食用指南:本文在有C基础的情况下食用更佳
🔥这就不得不推荐此专栏了:C语言
♈️今日夜电波:水星—今泉愛夏
1:10 ━━━━━━️💟──────── 4:23
🔄 ◀️ ⏸ ▶️ ☰
💗关注👍点赞🙌收藏您的每一次鼓励都是对我莫大的支持😍
目录
❤️什么是堆?
堆的分类
💛堆的实现思路
使用什么实现?
怎么分辨父节点以及子节点?
总体实现思路
💜堆的实现
结构体以及接口的实现
💯堆的两种建堆方式(调整方法)究极无敌重要!!!
向上调整方法
向下调整方法
堆的构建
堆的销毁
堆的插入
⭕️堆的删除 (较重要)
取堆顶的数据
堆的数据个数
堆的判空
💚总体代码
❤️什么是堆?
堆是一种基于树结构的数据结构,它是一棵二叉树,具有以下两个特点:
1. 堆是一个完全二叉树,即除了最后一层,其他层都是满的,最后一层从左到右填满。
2. 堆中每个节点都满足堆的特性,即父节点的值要么等于或者大于(小于)子节点的值。
堆的分类
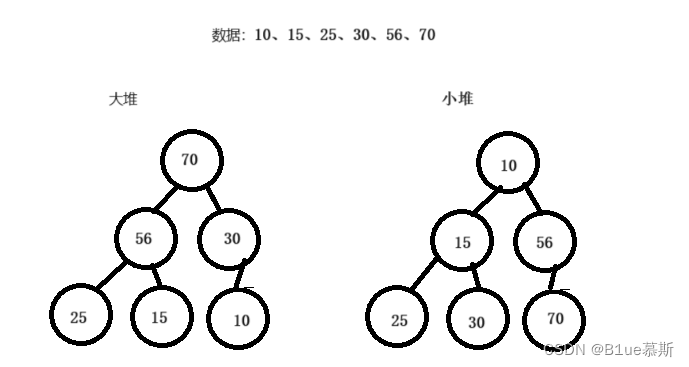
堆一般分为两类:大堆和小堆。大堆中,父节点的值大于或等于子节点的值,而小堆中,父节点的值小于或等于子节点的值。堆的主要应用是在排序和优先队列中。
以下分别为两个堆(左大堆,右小堆):
💛堆的实现思路
使用什么实现?
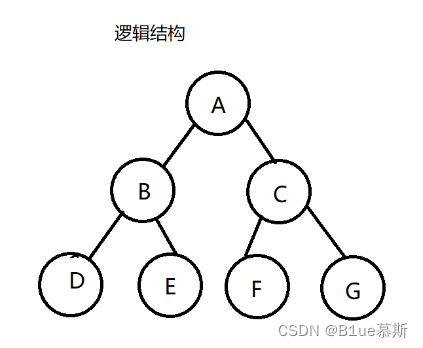
逻辑结构如上, 然而这仅仅是我们想像出来的而已,而实际上的堆的物理结构是一个完全二叉树,通常是用数组实现的。如下:
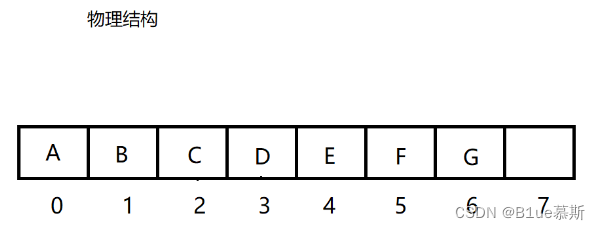
对此,这就要引申出一个问题?我们该如何分辨父节点以及子节点呢?如下:
怎么分辨父节点以及子节点?
