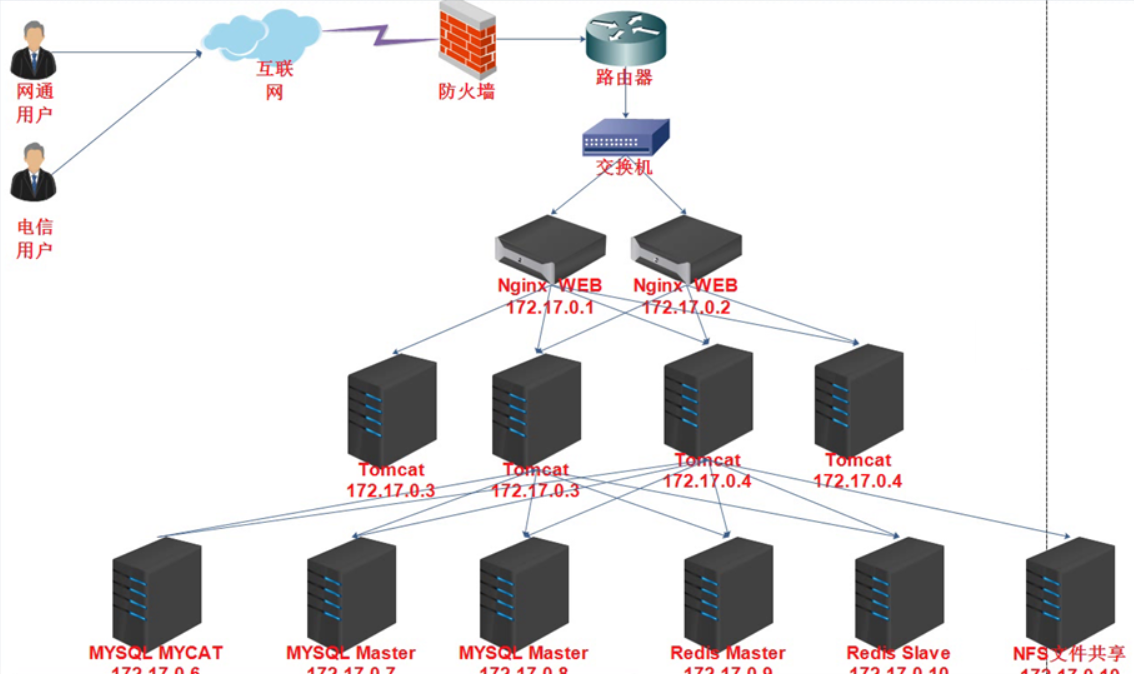
Java8实战-总结27
- 用流收集数据
- 分区
- 分区的优势
- 将数字按质数和非质数分区
用流收集数据
分区
分区是分组的特殊情况:由一个谓词(返回一个布尔值的函数)作为分类函数,它称分区函数。分区函数返回一个布尔值,这意味着得到的分组Map的键类型是Boolean,于是它最多可以分为两组——true是一组,false是一组。例如,如果把菜单按照素食和非素食分开:
//分区函数
Map<Boolean, List<Dish>> partitionedMenu = menu.stream().collect(partitioningBy(Dish::isVegetarian));
这会返回下面的Map:
{false=[pork, beef,chicken, prawns, salmon], true=[french fries, rice, season fruit, pizza])
那么通过Map中键为true的值,就可以找出所有的素食菜肴了:
List<Dish> vegetarianDishes = partitionedMenu.get(true);
请注意,用同样的分区谓词,对菜单List创建的流作筛选,然后把结果收集到另外一个List中也可以获得相同的结果:
List<Dish> vegetarianDishes = menu.stream().filter(Dish::isVegetarian).collect(toList ();
分区的优势
分区的好处在于保留了分区函数返回true或false的两套流元素列表。在上一个例子中,要得到非素食Dish的List,可以使用两个筛选操作来访问partitionedMenu这个Map中false键的值:一个利用谓词,一个利用该谓词的非。而且就像在分组中看到的,partitioningBy工厂方法有一个重载版本,可以像下面这样传递第二个收集器:
Map<Boolean, Map<Dish.Type,List<Dish>>> vegetarianDishesByType = menu.stream()
.collect(//一分区函数
partitioningBy(Dish::isVegetarian,
groupingBy(Dish::getType)));//第二个收集器
这将产生一个二级Map:
{false = {FISH = [prawns, salmon], MEAT = [pork, beef, chicken]},
true = {OTHER = [french fries, rice, season fruit, pizza]}}
这里,对于分区产生的素食和非素食子流,分别按类型对菜肴分组,得到了一个二级Map。再举一个例子,可以重用前面的代码来找到素食和非素食中热量最高的菜:
Map<Boolean, Dish> mostCaloricPartitionedByVegetarian =
menu.stream().collect(
partitioningBy(Dish::isVegetarian,
collectingAndThen(
maxBy(comparingInt(Dish::getCalories)),
Optional::get)));
这将产生以下结果:
{false=pork, true=pizza}
可以把分区看作分组一种特殊情况。groupingBy和partitioningBy收集器之间的相似之处并不止于此.
测验:使用partitioningBy
我们已经看到,和groupingBy收集器类似,partitioningBy收集器也可以结合其他收集器使用。尤其是它可以与第二个partitioningBy收集器一起使用来实现多级分区。
以下多级分区的结果会是什么呢?
(1)menu.stream().collect(partitioningBy(Dish::isVegetarian,
partitioningBy (d -> d.getCalories()> 500>));
(2)menu.stream().collect (partitioningBy(Dish::isVegetarian,partitioningBy (Dish::getType)));
(3)menu.stream().collect (partitioningBy(Dish::isvegetarian,counting()));
答案如下。
(1)这是一个有效的多级分区,产生以下二级Map:
{false={false=[chicken,prawns, salmon], true=[pork, beef]},
true={false=[rice, season fruit], true=[french fries, pizza]}}
(2)这无法编译,因为partitioningBy需要一个谓词,也就是返回一个布尔值的函数。方法引用Dish::getType不能用作谓词。
(3)它会计算每个分区中项目的数目,得到以下Map:
{false=5,true=4}
将数字按质数和非质数分区
假设你要写一个方法,它接受参数int n,并将前n个自然数分为质数和非质数。但首先,找出能够测试某一个待测数字是否是质数的谓词会很有帮助:
public boolean isPrime(int candidate) {
return IntStream.range(2, candidate)//产生一个自然数范围,从2开始,直至但不包括待测数
.noneMatch(i -> candidate % i == 0);//如果待测数字不能被流中任何数字整除则返回true
一个简单的优化是仅测试小于等于待测数平方根的因子:
public boolean isPrime(int candidate) {
int candidateRoot =(int)Math.sqrt((double)candidate);
return IntStream.rangeclosed(2, candidateRoot)
.noneMatch(i -> candidate % i == 0);
现在最主要的一部分工作已经做好了。为了把前n个数字分为质数和非质数,只要创建一个包含这n个数的流,用刚刚写的isPrime方法作为谓词,再给partitioningBy收集器归约就好了:
public Map<Boolean, List<Integer>> partitionPrimes(int n) {
return IntStream.rangeclosed(2, n).boxed()
.collect(
partitioningBy(candidate -> isPrime(candidate)));
现在已经讨论过了Collectors类的静态工厂方法能够创建的所有收集器,并介绍了使用它们的实际例子。下表将它们汇总到一起,给出了它们应用到stream<T>上返回的类型,以及它们用于一个叫作menuStream的Stream<Dish>上的实际例子。