一、项目简介
本项目是一套基于Python开发的Excel数据分析系统,主要针对计算机相关专业的正在做毕设的学生与需要项目实战练习的Python学习者。
包含:项目源码、项目文档等,该项目附带全部源码可作为毕设使用。
项目都经过严格调试,确保可以运行!
二、开发环境要求
本系统的软件开发及运行环境具体如下。
操作系统:Windows 7、Windows 10。
Python版本:Python 3.6。
可视化开发环境:PyCharm 2017.3.3。
界面设计工具:Qt Designer
Python内置模块:os、sys、glob、numpy。
第三方模块:PyQt5、pyqt5-tools、pandas、matplotlib、xlrd。
注意:在使用第三方模块时,首先需要使用pip install命令安装该模块,例如,安装PyQt5模块,可以在Python命令窗口中执行以下命令:
pip install pandas
三、系统功能
导入EXCEL
提取列表数据
定向筛选
多表合并
多表统计排行
生成图表
贡献度分析
退出
四、页面功能
在PyCharm中运行《Excel数据分析师》即可进入如图1所示的系统主界面。在该界面中,通过顶部的工具栏可以选择所要进行的操作
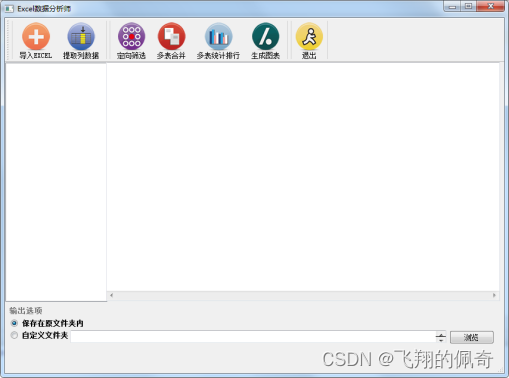
具体的操作步骤如下:
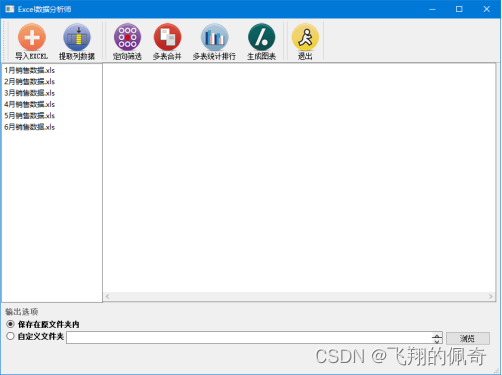
(1)导入Excel。单击工具栏中的“导入Excel”按钮,打开文件对话框选择文件夹,如XS1文件夹,系统将遍历该文件夹中的*.xls文件,并且将文件添加到列表区,效果如图2所示。
(2)提取列数据。单击工具栏中的“提取列数据”按钮,提取买家会员名、收货人姓名、联系手机和宝贝标题,效果如图3所示。提取后的数据将保存在程序所在目录下的mycell.xls文件中。
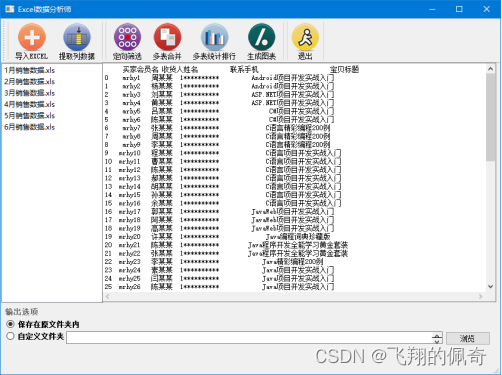
说明:“输出选项”可以选择数据分析结果要保存的位置,默认是程序所在文件夹。
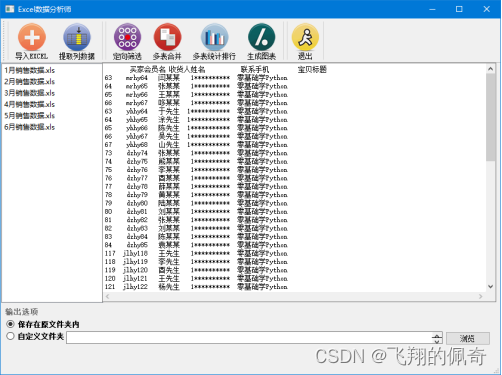
(3)定向筛选。单击工具栏中的“定向筛选”按钮,筛选“零基础学Python”的用户信息,效果如图4所示。筛选后的数据将保存在程序所在目录下的mycell.xls文件中。
(4)多表合并。单击工具栏中的“多表合并”按钮,将列表中的Excel表全部合并成一个表,合并结果将保存在程序所在目录下的mycell.xls文件中。
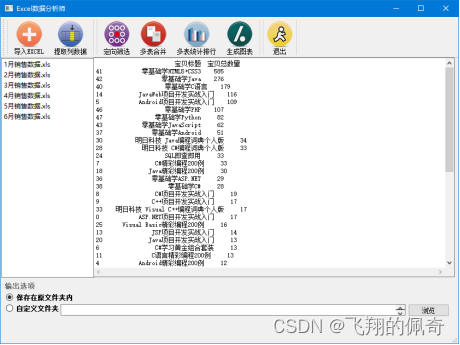
(5)多表统计排行。单击工具栏中的“多表统计排行”按钮,按“宝贝标题”进行分组统计数量并进行排序,效果如图5所示。统计排行结果将保存在程序所在目录下的mycell.xls文件中。
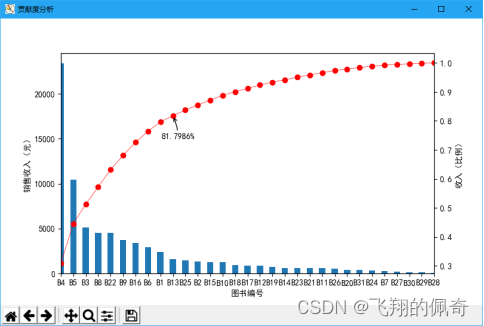
(5)生成图表,该功能主要分析产品的贡献度。单击工具栏中的“生成图表”按钮,将全彩系列图书2018年上半年收入占80%的产品以图表形式展示,效果如图6所示。
五、部分代码展示
#多表合并
def click4(self):
global root
# 合并指定文件夹下的所有Excel表
filearray = []
filelocation = glob.glob(root+"\*.xls")
for filename in filelocation:
filearray.append(filename)
res = pd.read_excel(filearray[0])
for i in range(1, len(filearray)):
A = pd.read_excel(filearray[i])
res = pd.concat([res, A], ignore_index=False, sort=True)
self.textEdit.setText(str(res.index))
# 调用SaveExcel函数,将合并后的数据保存到Excel
SaveExcel(res, self.rButton2.isChecked())
#多表统计排行
def click5(self):
global root
# 合并Excel表格
filearray = []
