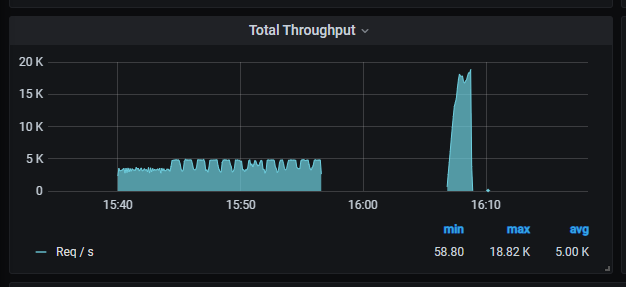
文章目录
- Fine-Grained Code Clone Detection with Block-Based Splitting of Abstract Syntax Tree
- 文章结构
- Intro
- Motivation
- Definition
- System
- Overview
- Processing
- Verify
- Experiment
- experimental settings
- RQ1
- RQ2
- RQ3
- RQ4
- RQ5
Fine-Grained Code Clone Detection with Block-Based Splitting of Abstract Syntax Tree
华科
Zoudeqing
Received 2023-02-16; accepted 2023-05-03
文章结构
- intro
- motivation
- definition
- system
- overview
- processing
- locate & filter
- verify
- experiment
- settings
- RQ1
- RQ2
- RQ3
- RQ4
- RQ5
- discussion
- related work
- conclusion
Intro
代码克隆是通过复制、粘贴和修改代码片段来重用代码的过程[30, 37]。由于克隆代码可以节省大量时间,开发人员在实现类似方法时往往倾向于克隆他人的代码,而不是从头开始编写代码。然而,如果程序员克隆了一些存在漏洞的代码,将导致漏洞的传播。换句话说,尽管代码克隆为软件开发带来了很多便利,但它也降低了软件的安全性,并增加了维护成本。由于存在这些问题,克隆检测成为了软件工程的一个活跃领域,并逐渐在该领域占据了重要位置。
随着克隆检测技术的发展,出现了许多克隆检测器。根据不同的代码表示方法,它们可以大致分为两类:基于标记的和基于中间表示的。它们在检测能力和可扩展性上存在差异。
- 基于token的工具[18, 27, 28, 32, 38, 41, 44]直接将代码片段转换为文本或标记序列,然后进行相似性比较。尽管速度很快,但大多数工具只能检测文本中的克隆。
- 研究人员提出了应用代码的中间表示来保持代码的语法和语义的一致性。例如,一些基于图的工具[16, 29, 31, 43, 53, 54]将程序详细信息转换为图,并应用图分析来检测复杂的代码克隆。然而,图分析通常耗时,难以用于大规模代码克隆检测。
因此,为了解决这个问题,其他方法[14, 24–26, 33, 48]提出了一种树表示方法,以保持代码的语法特征,并进行树匹配来检测克隆。尽管源代码的树分析速度比图分析快,但树的结构仍然复杂,克隆检测仍然需要很长时间。
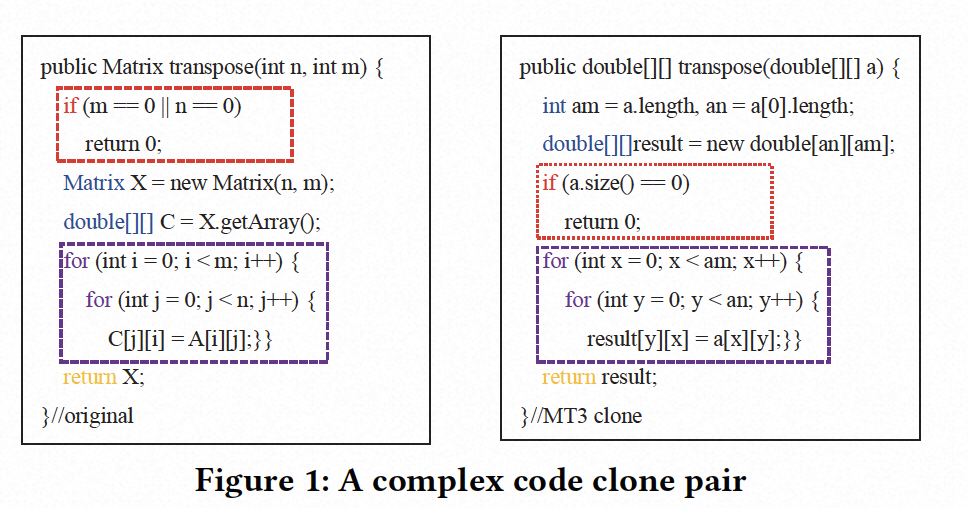
图2显示了图1中源代码的抽象语法树。我们可以看到,只有十行的简单方法可以转换成具有99个节点的复杂树。当一个方法的代码行数更多时,相应的语法树将更加复杂,这导致了树分析的高开销。此外,现有的克隆检测器不能定位克隆对的相似部分。如果具有大量代码行的克隆代码中的某些行存在安全问题,很难定位和修改。因此,我们需要设计一种基于树的克隆检测器,可以有效减少时间成本,并实现细粒度的克隆分析。
