阿丹:
在刚开始写本文章的是还不太清楚要如何去细啃下这两个体系,在查阅资料的过程中。发现大厂阿里的庖丁解InnoDB系列,详细了的写了很多底层知识,于是基于这个这两个文章才有了阿丹的这篇文章。
整体认知:
在 MySQL 中的撤销日志(undo log)和重做日志(redo log)的机制。
撤销日志(undo log)在 MySQL 中被称为回滚日志(rollback log),用于回滚事务的修改。在事务执行期间,所有的修改操作都会被写入回滚日志中,以便在发生回滚操作或者系统崩溃时能够撤销事务的修改。回滚日志记录了数据修改前的旧值,以便进行回滚操作。
重做日志(redo log)在 MySQL 中同样被称为重做日志(redo log),用于事务的持久性和恢复性。在事务提交时,重做日志会将事务所做的修改记录下来,以便在系统崩溃时能够通过重演这些修改来恢复数据库的状态。重做日志的记录方式是采用追加日志的方式,将数据修改操作追加到日志文件中。
这两个日志(回滚日志和重做日志)是 MySQL 确保事务的原子性、一致性、持久性和可恢复性的关键机制。它们一起确保了数据库的安全性,并允许系统在发生故障时能够恢复到正确的状态。
有点不一样!
在 InnoDB 存储引擎中,独有的日志是撤销日志(undo log)。InnoDB 引擎使用撤销日志来实现事务的一致性和原子性。
InnoDB 的撤销日志是作为事务日志(transaction log)的一部分进行记录的,其目的是为了支持事务的回滚操作。每个事务在执行期间所做的修改都会被写入撤销日志,以确保在事务回滚时可以撤销这些修改。撤销日志记录了数据修改前的旧值,以便回滚操作能够正确地恢复数据。
而重做日志(redo log)在 InnoDB 中同样存在,但不属于 InnoDB 引擎独有。重做日志用于事务的持久性和恢复性,确保在系统崩溃后可以通过重演事务的修改来恢复数据库的一致性。
总结来说,InnoDB 引擎中独有的是撤销日志(undo log),而重做日志(redo log)是作为事务日志的一部分存在于多个存储引擎中。
redo log和undo log的关系
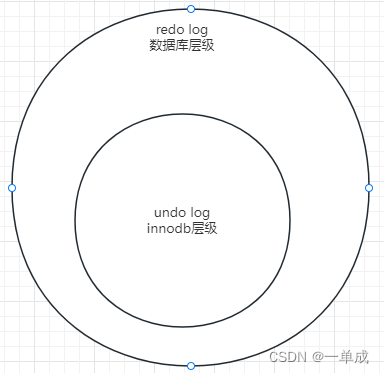
InnoDB中其实是把Undo当做一种数据来维护和使用的,也就是说,Undo Log日志本身也像其他的数据库数据一样,会写自己对应的Redo Log,通过Redo Log来保证自己的原子性。因此,更合适的称呼应该是Undo Data。
理解:
也就说其实undo log在数据库中也是和一张表中的数据一样,也是使用redo log来保证数据的一致性的。它也是存储在innodb中的数据页16kb物理存储块的限制管理中的。
mysql中的redo log
在其他的数据库以及在其他的数据库管理系统中,redo log的作用是保证数据的原子性与持久性。同时为了保证一致性和与隔离性。innodb推出并维护了undo log。并且undo log是受到redo log来管理的。
为什么需要记录REDO
1、为了取得更好的读写性能,innodb会将数据缓存在内存中(InnoDB Buffer Pool),对磁盘数据的修改也会落后于内存。因为是在缓存中所以进程或者机器崩溃的时候就会导致整个内存的数据丢失。
2、为了保证数据库中的持久性以及一致性,innodb中维护redo log。
也就是说在数据落库前先将数据生成的的redo log落库持久化。也就是修改page之前需要先将修改的内容记录到redo中。保证redo log在修改page数据页中落盘。
