当前,“百模大战”带来了算力需求的爆发,AI芯片产业也迎来巨大机遇,“创新架构+开源生态”正在激发多元AI算力产品百花齐放。面对新的产业机会,AI算力产业链亟需通过上下游协作共同把握机遇。
近日,浪潮信息AI&HPC产品线高级产品经理Stephen Zhang在开放计算中国峰会就AIGC时代的算力需求趋势与开放加速计算发展之道进行了洞察分享,他指出,开放加速计算生态协作将有效赋能多元的AI算力产品创新发展,为应对AIGC时代的算力挑战提供有益的解决之道。
以下为演讲要点:
- 大模型带来对AI计算性能、互连带宽、可扩展性的爆发式需求;
- 开放加速计算技术为大规模深度神经网络训练而生;
- 应用导向的算力基础设施架构设计以及算力和算法的协同设计,能够实现更高效的大模型训练;
- 开放加速计算在性能、扩展性、节能、生态兼容层面积累了丰硕成果;
以下为演讲原文:
大模型时代的算力需求及趋势
自ChatGPT发布以来,大家可以明显地感受到全社会对于生成式人工智能技术的广泛关注,ChatGPT出圈之后带来了更多参与者,模型的数量和模型参数量不断激增。据不完全统计,我们国家的大模型数量已经超过110个,这就带来了对于AI算力需求的剧增。
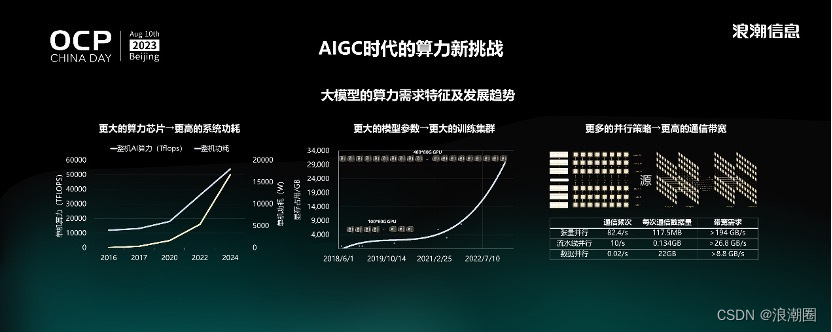
针对大模型发展带来的严峻算力挑战,我们进行了大量的需求分析和趋势判断。从AI服务器算力及功耗随时间变化的趋势来看,要解决大模型的算力短缺问题,最直接的方式是提高单机的算力。从2016年到现在,AI服务器单机算力增长近100倍,功耗从4千瓦增长到12千瓦,下一代AI服务器的功耗继续增长到18千瓦乃至20千瓦以上。AI服务器的系统架构供电、散热方式,以及数据中心基础设施建设模式,将难以满足未来高功耗AI服务器的部署需求。
其次,大模型参数量增长对GPU数量的需求也随之增加,需要更大的显存容量承载。2021年,一个千亿规模的大模型需要3,000 GB显存容量空间承载,换算过来需要将近40张80G的GPU才能放得下这个模型,包括权重参数、梯度数据、优化值数据和激活值数据。今天,很多大模型的参数量已经超过了万亿规模,显存容量将会达到30,000GB,需要将近400块80G显存的GPU才能承载,这意味着需要更大规模的算力平台才能进行如此规模大模型的训练。
更大规模的平台会带来另外一个问题,即卡与卡之间、不同的节点之间的更多通信,大模型的训练需要融合多种并行策略,对卡间P2P互连带宽以及跨节点互联带宽提出了更高的要求。
以2457亿参数的“源1.0”大模型训练的工程实践为例,“源1.0”训练共有1800亿Token,显存容量需求7.4TB,训练过程中融合了张量并行、流水行并行、数据并行三种策略。单节点张量并行通信频次达到每秒82.4次,节点内通信带宽最低需求达到194GB/s。计算节点内会开展流水线并行,跨节点通信带宽达到26.8GB/s,至少需要300Gbps通信带宽才能满足流水线并行训练的带宽需求。在训练“源1.0”过程中,实际用到两张200Gbps网卡进行跨节点通信,数据并行通信频次低但数据量大,带宽需求至少要达到8.8GB/s,单机400Gbps的带宽可以满足。
随着模型参数量进一步增加以及GPU算力的成倍增加,未来需要更高的互连带宽才能满足更大规模模型的训练需求。
开放加速计算 为超大规模深度神经网络而生