通常我们的数组下标为“0”处即为根节点,也就是说我们一定知道一个父节点!并且我们也有计算公式一个来计算父节点以及子节点(先记住,后面实现有用!!!)也就是说我们也可以通过公式从每一个位置计算父节点以及子节点!如下:
总体实现思路
先建立一个结构体,由于堆的结构实际上是一颗完全二叉树,因此我们的结构跟二叉树一样即可!接着,想想我们的堆需要实现的功能?构建、销毁、插入、删除、取堆顶的数据、取数据个数、判空。(⊙o⊙)…基本的就这些吧哈~
接着按照 定义函数接口->实现各个函数功能->测试测试->收工(-_^) o(* ̄▽ ̄*)ブ
💜堆的实现
结构体以及接口的实现
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);
💯堆的两种建堆方式(调整方法)究极无敌重要!!!
在实现以上的接口之前,我们必须必须要知道堆的两种建堆方式!!!
并且仅仅通过调整两种建堆方式的<和>符号我们就可以轻易控制大小堆,具体看代码注释!
建堆有两种方式,分别是自底向上建堆以及自顶向下建堆。具体简介如下:
1. 自底向上建堆:自底向上建堆是指按照原始数组顺序依次插入元素,然后对每个插入的元素执行向上调整的操作,使得堆的性质保持不变。这种方法需要对每个元素都进行调整操作,时间复杂度为 O(nlogn)。
2. 自顶向下建堆:自顶向下建堆是指从堆顶开始,对每个节点执行向下调整操作,使得堆的性质保持不变。这种方法需要从根节点开始递归向下调整,时间复杂度为 O(n)。因此,自顶向下建堆的效率比自底向上建堆要高。
以上两种建堆方式 实际上是基于两种调整方法,接下来将详细介绍:
向上调整方法
堆的向上调整方法将新插入的节点从下往上逐层比较,如果当前节点比其父节点大(或小,根据是大根堆还是小根堆),则交换这两个节点。一直向上比较,直到不需要交换为止。这样可以保证堆的性质不变。
具体步骤如下:
1.将新插入的节点插入到堆的最后一位。
2.获取该节点的父节点的位置,比较该节点与其父节点的大小关系。
.如果该节点比其父节点大(或小,根据是大根堆还是小根堆),则交换这两个节点。
4.重复步骤2-3,直到不需要交换为止,堆的向上调整完成。
堆的向上调整的时间复杂度为O(logn),其中n为堆的大小。
一图让你了解~(以大堆为例)

实现如下:
void swap(HPDataType* s1, HPDataType* s2)
{
HPDataType temp = *s1;
*s1 = *s2;
*s2 = temp;
}
void Adjustup(HPDataType* a, int child)//向上调整
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])//建大堆,小堆则<
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}向下调整方法
堆的向下调整方法是指将某个节点的值下放至其子节点中,以维护堆的性质的过程。
假设当前节点为 i,其左子节点为 2i+1,右子节点为 2i+2,堆的大小为 n
则向下调整的步骤如下:
-
从当前节点 i 开始,将其与其左右子节点中较小或较大的节点比较,找出其中最小或最大的节点 j。
-
如果节点 i 小于等于(或大于等于,取决于是最小堆还是最大堆)节点 j,则说明它已经满足堆的性质,调整结束;否则,将节点 i 与节点 j 交换位置,并将当前节点 i 更新为 j。
-
重复执行步骤 1 和步骤 2,直到节点 i 没有子节点或已经满足堆的性质。
一图让你了解~(以大堆为例)

实现如下:
void swap(HPDataType* s1, HPDataType* s2)
{
HPDataType temp = *s1;
*s1 = *s2;
*s2 = temp;
}
void Adjustdown(HPDataType* a, int n, int parent)//向下调整
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child + 1] > a[child])//找出两个孩子中较大的那个,此为大堆,如果要实现小堆则 改 >
{
++child;
}
if (a[child] > a[parent])//此为大堆,如果要实现小堆则 改 >
{
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);
assert(a);
hp->_a = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (!hp->_a)
{
perror("malloc fail");
exit(-1);
}
hp->_capacity = hp->_size = n;
