目录
一, 搜索
1,传统搜索
2,Map和Set模型
二, Map的使用
1,Map接口的继承及实现图
2,Map接口的使用
3,TreeMap和HashMap的使用和对比
1,TreeMap
代码示例
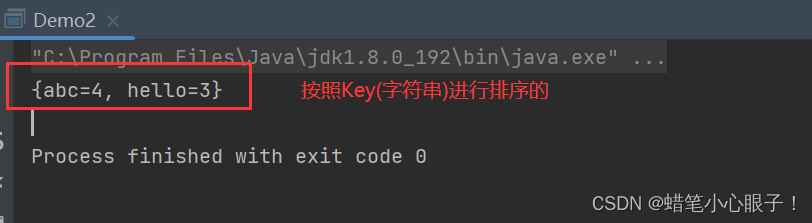
map中插入的数据按照key进行排序
map中插入的数据必须具有可比较性(或者实现了比较器相关接口)
map中插入的值必须是唯一的,否则会进行覆盖
通过Set> entrySet() 方法对map中的键值对进行遍历
将Map中的value全部分离出来存放在Collection中
2,HashMap
代码示例
3,TreeMap和HashMap的对比
三, Set的使用
1,Set接口的继承及实现图
2,Set接口的使用
3,TreeSet和HashSet的使用和对比
1,TreeSet
代码示例
Set存入的Key必须是唯一的,存入重复的Key会自动去重
Set中不能插入为null的数据,否则会报空指针异常的错误
Set中插入的Key必须具有可比较性
2,HashSet
四, 总结
一, 搜索
1,传统搜索
- 直接遍历:时间复杂度是O(N),元素如果比较多的情况下效率会非常慢
- 二分查找:时间复杂度是O(logN),但是搜索的前提是序列必须有序
这两种排序比较适合静态类型的查找(给定区间内的元素进行查找),一般不会对区间上的序列进行插入和删除了,而现实中的查找比如:
- 根据姓名查找考试成绩
- 通讯录,根据姓名查询联系方式
- 不重复集合,需要先搜索关键字是否已经在集合中
这三种在查找时进行一些插入和删除的操作称为动态查找,上述的直接遍历和二分查找的方式就不太适合了,本篇博客介绍的Map和Set集合就是一种专门用来动态查找的集合容器.
2,Map和Set模型
一般把搜索的数据称为关键字(Key),和关键字对应的称为值(Value),将其称为Key-Value的键值对,所有模型有两种:
- 纯Key模型:
- 有一个英文词典,快速查找一个单词是否在词典中
