文章目录
一、任务目标
二、实行任务 1. 创建Maven项目 2. 添加相关依赖 3. 创建日志属性文件 4. 创建学生实体类 5. 创建学生映射器类 6. 创建学生归并器类 7. 创建学生驱动类 8. 启动学生驱动器类,查看结果
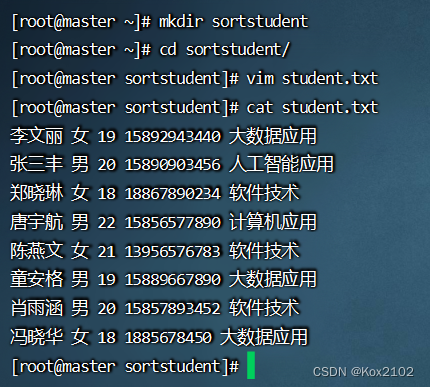
创建sortstudent目录,在里面创建student.txt文件 创建/sortstudent/input目录,执行命令:hdfs dfs -mkdir -p /sortstudent/input 将文本文件student.txt,上传到HDFS的/sortstudent/input目录 Maven项目 - SortStudent 在pom.xml文件里添加hadoop和junit依赖 < dependencies> < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> < dependency> < groupId> </ groupId> < artifactId> </ artifactId> < version> </ version> </ dependency> </ dependencies> 在resources目录里创建log4j.properties文件 log4j.rootLogger = ERROR, stdout, logfile
log4j.appender.stdout = org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout = org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern = %d %p [ %c] - %m%n
log4j.appender.logfile = org.apache.log4j.FileAppender
log4j.appender.logfile.File = target/sortstudent.log
log4j.appender.logfile.layout = org.apache.log4j.PatternLayout
log4j.appender.logfile.layout.ConversionPattern = %d %p [ %c] - %m%n
package net. kox. mr ;
import org. apache. hadoop. io. WritableComparable ;
import java. io. DataInput ;
import java. io. DataOutput ;
import java. io. IOException ;
public class Student implements WritableComparable < Student > {
private String name;
private String gender;
private int age;
private String phone;
private String major;
public String getName ( ) {
return name;
}
public void setName ( String name) {
this . name = name;
}
public String getGender ( ) {
return gender;
}
public void setGender ( String gender) {
this . gender = gender;
}
public int getAge ( ) {
return age;
}
public void setAge ( int age) {
this . age = age;
}
public String getPhone ( ) {
return phone;
}
public void setPhone ( String phone) {
this . phone = phone;
}
public String getMajor ( ) {
return major;
}
public void setMajor ( String major) {
this . major = major;
}
@Override
public String toString ( ) {
return "Student{" +
"name='" + name + '\'' +
", gender='" + gender + '\'' +
", age=" + age +
", phone='" + phone + '\'' +
", major='" + major + '\'' +
'}' ;
}
public int compareTo ( Student o) {
return o. getAge ( ) - this . getAge ( ) ;
}
public void write ( DataOutput out) throws IOException {
out. writeUTF ( name) ;
out. writeUTF ( gender) ;
out. writeInt ( age) ;
out. writeUTF ( phone) ;
out. writeUTF ( major) ;
}
public void readFields ( DataInput in) throws IOException {
name = in. readUTF ( ) ;
gender = in. readUTF ( ) ;
age = in. readInt ( ) ;
phone = in. readUTF ( ) ;
major = in. readUTF ( ) ;
}
}
在net.kox.mr里创建StudentMapper类 package net. kox. mr ;
import org. apache. hadoop. io. LongWritable ;
import org. apache. hadoop. io. NullWritable ;
import org. apache. hadoop. io. Text ;
import org. apache. hadoop. mapreduce. Mapper ;
import java. io. IOException ;
public class StudentMapper extends Mapper < LongWritable , Text , Student , NullWritable > {
@Override
protected void map ( LongWritable key, Text value, Context context)
throws IOException , InterruptedException {
String line = value. toString ( ) ;
String [ ] fields = line. split ( " " ) ;
String name = fields[ 0 ] ;
String gender = fields[ 1 ] ;
