langchain2之模型输入输出
- langchain
- 1.概念
- 2.主要模块
- 模型输入/输出 (Model I/O)
- 数据连接 (Data connection)
- 链式组装 (Chains)
- 代理 (Agents)
- 内存 (Memory)
- 回调 (Callbacks)
- 3.模型输入/输出 (Model I/O)
- 提示
- 提示模板
- 示例选择器
- 模型
- LLMs
- ChatModels
- 输出解释器
langchain
1.概念
什么是LangChain?
源起:LangChain产生源于Harrison与领域内的一些人交谈,这些人正在构建复杂的LLM应用,他在开发方式
上看到了一些可以抽象的部分。一个应用可能需要多次提示LLM并解析其输出,因此需要编写大量的复制粘贴。
LangChain使这个开发过程更加简单。一经推出后,在社区被广泛采纳,不仅有众多用户,还有许多贡献者参
与开源工作。
还有大模型本身的问题,无法感知实时数据,无法和当前世界进行交互。
LangChain是一个用于开发大语言模型的框架。
主要特性:
\1. 数据感知:能够将语⾔模型与其他数据源进⾏连接。
\2. 代理性:允许语⾔模型与其环境进⾏交互。可以通过写⼯具的⽅式做各种事情,数据的写⼊更新。
主要价值:
1、组件化了需要开发LLM所需要的功能,提供了很多工具,方便使用。
2、有一些现成的可以完整特定功能的链,也可以理解为提高了工具方便使用。
2.主要模块
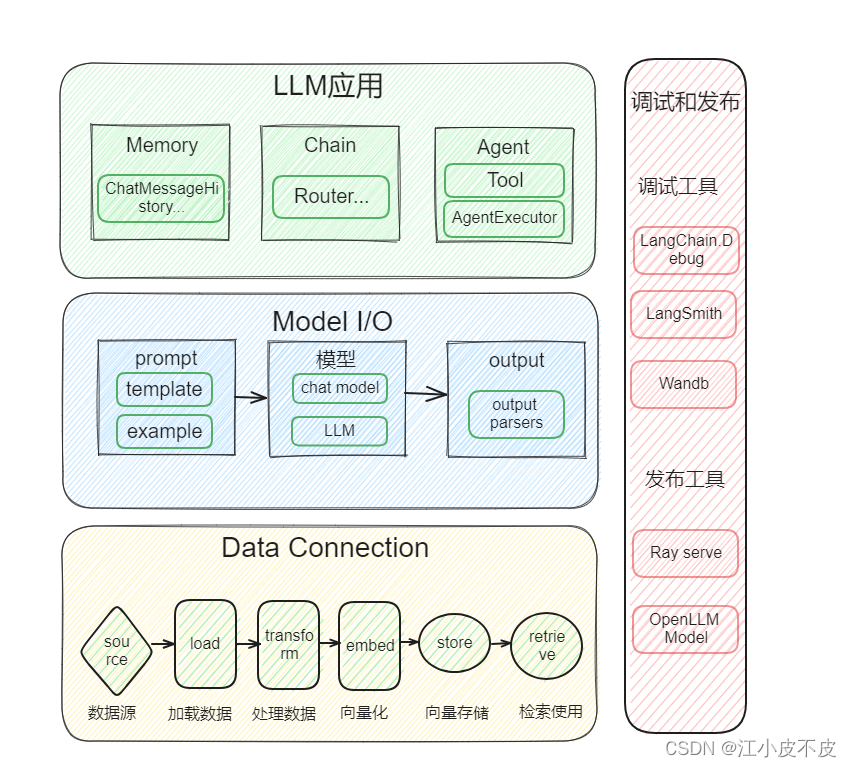
LangChain 为以下模块提供了标准、可扩展的接口和外部集成,按照复杂程度从低到高列出:
模型输入/输出 (Model I/O)