面向AIGC大模型训练的计算系统需要具备三个主要特征,一是大算力,二是高互联,三是强扩展,传统的PCIe CEM形态的加速卡很难满足三个特征需求,因此越来越多的芯片厂商都开发了非PCIe形态的加速卡。
开放计算组织OCP在2019年发布了专门面向大模型训练的加速计算系统架构,核心是UBB和OAM标准,特点是大算力。Mezz扣卡形态的加速器具备更高的散热和互联能力,可以承载具有更高算力的芯片。同时,它有非常强的跨节点扩展能力,可以很轻易地扩展到千卡、万卡级的平台,支撑大模型的训练。这个架构是天然适用于超大规模深度神经网络训练的计算架构。

但是,在OAM产业落地过程中,很多厂商所开发的加速卡依然存在硬件接口不统一、互连协议不统一,同时软件生态互不兼容,带来了新型AI加速卡系统适配周期长、定制投入成本高的落地难题,导致算力供给和算力需求之间的剪刀差不断加大,行业亟需更加开放的算力平台,以及更加多元的算力支撑大模型的训练。
对此,浪潮信息开展了大量工作,包括技术上的预研和对产业生态的贡献。2019年开始,浪潮信息牵头主导了OAM标准的制定,发布了首款开放加速基板UBB,同时开发了全球首款开放加速参考系统MX1,并协同业界领先的芯片厂商一起完成了OAM形态加速卡的适配,证明了这条技术路线的可行性。为了推动符合OAM开放加速规范的系统产业化落地,浪潮信息开发了第一款“ALL IN ONE” OAM服务器产品,把CPU和OAM加速卡集成到一台19英寸机箱中,实现数据中心级的快速部署,并在众多客户的智算中心落地应用。
此后,OAM 芯片的算力和功耗在不断提升,同时数据中心对于绿色节能的要求也越来越高。对此,我们开发了第一款液冷OAM服务器,可以实现8颗OAM加速器和两颗高功耗的CPU的液冷散热,整个液冷散热覆盖率超过90%,基于这款产品构建的液冷OAM智算中心解决方案,千卡平台稳定运行状态下PUE值小于1.1。而浪潮信息刚刚发布的新一代的OAM服务器NF5698G7,基于全PCIe Gen5链路,H2D互联能力提升4倍,为新一代OAM研发提供了更加先进的部署平台。
通过平台架构设计和算力算法协同设计解决能耗问题
仅仅提供算力平台是不够的,目前数据中心面临着巨大的能耗挑战,尤其是面向大模型训练的AI服务器,单机功耗轻易超过6-7千瓦。
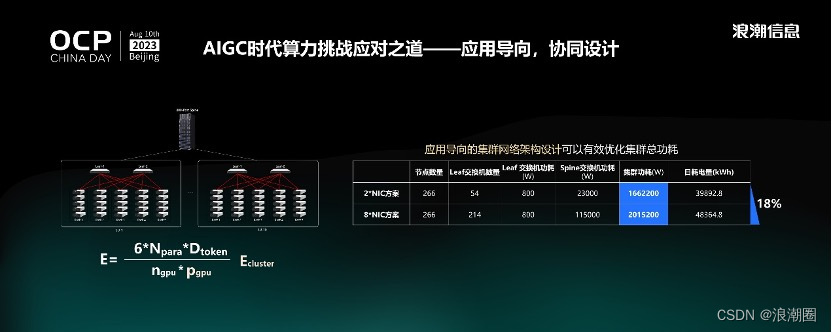
一个公式可以快速计算训练一个大模型所需要的整体耗电量(E):分子用6倍模型参数量和训练过程中所用到的Token数量表征大模型训练所需要的算力当量,分母用加速卡的数量还有单张加速卡的算力性能表征智算基础设施所能够提供的整体算力性能,二者相除的结果代表的是训练大模型所需要的时间,乘以Ecluster指标(大模型训练平台每日耗电量)即可得到整体耗电量。那么,在选定模型并且有确定卡数和规模的情况下,只有通过优化单卡算力值,或者降低单个平台的耗电量,才能优化大模型训练所需的整体耗电量。
针对这两个参数的优化,我们做了进一步研究。通过两张表格了呈现不同大模型训练平台网络架构设计下,平台功耗和相应的大模型训练整体功耗的对比。以单机2张网卡(NIC)组网方案和单机8张网卡(NIC)组网方案为例,虽然不同网卡数量带来的单机功耗影响并不显著,然而放到整个计算平台层面,网卡数量增加导致交换机数量增加,总功耗会有显著差异,8网卡方案总功耗可达2000多千瓦,2网卡方案只有1600多千瓦,2张网卡方案可以节省功耗18%。
