1 查询时设置权重
用户可以使用布尔查询将多种查询组合在一起。在默认情况下,这些查询的权重都为1,也就是查询之间都是平等的。有时我们希望某些查询的权重高一些,也就是在其他条件相同的情况下,匹配该查询的文档得分更高。此时应该怎么做呢?本节将介绍的boosting查询和boost设置可以满足上述查询需求。
1.1 查询时boost参数的设置
在ES中可以通过查询的boost值对某个查询设定其权重。在默认情况下,所有查询的boost值为1。但是当设置某个查询的boost为2时,不代表匹配该查询的文档评分是原来的2倍,而是代表匹配该查询的文档得分相对于其他文档得分被提升了。例如,可以为查询A设定boost值为3,为查询B设定boost值为6,则在进行相关性计算时,查询B的权重将比查询A相对更高一些。
boost值的设置只限定在term查询和类match查询中,其他类型的查询不能使用boost设置。boost值没有特别约束,因为它代表的是一个相对值。当该值在0~1时表示对权重起负向作用,当该值大于1时表示对权重起正向作用。为方便演示,下面先创建索引:
PUT /hotel
{
"settings": {
"number_of_shards": 1
},
"mappings": { //定义字段
"properties": {
"title": {
"type": "text"
},
"price": {
"type": "double"
},
"full_room": {
"type": "boolean"
}
}
}
}
在上面的DSL中设定了索引的主分片数为1,这是为了方便计算文本的IDF值,现在向索引中写入数据:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title": "文雅酒假日酒店","price": 556.00,"full_room":false}
{"index":{"_index":"hotel","_id":"002"}}
{"title": "金都嘉怡假日酒店","price": 337.00,"full_room":true}
{"index":{"_index":"hotel","_id":"003"}}
{"title": "金都欣欣酒店","price": 200.00,"full_room":true}
{"index":{"_index":"hotel","_id":"004"}}
{"title": "金都家至酒店","price": 500.00,"full_room":false}
{"index":{"_index":"hotel","_id":"005"}}
{"title": "文雅精选酒店","price": 800.00,"full_room":true}
下面对索引进行查询,假设“金都”或者“文雅”是两个酒店的品牌,用户想查询标题中包含“金都”或者“文雅”的酒店文档:
GET /hotel/_search
{
"query": {
"bool": {
"should": [
{
"match": { //查询标题匹配“金都”的文档
"title":{
"query": "金都"
}
}
},
{
"match": { //查询标题匹配“文雅”的文档
"title":{
"query": "文雅"
}
}
}
]
}
}
}
在默认情况下,各个子查询的boost值为1,也就是说上述的两个match查询是平等的。文档的分值等于两个match相关性分数之和。执行上述DSL后结果如下:
{
…
"hits" : {
…
"hits" : [ //匹配的文档列表
{
…
"_id" : "005",
"_score" : 1.7743526,
"_source" : {
"title" : "文雅精选酒店",
…
}
},
{
…
"_id" : "001",
"_score" : 1.6631467,
"_source" : {
"title" : "文雅酒假日酒店",
…
}
},
{
…
"_id" : "002",
"_score" : 1.0924089,
"_source" : {
"title" : "金都嘉怡酒店",
…
}
},
{
…
"_id" : "003",
"_score" : 1.0924089,
"_source" : {
"title" : "金都欣欣酒店",
…
}
},
{
…
"_id" : "004",
"_score" : 1.0924089,
"_source" : {
"title" : "金都家至酒店",
…
}
}
]
}
}
通过上述结果可以看到,“金都”品牌的酒店文档的打分相对低一些,如果想对“金都”品牌的酒店进行推广,也就是提升标题中包含“金都”这些文档的排序分值,则可以设定“金都”的match查询的boost值更高一些,例如下面的DSL:
GET /hotel/_search
{
"query": {
"bool": {
"should": [
{
"match": {
"title":{
"query": "金都",
"boost": 2 //设置“金都”匹配的权重更高一些
}
}
},
{
"match": {
"title":{
"query": "文雅"
}
}
}
]
}
}
}