- 快速查找某个名字在不在通讯录中
- Key-Value模型:
- 统计文件中每个单词出现的次数,统计结果是每个单词都与其对应的次数:<单词,单词出现的次数>
- 梁山好汉的江湖绰号:每个好汉都有自己的江湖绰号
Map中存储的就是Key-Value的键值对,Set中只存储了Key
二, Map的使用
Map是一个接口,该接口没有继承自Collection,该类中存储的是<K,V>结构的键值对,并且K一定是唯一的,不能重复.
1,Map接口的继承及实现图
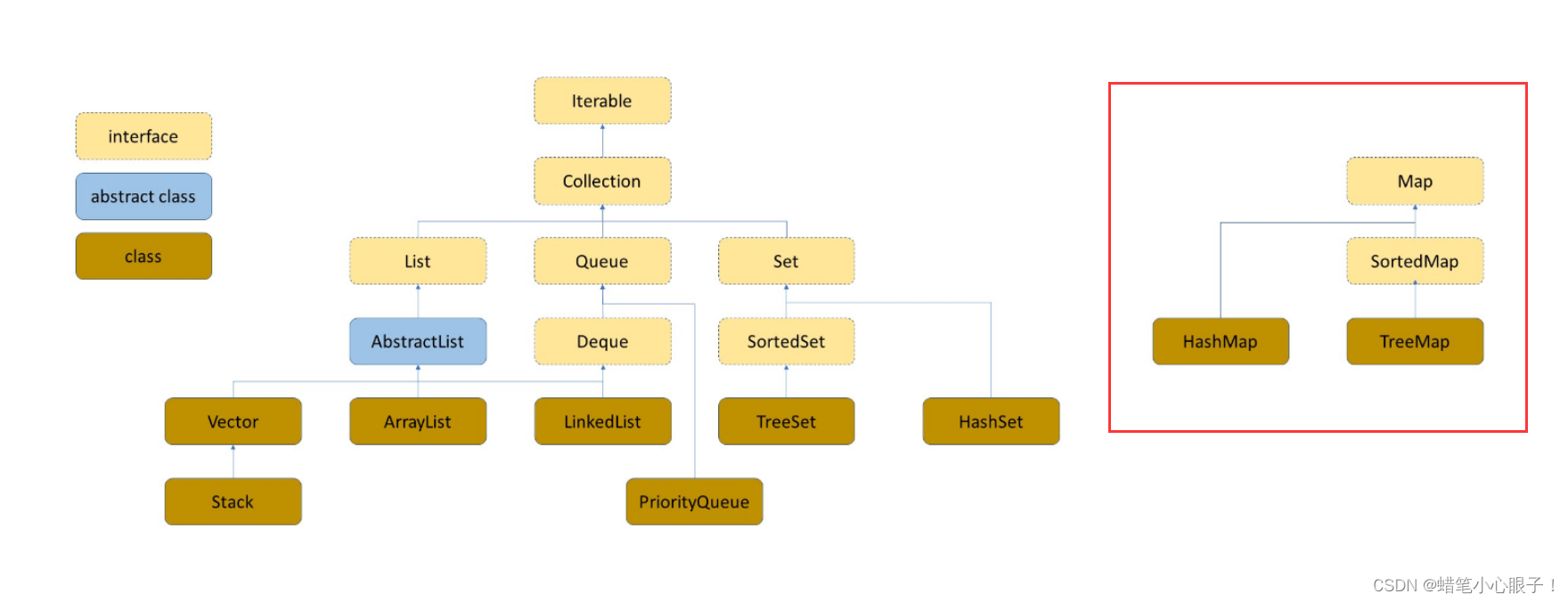
- Map接口的实现类有两个,分别是TreeMap和HashMap
- TreeMap类实现了SortedMap接口(所以TreeMap中存入的key必须是可比较的,后面会说)
2,Map接口的使用
| 方法 | 解释 |
|
V
get
(Object key)
|
返回
key
对应的
value
|
|
V
getOrDefault
(Object key, V defaultValue)
|
返回
key
对应的
value
,
key
不存在,返回默认值
|
|
V
put
(K key, V value)
|
设置
key
对应的
value
|
|
V
remove
(Object key)
|
删除
key
对应的映射关系
|
|
Set<K>
keySet
()
|
返回所有
key
的不重复集合
|
|
Collection<V>
values
()
|
返回所有
value
的可重复集合
|
|
Set<Map.Entry<K, V>>
entrySet
()
|
返回所有的
key-value
映射关系
|
|
boolean
containsKey
(Object key)
|
判断是否包含
key
|
|
boolean
containsValue
(Object value)
|
判断是否包含
value
|
注意:
