CPU
现在CPU都是多核结构,每个核心都有自己的一级缓存,二级缓存,以及共享的三级缓存。如下图,其中一级缓存分为指令缓存IL1和数据缓存DL1,二级缓存L2 256kB,三级缓存 L3 8MB。
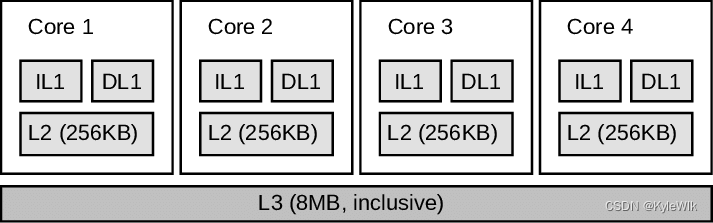
从上图可以看出L3比L2大得多,但是L3离核心比较远,访问速度比较慢,L3后面则是与内存相连。当CPU核心要读取内存数据时,需要先从内存读取到L3,再到L2,再到L1.....。
因CPU有多个核心,所以可以同时并行多个线程。CPU的每个核心可以有多个ALU(逻辑运算单元),也就是说单个核心内部也可以并行执行指令提高运行速度,而且CPU为进一步加快运行速度,还引入了乱序执行、分支预测等。
在多线程中并行执行就会有数据竞争(Data Race),需要加锁,防止多个线程同时访问数据,导致数据被破坏。
程序执行
执行顺序
程序在CPU中执行的顺序是不可确定的,除了因为上面提到的乱序执行、分支预测,还有CPU会对执行指令进行重排,且编译器在编译时也会对指令进行重排,提高运行速度。
指令重排
指令重排有一个要求:重排后的指令在单线程下执行的结果与重排前一致。 如下3行代码:

代码的执行顺序可以是:2、1、3,但是不能是 2、3、1。
Debug版本程序中不会进行指令重排,程序会按照代码逐行执行。程序在Release版本下才会进行指令重排,如果调试Release版本程序,并不一定完全按照代码顺序执行,特别是ARM处理器(手机上)。Debug版本因为缺少指令优化,执行速度会比Release版本慢很多。
多线程指令重排
指令重排对单线程没有影响,但多线程影响很大。例如以下代码:
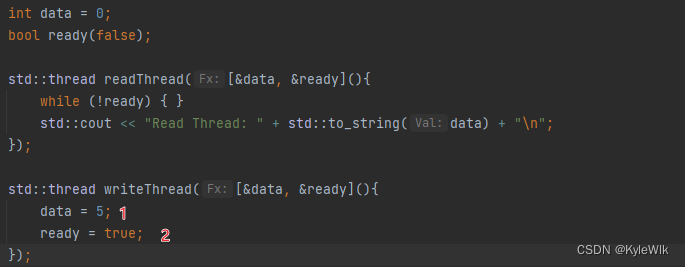
如果writeThread中 1、2 两行代码进行指令重排,执行顺序位2、1,这会导致readThread读取到的data数据为0。
缓存
当某个线程修改数据,其首先修改的是线程运行所在核心的L1缓存,其他核心并不能第一实际看到,其他核心还会继续使用修改前的数据。例如以下代码:
// 需要在Release模式下测试, 代码在VS2022 Release模式上测试readThread会死循环
int data = 0;
bool ready(false);
std::thread readThread([&data, &ready]() {
int n = 0;
while (!ready) { ++n; /*++n 为防止空循环被过度优化*/ }
std::cout << n << "Read Thread1: " + std::to_string(data) + "\n";
});
std::thread writeThread([&data, &ready]() {
std::this_thread::sleep_for(std::chrono::microseconds(10)); // 延迟执行
data = 5;
std::atomic_thread_fence(std::memory_order_seq_cst); //防止指令重排
ready = true;
});