执行上述DSL后,ES的返回结果如下:
{
…
"hits" : {
…
"hits" : [ //匹配的文档列表
{
…
"_id" : "002",
"_score" : 2.1848178,
"_source" : {
"title" : "金都嘉怡酒店",
…
}
},
{
…
"_id" : "003",
"_score" : 2.1848178,
"_source" : {
"title" : "金都欣欣酒店",
…
}
},
{
"_index" : "hotel",
"_type" : "_doc",
"_id" : "004",
"_score" : 2.1848178,
"_source" : {
"title" : "金都家至酒店",
…
}
},
{
…
"_id" : "005",
"_score" : 1.7743526,
"_source" : {
"title" : "文雅精选酒店",
…
}
},
{
…
"_id" : "001",
"_score" : 1.6631467,
"_source" : {
"title" : "文雅酒假日酒店",
…
}
}
]
}
}
如上所示,设定的boost值提升了标题中包含“金都”的文档的得分。现在我们来思考一下上述match查询的打分细节,在默认情况下,文档的boost为BM25中的k1+1,因为在默认情况下k1=1.2,所以boost=k1+1=1.2+1=2.2。当在match查询中设置boost为2时,匹配该查询文档的最终boost=(k1+1)×2=(1.2+1)×2=4.4。
title字段使用标准分析器,设置“金都”这个match查询的boost值为2后,在查询时“金都”被切分成“金”“都”,这两个切分的字在BM25查询中的最终boost值都为4.4。
因此设置match查询的boost参数可以直接影响BM25的评分机制,从而影响整体结果的相关度。更近一步说,设置boost参数为某个值后并不是将查询命中的文档分数乘以该值,而是将BM25中的boost参数乘以该数值。
在Java客户端中使用boost参数时,只需要在QueryBuilder实例中调用boost()方法即可,以下Java代码和上面的DSL在搜索结果上是等效的:
public void getBoostSearch() {
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder(
//构建“金都”的match查询
MatchQueryBuilder matchQueryBuilder1 = QueryBuilders.matchQuery
("title", "金都");
//设置boost值为2
matchQueryBuilder1.boost(2);
//构建“文雅”的match查询,boost使用默认值
MatchQueryBuilder matchQueryBuilder2 = QueryBuilders.matchQuery
("title", "文雅");
BoolQueryBuilder boolQueryBuilder=QueryBuilders.boolQuery();
//将“金都”的match查询添加到布尔查询中
boolQueryBuilder.should(matchQueryBuilder1);
//将“文雅”的match查询添加到布尔查询中
boolQueryBuilder.should(matchQueryBuilder2);
searchSourceBuilder.query(boolQueryBuilder); //设置查询为布尔查询
searchRequest.source(searchSourceBuilder); //设置查询请求
printResult(searchRequest); //打印搜索结果
}
1.2 boosting查询
虽然使用boost值可以对查询的权重进行调整,但是仅限于term查询和类match查询。有时需要调整更多类型的查询,如搜索酒店时,需要将房价低于200的酒店权重降低,此时可能需要用到range查询,但是range查询不能使用boost参数,这时可以使用ES的boosting查询进行封装。
ES的boosting查询分为两部分,一部分是positive查询,代表正向查询,另一部分是negative查询,代表负向查询。可以通过negative_boost参数设置负向查询的权重系数,该值的范围为0~1。最终的文档得分为:正向匹配值+负向匹配值×negative_boost。先来看看使用原始查询时的搜索排序状态,以下DSL为搜索“金都”查询:
GET /hotel/_search
{
"query": { //普通的match搜索
"match": {
"title": "金都"
}
}
}
搜索结果如下:
{
…
"hits" : {
…
"max_score" : 1.0924089,
"hits" : [ //匹配的文档列表
{
…
"_id" : "002",
"_score" : 1.0924089,
"_source" : {
"title" : "金都嘉怡酒店",
"price" : 337.0,
"full_room" : true
}
},
{
…