//将a中的元素全部转移到堆中
memcpy(hp->_a, a, sizeof(HPDataType) * n);
//建堆
for (int i = 1; i < n; i++)
{
Adjustup(hp->_a, i);//按向上调整,此建立大堆
}
}本文的构建方法是通过传递一个数组以及传递一个数组大小来构建的,里面包括了堆结构体的初始化操作,基本的建堆方式则是通过向上调整方法建堆。
堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp);
free(hp->_a);
hp->_a = NULL;
hp->_capacity = hp->_size = 0;
}就正常的销毁操作?大家应该都懂(确信) (o°ω°o)
堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if (hp->_capacity == hp->_size)//扩容
{
int newcapacity = hp->_capacity == 0 ? 4 : hp->_capacity * 2;
HPDataType* new = (HPDataType*)realloc(hp->_a, sizeof(HPDataType) * newcapacity);
if (!new)
{
perror("realloc fail");
exit(-1);
}
hp->_a = new;
hp->_capacity = newcapacity;
}
hp->_a[hp->_size++] = x;
Adjustup(hp->_a, hp->_size - 1);
}实现是对于堆的空间进行判断,不够则是扩容操作,当然也有初始化的意思,接着是通过向上调整的方式插入操作。
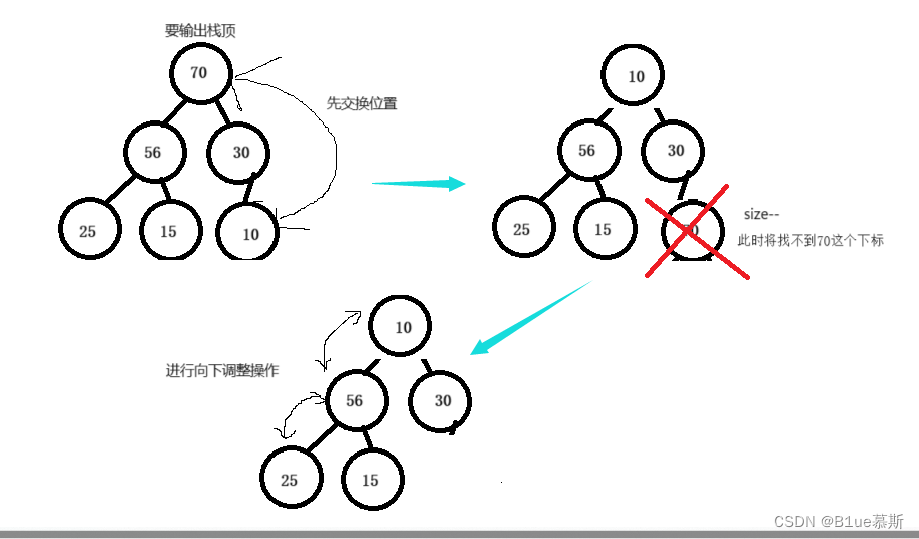
⭕️堆的删除 (较重要)
void HeapPop(Heap* hp)//先将最后一个数与堆顶交换,然后再让size--,再进行向下调整
{
assert(hp);
swap(&hp->_a[0], &hp->_a[hp->_size - 1]);
hp->_size--;
Adjustdown(hp->_a, hp->_size, 0);
}进行删除操作,我们当然是删除堆顶啦,这个删除操作先将最后一个数与堆顶交换,然后再让size--,再进行向下调整。
一图让你了解~
取堆顶的数据
HPDataType HeapTop(Heap* hp)//取堆顶
{
assert(hp);
assert(hp->_size > 0);
return hp->_a[0];
}
堆的数据个数
int HeapSize(Heap* hp)//堆大小
{
assert(hp);
return hp->_size;
}堆的判空
int HeapEmpty(Heap* hp)//判堆空
{
assert(hp);
return hp->_size==0;
}💚总体代码
pile.h
#pragma once
#define _CRT_SECURE_NO_WARNINGS 01
#include<stdio.h>
#include<stdlib.h>
#include<string.h>
#include<assert.h>
typedef int HPDataType;
typedef struct Heap
{
HPDataType* _a;
int _size;
int _capacity;
}Heap;
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n);
// 堆的销毁
void HeapDestory(Heap* hp);
// 堆的插入
void HeapPush(Heap* hp, HPDataType x);
// 堆的删除
void HeapPop(Heap* hp);
// 取堆顶的数据
HPDataType HeapTop(Heap* hp);
// 堆的数据个数
int HeapSize(Heap* hp);
// 堆的判空
int HeapEmpty(Heap* hp);pile.c
#include"pile.h"
void swap(HPDataType* s1, HPDataType* s2)
{
HPDataType temp = *s1;
*s1 = *s2;
*s2 = temp;
}
void Adjustup(HPDataType* a, int child)//向上调整
{
int parent = (child - 1) / 2;
while (child > 0)
{
if (a[child] > a[parent])//建大堆,小堆则<