其中涉及到一个概念为:WAL
WAL(Write Ahead Log)实际上是redo log的一种实现方式,它是InnoDB为了确保数据的持久性而设计的一种机制。WAL的基本思想是在将数据修改应用到磁盘之前,先将这些修改记录到redo log中。这样即使在数据修改应用到磁盘之后发生机器崩溃,也可以通过redo log中的信息恢复数据。因此,WAL是InnoDB保证数据一致性和持久性的重要手段之一。
就是在故障发生导致内存数据丢失后,Innodb会在重启的时候,重放redo,将page恢复到崩溃前的状态。
需要什么样的REDO
1、事务正确性:一个事务在他的redo全部落盘之后才能返回用户成功。
2、redo的数据量要小
3、因为系统崩溃是无法预知的,重启重放redo的时候,系统是不知道那些redo对应page(数据页)已经重新落盘了。所以redo的重放必须要可重入,所以redo要保证幂等。
4、为了重入的速度,一个redo必须只对应一个page
使用对应技术选型来解决这个问题--使用技术特性来解决难题:
数据小--》Logical Logging
幂等以及基于page--》Physical Logging
因此innodb采用的日志被称为
Physiological Logging
解释:以page为单位,但是在Page内以逻辑的方式记录。
官方例子:
MLOG_REC_UPDATE_IN_PLACE类型的REDO中记录了对Page中一个Record的修改,方法如下:
(Page ID,Record Offset,(Filed 1, Value 1) ... (Filed i, Value i) ... )
其中,PageID指定要操作的Page页,Record Offset记录了Record在Page内的偏移位置,后面的Field数组,记录了需要修改的Field以及修改后的Value。
由于Physiological Logging的方式采用了物理Page中的逻辑记法,导致两个问题:
1、需要基于正确的Page状态上重放REDO
由于在一个Page内,REDO是以逻辑的方式记录了前后两次的修改,因此重放REDO必须基于正确的Page状态。然而InnoDB默认的Page大小是16KB,是大于文件系统能保证原子的4KB大小的,因此可能出现Page内容成功一半的情况。InnoDB中采用了Double Write Buffer的方式来通过写两次的方式保证恢复的时候找到一个正确的Page状态。这部分会在之后介绍Buffer Pool的时候详细介绍。
2、需要保证REDO重放的幂等
Double Write Buffer能够保证找到一个正确的Page状态,我们还需要知道这个状态对应REDO上的哪个记录,来避免对Page的重复修改。为此,InnoDB给每个REDO记录一个全局唯一递增的标号LSN(Log Sequence Number)。Page在修改时,会将对应的REDO记录的LSN记录在Page上(FIL_PAGE_LSN字段),这样恢复重放REDO时,就可以来判断跳过已经应用的REDO,从而实现重放的幂等。
REDO中记录了什么内容
到MySQL 8.0为止,已经有多达65种的REDO记录。用来记录这不同的信息,恢复时需要判断不同的REDO类型,来做对应的解析。根据REDO记录不同的作用对象,可以将这65中REDO划分为三个大类:作用于Page,作用于Space以及提供额外信息的Logic类型。
作用于Page的REDO