readThread中whlie会出现死循环,因为writeTread修改了ready变量,但readThread所在核心的缓存并没用刷新,缓存不一致,ready始终是false。
内存模型 Memory Model
上面提到多线程的三个问题:数据竞争(Data Race),指令重排,缓存一致性(cache coherence),内存模型可以用来解决这三个问题。
数据竞争(Data Race)
Data Race解决最简单的办法就是加锁,同mutex对象限制同时只有一个线程可以访问数据。C++ 20 还增加了Semaphores、barrier用于同步线程,这些对象在某些情况下也可也用于解决Data Race问题。
除了加锁还可以使用原子变量 atomic,原子变量可以保证每次只有一个线程操作数据。
缓存一致性(cache coherence)
当一个线程修改数据后,另一个线程需要刷新缓存,保证缓存一致性。以下方法可以刷新缓存:
1. 当线程获得锁时,此时会刷新缓存。
2. 使用原子操作,原子变量有修改时,其他线程在读取时会自动刷新对应的缓存。
3. 内存屏障,C++ 11中提供的函数std::atomic_thread_fence可以相当于设置内存屏障,通过调用这个函数,也可以刷新缓存。
4. yield、sleep_for、sleep_until有概率会把线程切换出核心,当线程再次被切换回核心时,此时会刷新缓存。
指令重排
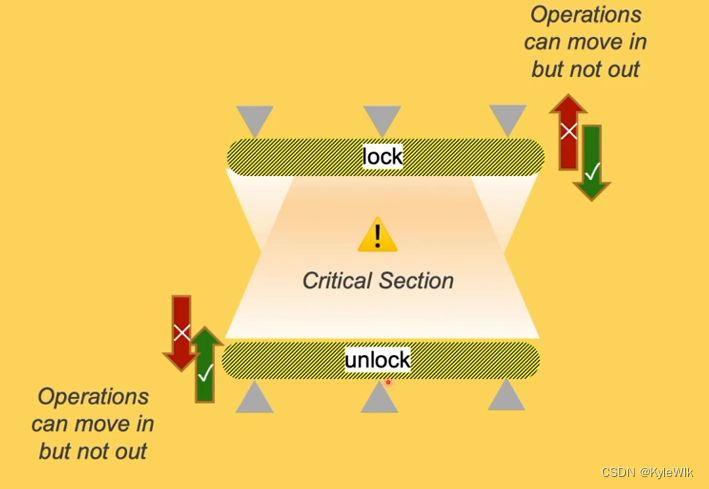
使用mutex阻止指令重排
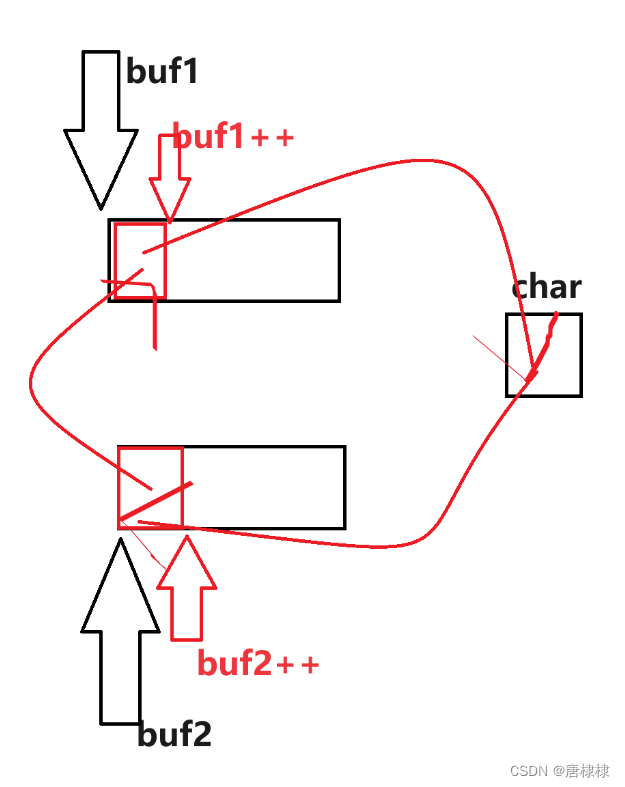
mutex可以防止指令重排,mutex.lock可以阻止lock后面的指令重排到lock前面。mutex.unlock可以阻止unlock内部的指令重排到外面。 如下图:
使用原子变量阻止指令重排
默认情况下原子变量的读写都会阻止原子变量前面的指令重排到后面,也可以阻止后面的指令重排到前面。相当于原子变量读写就是一个屏障,阻止了指令重排时穿过屏障。
如过不使用原子变量可以使用函数std::atomic_thread_fence(std::memory_order_seq_cst),效果相同。
Atomic和Memory Oreder
C++ 11 原子操作中引入了Memory Oreder,原子操作函数load、store、fetch_add等函数可以设置一个Memory Order参数,用于控制指令重排和缓存刷新。
- memory_order_seq_cst,Sequentially-consistent ordering,Atomic的默认操作,阻止原子变量操作前面的指令重排到后面,也可以阻止后面的指令重排到前面,相当于一个屏障,阻止了指令重排时穿过屏障,同时也会刷新缓存。
- memory_order_relaxed,不限制重排,只保证原子操作。
- memory_order_acquire ,memory_order_consume都用于读取函数,都可以限制后面的指令重排到读取前面,与mutex.unlock相同,并刷新缓存。不同之处是consume只会刷新原子变量的缓存,acquire会刷新所有变量的缓存(包括非原子变量)。有些情况下consume效率更高,但是并不是所有设备都会实现consume,有些设备底层会使用acquire实现consume,C++ 17开始也不鼓励使用consume。