在本文中,我们实现了Tamer,一种能够进行细粒度代码克隆分析的高效有效的克隆检测器。Tamer是一种基于树的克隆检测器,考虑了源代码的语法,因此它可以高效检测具有高性能的克隆。具体而言,我们使用精心设计的规则将抽象语法树(AST)在block级别拆分为一系列子树,并重新组织相对简单的结构树以保留AST的整体特征。
在拆分原始树之后,我们在sub-tree级别而不是AST级别计算两个代码的相似性,这可以显著提高Tamer的效率。更重要的是,每个子树分别代表源代码的一部分。因此,通过计算两个代码之间相应子树的相似性,我们可以区分具有高相似性的子树对,然后我们可以定位源代码中的相似代码块。通过这种方式,我们可以进行细粒度的代码克隆分析。
为了检验Tamer的性能,我们在一个广泛使用的数据集big clone bench (BCB) [2]上进行了全面的实验。
- 关于检测性能,我们的实验结果显示,Tamer的性能优于其他十个最先进的克隆检测器,它们分别是CCAligner [44]、SourcererCC [39]、Siamese [36]、NIL [35]、Nicad [38]、LVMapper [49]、Deckard [25]、Yang2018 [51]、CCFinder [28]和CloneWorks [41]。
- 关于可扩展性,Tamer只需要大约11分40秒的时间来完成对1000万行代码的克隆扫描,比我们的大多数对比检测器更快。
- 关于细粒度分析,Tamer的输出不仅可以报告两个方法是否是克隆,还可以给出不同代码块之间的相似度。通过这种方式,我们可以知道克隆对中哪些代码块更相似,从而帮助研究人员进行后续的安全分析。
Motivation
为了说明为什么我们设计了Tamer以及我们的检测方法是如何实现的,我们使用了一个简单但清晰的例子。如图1所示,我们选择了BCB数据集[2]中的一个克隆对,原始方法和克隆方法在语法上相似,实现了矩阵赋值。后者修改了变量名并添加了一些语句。
NIL [35]是一个最先进的基于token的克隆检测器。在计算两种方法的相似性时,NIL提取源代码的标记序列并计算两个标记序列的最长公共序列(LCS),最后将LCS除以两种方法的最小数量以获得相似性。对于图2中的两种方法,我们发现它们的标记数分别为99和113。在计算两个标记序列的LCS后,我们发现它们的LCS的长度为30。我们可以得出这两种方法之间的相似性为30/99=0.3。然而,NIL的默认相似性阈值为0.7,这意味着只有相似性大于0.7的代码对被视为克隆对。因此,NIL将处理此代码对为非克隆对。
为了找到一种确定这两种方法为克隆对的方法,我们考虑提取它们的AST。图2显示了它们的简要AST,尽管变量名和源代码中的语句数量不同,但它们在结构上非常相似。此外,如果我们仅使用类型名称表示节点,那么两个AST将变得非常相似。此外,从图2可以看出,两个AST的For语句部分是相同的。因此,自然而然地认为,如果我们计算代码块的AST部分的相似性,我们可以获得较高的相似性。