这类REDO占所有REDO类型的绝大多数,根据作用的Page的不同类型又可以细分为,Index Page REDO,Undo Page REDO,Rtree PageREDO等。比如MLOG_REC_INSERT,MLOG_REC_UPDATE_IN_PLACE,MLOG_REC_DELETE三种类型分别对应于Page中记录的插入,修改以及删除。这里还是以MLOG_REC_UPDATE_IN_PLACE为例来看看其中具体的内容:
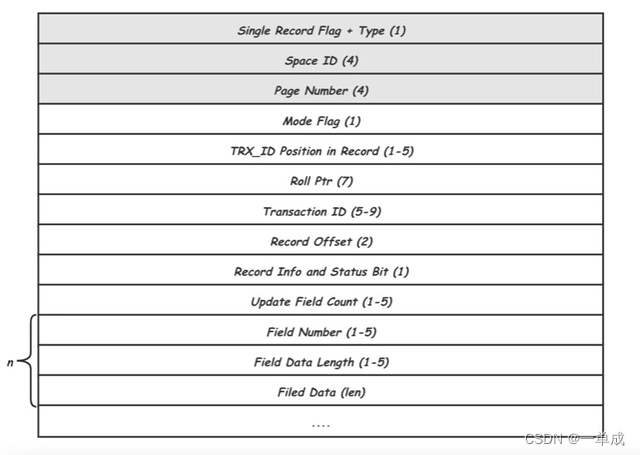
图片解读:
前三个带着阴影的是每个redo log都带有的公共字段
其中,Type就是MLOG_REC_UPDATE_IN_PLACE类型,Space ID和Page Number唯一标识一个Page页,这三项是所有REDO记录都需要有的头信息,后面的是MLOG_REC_UPDATE_IN_PLACE类型独有的,其中Record Offset用给出要修改的记录在Page中的位置偏移,Update Field Count说明记录里有几个Field要修改,紧接着对每个Field给出了Field编号(Field Number),数据长度(Field Data Length)以及数据(Filed Data)。
作用于Space的REDO
这类REDO针对一个Space文件的修改,如MLOG_FILE_CREATE,MLOG_FILE_DELETE,MLOG_FILE_RENAME分别对应对一个Space的创建,删除以及重命名。由于文件操作的REDO是在文件操作结束后才记录的,因此在恢复的过程中看到这类日志时,说明文件操作已经成功,因此在恢复过程中大多只是做对文件状态的检查,以MLOG_FILE_CREATE来看看其中记录的内容:

同样的前三个字段还是Type,Space ID和Page Number,由于是针对space的操作,并不作用于page,所以这里的Page Number永远是0。在此之后记录了创建的文件flag以及文件名,用作重启恢复时的检查。
解读:
其实这里记录的是一些对于表的修改。表的正删改查算是。
提供额外信息的Logic REDO
除了上述类型外,还有少数的几个REDO类型不涉及具体的数据修改,只是为了记录一些需要的信息,比如最常见的MLOG_MULTI_REC_END就是为了标识一个REDO组,也就是一个完整的原子操作的结束。
REDO是如何组织的
所谓组织方式其实就是我们如何给redo内从记录的磁盘文件保存下来。以便用方便高效的方式在redo中写入、读取、恢复以及清理。
我们这里把redo从上倒下分为三层:
逻辑、物理、文件
逻辑REDO层
这一层是真正的REDO内容,REDO由多个不同Type的多个REDO记录收尾相连组成,有全局唯一的递增的偏移sn,InnoDB会在全局log_sys中维护当前sn的最大值,并在每次写入数据时将sn增加REDO内容长度

解读:
偏移量sn可以理解为redo log的物理地址。偏移量sn(Segment Number)是InnoDB存储引擎中redo log的一种全局唯一的递增的数值,用于标记redo log中每个记录的位置。
redo log中的每个redo记录都有一个唯一的sn,它标记了redo记录在redo log中的位置。因此,sn的确可以视为redo log的物理地址。
物理REDO层
原文:
