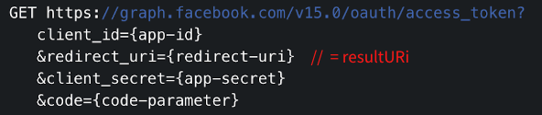
1.[ICML2019]Quantifying Generalization in Reinforcement Learning
文章提出16000多个单智能体闯关游戏CoinRun,通过智能体在分割开的训练环境和测试环境上表现的性能作为RL泛化性的度量。具体而言作者通过”奔跑硬币泛化曲线“ (CoinRun Generalization Curves)来评价泛化性,训练和测试时关卡等级服从同分布,所以殉难联合测试表现得差异代表了过拟合程度。
结论:1. 更深的CNN网络有益于防止过拟合 2. L2正则化和冻肉皮 out 有益于泛化性,dropout作用更小( Empirically, the most effective dropout probability is p = 0.1 and the most effective L2 weight is w = 10−4 .) 3. 批归一化Batch Normalization 有益于泛化性(As we can see, batch normalization offers a significant performance boost.) 4. 增加策略随机性或者环境随机性,具体是增加、epsilon-greedy和ppo中的熵奖励(但可能因环境不同具体效果差异大,在状态转移高度随机的环境中增益小)
1.RL过拟合定义:在见过的环境上通关率高,没见过的通关率低(CoinRun Generalization Curves)
2.[Arxiv 2018]*(173cited) Assessing Generalization in Deep Reinforcement Learning
本文提出一个泛化性的基准和实验方案——对一些经典的强化学习环境-gym 的参数进行内插和外插,内插即训练参数和测试参数相似,外插是不相似。
3. [Arxiv 2021] A Survey of Generalisation in Deep Reinforcement Learning
在监督学习中骂我们将训练和测试的表现差距作为泛化性的测量,与它相似的在强化学习中,交换训练和测试顺序,泛化性的差距度量为

其中:
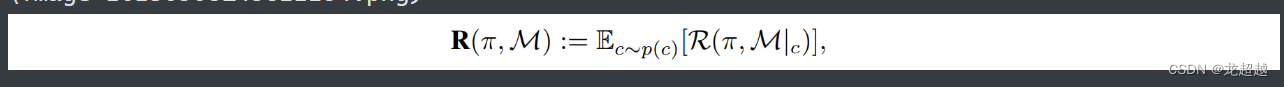
Ctrain 是一个训练的上下文集合,Ctest是一个测试的上下文集合,p(c)是文本的的分布,它影响的是初始状态的分布
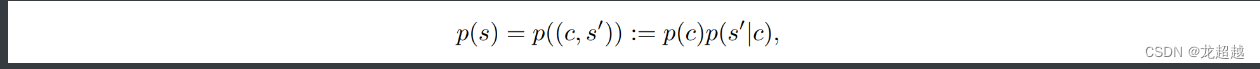
上下文C是对智能体agent不可兼得,这使得CMDP成为一个POMDP。
论文指出在MDP中,奖励函数、转移函数、初始状态分布和发射函数都以上下文作为输入。除了动作空间是固定的外,上下文的选择决定了MDP的一切。
泛化性使用的方法,主要从哪几方面入手具有什么问题