概述
Elasticsearch多文档聚合检索
详细
记得把这几点描述好咯:需求(要做什么) + 代码实现过程 + 项目文件结构截图 + 演示效果
应用场景
我们需要在五种不同的文档中检索数据。
比如 商品(goods)、案例(cases)、日记(diaries)、帖子(posts)、商家(shops)。
我们现在需要用关键字做全文检索,但是命中结果需要包含每一类数据。
goods->如果关键字命中,最多返回4条,不命中返回0条。
cases、diaries、posts、shops 4类数据都遵循上诉规则,就是每一类最多返回4条,没有关键词命中,则不返回。
1.分开检索每一类索引文档
为了赶工期,由于业务场景中,有单类索引检索的需求,所以一开始,我们重用了单索引的code,直接在接口层聚合5类数据。但是这样我们搜索服务与应用服务的开销无疑是增大了很多。我们来看看接口调用:
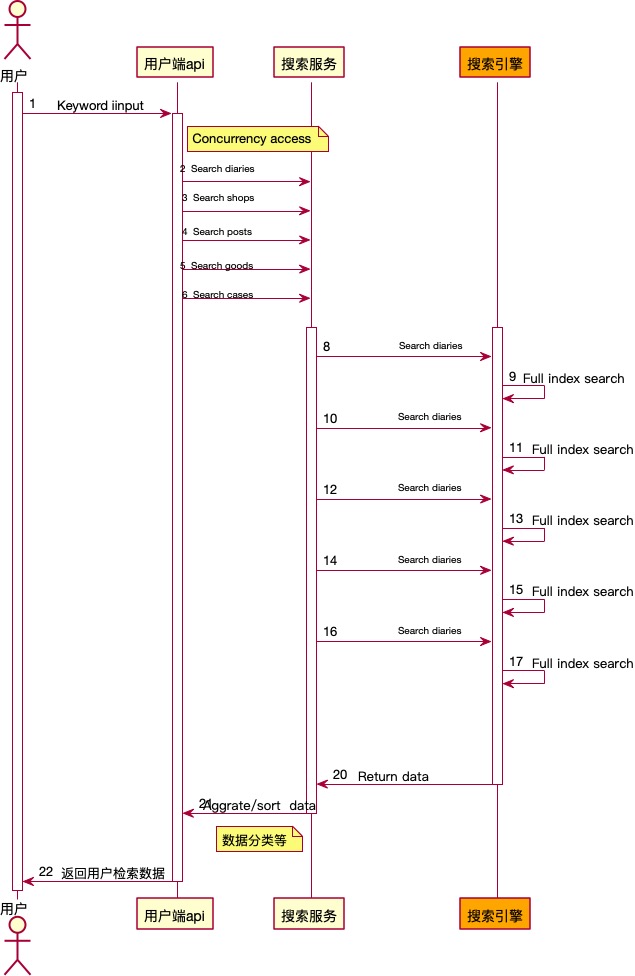
看到这儿,是不是有些难受。这么多调用,这么多并发,只想说一句,难受啊。是的,我心里也很难受,所以我们必须做出改变
2.一起来优化优化吧
不应该访问这么多服务,我们知道ES是可以一次性检索多类文档。我们当然希望,一次让ES返回我们所有的检索数据,那当然是最好的。我们来看看简化后的流程:

哟西,好像简洁了很多
3.把任务一次性交给Elasticsearch
优化之后的请求,少了服务的多次调用,少了并发的开销,我们把所有大部分任务一次性交给了SE(search engine),通过SE的计算,我们只需要一次调用服务,就可以拿到想要的所有数据,进行数据的分类封装,就可以返回给客户端使用了。那么这个过程又发生了哪些变化呢?在coding过程中,用到了哪些知识呢?下面我们一起来code share吧。
4.通过聚合函数平均返回值
要点:
terms aggregation — Bucket aggregation
topHints aggregation — Metrics aggregation
terms aggregation是Elasticsearch的Bucket aggregation,就是聚合桶;topHints aggregation 是Elasticsearch Metrics aggregation ,指标聚合。
terms aggregation — 提供根据某个字段进行装桶,可以认为是根据指定key进行分组。桶聚合的特点,只能返回桶的数据。比如:根据”_index”分组,那我们聚合桶就只有_index的值,而不能拿到命中的数据。
topHints aggregation — 返回排序靠前的数据,值得注意的是,支持返回最大的size 是 200。指标聚合,会根据桶内的数据进行指标计算。topHint 可以让我们拿到命中的数据。
说明:在这里介绍下metrics aggregation 、Bucket Aggregation的区别。metrics Aggregation 是对聚合数据的计算。Bucket Aggregation 用于对数据进行分组。往往我们在业务实现中,DSL中是需要有多种类型的aggregation的。
根据topHints aggregation 的特点,我们利用这样的方法检索,每类数据返回结果是不能超过200条的
5.code share
核心代码:
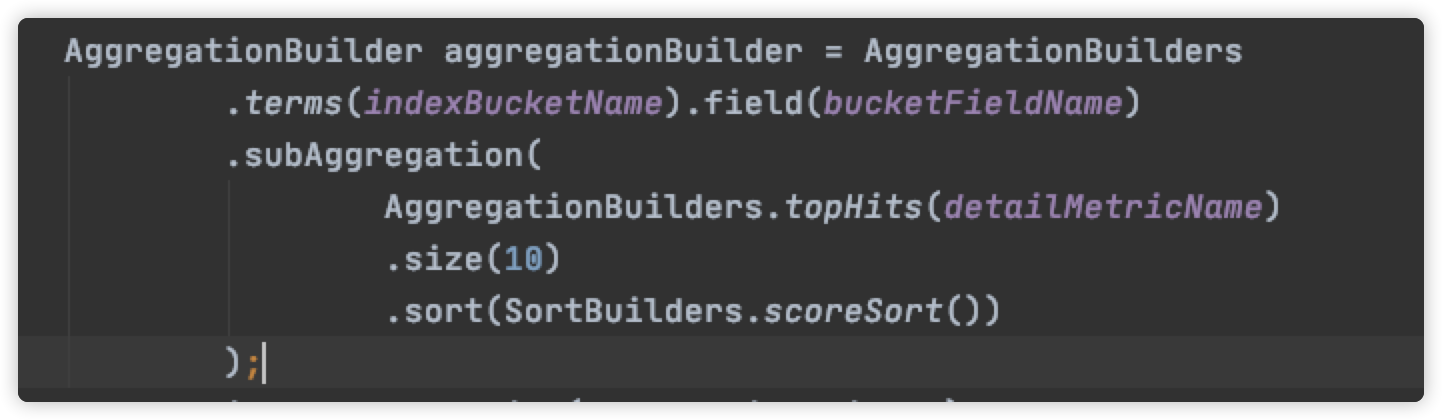
**aggregationBuilder 语义说明:
1.创建名称为 “index-group”的terms bucket
2.然后在每个terms bucket中创建名称为”details”的 topHints aggregation的子聚合。
3.子聚合中根据”_score”(命中分数),进行排序。
项目结构补充