{
swap(&a[child], &a[parent]);
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
void Adjustdown(HPDataType* a, int n, int parent)//向下调整
{
int child = parent * 2 + 1;
while (child < n)
{
if (child + 1 < n && a[child + 1] > a[child])//找出两个孩子中较大的那个,此为大堆,如果要实现小堆则 改 >
{
++child;
}
if (a[child] > a[parent])//此为大堆,如果要实现小堆则 改 >
{
swap(&a[child], &a[parent]);
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);
assert(a);
hp->_a = (HPDataType*)malloc(sizeof(HPDataType) * n);
if (!hp->_a)
{
perror("malloc fail");
exit(-1);
}
hp->_capacity = hp->_size = n;
//将a中的元素全部转移到堆中
memcpy(hp->_a, a, sizeof(HPDataType) * n);
//建堆
for (int i = 1; i < n; i++)
{
Adjustup(hp->_a, i);//按向上调整,此建立大堆
}
}
void HeapDestory(Heap* hp)
{
assert(hp);
free(hp->_a);
hp->_a = NULL;
hp->_capacity = hp->_size = 0;
}
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);
if (hp->_capacity == hp->_size)//扩容
{
int newcapacity = hp->_capacity == 0 ? 4 : hp->_capacity * 2;
HPDataType* new = (HPDataType*)realloc(hp->_a, sizeof(HPDataType) * newcapacity);
if (!new)
{
perror("realloc fail");
exit(-1);
}
hp->_a = new;
hp->_capacity = newcapacity;
}
hp->_a[hp->_size++] = x;
Adjustup(hp->_a, hp->_size - 1);
}
void HeapPop(Heap* hp)//先将最后一个数与堆顶交换,然后再让size--,再进行向下调整
{
assert(hp);
swap(&hp->_a[0], &hp->_a[hp->_size - 1]);
hp->_size--;
Adjustdown(hp->_a, hp->_size, 0);
}
HPDataType HeapTop(Heap* hp)//取堆顶
{
assert(hp);
assert(hp->_size > 0);
return hp->_a[0];
}
int HeapSize(Heap* hp)//堆大小
{
assert(hp);
return hp->_size;
}
int HeapEmpty(Heap* hp)//判堆空
{
assert(hp);
return hp->_size==0;
}test.c
#include"pile.h"
void test()
{
Heap hp;
int arr[] = { 1,6,2,3,4,7,5 };
HeapCreate(&hp, arr, sizeof(arr) / sizeof(arr[0]));
//HeapPush(&hp, 10);
printf("%d\n", HeapSize(&hp));
while (!HeapEmpty(&hp))
{
printf("%d %d \n", HeapTop(&hp), HeapSize(&hp));
HeapPop(&hp);
}
printf("%d\n", HeapSize(&hp));
HeapDestory(&hp);
HeapSort(arr, sizeof(arr) / sizeof(arr[0]));
printf("\n");
}
int main()
{
test();
return 0;
}测试结果:

感谢你耐心的看到这里ღ( ´・ᴗ・` )比心,如有哪里有错误请踢一脚作者o(╥﹏╥)o!

给个三连再走嘛~