为了说明我们如何划分AST的不同部分,我们在图2中使用了不同的颜色。AST有五个部分,用五种颜色标记。我们将函数声明、变量声明和返回值的三个部分合并为一个块,if和for部分合并为一个块,以便从一个方法中获得三个块,它们分别是if块、for块和rest块。我们首先通过深度优先遍历(DFS)获得节点类型序列,然后计算两个序列的LCS以获得类似NIL的相似性。表1显示了每个块的相似性。我们可以看到,For块的相似性为100%,If块为59%,其余块为53%。它们都超过了由NIL计算的相似性。即使我们将三个块的平均相似性作为最终相似性,我们也可以发现它为71%,高于70%的阈值。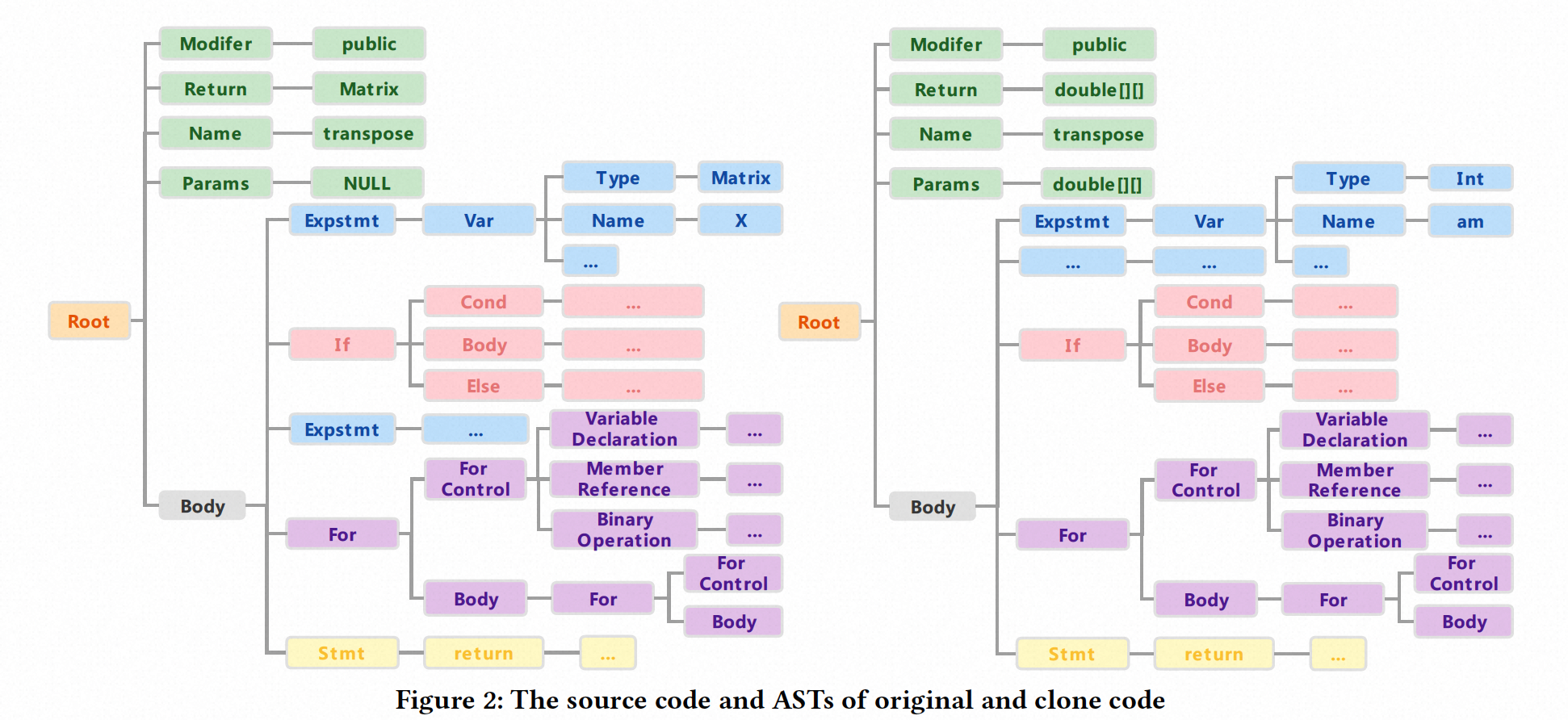
在实际应用中,我们还通过直接分析原始AST来计算相似性,图1中的代码对也可以报告为克隆对。然而,克隆检测技术需要既保证准确性又优化检测效率。当我们使用原始复杂的AST进行类似计算时,发现其计算时间远远高于基于标记的计算方法。因此,如果两个代码块之间的单次比较耗时,那么整个比较时间将很难估算。
由于现有的LCS算法大多具有O(N^2)复杂度,计算子树之间的LCS所需的时间远远少于计算两个大型AST之间的LCS所需的时间。为了更具说服力,我们对原始代码的三个块进行了实验。If块、For块和rest块的节点数分别为12、48和56。整个AST的节点数为116。因此,计算AST的LCS所需的计算次数为116 * 116 = 13456次。然而,计算三个块的LCS所需的计算次数为12 * 12 + 48 * 48 + 56 * 56 = 5584次。计算次数减少了近一半。随着代码规模的增加,这种改进将变得更加显著,对于工具的可扩展性将是一项惊人的改进。
基于以上研究,我们提出了一种可以大大提高克隆检测性能和可扩展性的方法。

Definition
一个代码片段是源代码中的连续部分。代码块指的是大括号内的代码片段。由于一个方法可以实现特定的功能,我们选择它作为我们的检测粒度。通常,根据它们的相似性,克隆可以分为以下四个类别 [39, 44]:
- 类型-1 克隆(文本相似性):这个类别中的代码克隆是完全相同的副本,除了一些空格、空行和注释。
- 类型-2 克隆(词法相似性):这个类别中的代码克隆是在变量名、变量类型或一些函数标识符方面有所不同的副本。
- 类型-3 克隆(语法相似性):这个类别中的代码克隆是经过更多修改的副本,其中一些语句已经被修改、删除或添加。
- 类型-4 克隆(语义相似性):这个类别中的代码克隆是在语法结构上有不同的副本,但实现了相同的功能。
至于类型-4的克隆,它们是语义克隆,很难被检测到。因此,类似于先前的研究 [35, 39, 44],我们主要关注检测前三种类型的克隆。
System
在本节中,我们将详细介绍 Tamer(即一种使用 N-gram 和 LCS 的基于树的代码克隆检测器)。Tamer 的总体框架如图 3 所示,可以分为三个阶段:处理、定位和过滤、验证。
Overview
- 处理:此阶段的目的是提取方法的 AST(抽象语法树)。我们使用深度优先遍历(DFS)来遍历 AST 并记录每个节点的类型名称以获取节点序列。然后,我们根据生成的节点序列创建倒排索引。
- 定位和过滤:此阶段的目的是使用倒排索引对所有方法对的候选克隆对进行初步筛选和过滤,为后续的验证阶段做准备。
- 验证:此阶段的目的是获取真正的克隆对。根据在定位和过滤阶段获得的候选克隆对,我们使用 LCS 进行相似性计算,以确定候选克隆对是否为真正的克隆。
这些阶段组成了 Tamer 的工作流程,用于检测代码克隆。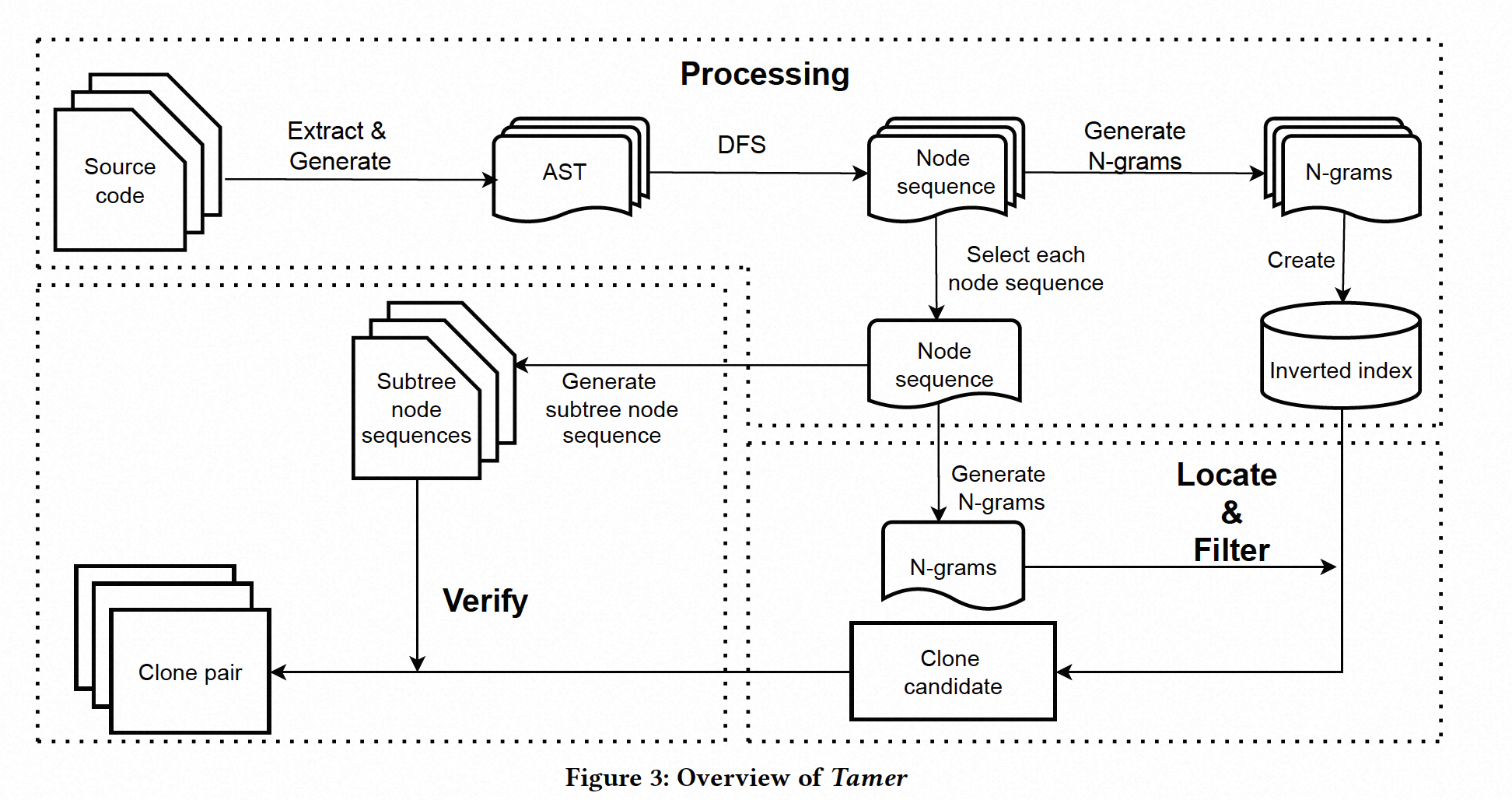
Processing