"_id" : "003",
"_score" : 1.0924089,
"_source" : {
"title" : "金都欣欣酒店",
"price" : 200.0,
"full_room" : true
}
},
{
…
"_id" : "004",
"_score" : 1.0924089,
"_source" : {
"title" : "金都家至酒店",
"price" : 500.0,
"full_room" : false
}
}
]
}
}
可以看到,上面的搜索结果只是按照标题相关度进行了打分,其中,标价为200元的“金都欣欣酒店”排在第二位,如果希望它排在最后该怎么做呢?下面的DSL将对房价低于200元的酒店进行降权处理:
GET /hotel/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": {
"query": "金都"
}
}
},
"negative": { //设置负面查询
"range": {
"price": {
"lte": 200
}
}
},
"negative_boost": 0.2 //设置降低的权重值
}
}
}
执行上述DSL后,ES搜索结果如下:
{
…
"hits" : {
"total" : {
"value" : 3,
"relation" : "eq"
},
"max_score" : 1.0924089,
"hits" : [ //匹配的文档列表
{
…
"_id" : "002",
"_score" : 1.0924089,
"_source" : {
"title" : "金都嘉怡酒店",
"price" : 337.0,
"full_room" : true
}
},
{
…
"_id" : "004",
"_score" : 1.0924089,
"_source" : {
"title" : "金都家至酒店",
"price" : 500.0,
"full_room" : false
}
},
{
…
"_id" : "003",
"_score" : 0.21848178,
"_source" : {
"title" : "金都欣欣酒店",
"price" : 200.0,
"full_room" : true
}
}
]
}
}
通过上面的结果可知,对房价低于200元的酒店进行降权处理后,目标酒店已经排在了最后面。
如果在以上结果基础上要求降低满房酒店的权重该怎么做呢?我们可以将在negative中的查询进行扩展:
GET /hotel/_search
{
"query": {
"boosting": {
"positive": {
"match": {
"title": {
"query": "金都"
}
}
},
"negative": { //扩展negative查询,增加更多条件
"bool": {
"should": [
{
"range": {
"price": {
"lte": 200
}
}
},
{
"term": {
"": {
"value": "true"
}
}
}
]
}
},
"negative_boost": 0.2
}
}
}
在以上查询中,使用布尔查询将“房价低于200元”和“满房状态”的酒店封装到了一个布尔查询中然后放入negative查询中,执行上述DSL后,搜索结果如下:
{
…
"hits" : {
…
"hits" : [ //匹配的文档列表
{
…
"_id" : "004",
"_score" : 1.0924089,
"_source" : {
"title" : "金都家至酒店",
"price" : 500.0,
"full_room" : false
}
},
{
…
"_id" : "002",
"_score" : 0.21848178,
"_source" : {
"title" : "金都嘉怡酒店",
"price" : 337.0,
"full_room" : true
}
},
{
…
"_id" : "003",
"_score" : 0.21848178,
"_source" : {
"title" : "金都欣欣酒店",
"price" : 200.0,
"full_room" : true
}
}
]
}
}
如上所示,通过使用negative进行调权,“房价低于200元”和“满房状态”的酒店都排在了后面。
在Java客户端中使用boosting查询:
public void getBoostingSearch() {
//创建搜索请求
SearchRequest searchRequest = new SearchRequest("hotel");
SearchSourceBuilder searchSourceBuilder = new SearchSourceBuilder();
//构建“金都”的match查询
MatchQueryBuilder matchQueryBuilder = QueryBuilders.matchQuery
("title", "金都");
//构建价格的range查询
QueryBuilder rangeQueryBuilder = QueryBuilders.rangeQuery("price").
