Java8实战-总结26
- 用流收集数据
- 分组
- 多级分组
- 按子组收集数据
用流收集数据
分组
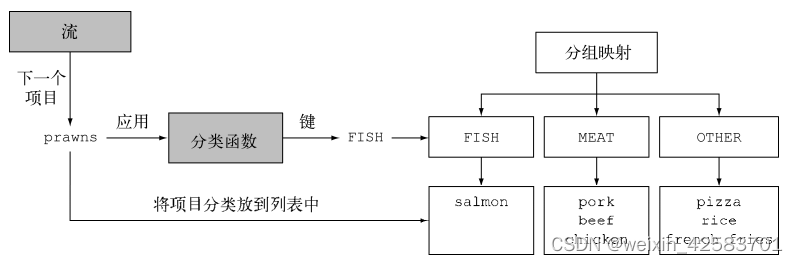
一个常见的数据库操作是根据一个或多个属性对集合中的项目进行分组。就像前面讲到按货币对交易进行分组的例子一样,如果用指令式风格来实现的话,这个操作可能会很麻烦、啰嗦而且容易出错。但是,如果用Java 8所推崇的函数式风格来重写的话,就很容易转化为一个非常容易看懂的语句。来看看这个功能的第二个例子:假设要把菜单中的菜按照类型进行分类,有肉的放一组,有鱼的放一组,其他的都放另一组。用Collectors.groupingBy工厂方法返回的收集器就可以轻松地完成这项任务,如下所示:
Map<Dish.Type,List<Dish>> dishesByType = menu.stream().collect(groupingBy(Dish::getType));
其结果是下面的Map:
{FISH = [prawns, salmon], OTHER=[french fries, rice, season fruit, pizza], MEAT=[pork, beef, chicken]}
这里,给groupingBy方法传递了一个Function(以方法引用的形式),它提取了流中每一道Dish的Dish.Type。这个Function叫作分类函数,因为它用来把流中的元素分成不同的组。如下图所示,分组操作的结果是一个Map,把分组函数返回的值作为映射的键,把流中所有具有这个分类值的项目的列表作为对应的映射值。在菜单分类的例子中,键就是菜的类型,值就是包含所有对应类型的菜肴的列表。
但是,分类函数不一定像方法引用那样可用,因为想用以分类的条件可能比简单的属性访问器要复杂。例如,把热量不到400卡路里的菜划分为“低热量”(diet),热量400到700卡路里的菜划为“普通”(normal),高于700卡路里的划为“高热量”(fat)。由于Dish类的作者没有把这个操作写成一个方法,无法使用方法引用,但可以把这个逻辑写成Lambda表达式:
public enum CaloricLevel { DIET, NORMAL, FAT }
Map<CaloricLevel, List<Dish>> dishesByCaloricLevel = menu.stream()
.collect(groupingBy(dish -> {
if(dish.getCalories() <= 400)return CaloricLevel.DIET;
else if (dish.getcalories()<= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
}));
现在,已经看到了如何对菜单中的菜肴按照类型和热量进行分组,但要是想同时按照这两个标准分类怎么办?分组的强大之处就在于它可以有效地组合。
多级分组
要实现多级分组,可以使用一个由双参数版本的Collectors.groupingBy工厂方法创建的收集器,它除了普通的分类函数之外,还可以接受collector类型的第二个参数。那么要进行二级分组的话,可以把一个内层groupingBy传递给外层groupingBy,并定义一个为流中项目分类的二级标准,如下多级分组代码示例所示:
Map<Dish.Type, Map<CaloricLevel, List<Dish>>> dishesByTypeCaloricLevel = menu.stream().collect(
//一级分类函数
groupingBy(Dish::getType,
groupingBy(dish -> {//二级分类函数
if(dish.getCalories() <= 400) return CaloricLevel.DIET;
else if (dish.getcalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;
})
)
);
这个二级分组的结果就是像下面这样的两级Map:
{MEAT={DIET=[chicken],NORMAL=[beef],FAT=[pork]},
FISH={DIET=[prawns],NORMAL=[salmon]},