filelocation = glob.glob(root + "\*.xls")
for filename in filelocation:
filearray.append(filename)
res = pd.read_excel(filearray[0])
for i in range(1, len(filearray)):
A = pd.read_excel(filearray[i])
res = pd.concat([res, A], ignore_index=False, sort=True)
# 分组统计排序
# 通过reset_index()函数将groupby()的分组结果转成DataFrame对象
df = res.groupby(["宝贝标题"])["宝贝总数量"].sum().reset_index()
df1 = df.sort_values(by='宝贝总数量', ascending=False)
self.textEdit.setText(str(df1))
# 调用SaveExcel函数,将统计排行结果保存到Excel
SaveExcel(df1, self.rButton2.isChecked())
def click6(self):
global root
# 合并Excel表格
filearray = []
filelocation = glob.glob(root + "\*.xls")
for filename in filelocation:
filearray.append(filename)
res = pd.read_excel(filearray[0])
for i in range(1, len(filearray)):
A = pd.read_excel(filearray[i])
res = pd.concat([res, A], ignore_index=False, sort=True)
# 分组统计排序
# 通过reset_index()函数将groupby()的分组结果转成DataFrame对象
df=res[(res.类别=='全彩系列')]
df1 = df.groupby(["图书编号"])["买家实际支付金额"].sum().reset_index()
df1 = df1.set_index('图书编号') # 设置索引
df1 = df1[u'买家实际支付金额'].copy()
df2=df1.sort_values(ascending=False) # 排序
SaveExcel(df2, self.rButton2.isChecked())
# 图表字体为华文细黑,字号为12
plt.rc('font', family='SimHei', size=10)
#plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure("贡献度分析")
df2.plot(kind='bar')
plt.ylabel(u'销售收入(元)')
p = 1.0*df2.cumsum()/df2.sum()
print(p)
p.plot(color='r', secondary_y=True, style='-o', linewidth=0.5)
#plt.title("图书贡献度分析")
plt.annotate(format(p[9], '.4%'), xy=(9, p[9]), xytext=(9 * 0.9, p[9] * 0.9),
arrowprops=dict(arrowstyle="->", connectionstyle="arc3,rad=.1")) # 添加标记,并指定箭头样式。
plt.ylabel(u'收入(比例)')
plt.show()
#单击“浏览”按钮选择文件存储路径
def viewButton_click(self):
global temproot
temproot = QFileDialog.getExistingDirectory(self, "选择文件夹", "/")
self.text1.setText(temproot)
六、源码地址
https://download.csdn.net/download/weixin_43860634/88335427