Map接口没有继承Iterable接口,所以使用Map的对象不能直接进行遍历,需要先将其转换成Set对象再进行遍历,Map也提供了相应的方法对这种集合做特殊处理,就是Set<Map.Entry<K, V>> entrySet() 方法,Map.Entry<K, V>是Map内部实现的,用来存放<key,value>键值对映射关系的内部类,该内部类中主要提供了<key,value>的获取,value的设置以及key的比较方式:
| 方法 | 解释 |
|
K
getKey
()
|
返回
entry
中的
key
|
|
V
getValue
()
|
返回
entry
中的
value
|
|
V setValue(V value)
|
将键值对中的
value
替换为指定
value
|
小结:
- Map是一个接口,不能直接实例化对象,如果实例化对象只能实例化其实现类TreeMap或者HashMap
- Map中存放键值对的Key是唯一的,value是可以重复的
- Map中的Key可以全部分离出来,存储到Set中尽显访问(因为key不能重复,Set要求Key不能重复)
- Map中的Value可以全部分离出来,存储在Collection的任何一个子集合中
- Map中键值对的Key不能直接修改,value可以修改,同时存储两个相同的key的键值对时,后存储入Map的会覆盖之前存储入Map中的数据
3,TreeMap和HashMap的使用和对比
1,TreeMap
TreeMap的底层是红黑树(可以把它想象成比较复杂,性能更加优秀的搜索树),我们联想二叉搜索树的一些性能就可以理解TreeMap的一些性能了:
- 二叉搜索树在插入的时候,对于已经在树中存在的数据是无法进行插入的,所以TreeMap中无法插入两个相同Key值的键值对
- 二叉搜索树的左子树的数据永远小于相同根节点的右子树的数据,可知他是一棵有序树,TreeMap中的数据也是有序的,所以插入的数据必须具有可比较性,否则会报错(TreeMap是基于Key进行比较的)
代码示例
map中插入的数据按照key进行排序