lte("200");
//构建满房的term查询
QueryBuilder termQueryBuilder = QueryBuilders.termQuery("full_room",
true);
BoolQueryBuilder boolQueryBuilder=QueryBuilders.boolQuery();
//将价格的range查询添加到布尔查询中
boolQueryBuilder.should(rangeQueryBuilder);
//将满房的term查询添加到布尔查询中
boolQueryBuilder.should(termQueryBuilder);
//构建boosting查询,将match查询作为正向查询,布尔查询作为负向查询
BoostingQueryBuilder boosting=QueryBuilders.boostingQuery(matchQuery
Builder,boolQueryBuilder);
boosting.negativeBoost(0.2f); //设置负向查询的权重系数
searchSourceBuilder.query(boosting); //设置查询为boosting查询
searchRequest.source(searchSourceBuilder); //设置查询请求
printResult(searchRequest); //打印搜索结果
}
2 Function Score查询简介
例如,一个酒店搜索引擎,不仅需要考虑查询词和酒店名称的匹配程度,而且还需要评估酒店的好评率、地理位置和设施服务等诸多因素。ES提供了Function Score查询模式,用户可以借助该查询模式使用多种因素来影响打分逻辑。
2.1 简单函数
我们在第4章中简要介绍了在Function Score查询中可以使用random_score随机函数对文档进行打分,在Function Score查询中还提供了其他打分函数,如表6.1所示。
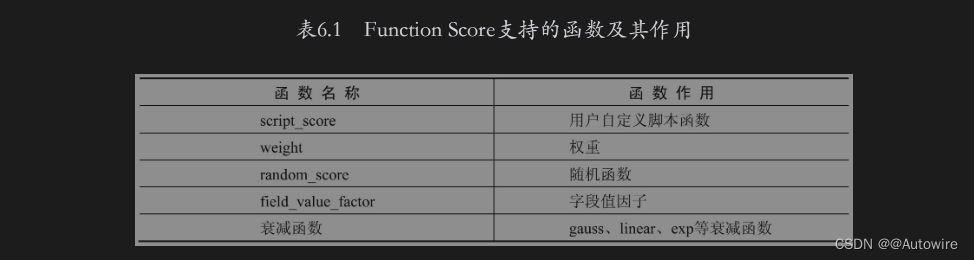
在这些函数中,比较灵活的是script_score函数,它支持用户使用脚本自定义评分函数。在函数体中,既可以使用原有的score值进行计算,也可以使用文档的某个字段值的一些运算结果来影响评分的值。下面使用script_score函数将原有评分和好评数相乘的结果作为最后的评分,示例如下:
GET /hotel/_search
{
"query": {
"function_score": {
"query": { //定义查询条件
"match_all": {} //匹配所有文档
},
"functions": [ //可以定义多个打分函数
{
"script_score": { //使用脚本打分
"script": "_score * doc[' favourable_comment'].value"
}
}
]
}
}
}
需要注意的是,script_score子句中的结果必须大于或者等于0,不能为负数,否则,ES将会报错。以下是script_score取值为原有评分和差评数的乘积再乘以-1的查询示例:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match_all": {} //匹配所有文档
},
"functions": [
{
"script_score": {
//乘以-1使得分为负数
"script": "_score * -1*doc['negative_comment'].value"
}
}
]
}
}
}
系统报错信息如下:
{
"error" : {
"root_cause" : [
{ //打分函数返回负数时ES报错
"type" : "illegal_argument_exception",
"reason" : "script score function must not produce negative scores,
but got: [-10.0]"
}
],
"type" : "search_phase_execution_exception",
…
},
"status" : 400 //返回的状态码
}
另外,还可以使用params为script_score传递参数。在下面的示例中,将原有评分和评论进行相乘,然后乘以p,并将得到的结果作为最后的评分。其中,p的值是通过params中的传递参数得到的。