由于 Tamer 的目标是在检测 Type-3 克隆方面取得良好的性能,因此我们需要使用 AST,这是一种保留原始代码语法的中间表示。因此,代码处理的第一步是通过静态语法分析获取 AST。由于数据集的编程语言是 Java,我们使用 JavaParser [7] 来实现静态分析。
此外,AST 比源代码更复杂,因此如果保留完整的 AST,将会对检测器的空间造成巨大的开销。因此,我们考虑使用单个字符串来存储 AST 信息。我们使用深度优先遍历整个 AST 并记录节点的类型名称。具体来说,我们对整个 BCB 数据集进行统计分析,发现只有 70 种节点类型,因此我们可以将名称空间转换为存储 AST 信息。
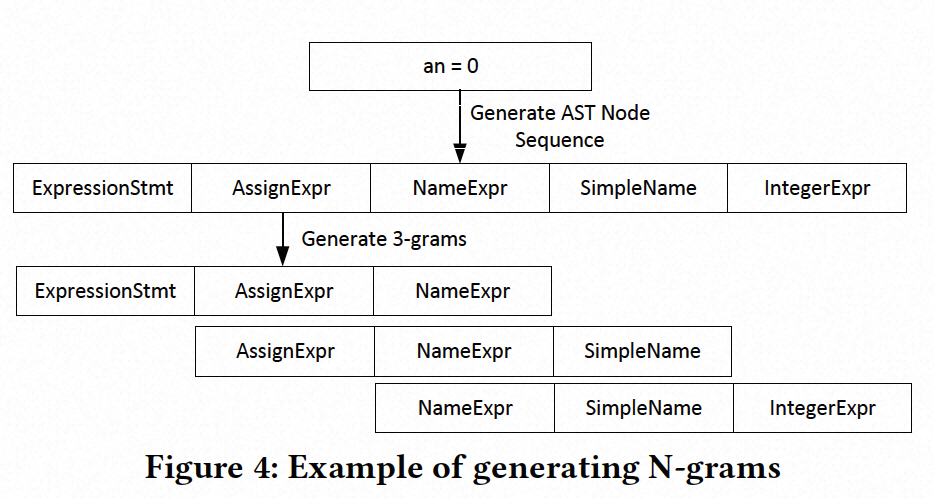
在获取每个方法的节点序列之后,我们可以在此基础上获得相应的 N-gram。N-gram 是一组连续节点,其数量为 N。图 4 显示了从节点序列获取 3-gram 的过程。我们遍历数据集中所有方法生成的 AST 节点序列,每个方法都会生成一系列 N-gram。接下来,Tamer 根据获取的 N-gram 创建倒排索引。倒排索引是一种快速信息检索工具,可以快速检索包含查询词的文档。这个想法源于我们需要根据给定的值查找一些记录的情况。在 Tamer 中,我们使用 HashMap 结构,其键是 N-gram 的哈希值,然后我们使用包含与 HashMap 值相同的 N-gram 的方法的 ID 作为值。因此,可以通过倒排索引快速找到包含相同 N-gram 的代码块。
当所有的 N-gram 存储在 HashMap 中时,就建立了数据集的倒排索引,可以快速计算任意两个方法之间共同的 N-gram 数量。
在处理阶段之后,Tamer 使用从处理阶段获得的倒排索引来执行定位操作。定位操作主要通过倒排索引获取目标代码块的候选克隆。其算法对应于算法 1 中的第 6-11 行。
首先,我们获取由 AST 节点序列生成的 N-gram。具有长度 M 的节点序列可以生成 M-N+1 个 N-gram。接下来,我们计算每个 N-gram 的哈希值,并使用哈希值作为查询对象在倒排索引中查询与之对应的所有方法。这些方法都具有相同的 N-gram,表明它们的 AST 节点序列具有部分相同的子序列。因此,我们将这些方法添加到目标方法的候选克隆中。
在处理阶段之后,Tamer 使用从处理阶段获得的倒排索引来执行定位操作。定位操作主要通过倒排索引获取目标代码块的候选克隆。其算法对应于算法 1 中的第 6-11 行。
首先,我们获取由 AST 节点序列生成的 N-gram。具有长度 M 的节点序列可以生成 M-N+1 个 N-gram。接下来,我们计算每个 N-gram 的哈希值,并使用哈希值作为查询对象在倒排索引中查询与之对应的所有方法。这些方法都具有相同的 N-gram,表明它们的 AST 节点序列具有部分相同的子序列。因此,我们将这些方法添加到目标方法的候选克隆中。
过滤。在过滤操作中,我们主要删除定位操作获得的候选克隆中那些不能成为克隆的候选克隆。这个算法对应于算法 1 中的第 12-21 行。需要减少克隆候选的数量,因为在验证阶段计算两个方法之间的节点序列相似性需要大量时间。因此,为了实现可扩展和快速的克隆检测,我们不需要检测具有少量共同 N-gram 的代码块对。
在这个阶段,我们考虑了一个小技巧来减少计算两个方法之间共同 N-gram 数量的时间成本。我们使用一个数组来存储目标方法与其他方法之间的共同 N-gram 数量。这样,我们只需要遍历目标方法的 N-gram 一次,就可以得到目标方法与其他所有方法之间的共同 N-gram 数量。
为了定量描述两个方法之间 N-gram 的相似度,我们使用下面定义的过滤得分(filter-score)。
Verify
在这个阶段,我们验证候选克隆对中的每个代码块对是否是真正的克隆。该算法的主要思想对应于算法1中的第22-30行。
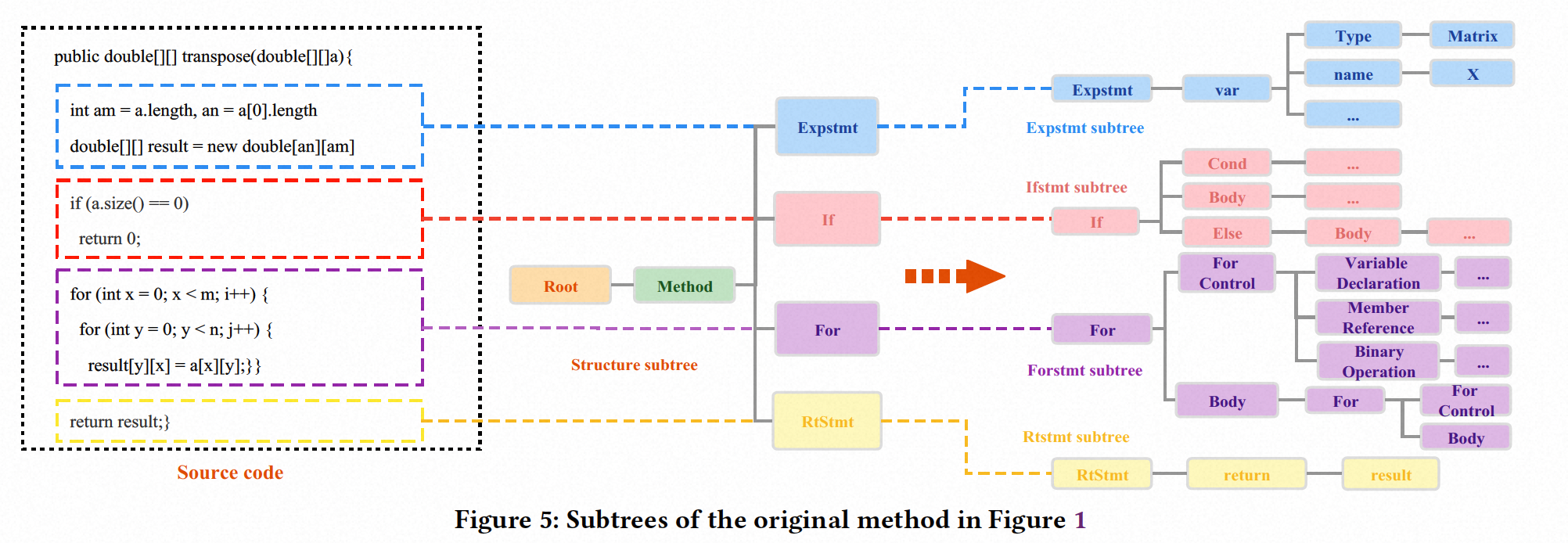
首先,我们需要获取每个代码块的子树节点序列。因为在处理阶段,我们已经获得了每个代码块的AST,所以我们可以直接通过一个经过精心设计的规则从中生成子树。基于在第2节中介绍的思想,我们主要根据它具有的不同类型的语句来拆分AST。我们对BCB数据集中的所有方法进行统计,并对源代码中不同类型语句的复杂性进行排序(即,Expressionstmt,Ifstmt)。每种语句类型的复杂性通过AST中相应节点的平均数量来计算。我们选择了八个最复杂的语句,它们分别是Forstmt、Whilestmt、Trystmt、Dostmt、ForEachstmt、Switchstmt、Synchronizedstmt和Ifstmt。
另外,如果我们只考虑语句子树,可能会失去方法的整体结构信息。因此,有必要生成方法的结构子树。总之,我们的拆分规则是:对于相对简单的语句,如变量声明和赋值,我们将它们保留在原始AST中。对于更复杂的语句,如if语句和for语句,我们将它们从原始AST树中分离出来形成一个子树。仅保留这些子树的根节点类型在原始AST树上。最后,原始AST将形成一个结构子树,而分离的语句块将形成一个语句树。通过这种方式,我们将原始的复杂AST拆分成了九个更简单的子树,假设它包含了上述提到的所有类型的语句。
AST的子树如图2所示,如图5所示。我们可以看到,一个简单的方法有四个不同颜色的块,这些块对应于结构树的一部分。这些块可以分别由一个子树表示。如图5所示,展示了源代码、块和子树之间的关系。最后,根据我们上面提到的规则,将复杂的AST拆分成了三个更简单的子树。Ifstmt子树表示源代码中的if块,Forstmt子树表示源代码中的for块,Structure子树记录了AST的结构信息。之后,我们使用DFS遍历子树并获取相应的节点序列。我们计算两个节点序列的LCS作为它们相似性的指标。为了定量描述相似度程度,我们使用下面定义的verify-score,其中𝑠1𝑖和𝑠2𝑖是两个子树节点序列,其节点长度分别为|𝑠1𝑖|和|𝑠2𝑖|。lcs(𝑠1𝑖, 𝑠2𝑖)是两个节点序列之间的LCS长度。我们使用|𝑠1𝑖| + |𝑠2𝑖| - lcs(𝑠1𝑖, 𝑠2𝑖)作为分母,这可以避免在两个节点序列的长度非常不同的情况下,subtree_score的计算不平衡,并且可以有效减少Tamer错误地将非克隆对判断为克隆对的情况。我们将九个subtree_score相加以获得verify_score。
Experiment
在这一节中,我们专注于回答以下五个研究问题(RQs):
• RQ1:Tamer在不同参数下的检测性能如何?
• RQ2:Tamer能否胜过其他最先进的克隆检测器?
• RQ3:Tamer是否可以应用于大型代码?
• RQ4:Tamer如何执行细粒度分析并定位代码克隆的具体位置?
• RQ5:拆分AST的优势是什么?
experimental settings
数据集。我们在一个广泛使用的数据集BCB上评估了Tamer[2]。BCB数据集中的每对方法的克隆类型都是由专家手动分配的。BCB数据集包含了超过8,000,000个已标记的克隆对。由于类型3和类型4之间的边界不明确,这两种克隆类型根据线级和令牌级代码归一化测量的相似度分数进一步分为四个子类,如下所示:1) 非常强的类型3(VST3),相似度在90-100%之间;2) 强类型3(ST3),相似度在70-90%之间;3) 中度类型3(MT3),相似度在50-70%之间;4) 弱类型3/类型4(WT3/T4),相似度在0-50%之间。正如前面所提到的,由于T4代码克隆是语义克隆,难以区分,我们忽略了它们,更关注其他类型的克隆。
5.1.2 实现。我们在一台标准服务器上运行所有实验,该服务器配备了128GB的RAM和16个CPU核心。对于Tamer的实现,我们主要使用Javaparser[7]完成静态分析,包括树提取、分析和拆分。
5.1.3 比较。我们将Tamer与十个现有的最先进的代码克隆检测器进行比较:
• CCAligner [44]:通过分析代码窗口和方法之间的编辑距离来进行代码克隆检测的流行工具。
• SourcererCC [39]:通过计算方法之间重叠令牌的数量来进行代码克隆检测的流行工具。
• Siamese [36]:通过将令牌序列转换为不同的表示形式来进行代码克隆检测的流行工具。
• NIL [35]:通过计算方法的令牌序列的最长公共子序列(LCS)来进行代码克隆检测的流行工具。
• NiCad [38]:通过使用TXL解析器计算方法之间的相似性来进行代码克隆检测的流行工具。
• LVMapper [49]:通过计算公共令牌数量和动态阈值来进行代码克隆检测的流行工具。
• Deckard [25]:一种基于树的代码克隆检测器,使用基于欧几里德空间中的数值向量的算法。
• Yang2018 [51]:一种基于树的代码克隆检测器,采用混合增量式克隆检测和实时散点图技术。
• CCFinder [28]:一种多语言令牌级别的大规模源代码克隆检测系统。
• CloneWorks [41]:一种使用修改的Jaccard相似度度量的快速灵活的大规模近似克隆检测工具。
5.1.4 评估指标。由于代码克隆检测是一个二元分类任务,我们采用广泛使用的指标来衡量Tamer的性能。我们的测量指标定义如下:
• 真正例(TP):表示一个或多个克隆对被预测为克隆代码。
• 真负例(TN):表示一个或多个非克隆对被预测为非克隆代码。
• 假正例(FP):表示一个或多个非克隆对被预测为克隆代码。
• 假负例(FN):表示一个或多个克隆对被预测为非克隆代码。
• 精确率=TP/(TP+FP):检测的正确率。
• 召回率=TP/(TP+FN):成功检测到的克隆对的百分比。
RQ1
Tamer需要三个参数:N的值,过滤阈值𝜃,和验证阈值𝛿。经过多次实验,我们发现𝜃对Tamer的影响不大。具体来说,我们进行了大量实验,并观察到那些无法达到𝜃的候选克隆对通常都不是真正的克隆。因此,𝜃的值只对可伸缩性产生轻微影响。具体而言,我们结合以前的研究(例如NIL [35] 和LVMapper [49])以及我们的实验结果,将𝜃设置为0.15。
然而,N的值需要谨慎选择,因为它对检测性能有很大影响。如果将N值设置为较小的值,召回率将很高,但系统执行时间将大幅增加。如果将N值设置为较大的值,虽然系统执行时间会减少,但召回率会降低。因此,为了选择最合适的N值,我们进行了一项实验,N的范围从10到18,并在𝜃=0.7时测量召回率和执行时间。图6显示了每个N值的结果。可以看出,当N<15时,随着N值的降低,执行时间显著增加,而当N>15时,执行时间趋于稳定。此外,当N>15时,召回率显著下降。因此,考虑到这两个因素的平衡,我们最终选择N=15作为最佳参数。
接下来,我们进行实验以选择验证阈值𝛿的最佳值。我们计算了从0.6到0.8的𝛿的召回率和精确率,步长为0.05。实验结果如图7所示。可以看出,当𝛿>0.65时,召回率开始显著下降,但精确率只有轻微变化。考虑到当𝛿=0.60时精确率不太好,我们最终选择𝛿=0.65作为最佳参数。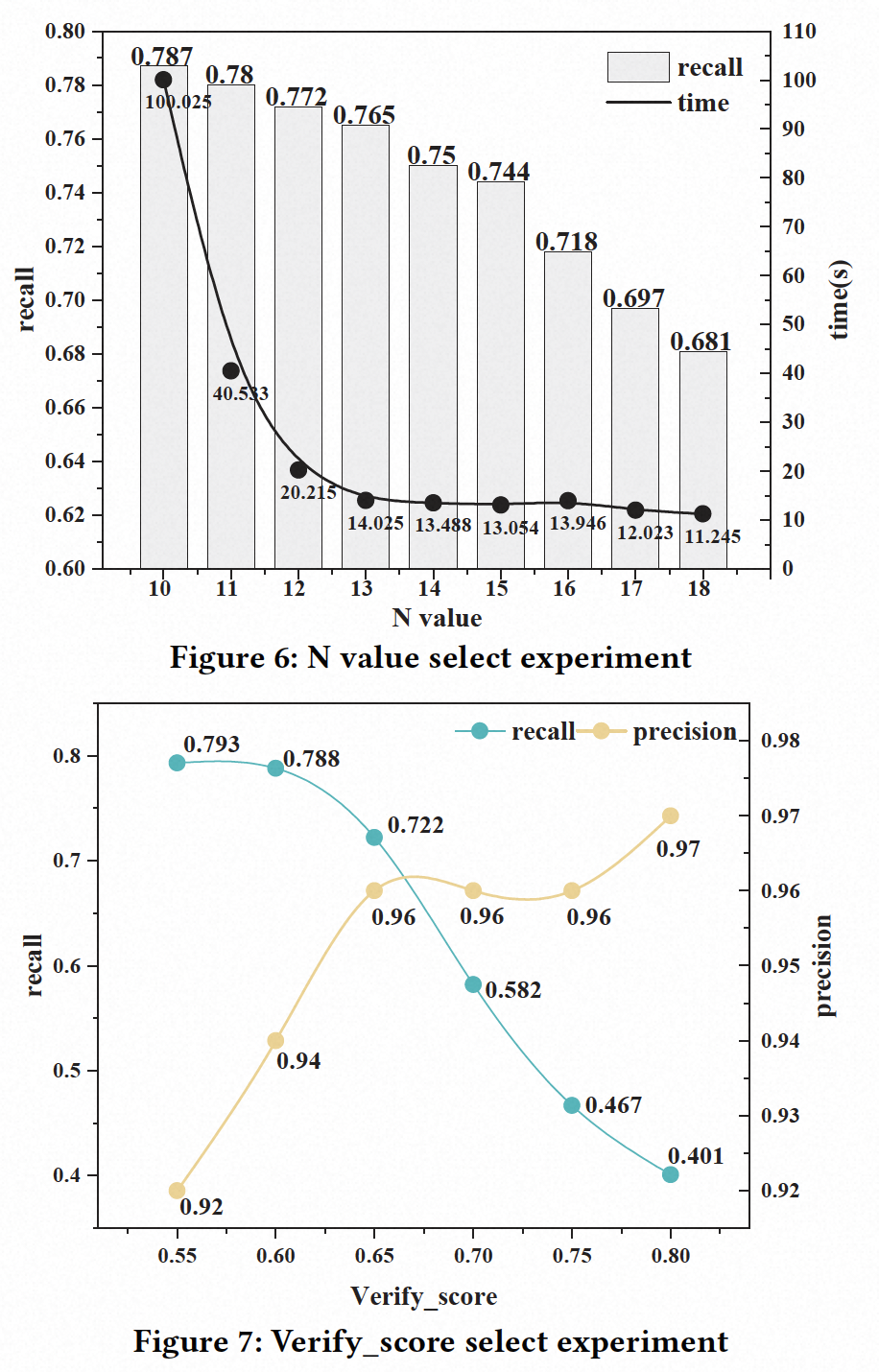
RQ2
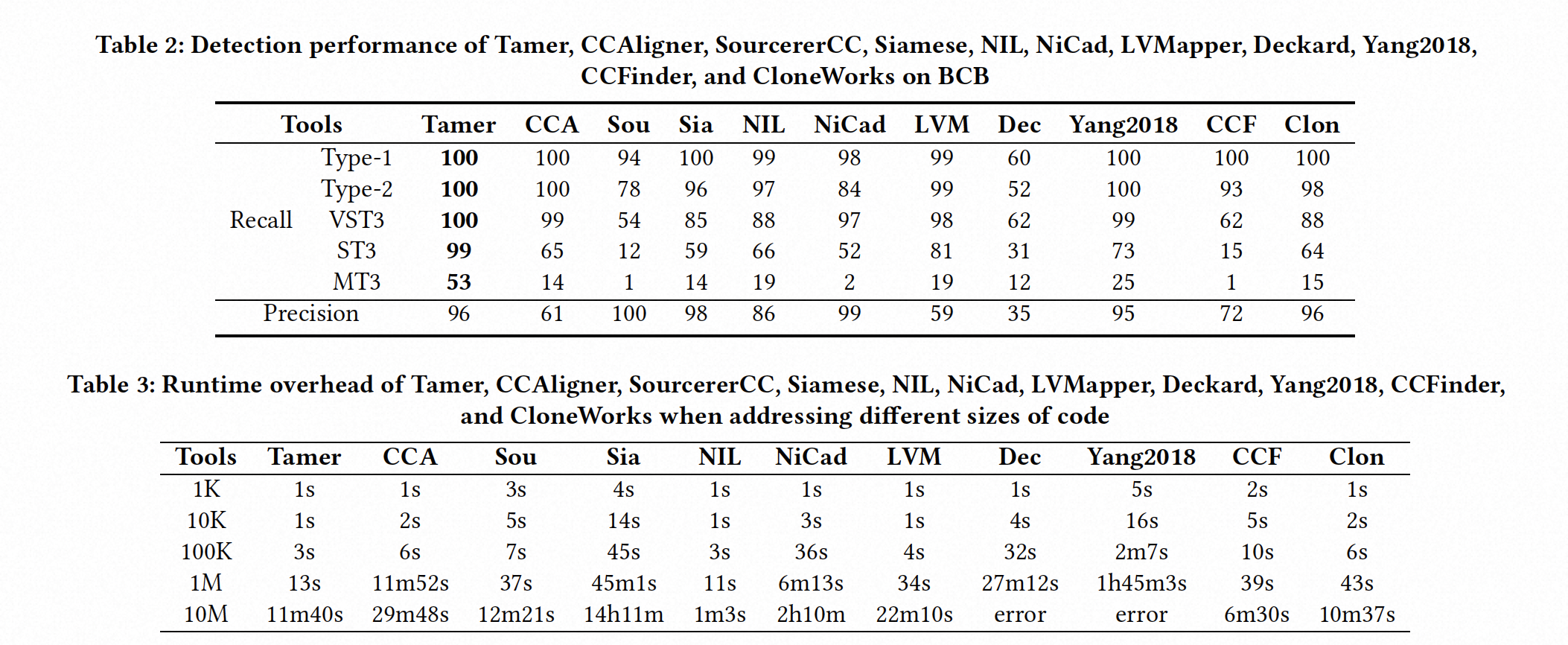
我们在RQ1中选择的参数下,在BCB数据集上测量了不同类型的克隆的召回率,并计算了与之前研究[39, 44, 49]相同的精确率。表2显示了在BCB数据集上测试的每个工具的召回率和精确率结果。我们可以看到,在所有类型的克隆中,Tamer的召回率最高。其中,ST3克隆的召回率超过了其余十个工具中召回率最高的LVMapper 17%,MT3克隆的召回率超过了其余十个工具中召回率最高的Yang2018 26%。实验结果表明,Tamer在克隆检测方面有显著改进。
在分析这一现象背后的原因时,我们发现八个基于标记的克隆检测工具很难检测Type-3克隆。原因在于Type-3克隆具有不同的词汇结构但相似的语法结构。然而,源代码的树表示可以保留其语法信息,因此基于树的检测器可以检测到Type-3克隆,这就是为什么Tamer与其他克隆检测工具相比具有如此高的召回率值的原因。此外,即使Deckard和Yang2018使用源代码的树表示执行克隆检测,并且确实击败了其他基于标记的方法,它们的召回率仍然低于Tamer。这是因为虽然这两种方法使用源代码的树表示,但它们只对AST进行了浅层分析,并最终使用整个AST计算相似性,算法并没有得到显著改进。然而,Tamer不仅使用AST,还提出了一种新的算法来对树进行更精细的代码克隆分析,因此对Type-3克隆更敏感,因此具有更高的召回率。
Tamer的精确率超过了CCAligner、NIL、LVMapper、Deckard、Yang2018和CCFinder,略低于SourcererCC、Siamese和NiCad。这是因为它们在提高精确度的同时牺牲了检测性能。可以看到它们的召回率非常低。因此,与现有工具相比,Tamer具有更好的检测性能和相当的精确度。实验结果证明了我们的检测方法非常有效
RQ3
我们使用不同规模的代码库来评估Tamer的可伸缩性,并将执行时间与现有工具进行比较。我们使用IJaDataset [1],这是一个大型的跨项目Java数据集,与之前的研究[39, 44, 49]一样。我们使用CLOC [4]来测量数据集中的代码行数,从而分为1K、10K、100K、1M和10M LOC数据集。我们的实验在一个四核CPU和12GB内存上运行,与之前的研究[39, 44]一样。
在第二节中,我们已经说明了Tamer如何执行子树拆分和代码精细化分析。在这一节中,我们将使用实验数据进一步解释。表3显示了不同大小的数据集中每个工具的执行时间。可以看到,Tamer在各种数据集大小下都超过了几乎所有的检测工具。NiCad、CCAligner和Siamese使用复杂的计算公式和中间代码表达式来计算两个方法的相似性。Deckard和Yang2018是基于树的克隆检测工具。它们使用树表示来计算相似性,没有优化手段,无疑复杂且耗时,因此可伸缩性性能较差。LVMapper和SourcererCC都计算两个代码块之间的公共标记数,因此算法复杂度较低,时间消耗相对较小。然而,计算公共标记的复杂度是O(𝑁^2),所以当比较具有大量标记的两个代码块时,会导致检测时间大幅增加。
考虑到这个问题,Tamer创新性地提出将原来复杂的AST分成不同类型的子树,使子树节点类型序列也变短,大大减少了检测时间。实验数据还显示,我们的可伸缩性比LVMapper和SourcererCC更好。但是,我们发现在检测10M数据集时,我们的检测时间较慢,比NIL、CCFinder和CloneWorks要慢。以NIL为例,为了解释原因,我们分析了其源代码,发现NIL在预处理步骤中减少了代码标准化等耗时步骤。尽管它的检测执行时间很短,但检测性能大大降低。此外,它几乎无法检测到Type-3克隆。在实际情况下,存在许多Type-3克隆,因此NIL难以应用于实际的大规模克隆检测。CCFinder和CloneWorks都有这个问题。Tamer克服了Type-3类型克隆检测率低的问题,而且在执行时间方面表现出色,因此我们说Tamer具有出色的可伸缩性。

RQ4
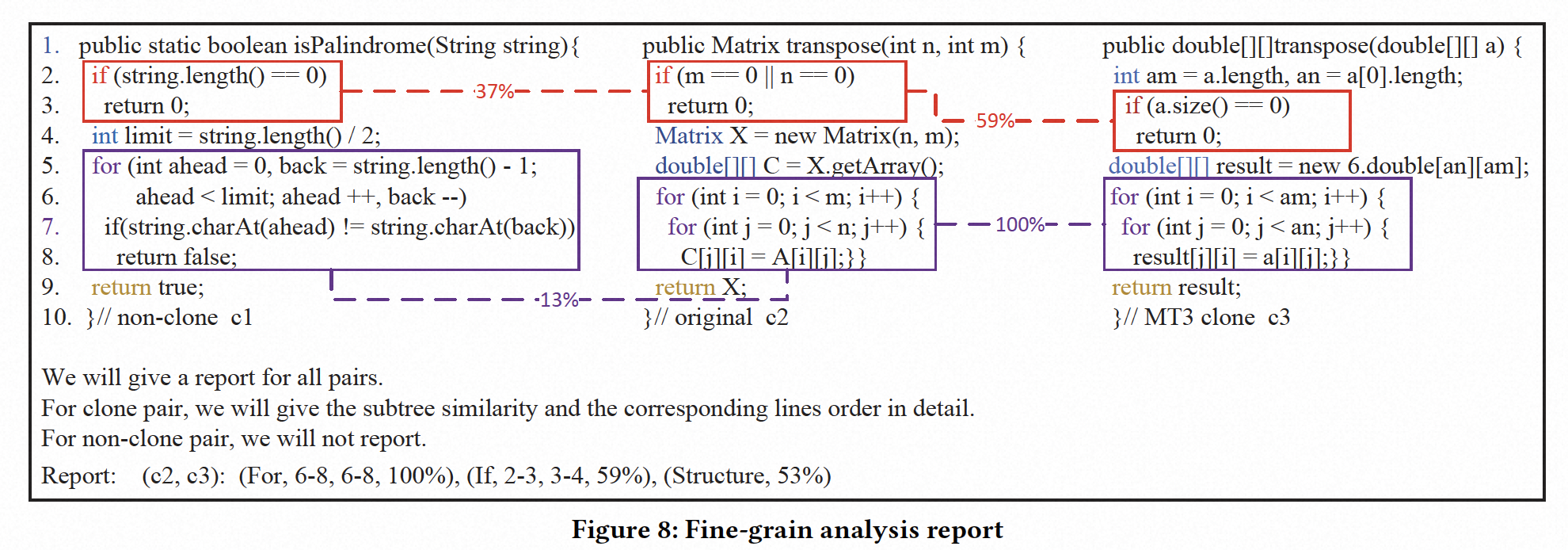
为了更好地回答这个问题,我们绘制了Tamer生成的部分报告,如图8所示。对于非克隆对,我们不进行报告。对于克隆对,我们不仅提供结果,还形成了精细的分析报告。以图8中的源代码为例。我们可以看到(c1, c2)被视为非克隆对,因为它们的子树相似性较低。 (c2, c3)被视为克隆对,因为它们的子树相似性很高。在报告中,我们对克隆对进行了精细的分析。我们可以看到c2和c3中For块的相似性为100%,相应的代码行是6-8和6-8。因为我们对源代码进行了抽象,并使用节点类型来表示节点,所以For块的节点序列完全相同。c2和c3中If块的相似性为59%,相应的代码行是2-3和3-4。在分析源代码后,我们发现两个If块的判断条件不同,因此它们的相似性仅为59%。至于结构子树的相似性,我们可以发现它只有53%。这是因为接口方法的参数不同,本地变量声明方式不同。此外,If块的位置也不同。因此,它们结构子树的相似性只有53%。
可以看出,我们在子树之间的相似性分析方法可以充分准确地反映源代码相应部分的相似关系。因此,我们可以使用这种方法来定位克隆对的克隆部分,并通过Tamer生成的报告对克隆对进行精细化分析。上面的报告只是一个简单的示例,用来说明Tamer的这一功能。我们的真实报告更加详细。
RQ5
我们将Tamer的优势归因于AST的分解,并进一步研究了分解AST的影响。在这部分中,我们进行了消融实验。具体而言,我们通过直接处理整个AST来设计另一个工具,即Tamer-ws(不分解)。
表4显示了两种工具在BCB数据集上的召回率和执行时间。就可扩展性而言,Tamer从100万行代码中检测克隆大约需要13秒,而Tamer-ws需要大约18秒才能完成该过程。此外,对于1000万数据集,Tamer-ws的运行时开销几乎是Tamer的两倍。就有效性而言,Tamer-ws的MT3召回率为35%,比Tamer低18%。这些结果表明,分解AST确实可以加速检测速度并提高检测的有效性。因此,我们可以发现分解AST不仅可以大大提高系统的检查速度(如第2节所述),还可以提高Tamer的有效性。
至于为什么分解可以增强有效性,我们观察到,在分解AST后获得的每个子树可以表示方法的一个子行为。一些克隆方法只有一些相似的子行为,而其他子行为不相似,这可能导致它们的整个AST不同。因此,如果我们直接分析整个AST,其他不相似的子行为可能会变成噪音,干扰克隆检测。当我们采用更精细的子行为(子树)匹配时,这些相似的子行为更容易检测,使我们能够检测更多的克隆。