public static void main(String[] args) {
Map<String,Integer> map = new TreeMap<>();
map.put("hello",3);
map.put("abc",4);
System.out.println(map);
}
map中插入的数据必须具有可比较性(或者实现了比较器相关接口)
//定义一个Student类 不实现比较器接口
class Student {
}
public static void main(String[] args) {
Map<Student,Integer> map = new TreeMap<>();
map.put(new Student(),3);
}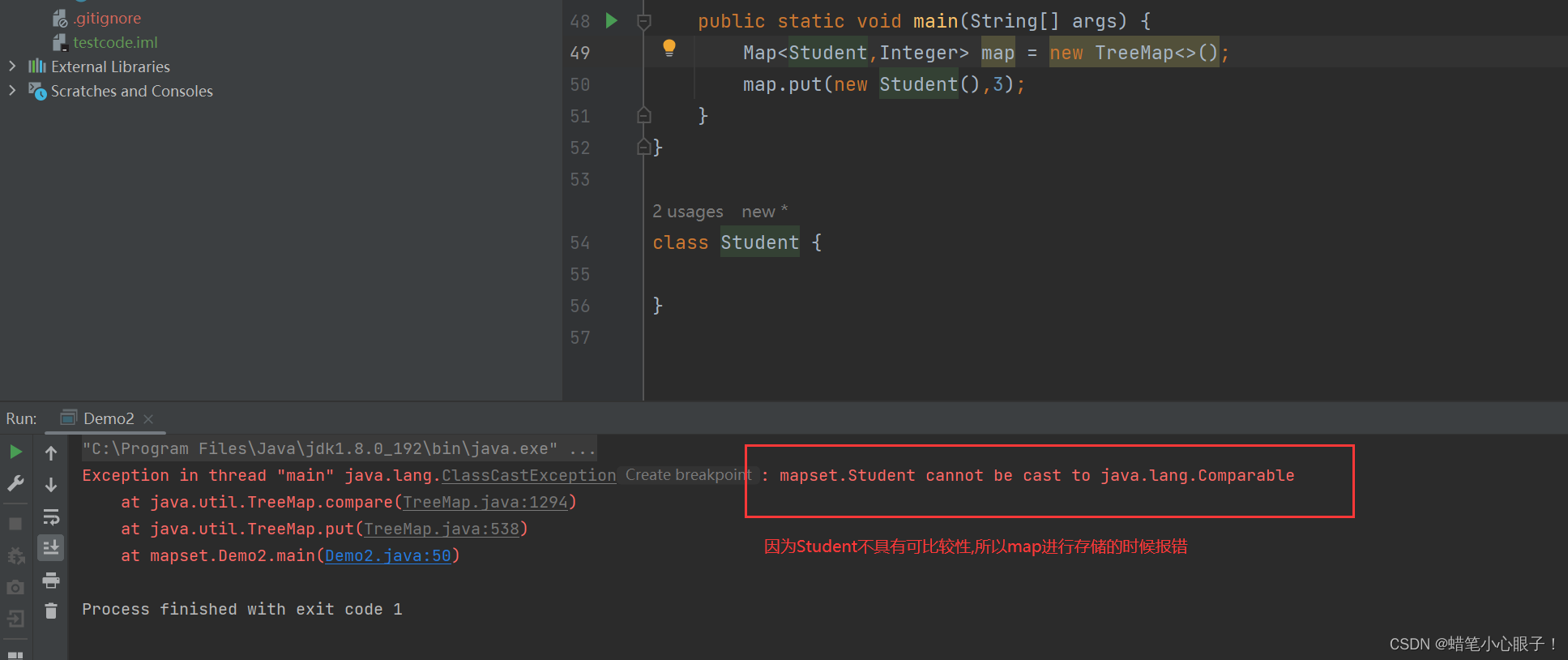 map中插入的值必须是唯一的,否则会进行覆盖
map中插入的值必须是唯一的,否则会进行覆盖
public static void main(String[] args) {
Map<String,Integer> map = new TreeMap<>();
map.put("hello",3);
map.put("hello",4);
System.out.println(map);
}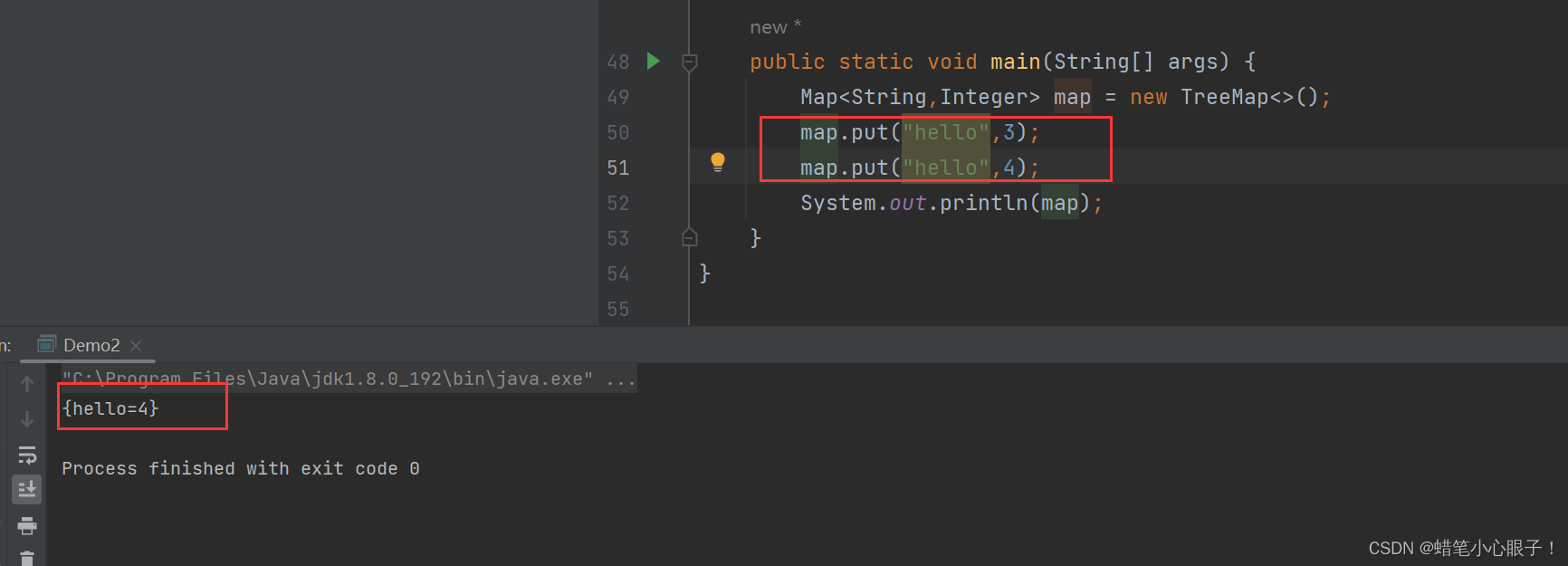 通过Set<Map.Entry<K, V>> entrySet() 方法对map中的键值对进行遍历
通过Set<Map.Entry<K, V>> entrySet() 方法对map中的键值对进行遍历
public static void main(String[] args) {
Map<String,Integer> map = new TreeMap<>();
map.put("hello",3);
map.put("abc",4);
map.put("def",2);
Set<Map.Entry<String, Integer>> entries = map.entrySet();