因此,面向实际应用需求,通过精细化地计算大模型训练所需要的网络带宽,可以在不影响性能的前提下,显著地优化总功耗。“源”大模型训练过程当中,仅仅使用了两张200G的IB卡就完成2457亿参数模型的训练,这是我们发现的第一个优化训练平台总功耗的技术路径。
第二,提高单卡算力利用率以实现提效节能,也是非常重要的一个命题。经我们测试,采用算法和算力架构协同设计的方法,基于算力基础设施的技术特点,深度优化模型的参数结构和训练策略,可以用更短的时间完成同等规模模型的训练。以GPT-3模型的训练为例,模型训练时间可以从15天优化为12天,总耗电量节省达到33%。
以上两点可以说明,应用导向的架构设计,以及算力和算法的协同设计,能够实现更高效的大模型训练,最终加速节能降碳目标的实现。
绿色开放加速平台,赋力大模型高效释放算力
基于上述在开放计算、高效计算的技术、产品和方法的创新和研究,浪潮信息正在积极构建面向生成式AI的绿色开放加速智算平台。
去年协同合作伙伴发布的液冷开放加速智算中心解决方案,首先具有非常高的算力性能;其次,可以实现千芯级大规模扩展,支撑超千亿规模模型训练;同时,先进液冷技术使整个平台的PUE大幅优化。
同时,浪潮信息也在积极构建全栈开放加速智算能力,除了提供底层的AI计算平台,上层有AI资源平台,能够在资源管理层通过统一接口实现对于30余种多元算力芯片的统一的调度和管理。再往上是AI算法平台,提供开源的深度学习算法框架、大模型以及开放的数据集。在此之上是算力服务,包括算力、模型数据、交付、运维等多种服务模式。最上层是拥有4000多家合作伙伴的元脑生态,浪潮信息和生态合作伙伴共同开展开放加速计算方案的设计,并成功地推向产业落地。
基于开放加速规范的AI计算平台目前已经适配20多种业界主流的大模型,包括大家非常熟悉的GPT系列、LLaMA、Chat GLM、“源”,同时还支持多类扩散模型适配。
“助百芯,智千模” 加速多元算力落地
在AIGC技术和产业快速发展过程中,虽然业界已经制定了开放加速计算相关规范,但产业落地还存在一些问题。比如,开放计算系统定制化程度高,规范覆盖的领域不足,包括多元算力芯片的系统适配、管理和调度,以及深度学习环境的部署等等。
在OAM规范基础上,日前《开放加速规范AI服务器设计指南》发布,基于当前AIGC产业背景下客户的痛点,定义了开放加速服务器设计的原则,包括应用导向、多元开放、绿色高效、统筹设计。同时对服务器设计方法进行深化和细化,包括从节点层到平台层的多维协同设计方案。方案充分考量适配和研发过程中遇到的问题,进一步细化了节点到平台的设计参数,最终目的是提高多元算力芯片的开发和适配、部署效率。
由于面向AIGC训练的服务器具有非常多的高功耗芯片以及高互连带宽设计,稳定性问题严峻,需要更加全面的测试保证系统稳定性,减少断点的发生和对大模型训练效率的影响。因此,《指南》提供了从结构、散热、压力、稳定性、软件兼容性等全面系统的测试指导。
最后,多元算力要推向产业应用,最关键的是性能,包括芯片性能、互连性能、模型性能以及虚拟化性能。《指南》基于前期积累的Benchmark调优经验,提出了性能测评和调优标准及方法,帮助合作伙伴更快、更好地将他们最新的芯片产品推向应用落地,提高算力的可用性。最终目标是推动整个AI算力产业的创新和发展,协同产业链上下游合作伙伴推动整个开放加速生态,共同应对AIGC时代的算力挑战。
谢谢大家!