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match_all": {} //匹配所有文档
},
"functions": [
{
"script_score": {
"script": {
"params": { //传递p参数的值为0.5
"p": 0.5
},
//在打分函数的计算中使用p参数
"source": "_score*doc['favourable_comment'].value*params.p"
}
}
}
]
}
}
}
weight函数提供的是一个系数,最终的得分等于对原有评分乘以这个系数。例如,对命中的文档原有评分乘以10:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match_all": {} //匹配所有文档
},
"functions": [
{ //定义weight函数
"weight": 10 //定义weight函数中的权重值
}
]
}
}
}
random_score产生0~1的随机小数,但是不包括1。在默认情况下,该随机函数使用的随机种子为文档_id,可以通过seed参数指定随机数种子。例如,使用随机函数的简单形式对文档打分:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match_all": {} //匹配所有文档
},
"functions": [
{
"random_score": {} //使用随机函数打分
}
]
}
}
}
如果希望文档中的某些字段对排序产生影响,除了使用script_score函数以外,也可以使用字段值因子函数field_value_factor,该函数可以省去编写脚本代码的麻烦。在下面的例子中以原有评分和好评数相乘的结果作为最后的评分:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match_all": {} //匹配所有文档
},
"functions": [
{
"field_value_factor": {
//定义field_value_factor中的field参数为字段favourable_comment, 则ES将原有分数乘以字段favourable_comment的值作为文档最终得分
"field": "favourable_comment"
}
}
]
}
}
}
在field_value_factor中还可以使用函数进一步对字段的因子进行处理。例如使用原有评分和好评数的平方根进行相乘的结果作为最后的评分:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"functions": [
{
"field_value_factor": {
"field": "favourable_comment",
//使用原有评分和好评数的平方根进行相乘的结果作为最后的评分
"modifier": "sqrt"
}
}
]
}
}
}
2.2 函数计算关系
如果在Function Score的functions子句中有多个函数,则可以使用score_mode参数定义各个函数值之间的计算关系,当前支持的计算关系如表6.2所示。
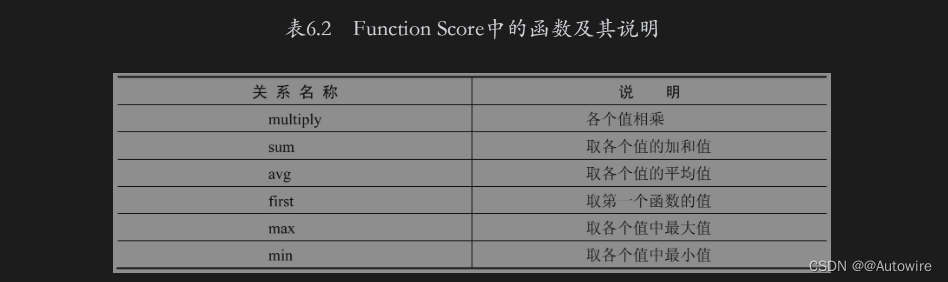
score_mode的默认值为multiply,即最终的分数默认取各个函数的值相乘的结果。在下面的示例中score_mode取各个值的加和值:
GET /hotel/_search
{
"query": {
"function_score": {
"query": {
"match_all": {}
},
"score_mode": "sum", //设置score_mode为sum,则最终得分取各个值的加和值
"functions": [
{
"field_value_factor": {
"field": "favourable_comment",
"modifier": "sqrt"
},
"random_score": {}
}
]
}
}
}
2.3 衰减函数
在对文档进行打分时,希望在某个值域附近进行衰减打分。例如当搜索酒店时,酒店距离当前位置越近越好。假定距离当前位置1km范围内的酒店都可以接受,如果使用过滤器将超过1km的酒店排除掉,这种做法未免有些“生硬”。假设一个酒店距离当前位置刚好是1.1km,其好评度也不错,那么是可以考虑一下该酒店的。所以我们希望酒店最好距离当前位置在1km范围内,如果超过1km,酒店的评分应该随着距离的增大有一个明显的下降趋势。