for (Map.Entry<String, Integer> x: entries) {
System.out.println("key: " + x.getKey() + " 出现了: " + x.getValue() + "次!");
}
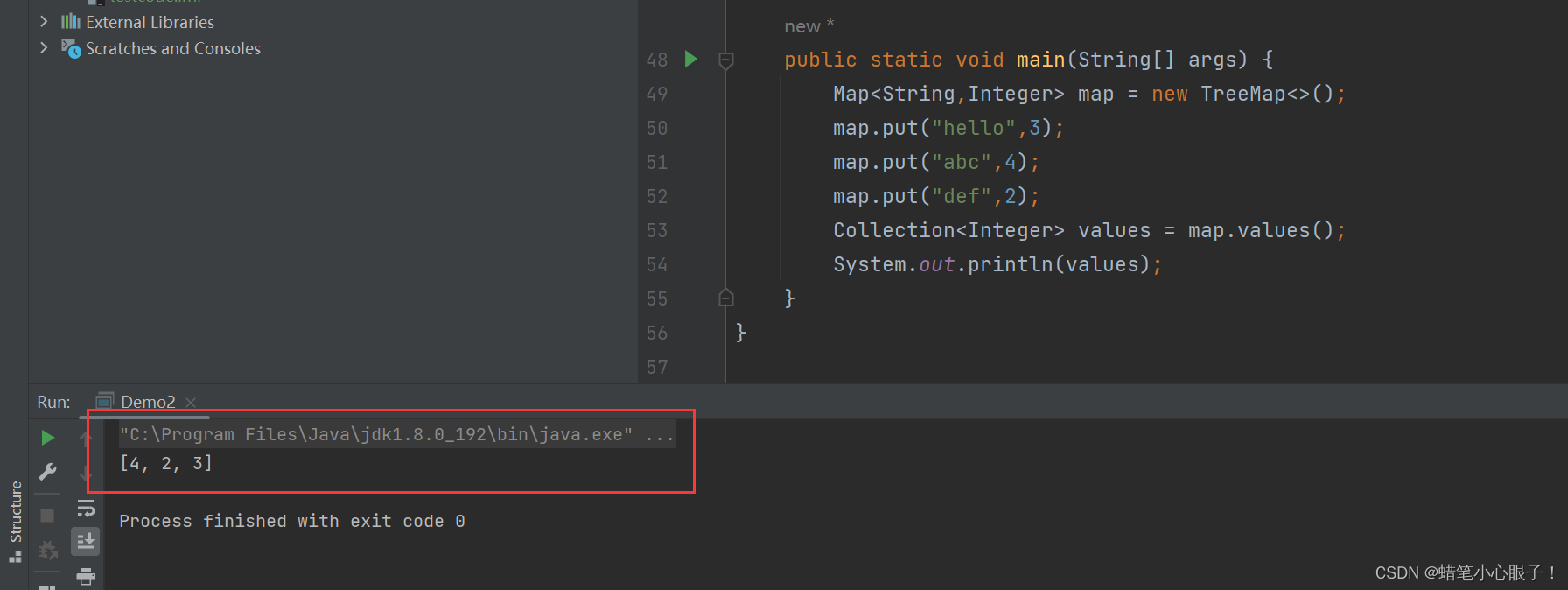
}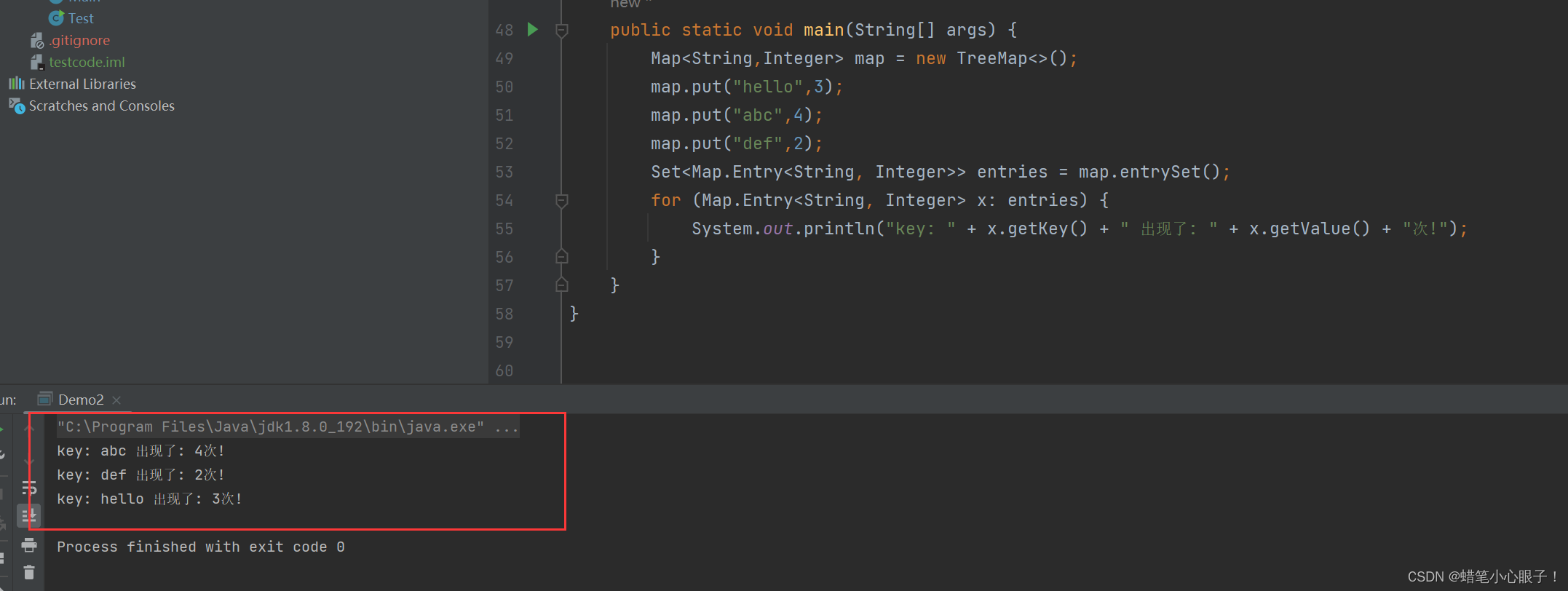 将Map中的value全部分离出来存放在Collection中
将Map中的value全部分离出来存放在Collection中
public static void main(String[] args) {
Map<String,Integer> map = new TreeMap<>();
map.put("hello",3);
map.put("abc",4);
map.put("def",2);
Collection<Integer> values = map.values();
System.out.println(values);
}
2,HashMap
HashMap的底层是一个哈希桶(数组+链表/红黑树)的结构,查询的时间复杂度是O(1),所以一般HashMap的效率比较高,由于HashMap这个类并没有实现SortedMap这个接口,所以不要求插入的数据中的Key具有可比较性
代码示例
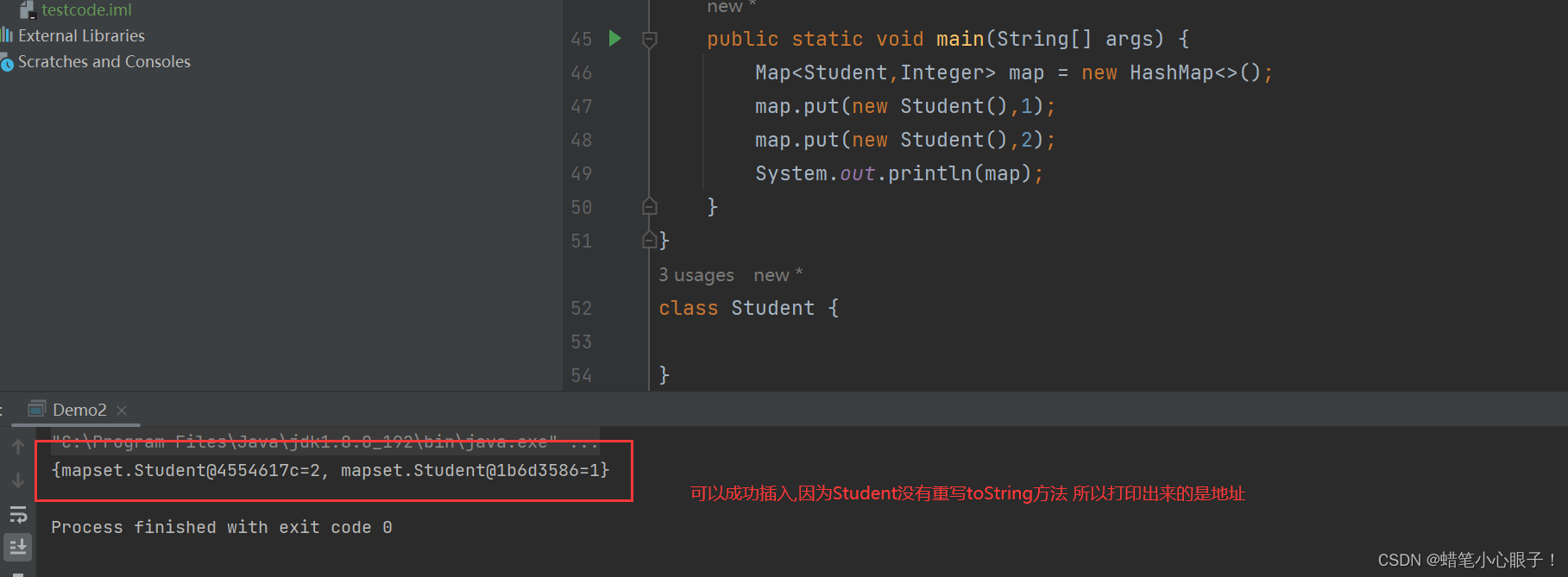
HashMap和TreeMap大部分的方法相同,可以参照TreeMap的代码进行练习,这里只演示HashMap可以插入不需要具有可比较性的数据的代码
class Student {
}
public static void main(String[] args) {
Map<Student,Integer> map = new HashMap<>();
map.put(new Student(),1);