与语言模型进行接口交互
数据连接 (Data connection)
与特定于应用程序的数据进行接口交互
链式组装 (Chains)
构造调用序列
代理 (Agents)
根据高级指令让链式组装选择要使用的工具
内存 (Memory)
在链式组装的多次运行之间持久化应用程序状态
回调 (Callbacks)
记录和流式传输任何链式组装的中间步骤
3.模型输入/输出 (Model I/O)
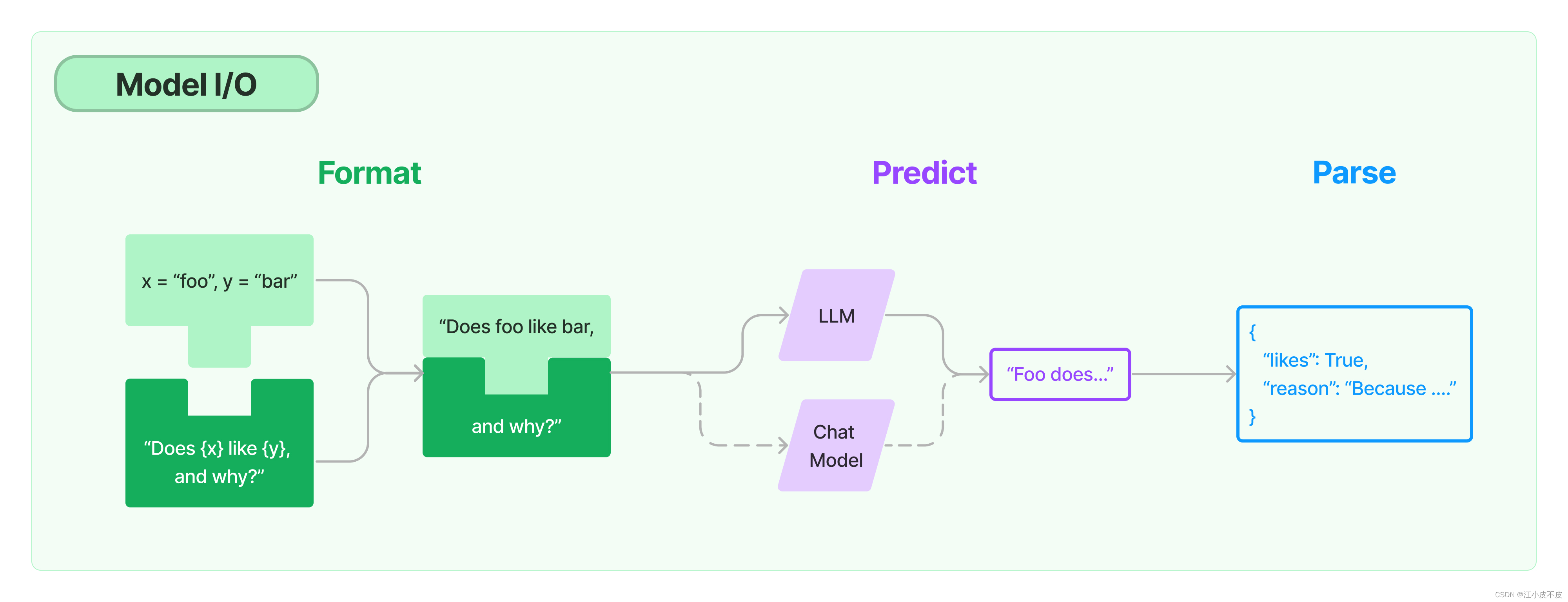
Model I/O = (Model + Prompt + Output Parsers)
-
Model:各种LLM,ChatGPT,ChatGLM,Claude,通义千问,vicuna
-
Prompts:模型输⼊的模板,可以动态替换内容,以及⼀些其他的⼯具模板
-
Output parsers:从模型输出中提取信息
提示
提示模板
prompt template
提示模板是指一种可复制的生成提示的方式。它包含一个文本字符串(“模板”),可以从最终用户那里接收一组参数并生成提示。
提示模板可以包含:
- 向语言模型提供指令,
- 一组少样本示例,以帮助语言模型生成更好的回复,
- 向语言模型提出问题。
from langchain import PromptTemplate
template = """\
你是一个新公司的命名咨询顾问.
为制作 {product} 的公司起一个好的名字?
"""
prompt = PromptTemplate.from_template(template)
prompt.format(product="五颜六色的袜子")
'你是一个新公司的命名咨询顾问.
为制作 五颜六色的袜子 的公司起一个好的名字?'
