和超过shmInvalBuffer中nextThreshold时就会进行清理操作,调用SICleanupQueue函数。
/* CreateSharedInvalidationState: Create and initialize the SI message buffer */
void CreateSharedInvalidationState(void) {
Size size; int i; bool found;
/* Allocate space in shared memory */
size = offsetof(SISeg, procState); size = add_size(size, mul_size(sizeof(ProcState), MaxBackends));
shmInvalBuffer = (SISeg *)ShmemInitStruct("shmInvalBuffer", size, &found);
if (found) return;
/* Clear message counters, save size of procState array, init spinlock */
shmInvalBuffer->minMsgNum = 0; shmInvalBuffer->maxMsgNum = 0; shmInvalBuffer->nextThreshold = CLEANUP_MIN;
shmInvalBuffer->lastBackend = 0; shmInvalBuffer->maxBackends = MaxBackends;
SpinLockInit(&shmInvalBuffer->msgnumLock);
/* The buffer[] array is initially all unused, so we need not fill it */
/* Mark all backends inactive, and initialize nextLXID */
for (i = 0; i < shmInvalBuffer->maxBackends; i++){
shmInvalBuffer->procState[i].procPid = 0; /* inactive */
shmInvalBuffer->procState[i].proc = NULL;
shmInvalBuffer->procState[i].nextMsgNum = 0; /* meaningless */
shmInvalBuffer->procState[i].resetState = false;
shmInvalBuffer->procState[i].signaled = false;
shmInvalBuffer->procState[i].hasMessages = false;
shmInvalBuffer->procState[i].nextLXID = InvalidLocalTransactionId;
}
}
SICleanupQueue函数Remove messages that have been consumed by all active backends。在shmInvalBuffer中,Invalid Message存储在由Buffer字段指定的定长数组中(其长度MAXNUMMESSAGES预定义为4096),该数组中每一个元素存储一个Invalid Message,也可以称该数组为无效消息队列。无效消息队列实际是一个环状结构,最初数组为空时,新来的无效消息从前向后依次存放在数组中,当数组被放满之后,新的无效消息将回到Buffer数组的头部开始插人。minMsgNum字段记录Buffer中还未被所有进程处理的无效消息编号中的最小值,maxMsgNum字段记录下一个可以用于存放新无效消息的数组元素下标。实际上,minMsgNum指出了Buffer中还没有被所有进程处理的无效消息的下界,而maxMsgNum则指出了上界,即编号比minMsgNmn小的无效消息是已经被所有进程处理完的,而编号大于等于maxMsgNum的无效消息是还没有产生的,而两者之间的无效消息则是至少还有一个进程没有对其进行处理。因此在无效消息队列构成的环中,除了 minMsgNum和maxMsgNum之间的位置之外,其他位置都可以用来存放新增加的无效消息。在向SI Message队列中插入无效消息时,可能出现可用空间不够的情况(此时队列中全是没有完全被读取完毕的无效消息),需要清空一部分未处理无效消息,这个操作称为清理无效消息队列。这里的清理动作主要是:1. 确定所有后端的nextMsgNum消费游标最小的作为minMsgNum 2. 当然不是所有后端的nextMsgNum都参与最小值计算,落后太多【segP->maxMsgNum - MAXNUMMESSAGES + minFree】的后端直接被reset掉 3. 参与最小值计算的后端,且该后端的nextMsgNum小于minsig【需要发送信号MsgNum的阈值】中的最小的后端需要发送sinval catchup signal信号。
void SICleanupQueue(bool callerHasWriteLock, int minFree) {
SISeg *segP = shmInvalBuffer;
int min, minsig, lowbound, numMsgs, i;
ProcState *needSig = NULL;
/* Lock out all writers and readers */
if (!callerHasWriteLock) LWLockAcquire(SInvalWriteLock, LW_EXCLUSIVE);
LWLockAcquire(SInvalReadLock, LW_EXCLUSIVE);