map.put(new Student(),2);
System.out.println(map);
}
3,TreeMap和HashMap的对比
|
Map
底层结构
|
TreeMap
|
HashMap
|
|
底层结构
|
红黑树
|
哈希桶
|
|
插入
/
删除
/
查找时间
复杂度
| O(logN) | O(1) |
|
是否有序
|
关于
Key
有序
|
无序
|
|
线程安全
|
不安全
| 不安全 |
|
插入
/
删除
/
查找区别
|
需要进行元素比较
|
通过哈希函数计算哈希地址
|
|
比较与覆写
|
key
必须能够比较,否则会抛出 ClassCastException异常
|
自定义类型需要覆写
equals
和 hashCode方法
|
|
应用场景
|
需要
Key
有序场景下
|
Key
是否有序不关心,需要更高的时间性能
|
三, Set的使用
Set与Map主要的不同有两点:Set是继承自Collection的接口类,Set中只存储了Key
1,Set接口的继承及实现图
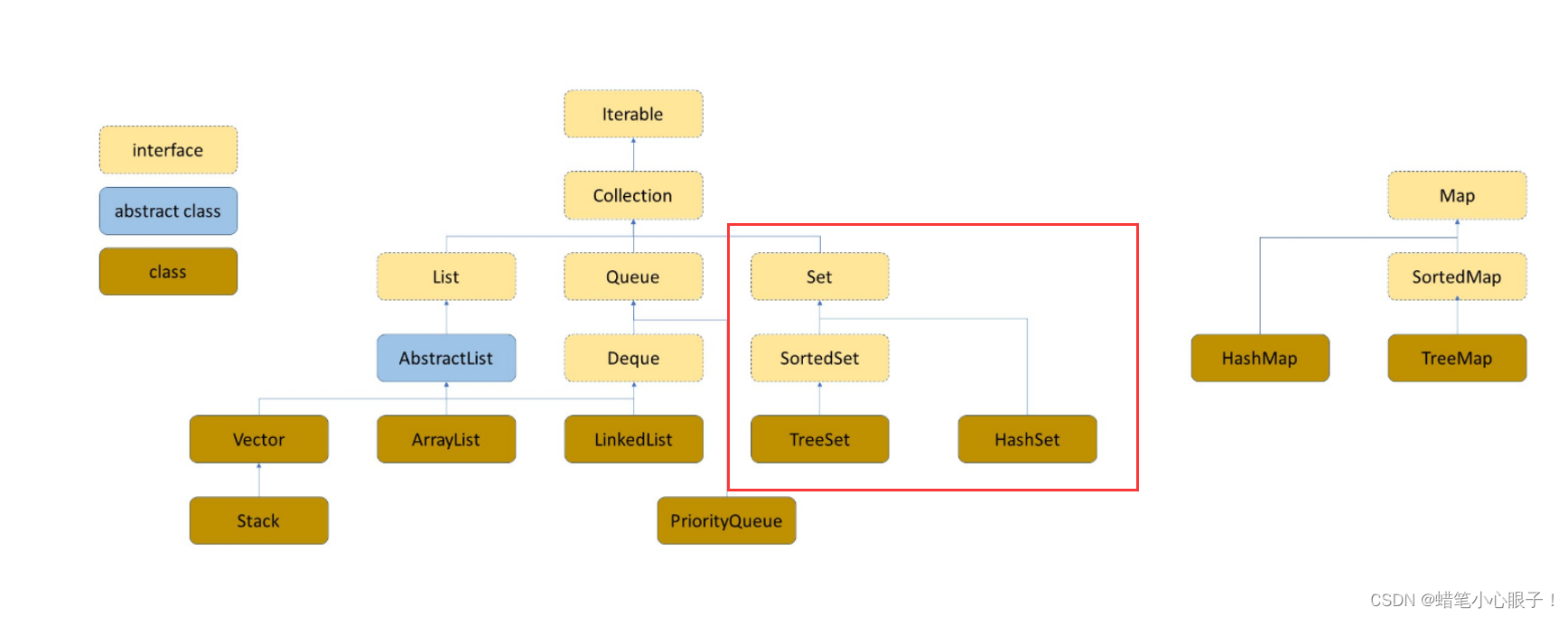
- Set接口的实现类有两个,分别是TreeSet和HashSet
- TreeSet类实现了SortedSet接口,所以TreeSet中存入的key必须是可比较的
- Set实现了Iterable接口,所以可以对Set进行遍历
2,Set接口的使用
| 方法 | 解释 |
|
boolean
add
(E e)
|
添加元素,但重复元素不会被添加成功
|
|
void
clear
()
|
清空集合
|
|
boolean
contains
(Object o)
|
判断
o
是否在集合中
|
|
Iterator<E>
iterator
()
|
返回迭代器
|
|
boolean
remove
(Object o)
|
删除集合中的
o
|
|
int size()
|
返回
set
中元素的个数
|
|
boolean isEmpty()
|
检测
set