int age = Integer . parseInt ( fields[ 2 ] ) ;
String phone = fields[ 3 ] ;
String major = fields[ 4 ] ;
Student student = new Student ( ) ;
student. setName ( name) ;
student. setGender ( gender) ;
student. setAge ( age) ;
student. setPhone ( phone) ;
student. setMajor ( major) ;
context. write ( student, NullWritable . get ( ) ) ;
}
}
package net. kox. mr ;
import org. apache. hadoop. io. NullWritable ;
import org. apache. hadoop. io. Text ;
import org. apache. hadoop. mapreduce. Reducer ;
import java. io. IOException ;
public class StudentReducer extends Reducer < Student , NullWritable , Text , NullWritable > {
@Override
protected void reduce ( Student key, Iterable < NullWritable > , Context context)
throws IOException , InterruptedException {
Student student = key;
String studentInfo = student. getName ( ) + "\t"
+ student. getGender ( ) + "\t"
+ student. getAge ( ) + "\t"
+ student. getPhone ( ) + "\t"
+ student. getMajor ( ) ;
context. write ( new Text ( studentInfo) , NullWritable . get ( ) ) ;
}
}
在net.kox.mr包里创建StudentDriver类 package net. kox. mr ;
import org. apache. hadoop. conf. Configuration ;
import org. apache. hadoop. fs. FSDataInputStream ;
import org. apache. hadoop. fs. FileStatus ;
import org. apache. hadoop. fs. FileSystem ;
import org. apache. hadoop. fs. Path ;
import org. apache. hadoop. io. IOUtils ;
import org. apache. hadoop. io. NullWritable ;
import org. apache. hadoop. io. Text ;
import org. apache. hadoop. mapreduce. Job ;
import org. apache. hadoop. mapreduce. lib. input. FileInputFormat ;
import org. apache. hadoop. mapreduce. lib. output. FileOutputFormat ;
import java. net. URI ;
public class StudentDriver {
public static void main ( String [ ] args) throws Exception {
Configuration conf = new Configuration ( ) ;
conf. set ( "dfs.client.use.datanode.hostname" , "true" ) ;
Job job = Job . getInstance ( conf) ;
job. setJarByClass ( StudentDriver . class ) ;
job. setMapperClass ( StudentMapper . class ) ;
job. setMapOutputKeyClass ( Student . class ) ;
job. setMapOutputValueClass ( NullWritable . class ) ;
job. setReducerClass ( StudentReducer . class ) ;
job. setOutputKeyClass ( Student . class ) ;
job. setOutputValueClass ( NullWritable . class ) ;
String uri = "hdfs://master:9000" ;
Path inputPath = new Path ( uri + "/sortstudent/input" ) ;
Path outputPath = new Path ( uri + "/sortstudent/output" ) ;
FileSystem fs = FileSystem . get ( new URI ( uri) , conf) ;
fs. delete ( outputPath, true ) ;
FileInputFormat . addInputPath ( job, inputPath) ;
FileOutputFormat . setOutputPath ( job, outputPath) ;
job. waitForCompletion ( true ) ;
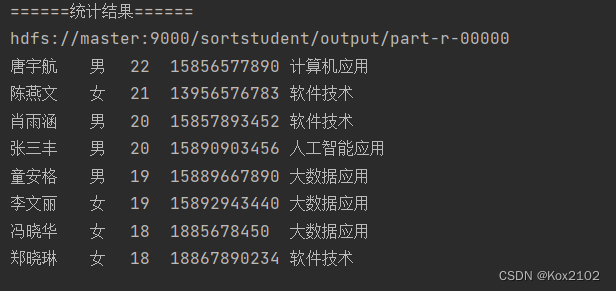
System . out. println ( "======统计结果======" ) ;
FileStatus [ ] fileStatuses = fs. listStatus ( outputPath) ;
for ( int i = 1 ; i < fileStatuses. length; i++ ) {
System . out. println ( fileStatuses[ i] . getPath ( ) ) ;
FSDataInputStream in = fs. open ( fileStatuses[ i] . getPath ( ) ) ;
IOUtils . copyBytes ( in, System . out, 4096 , false ) ;
}
}
}
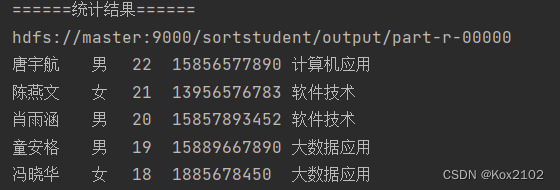
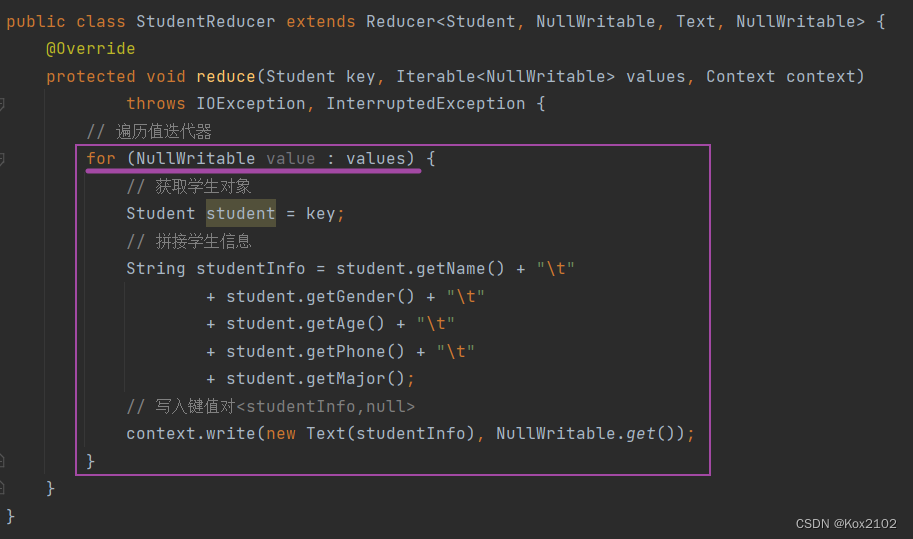
运行StudentDriver 类 确实学生信息按照年龄降序排列了,但是做了一件我们不需要的去重,少了3条记录 需要修改学生归并器类,遍历值迭代器,这样就不会去重了 再次运行StudentDriver 类