示例选择器
Example selectors
如果你有一些示例,可以需要去使用一些示例加到Prompt中。
from langchain.prompts import PromptTemplate
from langchain.prompts import FewShotPromptTemplate
from langchain.prompts.example_selector import LengthBasedExampleSelector
# 这里有很多关于创建反义词的示例。
examples = [
{"input": "happy", "output": "sad"},
{"input": "tall", "output": "short"},
{"input": "energetic", "output": "lethargic"},
{"input": "sunny", "output": "gloomy"},
{"input": "windy", "output": "calm"},
]
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="输入: {input}\n输出: {output}",
)
example_selector = LengthBasedExampleSelector(
# 这些是它可以选择的示例。
examples=examples,
# 这是用来格式化示例的PromptTemplate。
example_prompt=example_prompt,
# 这是格式化的示例应该的最大长度。
# 长度是通过下面的get_text_length函数来测量的。
max_length=25,
# 这是用来获取字符串长度的函数,用于确定要包含哪些示例。
# 它被注释掉了,因为如果没有指定,它会作为默认值提供。
# get_text_length: Callable[[str], int] = lambda x: len(re.split("\n| ", x))
)
dynamic_prompt = FewShotPromptTemplate(
# 我们提供一个ExampleSelector,而不是示例。
example_selector=example_selector,
example_prompt=example_prompt,
prefix="给出每个输入的反义词",
suffix="输入: {adjective}\n输出:",
input_variables=["adjective"],
)
print(dynamic_prompt.format(adjective="big"))
# 由于max_length设置了25.所以只有一个示例.
long_string = "big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else"
print(dynamic_prompt.format(adjective=long_string))
给出每个输入的反义词
输入: happy
输出: sad
输入: tall
输出: short
输入: energetic
输出: lethargic
输入: sunny
输出: gloomy
输入: windy
输出: calm
输入: big
输出:
给出每个输入的反义词
输入: happy
输出: sad
输入: big and huge and massive and large and gigantic and tall and much much much much much bigger than everything else
输出:
模型
LLMs
输入为文本字符串,输出为文本字符串的模型
from langchain.llms import OpenAI
llm = OpenAI()
# 输入为字符串,输出也为字符串
output = llm("给我讲个笑话")
print(output)
两个病人在医院病房里,一个说:“你知道为什么医院的灯都是绿色的吗?”另一个病人答道:“不知道,为什么?”第一个病人说:“因为绿色是医生的最爱!”
ChatModels
由语言模型支持,输入为聊天消息列表,输出为聊天消息的模型
from langchain.chat_models import ChatOpenAI
from langchain.schema import (
AIMessage,
HumanMessage,
SystemMessage
)
chat = ChatOpenAI()
chat([HumanMessage(content="把下面的英文翻译为中文: I love programming.")])
AIMessage(content='我喜欢编程。', additional_kwargs={}, example=False)
输出解释器
语言模型输出文本。但很多时候,您可能希望获得比仅文本更结构化的信息。这就是输出解析器的作用。
输出解析器是帮助结构化语言模型响应的类。一个输出解析器必须实现两个主要方法:
- “获取格式化指令”: 一个返回包含语言模型输出应如何格式化的字符串的方法。
- “解析”: 一个接受字符串(假设为语言模型的响应)并将其解析为某种结构的方法。
然后再加一个可选的方法:
- “带提示解析”: 一个接受字符串(假设为语言模型的响应)和提示(假设为生成此响应的提示)并将其解析为某种结构的方法。在需要从提示中获取信息以重试或修复输出的情况下,通常提供提示。
示例:列表解析器 comma_separated
当您想返回一个逗号分隔项的列表时,可以使用此输出解析器。
- 加载本地模型
from gpt_server import ChatGLMService
llm_model_path = "/mnt/code/LLM_Service/model/chatglm2-6b-32k/"
chatLLM = ChatGLMService()
chatLLM.load_model(model_name_or_path=llm_model_path)
- 构建列表解释器
from langchain.output_parsers import CommaSeparatedListOutputParser
from langchain.prompts import PromptTemplate, ChatPromptTemplate, HumanMessagePromptTemplate
output_parser = CommaSeparatedListOutputParser()
format_instructions = output_parser.get_format_instructions()
prompt = PromptTemplate(
template="List five {subject}.\n{format_instructions}",
input_variables=["subject"],
partial_variables={"format_instructions": format_instructions}
)
_input = prompt.format(subject="ice cream flavors")
output = chatLLM(_input)
print(output)
冰淇淋口味有很多种,这里列举五种常见的口味: 1. 巧克力味 2. 草莓味 3. 香草味 4. 芒果味 5. 巧克力、草莓和香草混合味
- 解析
output_parser.parse(output)
[‘冰淇淋口味有很多种,这里列举五种常见的口味:\n\n1. 巧克力味\n2. 草莓味\n3. 香草味\n4. 芒果味\n5. 巧克力、草莓和香草混合味’]