是否为空,空返回
true
,否则返回
false
|
|
Object[] toArray()
|
将
set
中的元素转换为数组返回
|
|
boolean containsAll(Collection<?> c)
|
集合
c
中的元素是否在
set
中全部存在,是返回
true
,否则返回false
|
|
boolean addAll(Collection<? extends
E> c)
|
将集合
c
中的元素添加到
set
中,可以达到去重的效果
|
小结:
- Set是继承自Collection的一个接口类
- Set中只存储了Key,并且要求Key是唯一的
- Set的底层是使用Map实现的,其使用key与Object的一个默认对象作为键值对插入到Map中的
- Set最大的功能就是对集合中的元素进行去重
- 实现Set接口的常用类有TreeSet和HashSet,还有一个LinkedHashSet,LinkedHashSet实在HashSet的基础上维护了一个双向链表来记录元素的插入次序
- Set中的Key不能修改,如果要修改,要先将原来的删除掉,然后再重新插入
- Set中不能插入null的Key
3,TreeSet和HashSet的使用和对比
1,TreeSet
TreeSet的底层是红黑树(可以把它想象成比较复杂,性能更加优秀的搜索树),我们联想二叉搜索树的一些性能就可以理解TreeSet的一些性能了:
- 二叉搜索树在插入的时候,对于已经在树中存在的数据是无法进行插入的,所以TreeSet中无法插入两个相同Key
- 二叉搜索树的左子树的数据永远小于相同根节点的右子树的数据,可知他是一棵有序树,TreeSet中的Key也是有序的,所以插入的数据必须具有可比较性,否则会报错
代码示例
Set存入的Key必须是唯一的,存入重复的Key会自动去重
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add("hello");
set.add("abc");
