一、RDD对象
PySpark支持多种数据的输入,在输入完成后,都会得到一个:RDD类的对象
RDD全称为:弹性分布式数据集(Resilient Distributed Datasets)
PySpark针对数据的处理,都是以RDD对象作为载体,即:
- 数据存储在RDD内
- 各类数据的计算方法,也都是RDD的成员方法
- RDD的数据计算方法,返回值依旧是RDD对象
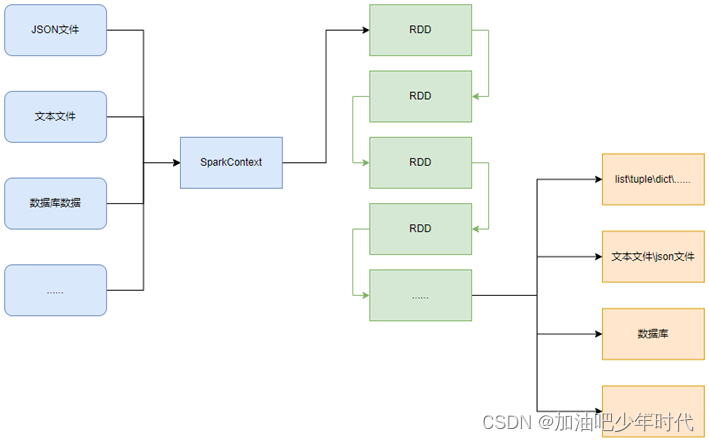
PySpark的编程模型可以归纳为:准备数据到RDD -> RDD迭代计算 -> RDD导出为list、文本文件等,即:源数据 -> RDD -> 结果数据
二、Python数据容器转RDD对象
PySpark支持通过SparkContext对象的parallelize成员方法,将:list、tuple、set、dict、str转换为PySpark的RDD对象

PySpark也支持通过SparkContext入口对象,来读取文件,来构建出RDD对象。

代码案例:
"""
#通过PySpark代码加载数据,即数据输入
"""
from pyspark import SparkConf,SparkContext
conf = SparkConf().setMaster("local[*]").setAppName("test_spark")
sc = SparkContext(conf = conf)
# 通过parallelize方法将Python对象加载到Spark内,成为RDD对象
rdd1 = sc.parallelize([1, 2, 3, 4, 5])
rdd2 = sc.parallelize((1, 2, 3, 4, 5))
rdd3 = sc.parallelize("abcdefg")
rdd4 = sc.parallelize({1, 2, 3, 4, 5})
rdd5 = sc.parallelize({"key1": "value1", "key2": "value2"})
# 如果要查看RDD里面有什么内容,需要用collect()方法
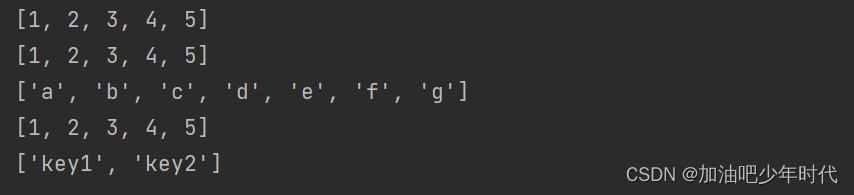
print(rdd1.collect())
print(rdd2.collect())
print(rdd3.collect())
print(rdd4.collect())
print(rdd5.collect())
打印结果:
pyspark安装方法 :
第一种方法时命令行安装:pip install pyspark;
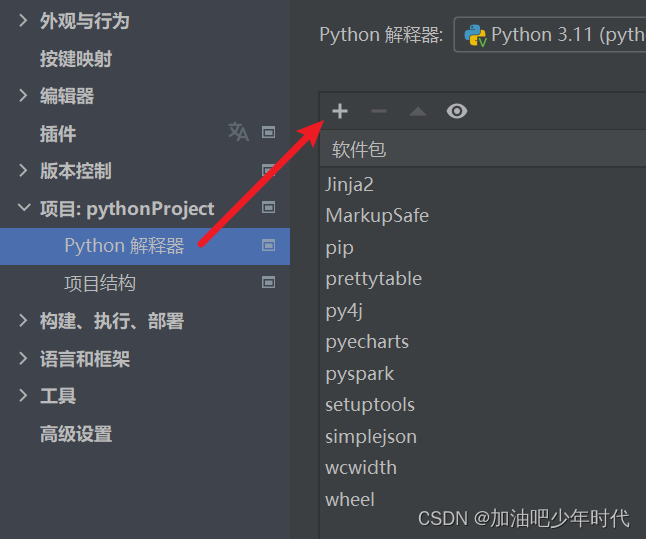
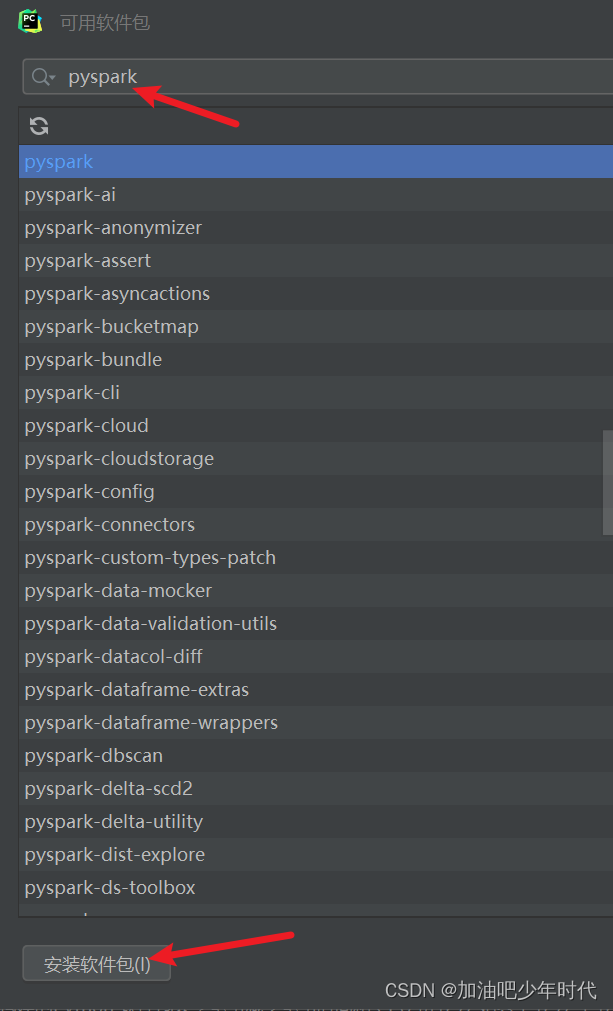
第二种方式是直接在Pycharm进行安装,如下图所示;
安装完成后,运行代码出现缺少Java环境依赖,需要配置java运行环境才可以运行Pyspark导入报对象,配置环境的过程可以参考博客教程:
java 环境配置(详细教程)_java环境配置_多加点辣也没关系的博客-CSDN博客
JDK 8.0 的安装包已上传资源报,希望可以帮助到大家!