磁盘是块设备,InnoDB中也用Block的概念来读写数据,一个Block的长度OS_FILE_LOG_BLOCK_SIZE等于磁盘扇区的大小512B,每次IO读写的最小单位都是一个Block。除了REDO数据以外,Block中还需要一些额外的信息,下图所示一个Log Block的的组成,包括12字节的Block Header:前4字节中Flush Flag占用最高位bit,标识一次IO的第一个Block,剩下的31个个bit是Block编号;之后是2字节的数据长度,取值在[12,508];紧接着2字节的First Record Offset用来指向Block中第一个REDO组的开始,这个值的存在使得我们对任何一个Block都可以找到一个合法的的REDO开始位置;最后的4字节Checkpoint Number记录写Block时的next_checkpoint_number,用来发现文件的循环使用,这个会在文件层详细讲解。Block末尾是4字节的Block Tailer,记录当前Block的Checksum,通过这个值,读取Log时可以明确Block数据有没有被完整写完。

Block中剩余的中间498个字节就是REDO真正内容的存放位置,也就是我们上面说的逻辑REDO。我们现在将逻辑REDO放到物理REDO空间中,由于Block内的空间固定,而REDO长度不定,因此可能一个Block中有多个REDO,也可能一个REDO被拆分到多个Block中,如下图所示,棕色和红色分别代表Block Header和Tailer,中间的REDO记录由于前一个Block剩余空间不足,而被拆分在连续的两个Block中。
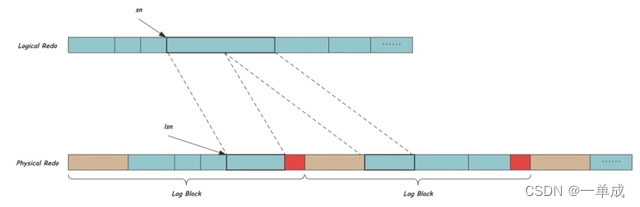
由于增加了Block Header和Tailer的字节开销,在物理REDO空间中用LSN来标识偏移,可以看出LSN和SN之间有简单的换算关系:
constexpr inline lsn_t log_translate_sn_to_lsn(lsn_t sn) {return (sn / LOG_BLOCK_DATA_SIZE * OS_FILE_LOG_BLOCK_SIZE +sn % LOG_BLOCK_DATA_SIZE + LOG_BLOCK_HDR_SIZE);}
SN加上之前所有的Block的Header以及Tailer的长度就可以换算到对应的LSN,反之亦然。
阿丹解读:
第一段中提高的Block概念为:
这里提到的"Block"是InnoDB存储引擎中的一个概念,用于管理磁盘上的数据和日志。在InnoDB中,一个Block是数据文件和日志文件的最小读写单位,也是数据恢复和事务处理的基本单位。
在InnoDB中,每个Block都有固定的开头和结尾,包含了一些元数据信息,例如:
- Block Header:这是每个Block的头部,包含了一些状态信息,例如是否是第一次写入(Flush Flag),Block的编号等。
- Data Length:这是紧跟在Block Header后面的字段,表示该Block中数据的长度。
- First Record Offset:这个字段用于指向Block中第一个REDO组的开始位置。在发生事务回滚或数据恢复时,可以通过这个偏移量快速找到REDO数据的起始位置。
- Checkpoint Number:这是记录在Block末尾的校验和,用于验证数据的完整性。在写入Block时,会将写入的下一个checkpoint的编号记录下来,以便在读取Log时,可以通过比较当前的checkpoint编号和记录的checkpoint编号来检查数据是否被完整写入。