set.add("abc");
System.out.println(set);
}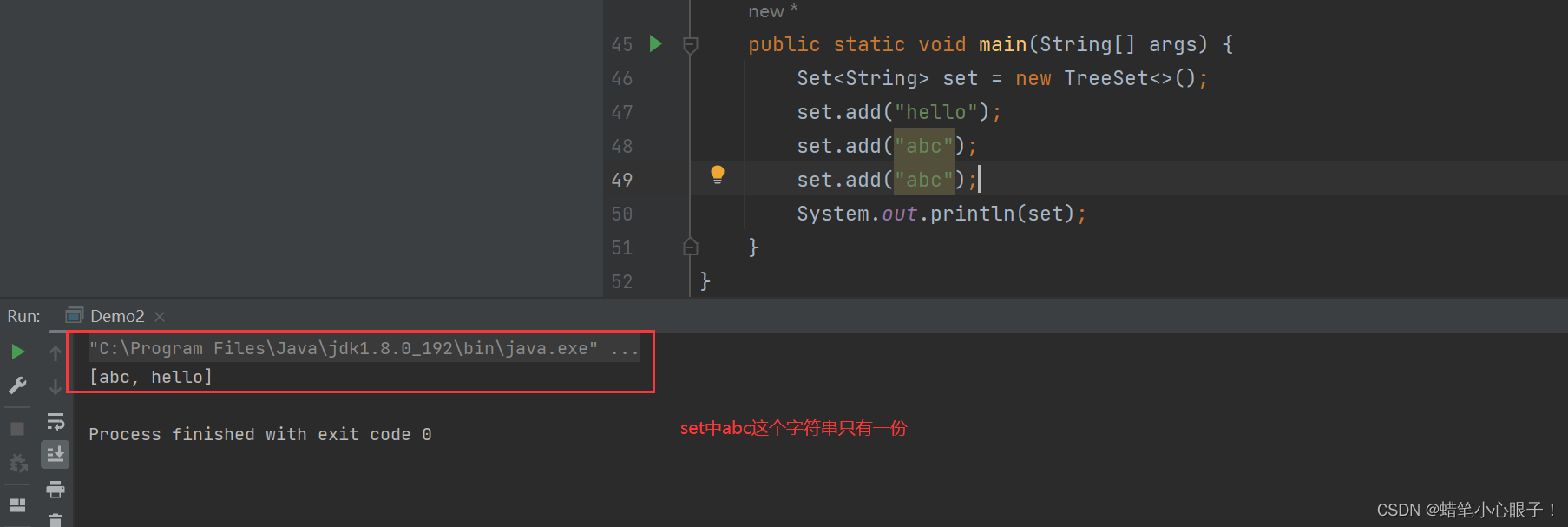 Set中不能插入为null的数据,否则会报空指针异常的错误
Set中不能插入为null的数据,否则会报空指针异常的错误
public static void main(String[] args) {
Set<String> set = new TreeSet<>();
set.add(null);
System.out.println(set);
}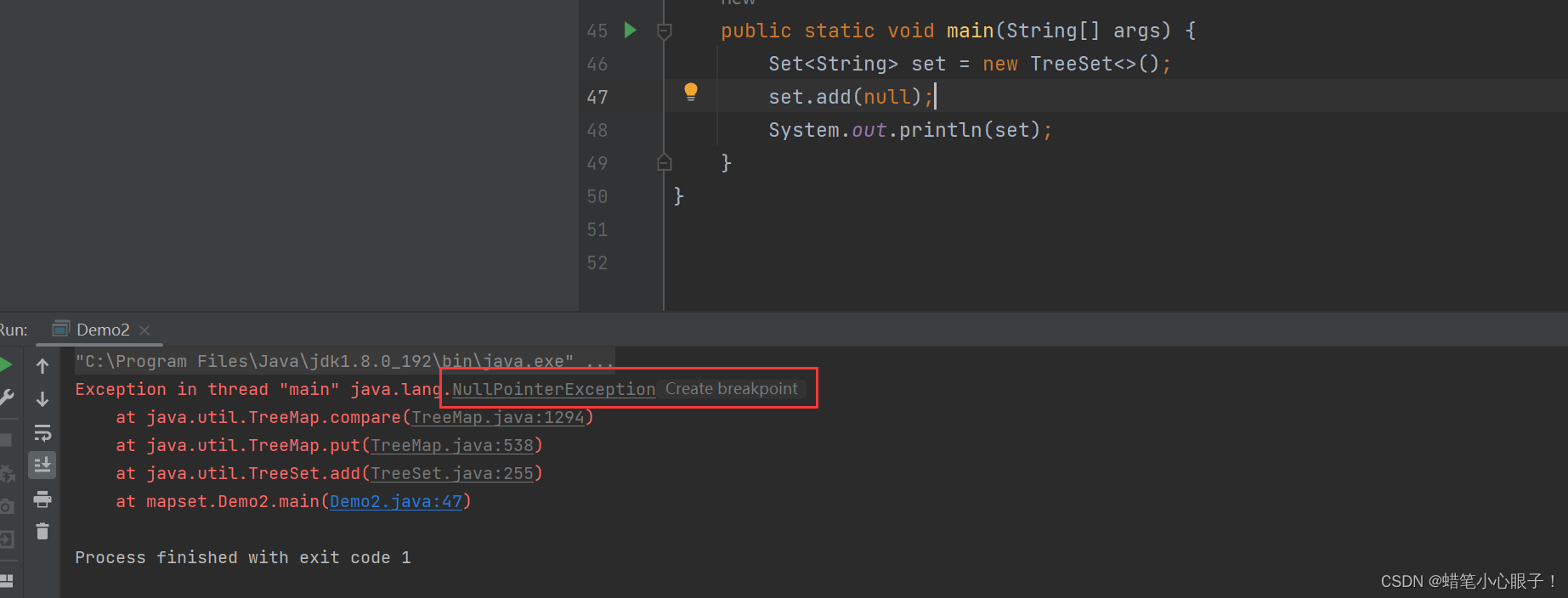 Set中插入的Key必须具有可比较性
Set中插入的Key必须具有可比较性
//定义一个Student类 该类不实现任何比较器接口
class Student {
}
public static void main(String[] args) {
Set<Student> set = new TreeSet<>();
set.add(new Student());
System.out.println(set);
}
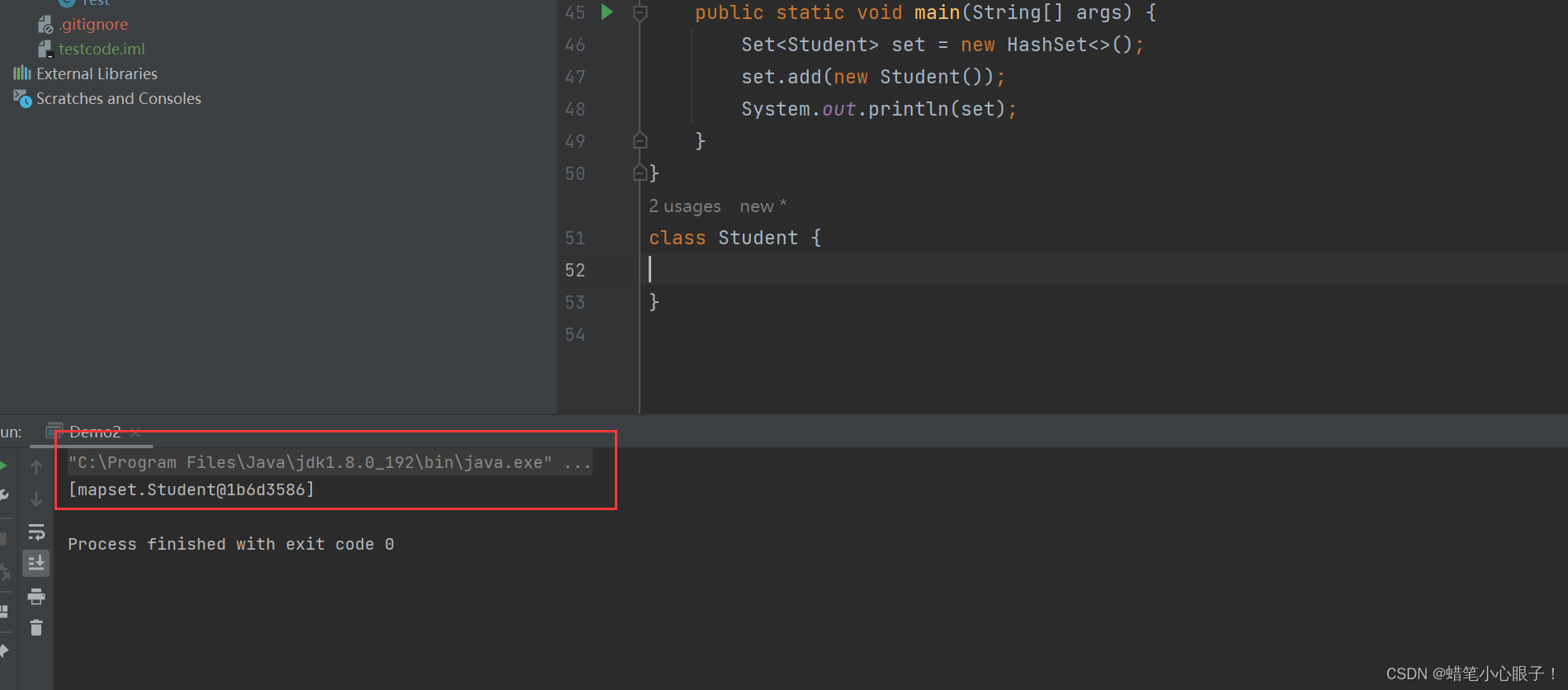
2,HashSet
HashSet和TreeSet大部分的方法相同,可以参照TreeMap的代码进行练习,这里只演示HashMap可以插入不需要具有可比较性的数据的代码
//定义一个Student类 该类不实现任何比较器接口
class Student {
}
public static void main(String[] args) {
Set<Student> set = new HashSet<>();
set.add(new Student());
System.out.println(set);
}
四, 总结
Set和Map使用场景分析:
Set:存储的Key没有其对应的映射关系,且需要对数据进行去重
Map:存储的数据之间存在某种映射关系