/* Recompute minMsgNum = minimum of all backends' nextMsgNum, identify the furthest-back backend that needs signaling (if any), and reset any backends that are too far back. Note that because we ignore sendOnly backends here it is possible for them to keep sending messages without a problem even when they are the only active backend. */
min = segP->maxMsgNum; minsig = min - SIG_THRESHOLD; lowbound = min - MAXNUMMESSAGES + minFree;
for (i = 0; i < segP->lastBackend; i++){
ProcState *stateP = &segP->procState[i];
int n = stateP->nextMsgNum;
/* Ignore if inactive or already in reset state */
if (stateP->procPid == 0 || stateP->resetState || stateP->sendOnly) continue;
/* If we must free some space and this backend is preventing it, force him into reset state and then ignore until he catches up. */
if (n < lowbound) {
stateP->resetState = true; /* no point in signaling him ... */ continue;
}
/* Track the global minimum nextMsgNum */
if (n < min) min = n;
/* Also see who's furthest back of the unsignaled backends */
if (n < minsig && !stateP->signaled){
minsig = n; needSig = stateP;
}
}
segP->minMsgNum = min;
/* When minMsgNum gets really large, decrement all message counters so as to forestall overflow of the counters. This happens seldom enough that folding it into the previous loop would be a loser. */
if (min >= MSGNUMWRAPAROUND){
segP->minMsgNum -= MSGNUMWRAPAROUND;
segP->maxMsgNum -= MSGNUMWRAPAROUND;
for (i = 0; i < segP->lastBackend; i++){
/* we don't bother skipping inactive entries here */
segP->procState[i].nextMsgNum -= MSGNUMWRAPAROUND;
}
}
/* Determine how many messages are still in the queue, and set the threshold at which we should repeat SICleanupQueue(). */
numMsgs = segP->maxMsgNum - segP->minMsgNum;
if (numMsgs < CLEANUP_MIN) segP->nextThreshold = CLEANUP_MIN;
else segP->nextThreshold = (numMsgs / CLEANUP_QUANTUM + 1) * CLEANUP_QUANTUM;
/* Lastly, signal anyone who needs a catchup interrupt. Since SendProcSignal() might not be fast, we don't want to hold locks while executing it. */
if (needSig){
pid_t his_pid = needSig->procPid; BackendId his_backendId = (needSig - &segP->procState[0]) + 1;
needSig->signaled = true;
LWLockRelease(SInvalReadLock); LWLockRelease(SInvalWriteLock);
elog(DEBUG4, "sending sinval catchup signal to PID %d", (int) his_pid);
SendProcSignal(his_pid, PROCSIG_CATCHUP_INTERRUPT, his_backendId);
if (callerHasWriteLock) LWLockAcquire(SInvalWriteLock, LW_EXCLUSIVE);
} else {
LWLockRelease(SInvalReadLock);
if (!callerHasWriteLock) LWLockRelease(SInvalWriteLock);
}
}
PostgreSQL后端如何使用
SI Message队列工作的流程大致如下:
- SI message 队列的初始化(上个小集已经描述了)。这个是由postmaster在启动服务器时做的,作为共享内存的一部分,由postmaster初始化。此时,SI message为空,因为此时还没有Invalid Message产生。
- 每个backend初始化(我们知道这些Invalid Message是由于我执行了SQL文对数据库进行了修改才产生的,那么很显然我们执行SQL文的途径是前端发送SQL文,后端启动一个backend进程去处理)时,需要初始化自己的共享内存并且向SI message注册自己。注册的目的有两个,一个是声明自己作为Invalid Message的生产者的身份,另一个表示自己也需要接受其他backend的Invalid Message。SharedInvalBackendInit作为初始化函数,在如下三处被调用:
InitPostgres->SharedInvalBackendInit(false)、StartupXLOG->UpdateCatalogForStandbyPromotion->SharedInvalBackendInit(false)、StartupXLOG->InitRecoveryTransactionEnvironment->SharedInvalBackendInit(true)。 - 每个backend执行SQL文,产生Invalid Message,其他backend接收该Invalid Message。SIInsertDataEntries、SIGetDataEntries用于向队列插入和获取消息。
AcceptInvalidationMessages函数最终会调用SIGetDataEntries,而SendSharedInvalidMessages最终会调用SICleanupQueue,以下梳理这两个函数被调用的流程:
- relation_openrv和relation_openrv_extended函数Check for shared-cache-inval messages before trying to open the relation,调用AcceptInvalidationMessages
- StartTransaction时,AtStart_Cache函数调用AcceptInvalidationMessages
- RangeVarGetRelidExtended和TempNamespaceValid函数调用AcceptInvalidationMessages
- RemoveRelations函数调用AcceptInvalidationMessages
- relcache在执行write_relcache_init_file函数时调用AcceptInvalidationMessages以Make sure we have seen all incoming SI messages
- LockRelationOid、ConditionalLockRelationOid、LockRelation、LockRelationNoWait、ConditionalLockRelation、LockDatabaseObject和LockSharedObject函数调用AcceptInvalidationMessages
- FinishPreparedTransaction函数->SendSharedInvalidMessages
- xact_redo_commit_internal函数->ProcessCommittedInvalidationMessages函数->SendSharedInvalidMessages
- vm_extend/smgrdounlink/smgrdounlinkall/smgrtruncate ->CacheInvalidateSmgr函数->SendSharedInvalidMessages
- CacheInvalidateRelmap函数->SendSharedInvalidMessages
每次执行SQL的时候,在执行SQL文的开头和结尾,backend都会去check SI message队列中的无效消息。难道我不执行SQL文,我的backend就不刷新无效消息么?要是某个backend长时间不读取SI Message或者backend落后太多,超过了SI Message队列可以接受的最大长度,那么就向该backend发送SIGUSR1,唤醒该backend让其做适当的操作。
exec_simple_query
->start_xact_command
->StartTransactionCommand /* 事务开始
->StartTransaction
->AtStart_Cache
->AcceptInvalidationMessages
->ReceiveSharedInvalidMessages /* consume SI message
->SIGetDataEntries
-> do query
->finish_xact_command
->CommitTransactionCommand /* 事务结束
->CommitTransaction
->AtEOXact_Inval
->SendSharedInvalidMessages /* send SI message
->SIInsertDataEntries
->SICleanupQueue
PROCSIG_CATCHUP_INTERRUPT信号处理

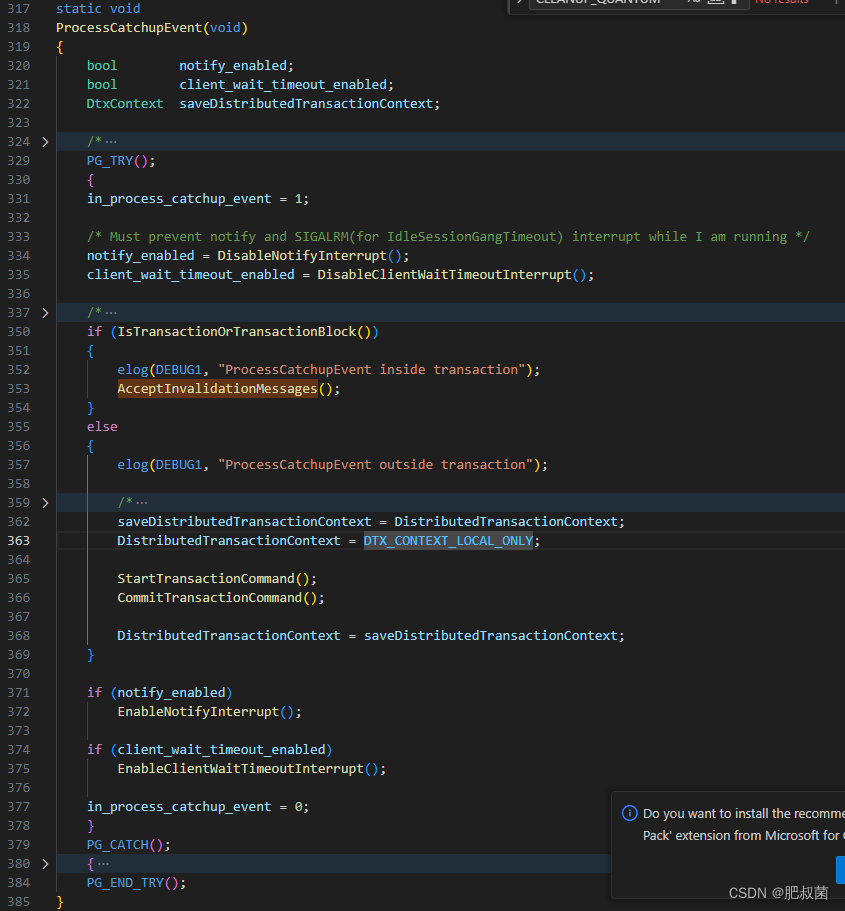
HandleCatchupInterrupt函数当后端进程收到PROCSIG_CATCHUP_INTERRUPT时调用。If we are idle (catchupInterruptEnabled is set), we can safely invoke ProcessCatchupEvent directly. Otherwise, just set a flag to do it later. (Note that it’s quite possible for normal processing of the current transaction to cause ReceiveSharedInvalidMessages() to be run later on; in that case the flag will get cleared again, since there’s no longer any reason to do anything.)
void HandleCatchupInterrupt(void) {
/* Note: this is called by a SIGNAL HANDLER. You must be very wary what you do here. */
/* Don't joggle the elbow of proc_exit */
if (proc_exit_inprogress) return;
if (catchupInterruptEnabled) {
bool save_ImmediateInterruptOK = ImmediateInterruptOK;
/* We may be called while ImmediateInterruptOK is true; turn it off while messing with the catchup state. This prevents problems if SIGINT or similar arrives while we're working. Just to be real sure, bump the interrupt holdoff counter as well. That way, even if something inside ProcessCatchupEvent() transiently sets ImmediateInterruptOK (eg while waiting on a lock), we won't get interrupted until we're done with the catchup interrupt. */
ImmediateInterruptOK = false;
HOLD_INTERRUPTS();
/* I'm not sure whether some flavors of Unix might allow another SIGUSR1 occurrence to recursively interrupt this routine. To cope with the possibility, we do the same sort of dance that EnableCatchupInterrupt must do --- see that routine for comments. */
catchupInterruptEnabled = 0; /* disable any recursive signal */
catchupInterruptOccurred = 1; /* do at least one iteration */
for (;;) {
catchupInterruptEnabled = 1;
if (!catchupInterruptOccurred) break;
catchupInterruptEnabled = 0;
if (catchupInterruptOccurred)
{
/* Here, it is finally safe to do stuff. */
ProcessCatchupEvent();
}
}
/* Restore the holdoff level and ImmediateInterruptOK, and check for interrupts if needed. */
RESUME_INTERRUPTS();
ImmediateInterruptOK = save_ImmediateInterruptOK;
if (save_ImmediateInterruptOK)
CHECK_FOR_INTERRUPTS();
}else{
/* In this path it is NOT SAFE to do much of anything, except this: */
catchupInterruptOccurred = 1;
}
}
和virtual transaction id的关联
We split VirtualTransactionIds into two parts so that it is possible to allocate a new one without any contention for shared memory, except for a bit of additional overhead during backend startup/shutdown. The high-order part of a VirtualTransactionId is a BackendId, and the low-order part is a LocalTransactionId, which we assign from a local counter. To avoid the risk of a VirtualTransactionId being reused within a short interval, successive procs occupying the same backend ID slot should use a consecutive sequence of local IDs, which is implemented by copying nextLocalTransactionId as seen above. 我们将VirtualTransactionId分为两部分,这样就可以在没有任何共享内存争用的情况下分配一个新的,除了在后端启动/关闭期间有一点额外的开销。VirtualTransactionId的高阶部分是BackendId,低阶部分是LocalTransactionId,我们从本地计数器分配它。为了避免VirtualTransactionId在短时间内被重用的风险,占用同一后端ID插槽的连续进程应该使用连续的本地ID序列,这是通过复制nextLocalTransactionId来实现的,如上所述。可以通过SharedInvalBackendInit函数观察到MyBackendId和nextLocalTransactionId的赋值流程。
/* GetNextLocalTransactionId --- allocate a new LocalTransactionId */
LocalTransactionId GetNextLocalTransactionId(void) {
LocalTransactionId result;
/* loop to avoid returning InvalidLocalTransactionId at wraparound */
do
{
result = nextLocalTransactionId++;
} while (!LocalTransactionIdIsValid(result));
return result;
}
https://www.cnblogs.com/flying-tiger/p/8414374.html
https://zhuanlan.zhihu.com/p/234681800