- memory_order_release,用于写入数据,可以限制前面的指令重排到读,与mutex.lock相同。
- memory_order_acq_rel,用于同时有读取和写入的函数,例如:exchange函数,对读取使用release,对写入使用acquire。
执行顺序
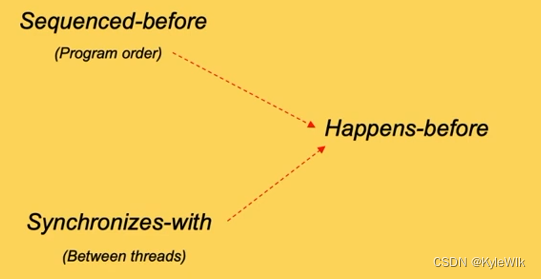
Sequenced-before Sequenced代表代码的顺序,Sequenced-before相当于指令的代码在前面。Sequenced-before只在线程内,不可以超出线程。Sequenced-before确定需要考虑运算符优先级,等于号的左右,函数参数调用顺序等待。
Synchronizes with 是多个线程之间一条指令必须在另一条指令前执行。例如生成者线程必须产生数据,消费者线程才能使用数据。产生数据的指令Synchronizes with使用数据的指令。
Happens-before 一个指令在另一个指令前执行,Sequenced-before是Happens-before的单线程形式,Synchronizes with是Happens-before的多线程形式。
同步
借助Atomic的Memory Order操作,可以实现Synchronizes with关系,在线程中实现同步,以及实现无锁编程(Lock Free)。
例如可以通过memory_order_release和memory_order_acquire实现同步生产者消费者,代码如下:
// 来源:https://en.cppreference.com/w/cpp/atomic/memory_order
#include <atomic>
#include <cassert>
#include <string>
#include <thread>
std::atomic<std::string*> ptr = nullptr;
int data = 0;
void producer()
{
std::string* p = new std::string("Hello");
data = 42;
ptr.store(p, std::memory_order_release);
}
void consumer()
{
std::string* p2;
while (!(p2 = ptr.load(std::memory_order_acquire)))
;
assert(*p2 == "Hello"); // never fires
assert(data == 42); // never fires
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join(); t2.join();
}参考:https://www.youtube.com/watch?v=IE6EpkT7cJ4