为了解决这类问题,可以在Function Score查询中使用衰减函数。ES提供了3个衰减函数,分别为gauss、linear和exp,这3个函数的区别主要是衰减曲线形状不同,但是它们的用法和参数设置都是一样的。如图6.4所示为以年龄字段为例展示的这3个函数的衰减曲线图像。
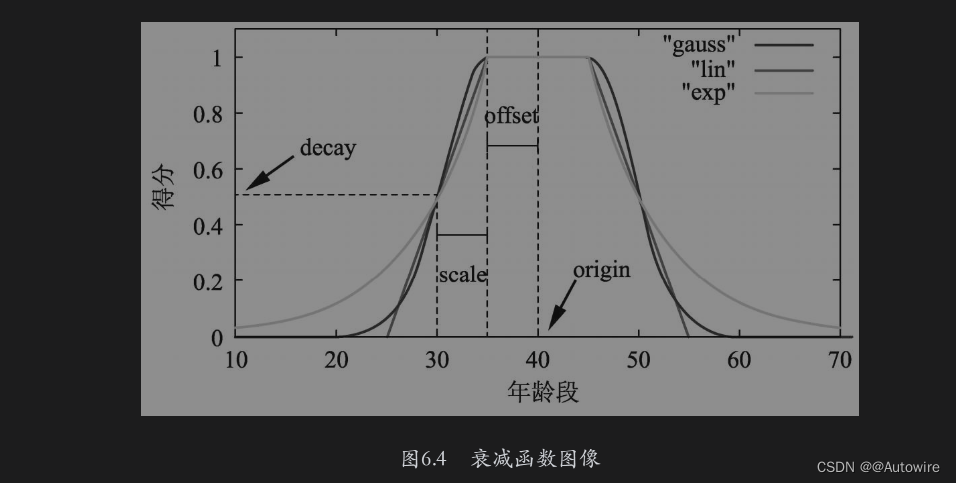
衰减函数可以用于数值型、日期型和地理位置型数据,需要用户设置一个中心值,如果实际值偏离中心值,无论大于中心值还是小于中心值,文档的分数都将降低。
由图6.4可知,gauss图像有点类似于钟摆,起初,其衰减值随着年龄的增大缓慢增大,然后到达某个区域后急速增大,直到到达某个阈值后又急速减小,最后又缓慢减小;linear的函数曲线是一条直线,其衰减值随着年龄的增大而线性增大,直到到达某个阈值后随着年龄的增大而线性减小;exp是一种指数衰减,它的衰减速率比gauss要激烈一些。
使用衰减函数时,可以设定如下参数:
·origin:用于设定计算距离的原点,该参数的值必须和字段类型相对应。
·offset:用于设定距离原点多远范围内的数据将享有和原点一样的衰减值,其默认值为0。
·scale:衰减曲线的一个锚点,即定义到该点的值,其衰减的值为某个值(即为decay的值)。这个锚点横坐标值的定义为原点+offset+scale,纵坐标为decay参数的值。
·decay:和scale配套使用,用于设定锚点的纵坐标,即衰减值,其默认值为0.5。
下面用一个酒店搜索的实例来介绍衰减函数的使用,先来建立酒店索引:
PUT /hotel
{
"mappings": {
"properties": {
"title": { //定义title字段和类型
"type": "text"
},
"location": { //定义location字段和类型
"type": "geo_point"
}
}
}
}
为方便介绍,在索引中写入一些酒店数据,这些酒店都是北京天安门附近的酒店:
POST /_bulk
{"index":{"_index":"hotel","_id":"001"}}
{"title": "大前门瀚海酒店","location": {"lat": 39.905194, "lon": 116.400029}}
{"index":{"_index":"hotel","_id":"002"}}
{"title": "磁器口美乐酒店","location": {"lat": 39.895314, "lon": 116.426241}}
{"index":{"_index":"hotel","_id":"003"}}
{"title": "天坛望都酒店","location": {"lat": 39.88892, "lon": 116.428415}}
{"index":{"_index":"hotel","_id":"004"}}
{"title": "南海公园酒店","location": {"lat": 39.918034, "lon": 116.395932}}
{"index":{"_index":"hotel","_id":"005"}}
{"title": "国贸天地酒店","location": {"lat": 39.914423, "lon": 116.462227}}
假设当前位置是天安门,经纬度坐标为[116.4039,39.915143],需求为搜索附近5km内的酒店,其中最佳距离是1km,超过1km的酒店打分需要按照距离进行衰减,其中3km的时候酒店衰减得分为0.4,则搜索的DSL如下:
GET /hotel/_search
{
"query": {
"function_score": {
"query": { //设置搜索范围为距离中心点5km
"geo_distance":{
"distance":"5km",
"location":{ "lat": 39.915143, "lon": 116.4039 }
}
},
"functions": [
{
"gauss": { //设置衰减函数为gauss
"location": {
"origin": { "lat": 39.915143, "lon": 116.4039 },
//最佳距离为1km,在1km范围内的所有酒店得分均相同
"offset": "1km",
"scale": "2km", //设定固定的衰减距离
"decay": 0.4 //设置距离中心点3km时的衰减得分为0.4