- Block Tailer:这是每个Block的尾部,记录了该Block的校验和(Checksum),用于检查数据是否在传输或存储过程中发生错误。
总的来说,"Block"是InnoDB中用于管理磁盘上数据和日志的一种数据结构,它包含了元数据信息和数据本身,可以有效地进行数据读写、事务处理和数据恢复等操作。
这里的计算我确实是没看太懂。
文件层
原文:
最终REDO会被写入到REDO日志文件中,以ib_logfile0、ib_logfile1...命名,为了避免创建文件及初始化空间带来的开销,InooDB的REDO文件会循环使用,通过参数innodb_log_files_in_group可以指定REDO文件的个数。多个文件收尾相连顺序写入REDO内容。每个文件以Block为单位划分,每个文件的开头固定预留4个Block来记录一些额外的信息,其中第一个Block称为Header Block,之后的3个Block在0号文件上用来存储Checkpoint信息,而在其他文件上留空:
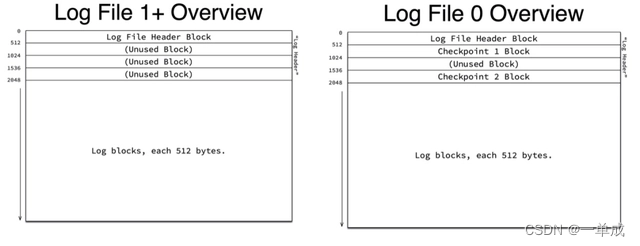
其中第一个Header Block的数据区域记录了一些文件信息,如下图所示,4字节的Formate字段记录Log的版本,不同版本的LOG,会有REDO类型的增减,这个信息是8.0开始才加入的;8字节的Start LSN标识当前文件开始LSN,通过这个信息可以将文件的offset与对应的lsn对应起来;最后是最长32位的Creator信息,正常情况下会记录MySQL的版本。

现在我们将REDO放到文件空间中,如下图所示,逻辑REDO是真正需要的数据,用sn索引,逻辑REDO按固定大小的Block组织,并添加Block的头尾信息形成物理REDO,以lsn索引,这些Block又会放到循环使用的文件空间中的某一位置,文件中用offset索引:
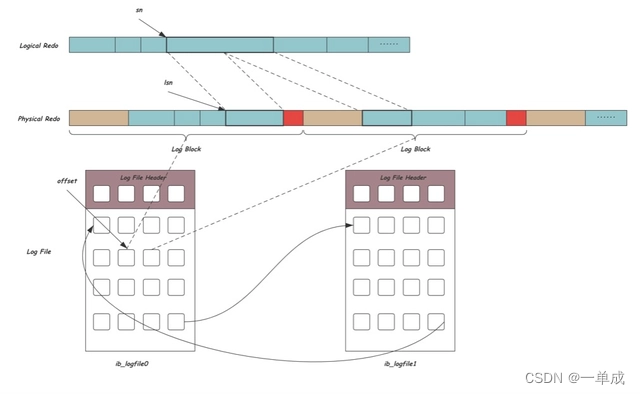
虽然通过LSN可以唯一标识一个REDO位置,但最终对REDO的读写还需要转换到对文件的读写IO,这个时候就需要表示文件空间的offset,他们之间的换算方式如下:
const auto real_offset =log.current_file_real_offset + (lsn - log.current_file_lsn);
切换文件时会在内存中更新当前文件开头的文件offset,current_file_real_offset,以及对应的LSN,current_file_lsn,通过这两个值可以方便地用上面的方式将LSN转化为文件offset。注意这里的offset是相当于整个REDO文件空间而言的,由于InnoDB中读写文件的space层实现支持多个文件,因此,可以将首位相连的多个REDO文件看成一个大文件,那么这里的offset就是这个大文件中的偏移。
Redo log中保存的是什么?
Redo log中保存的是事务中修改的任何数据,具体来说,它记录了数据库中数据页的更新内容,是一种物理日志。
在redo log buffer和redo log文件中,日志以块为单位存储,每个块包括以下三个部分:
-
日志块头(Header),占12字节,记录了日志块的一些元信息,例如:日志块的大小、日志块是否被写入磁盘等。
-
日志块尾(Tail),占8字节,记录了日志块的校验和(Checksum),用于检查日志块的完整性。
-
日志主体(Body),占492字节,记录了数据页的更新内容,具体包括:数据页的物理地址、修改的类型、修改的字节数、旧值和新值等。
Redo log是由以下信息组成的:
-
日志头信息:包括redo log的版本号、事务ID、事务开始时间等信息。
-
日志主体:记录了数据页的更新内容,包括数据页的物理地址、修改的类型、修改的字节数、旧值和新值等。
-
日志尾信息:包括redo log的校验和等信息。
总之,Redo log是数据库中非常重要的日志文件,它能够保证事务的持久性和原子性,以及在数据库发生故障时进行数据恢复等操作。
REDO产生
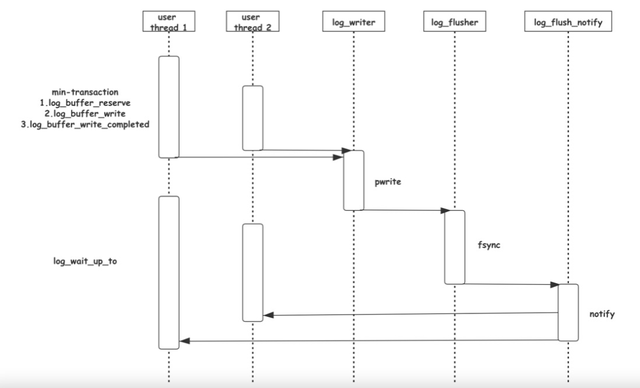
我们知道事务在写入数据的时候会产生REDO,一次原子的操作可能会包含多条REDO记录,这些REDO可能是访问同一Page的不同位置,也可能是访问不同的Page(如Btree节点分裂)。InnoDB有一套完整的机制来保证涉及一次原子操作的多条REDO记录原子,即恢复的时候要么全部重放,要不全部不重放,这部分将在之后介绍恢复逻辑的时候详细介绍,本文只涉及其中最基本的要求,就是这些REDO必须连续。InnoDB中通过min-transaction实现,简称mtr,需要原子操作时,调用mtr_start生成一个mtr,mtr中会维护一个动态增长的m_log,这是一个动态分配的内存空间,将这个原子操作需要写的所有REDO先写到这个m_log中,当原子操作结束后,调用mtr_commit将m_log中的数据拷贝到InnoDB的Log Buffer。
写入InnoDB Log Buffer
高并发的环境中,会同时有非常多的min-transaction(mtr)需要拷贝数据到Log Buffer,如果通过锁互斥,那么毫无疑问这里将成为明显的性能瓶颈。为此,从MySQL 8.0开始,设计了一套无锁的写log机制,其核心思路是允许不同的mtr,同时并发地写Log Buffer的不同位置。不同的mtr会首先调用log_buffer_reserve函数,这个函数里会用自己的REDO长度,原子地对全局偏移log.sn做fetch_add,得到自己在Log Buffer中独享的空间。之后不同mtr并行的将自己的m_log中的数据拷贝到各自独享的空间内。
/* Reserve space in sequence of data bytes: */const sn_t start_sn = log.sn.fetch_add(len);
写入Page Cache
写入到Log Buffer中的REDO数据需要进一步写入操作系统的Page Cache,InnoDB中有单独的log_writer来做这件事情。这里有个问题,由于Log Buffer中的数据是不同mtr并发写入的,这个过程中Log Buffer中是有空洞的,因此log_writer需要感知当前Log Buffer中连续日志的末尾,将连续日志通过pwrite系统调用写入操作系统Page Cache。整个过程中应尽可能不影响后续mtr进行数据拷贝,InnoDB在这里引入一个叫做link_buf的数据结构,如下图所示:
link_buf是一个循环使用的数组,对每个lsn取模可以得到其在link_buf上的一个槽位,在这个槽位中记录REDO长度。另外一个线程从开始遍历这个link_buf,通过槽位中的长度可以找到这条REDO的结尾位置,一直遍历到下一位置为0的位置,可以认为之后的REDO有空洞,而之前已经连续,这个位置叫做link_buf的tail。下面看看log_writer和众多mtr是如何利用这个link_buf数据结构的。这里的这个link_buf为log.recent_written,如下图所示:
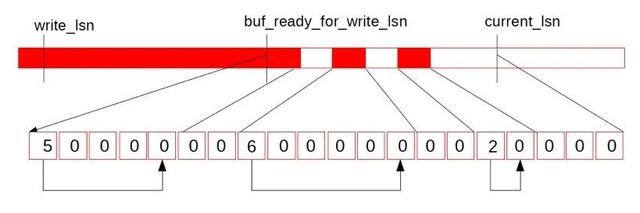
图中上半部分是REDO日志示意图,write_lsn是当前log_writer已经写入到Page Cache中日志末尾,current_lsn是当前已经分配给mtr的的最大lsn位置,而buf_ready_for_write_lsn是当前log_writer找到的Log Buffer中已经连续的日志结尾,从write_lsn到buf_ready_for_write_lsn是下一次log_writer可以连续调用pwrite写入Page Cache的范围,而从buf_ready_for_write_lsn到current_lsn是当前mtr正在并发写Log Buffer的范围。下面的连续方格便是log.recent_written的数据结构,可以看出由于中间的两个全零的空洞导致buf_ready_for_write_lsn无法继续推进,接下来,假如reserve到中间第一个空洞的mtr也完成了写Log Buffer,并更新了log.recent_written*,如下图:
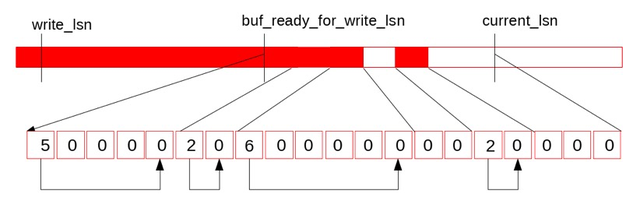
这时,log_writer从当前的buf_ready_for_write_lsn向后遍历log.recent_written,发现这段已经连续:
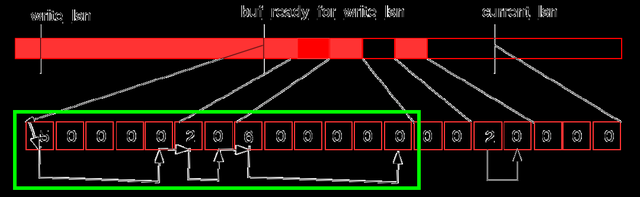
因此提升当前的buf_ready_for_write_lsn,并将log.recent_written的tail位置向前滑动,之后的位置清零,供之后循环复用:
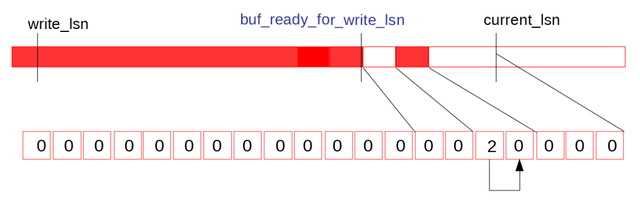
紧接log_writer将连续的内容刷盘并提升write_lsn。
刷盘
log_writer提升write_lsn之后会通知log_flusher线程,log_flusher线程会调用fsync将REDO刷盘,至此完成了REDO完整的写入过程。
唤醒用户线程
为了保证数据正确,只有REDO写完后事务才可以commit,因此在REDO写入的过程中,大量的用户线程会block等待,直到自己的最后一条日志结束写入。默认情况下innodb_flush_log_at_trx_commit = 1,需要等REDO完成刷盘,这也是最安全的方式。当然,也可以通过设置innodb_flush_log_at_trx_commit = 2,这样,只要REDO写入Page Cache就认为完成了写入,极端情况下,掉电可能导致数据丢失。
大量的用户线程调用log_write_up_to等待在自己的lsn位置,为了避免大量无效的唤醒,InnoDB将阻塞的条件变量拆分为多个,log_write_up_to根据自己需要等待的lsn所在的block取模对应到不同的条件变量上去。同时,为了避免大量的唤醒工作影响log_writer或log_flusher线程,InnoDB中引入了两个专门负责唤醒用户的线程:log_wirte_notifier和log_flush_notifier,当超过一个条件变量需要被唤醒时,log_writer和log_flusher会通知这两个线程完成唤醒工作。下图是整个过程的示意图:
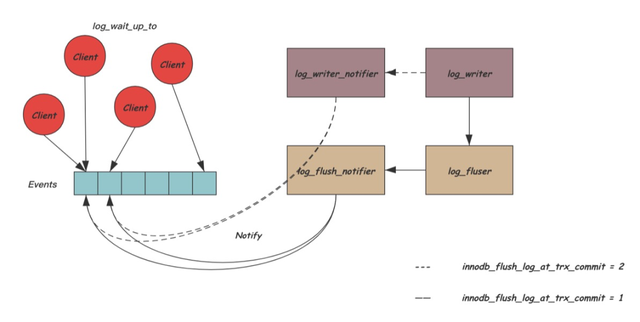
多个线程通过一些内部数据结构的辅助,完成了高效的从REDO产生,到REDO写盘,再到唤醒用户线程的流程,下面是整个这个过程的时序图: