题目
- 背景
- 1. 多线程有哪些基本参数?
- 2. 线程池是如何实现的?
- 3. ThreadLocal是怎么存的?
- 4. JVM内存模型(JDK1.8)了解吗?
- 5. 直接内存是用来存什么的?
- 6.NIO采用的是Linux哪种IO模型
- 7.常用的限流算法,挑一种讲讲?
- 8.Hashmap是怎么实现的?
- 9. redis碎片是如何产生的?
- 10. 如何提高数据库查询性能?
- 11. 最后:mysql的binlog是做什么的?
背景
某国企技术面试,职位是java高级开发工程师,个人情况:有八年java开发工作经验,平时也算是热爱学习,有个软考高级证书,没有带过团队。
看了一下高级的招聘要求,感觉都赶上对架构师的要求了,感觉做技术一把手很心虚(菜),但如果上面有个架构师,平时有疑难问题还可以求助,这个工作状态应该蛮好的。面试官有3位,两位技术一位人力HR。俗话说面试造火箭,工作拧螺丝,真的太贴切了,问的都是原理类的(不是会用,是这个XX东西是如何设计的,优缺点?太难了)
以下是本次面试技术问题的复盘,答案是个人见解,如有错误敬请批评指正,感谢您的收藏支持。
1. 多线程有哪些基本参数?
CorePoolSize, MaximumPollSize, AliveTime, Unit, WorkQueue, ThreadFactory,Stragetory
描述每个参数的概念及大概的任务处理流程,如:
(1)提交一个任务,线程池里存活的核心线程数小于线程数corePoolSize时,线程池会创建一个核心线程去处理提交的任务。
(2)如果线程池核心线程数已满,即线程数已经等于corePoolSize,一个新提交的任务,会被放进任务队列workQueue排队等待执行。
(3)当线程池里面存活的线程数已经等于corePoolSize了,并且任务队列workQueue也满,判断线程数是否达到maximumPoolSize,即最大线程数是否已满,如果没到达,创建一个非核心线程执行提交的任务。
(4)如果当前的线程数达到了maximumPoolSize,还有新的任务过来的话,直接采用拒绝策略处理。
面试官进一步提问了有哪些拒绝策略?
1.AbortPolicy – 当任务添加到线程池中被拒绝时,它将抛出 RejectedExecutionException 异常。
2.CallerRunsPolicy – 当任务添加到线程池中被拒绝时,会在线程池当前正在运行的Thread决定被拒绝的任务就由谁来处理。
3.DiscardOldestPolicy – 当任务添加到线程池中被拒绝时,线程池会放弃等待队列中最旧的未处理任务,然后将被拒绝的任务添加到等待队列中。
4.DiscardPolicy – 当任务添加到线程池中被拒绝时,线程池将丢弃被拒绝的任务。
2. 线程池是如何实现的?
线程池在内部实际上构建了一个生产者/消费者模型,任务管理部分充当生产者,当任务提交后,缓程池会判断该任务的后续流转(直接申请线程执行该任务、缓冲到队列中等待执行、拒绝该任务)。线程管理部分是消费者,它们被统一维护在线程地内,根据任务请求进行线程的分配(当线程执行完任务后继续获取新的任务去执行,最终当线程获取不到任多时被回收)。
3. ThreadLocal是怎么存的?
ThreadLocal是一种数据结构,可以防止各个线程之间的数据互相干扰。每个线程的内部都维护了一个 ThreadLocalMap,它是一个 Map(key,value)数据格式,key 是一个弱引用,也就是 ThreadLocal 本身,而 value 存的是线程变量的值。当ThreadLocal执行set方法时,其值保存在当前线程的threadlocals变置中,当执行get方法时,也从当前线程的threadlocals变量取。
题外话:ThreadLocal 如何解决 Hash 冲突?
与 HashMap 不同,ThreadLocalMap 结构非常简单,没有 next 引用,也就是说 ThreadLocalMap 中解决 Hash 冲突的方式并非链表的方式,而是采用线性探测的方式。如果使网threadlocals的set方法后没有显式的调用remove方法,就有可能发生内存泄露,所以用完后记得调用remove。
4. JVM内存模型(JDK1.8)了解吗?
(1)程序计数器:程序计数器是一块较小的内存空间,它可以看作是当前线程所执行的字节码的行号指示器。每个线程都有自己的程序计数器,它的作用是记录线程下一步要执行的指令。
(2)Java虚拟机栈:JVM栈是每个线程私有的,用于存储方法调用的局部变量、操作数栈、中间结果和返回值。(JVM栈的大小在编译器创建时就已经确定,并且它的生命周期与线程相同。)
(3)本地方法栈:本地方法栈与JVM栈类似,但是它为本地方法(非Java代码)提供了内存空间。
(4)Java堆:Java堆是JVM的最大一块内存区域,它是被所有线程共享的。Java堆用于存储对象实例和数组,它是垃圾回收器管理的主要区域。
(5)方法区:方法区也是被所有线程共享的一块内存区域,它用于存储被加载的类信息、常量、静态变量和编译器优化后的代码。
(6)运行时常量池:运行时常量池是方法区的一部分,它存储着编译器生成的各种字面量和符号引用,这些数据在类加载后存放在运行时常量池中。
(7)直接内存:直接内存是Java虚拟机直接使用操作系统的内存空间,它与Java堆不同,不受JVM参数-Xmx和-Xms的控制
堆是垃圾收集器的主要管理区域,不出意外问内存模型必问垃圾回收算法,这个也要看一下
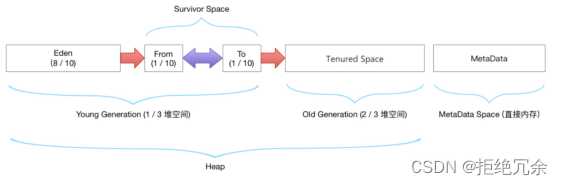
JDK1.8同1.7比,最大的差别就是:元数据区取代了永久代(两者都是方法区的实现),就是JDK8没有了PermSize相关的参数配置了。
5. 直接内存是用来存什么的?
在JVM中,直接内存是通过ByteBuffer类来实现的。ByteBuffer类提供了一种在JVM堆之外分配内存的方式,可以通过allocateDirect()方法来分配直接内存。与JVM堆内存不同,直接内存不受JVM堆大小的限制,因此可以用于处理大量的数据,例如网络传输、文件IO、数据库操作等。在这些场景中,需要频繁地读写大量的数据,如果使用JVM堆内存,可能会导致内存溢出或频繁的GC,从而影响程序的性能。
题外话:ByteBuffer是放在哪个内存区域:堆
6.NIO采用的是Linux哪种IO模型
java的IO模型:BIO(同步阻塞)、NIO(同步非阻塞)、AIO(异步非阻塞)
Linux(操作系统):阻塞IO、非阻塞IO、IO多路复用、信号驱动IO、异步IO。
答案:java的NIO对应Linux中NIO采用的是Linux中非阻塞IO、IO多路复用、信号驱动IO
关于Linux五种基本IO模型已有有很多动画或者实例讲解的文章,要想理解,自行搜索吧
7.常用的限流算法,挑一种讲讲?
经典的限流算法有三种:计数器法,漏桶算法和令牌桶算法
- 计数器法简单粗暴,首先维护一个计数器,将单位时间段当做一个窗口,计数器记录这个窗口接收请求的次数。
当次数少于限流阀值,就允许访问,并且计数器+1,当次数大于限流阀值,就拒绝访问。当前的时间窗口过去之后,计数器清零。缺点就是:假设我们允许的阈值是1万, 当1万个请求在计数器清零前1秒内一股脑儿的都涌进来,这突发的流量可是顶不住的。 - 漏桶算法可以认为就是注水漏水的过程。往漏桶中以任意速率流入水,以固定的速率流出水。当水超过桶的容量时,会被溢出,也就是被丢弃。因为桶容量是不变的,保证了整体的速率。缺点:面对突发请求,服务的处理速度和平时是一样的,这其实不是我们想要的,在面对突发流量我们希望在系统平稳的同时,提升用户体验即能更快的处理请求,而不是和正常流量一样,循规蹈矩的处理。
令牌桶算法是对漏斗算法的一种改进,除了能够起到限流的作用外,还允许一定程度的流量突发。
令牌桶算法原理:有一个令牌管理员,根据限流大小,定速往令牌桶里放令牌。如果令牌数量满了,超过令牌桶容量的限制,那就丢弃。系统在接受到一个用户请求时,都会先去令牌桶要一个令牌。如果拿到令牌,那么就处理这个请求的业务逻辑;如果拿不到令牌,就直接拒绝这个请求。缺点是实现相对复杂。
8.Hashmap是怎么实现的?
在jdk1.7中,hashMap的主干是个Entry数组,每个Entry包含一个key-value键值对。HashMap由数组+链表组成的,数组是HashMap的主体,链表则是主要为了解决哈希冲突而存在的,如果定位到的数组位置不含链表(当前entry的next指向null),那么查找,添加等操作很快,仅需一次寻址即可;如果定位到的数组包含链表,对于添加操作,其时间复杂度为O(n),首先遍历链表,存在即覆盖,否则新增; 当链表过长时,会影响查询value的效率,因为链表不适合查询,适合增加、删除操作。
9. redis碎片是如何产生的?
Redis 内存碎片产生比较常见的 2 个原因:
1、Redis 存储存储数据的时候向操作系统申请的内存空间可能会大于数据实际需要的存储空间。
2、频繁修改 Redis 中的数据也会产生内存碎片。
可以先说一下操作系统内存分配的原理:内存分配器不是按实际申请的大小来分配,而是分一个固定大小的空间(目的是为了减少分配次数,分配空间通常是2的整数倍),而且分配的空间必须是连续的,这样多出来的空间可能不能再此被分配,就产生了内存碎片。
如何清理 Redis 内存碎片?
Redis4.0-RC3 版本(直接说新版本就行)以后自带了内存整理,可以避免内存碎片率过大的问题。
10. 如何提高数据库查询性能?
各种优化吧,可以认真想想
11. 最后:mysql的binlog是做什么的?
还有其他mysql的问题,一些基本命令的用法。
各位先做个自我介绍,然后答完这些问题(还有一些通用问题如离职原因期望薪资等)需要多久,演练一下,我竟然从进门到出来就半个小时,可见回答的都很粗略了,平时工作中还是得慢慢的积累,等待机会。