}
}
}
]
}
}
}
执行上述DSL,搜索结果如下:
{
…
"hits" : {
…
"hits" : [ //返回的文档列表
{
…
"_id" : "004",
"_score" : 1.0,
"_source" : {"title" : "南海公园酒店","location" : {…}}
},
{
…
"_id" : "001",
"_score" : 0.99454683,
"_source" : {"title" : "大前门瀚海酒店","location" : {…}}
},
{
…
"_id" : "002",
"_score" : 0.43195635,
"_source" : {"title" : "磁器口美乐酒店","location" : {…}}
},
{
…
"_id" : "003",
"_score" : 0.21555501,
"_source" : {"title" : "天坛望都酒店","location" : {…}}},
{
…
"_id" : "005",
"_score" : 0.026788887,
"_source" : {"title" : "国贸天地酒店","location" : {…}}
}
]
}
}
通过以上结果大体上可以看出一些规律:距离天安门越近的酒店得分越高,反之则得分越低。为了能直观地看到更细粒度的结果,需要给出实际距离,因此我们使用普通的距离查询,并且将查询结果直接按照距离降序排列:
GET /hotel/_search
{
"query": {
"geo_distance": { //在距离中心点5km范围内搜索酒店
"distance": "5km",
"location": {
"lat": 39.915143,
"lon": 116.4039
}
}
},
"sort": [
{
"_geo_distance": { //按照与中心点的距离进行排序
"location": {
"lat": 39.915143,
"lon": 116.4039
},
"unit": "km", //排序使用的距离计量单位
"order": "asc" //升序排列
}
}
]
}
执行上述DSL,ES的返回结果如下:
{
…
"hits":{
…
"hits":[ //返回的文档列表
{
…
"_id":"004",
"_score":null,
"_source":{"title":"南海公园酒店","location":{…}},
"sort":[0.7517456062542669] //文档的排序值:酒店与中心点的距离
},
{
…
"_id":"001",
"_score":null,
"_source":{ "title":"大前门瀚海酒店","location":{…}},
"sort":[1.154501237598761] //文档的排序值:酒店与中心点的距离
},
{
"_index":"hotel",
"_type":"_doc",
"_id":"002",
"_score":null,
"_source":{"title":"磁器口美乐酒店","location":{…}},
"sort":[2.91428143818939] //文档的排序值:酒店与中心点的距离
},
{
…
"_id":"003",
"_score":null,
"_source":{"title":"天坛望都酒店","location":{…}},
"sort":[3.5882267893003497] //文档的排序值:酒店与中心点的距离
},
{
…
"_id":"005",
"_score":null,
"_source":{"title":"国贸天地酒店","location":{…}},
"sort":[4.975151875412991] //文档的排序值:酒店与中心点的距离
}
]
}
}
将上面的两个结果结合起来看,南海公园酒店距离天安门小于1km范围内,符合offset值的设定,因此其得分为1;大前门瀚海酒店距离天安门在1km和2km之间,并且非常接近1km,因此其得分虽然得到衰减,但只是轻微衰减到0.99左右;磁器口美乐酒店距离天安门2.91km,该值已经非常接近锚点值,因此其得分为0.43左右,更加接近decay的值(其值为0.4);天坛望都酒店和天安门的距离为3.5km,已经超过3km,因此其得分迅速衰减到0.22左右;最后的国贸天地酒店,它和天安门的距离已经接近5km,因此其得分急速衰减到0.03左右。