OTHER={DIET=[rice, seasonal fruit],NORMAL=[french fries, pizza]}}
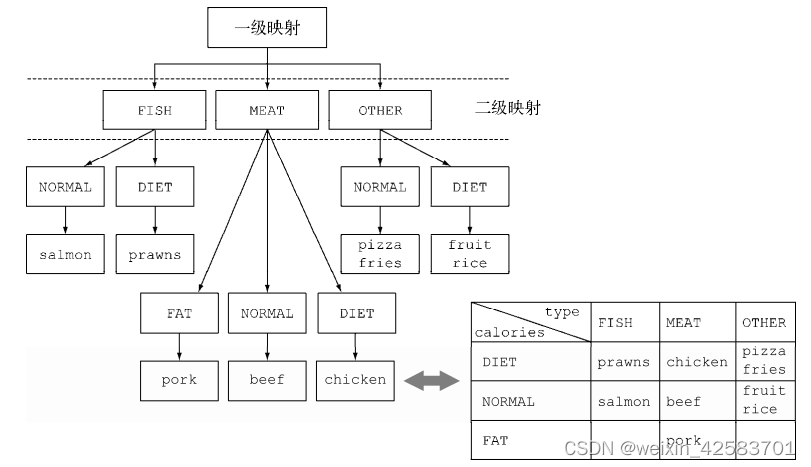
这里的外层Map的键就是第一级分类函数生成的值:"fish,meat,other",而这个Map的值又是一个Map,键是二级分类函数生成的值:“normal,diet,fat”。最后,第二级map的值是流中元素构成的List,是分别应用第一级和第二级分类函数所得到的对应第一级和第二级键的值:“salmon、pizza.”这种多级分组操作可以扩展至任意层级,n级分组就会得到一个代表n级树形结构的n级Map。
下图显示了为什么结构相当于n维表格,并强调了分组操作的分类目的。
一般来说,把groupingBy看作“桶”比较容易明白。第一个groupingBy给每个键建立了一个桶。然后再用下游的收集器去收集每个桶中的元素,以此得到n级分组。
按子组收集数据
可以把第二个groupingBy收集器传递给外层收集器来实现多级分组。但进一步说,传递给第一个groupingBy的第二个收集器可以是任何类型,而不一定是另一个groupingBy。例如,要数一数菜单中每类菜有多少个,可以传递counting收集器作为groupingBy收集器的第二个参数:
Map<Dish.Type, Long> typesCount = menu.stream().collect(groupingBy(Dish::getType, counting()));
其结果是下面的Map:
{MEAT = 3, FISH = 2, OTHER = 4}
还要注意,普通的单参数groupingBy(f)(其中f是分类函数)实际上是groupingBy (f, toList())的简便写法。
再举一个例子,可以把前面用于查找菜单中热量最高的菜肴的收集器改一改,按照菜的类型分类:
Map<Dish.Type, Optional<Dish>> mostcaloricByType = menu.stream().collect (groupingBy(Dish::getType, maxBy(comparingInt(Dish::getcalories))));
这个分组的结果显然是一个map,以Dish的类型作为键,以包装了该类型中热量最高的Dish的optional<Dish>作为值:
{FISH = Optional[salmon], OTHER = Optional[pizza], MEAT = Optional[pork]}
注意 这个Map中的值是optional,因为这是maxBy工厂方法生成的收集器的类型,但实际上,如果菜单中没有某一类型的Dish,这个类型就不会对应一个optional.empty()值,而且根本不会出现在Map的键中。groupingBy收集器只有在应用分组条件后,第一次在流中找到某个键对应的元素时才会把键加入分组Map中。这意味着optional包装器在这里不是很有用,因为它不会仅仅因为它是归约收集器的返回类型而表达一个最终可能不存在却意外存在的值。
1、把收集器的结果转换为另一种类型
因为分组操作的Map结果中的每个值上包装的optional没什么用,所以可能想要把它们去掉。要做到这一点,或者更一般地来说,把收集器返回的结果转换为另一种类型,可以使用Collectors.collectingAndThen工厂方法返回的收集器,如下所示查找每个子组中热量最高的Dish:
Map<Dish.Type, Dish> mostcaloricByType = menu.stream()
//分类函数
.collect (groupingBy(Dish::getType,
collectingAndThen(
maxBy(comparingInt(Dish::getcalories)),//包装后的收集器
//转换函数
Optional::get)));
这个工厂方法接受两个参数——要转换的收集器以及转换函数,并返回另一个收集器。这个收集器相当于旧收集器的一个包装,collect操作的最后一步就是将返回值用转换函数做一个映射。在这里,被包起来的收集器就是用maxBy建立的那个,而转换函数optional::get则把返回的optional中的值提取出来。前面已经说过,这个操作放在这里是安全的,因为reducing收集器永远都不会返回optional.empty()。其结果是下面的Map:
{FISH=salmon, OTHER=pizza, MEAT=pork}
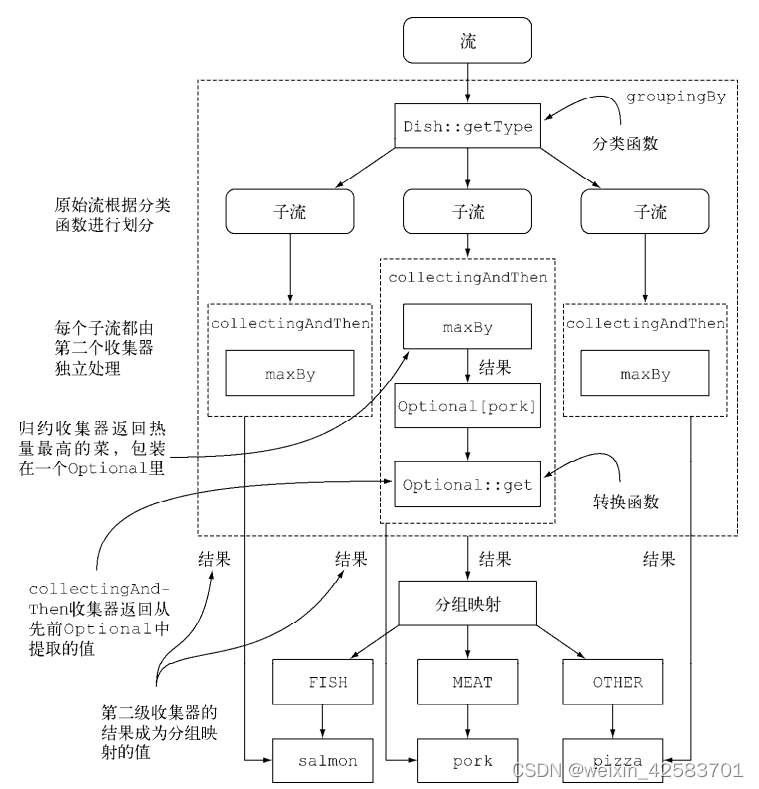
把好几个收集器嵌套起来很常见,它们之间到底发生了什么可能不那么明显。下图可以直观地展示它们是怎么工作的。从最外层开始逐层向里,注意以下几点。
- 收集器用虚线表示,因此
groupingBy是最外层,根据菜肴的类型把菜单流分组,得到三个子流。 groupingBy收集器包裹着collectingAndThen收集器,因此分组操作得到的每个子流 都用这第二个收集器做进一步归约。collectingAndThen收集器又包裹着第三个收集器maxBy。- 随后由归约收集器进行子流的归约操作,然后包含它的
collectingAndThen收集器会对其结果应用optional:get转换函数。 - 对三个子流分别执行这一过程并转换而得到的三个值,也就是各个类型中热量最高的
Dish,将成为groupingBy收集器返回的Map中与各个分类键(Dish的类型)相关联的值。
2、与groupingBy联合使用的其他收集器的例子
一般来说,通过groupingBy工厂方法的第二个参数传递的收集器将会对分到同一组中的所有流元素执行进一步归约操作。例如,重用求出所有菜肴热量总和的收集器,不过这次是对每一组Dish求和:
Map<Dish.Type, Integer> totalcaloriesByType = menu.stream().collect(groupingBy (Dish::getType, summingInt(Dish::getcalories)));
然而常常和groupingBy联合使用的另一个收集器是mapping方法生成的。这个方法接受两个参数:一个函数对流中的元素做变换,另一个则将变换的结果对象收集起来。其目的是在累加之前对每个输入元素应用一个映射函数,这样就可以让接受特定类型元素的收集器适应不同类型的对象。一个使用这个收集器的实际例子:比方说想要知道,对于每种类型的Dish,菜单中都有哪些CaloricLevel。可以把groupingBy和mapping收集器结合起来,如下所示:
Map<Dish.Type, Set<CaloricLevel>> caloricLevelsByType = menu.stream().collect(
groupingBy(Dish::getType, mapping(
dish -> {if (dish.getcalories() <= 400)return CaloricLevel.DIET;
else if(dish.getCalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;},
toset())));
这里,就像前面见到过的,传递给映射方法的转换函数将Dish映射成了它的CaloricLevel:生成的CaloricLevel流传递给一个toSet收集器,它和toList类似,不过是把流中的元素累积到一个Set而不是List中,以便仅保留各不相同的值。如先前的示例所示,这个映射收集器将会收集分组函数生成的各个子流中的元素,让你得到这样的Map结果:
{OTHER=[DIET, NORMAL], MEAT=[DIET, NORMAL,FAT], PISH=[DIET, NORMAL]}
由此就可以轻松地做出选择了。在上一个示例中,对于返回的Set是什么类型并没有任何保证。但通过使用toCollection,就可以有更多的控制。例如,可以给它传递一个构造函数引用来要求HashSet:
Map<Dish.Type, Set<CaloricLevel>> caloricLevelsByType =menu.stream().collect(
groupingBy(Dish::getType, mapping(
dish -> { if(dish.getcalories() <= 400) return CaloricLeve1.DIET;
else if (dish.getcalories() <= 700) return CaloricLevel.NORMAL;
else return CaloricLevel.FAT;},
toCollection(Hashset::new))));