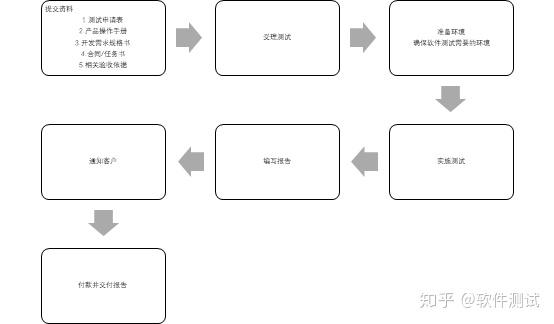
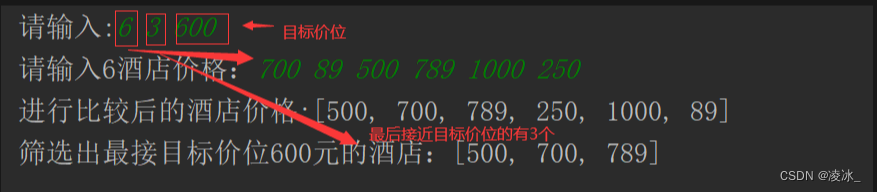
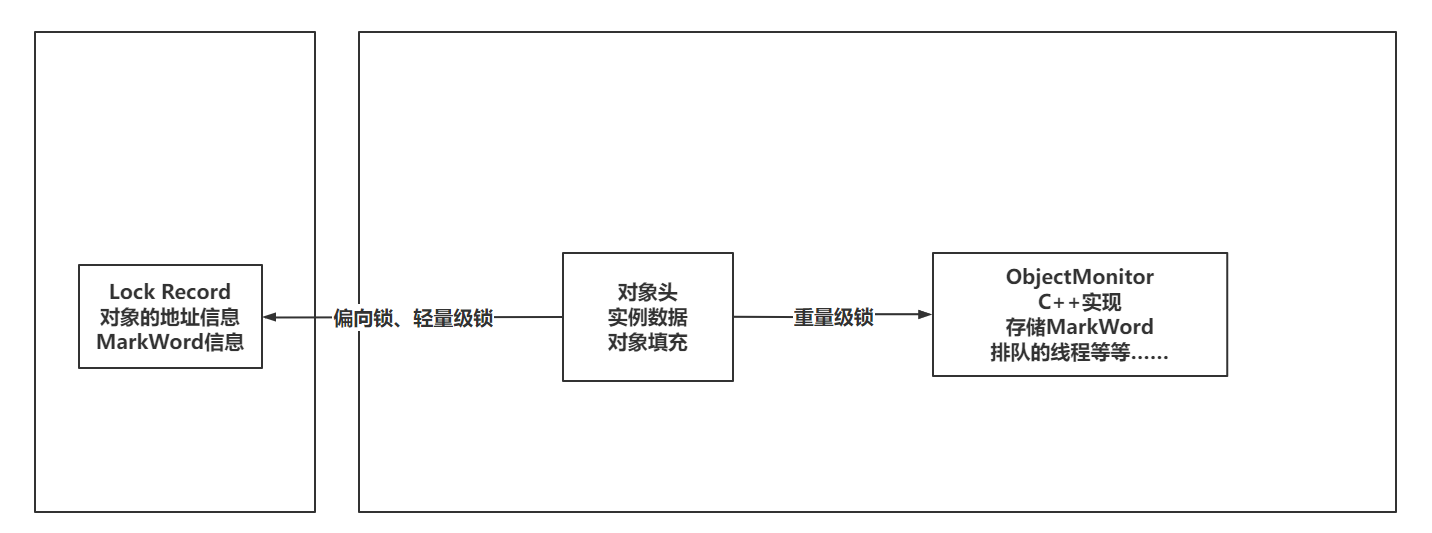
同样摘自知乎的回答:https://www.zhihu.com/question/29507442/answer/1212624591?utm_id=0
正巧之前做过时间序列 的异常检测项目,这里介绍几种尝试过的方法,也算是抛砖引玉 吧,欢迎大家讨论交流~
背景与定义
时间序列异常 检测的目的就是在时间序列中寻找不符合常见规律的异常点,无论是在学术界还是工业界这都是一个非常重要的问题。
应用十分广泛,这里拿“智能运维 ”场景的异常检测应用举例。企业的运维场景中有海量的运维指标数据,如果单纯依靠人力来发现并定位异常,将是十分低效的,所以如果可以开发一个智能运维系统对于异常波动 自动定位,将会提高运维效率。

现有方法
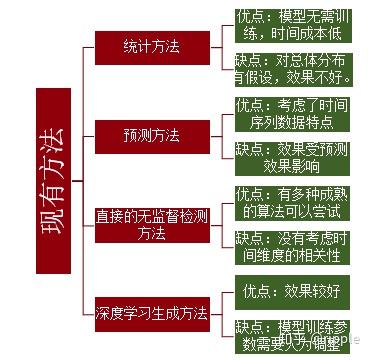
现有方法可以分为以下四类:
- 统计方法–通过历史同期的数据分布 来确定当前数据的合理波动范围。例如,k-sigma方法 。
- 预测方法 –比较预测值 与真实值的差异,超出阈值认为是异常点。
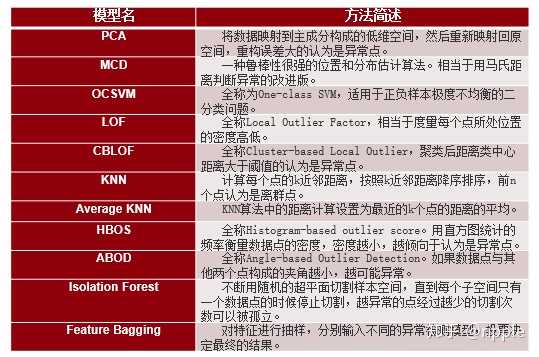
- 直接异常检测方法–有很多成熟算法,例如LOF,孤立森林 ,One-class SVM。
- 深度学习生成方法–对数据降维再升维重构,不能良好复原的点认为是异常点。例如GAN,VAE。

现有的方法在时间序列数据 中也许直接使用效果不好,这一点我们接下来的实验也能看出。
尝试的方法
–统计方法
异常检测工具包 (ADTK)是一个Python软件包,用于无监督/基于规则的时间序列异常检测。无需基于训练+测试范式,本方法具有极低的时间成本。基本思想是基于历史数据的统计,按照分位数或者阈值或者统计检验 的方法来判断当前点是否异常。
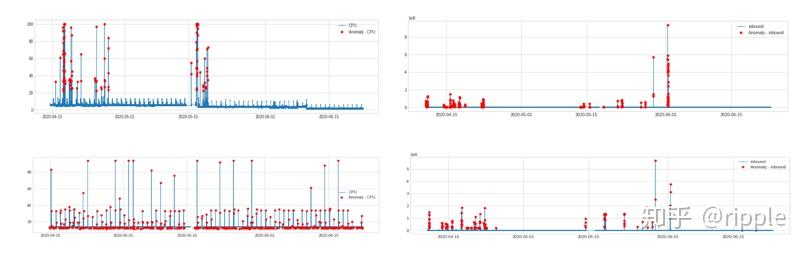
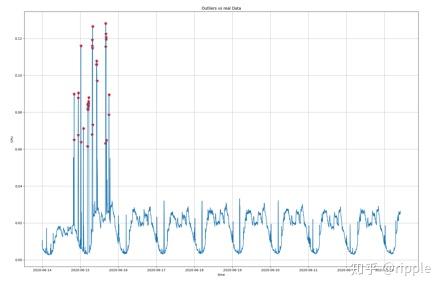
实验效果:模型倾向于把过多的点识别成异常值点 。
–直接异常检测
这种方法成熟的方法较多,大家可以参照Python的pyod软件包。
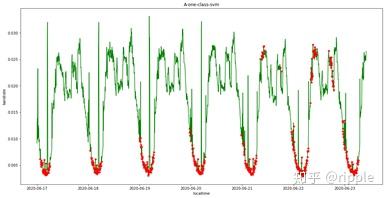

实验效果:时间序列正常的波动的高峰和低谷被判断为异常,没有充分利用时间维度 的信息。
–预测+统计方法(Prophet+3-sigma)
总体思路:如果数据超出了预测值的合理的波动范围,认为是异常。
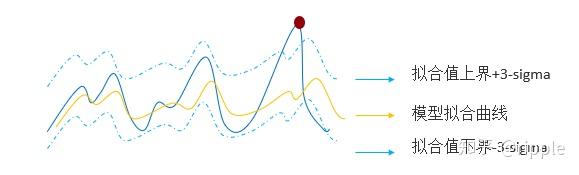

预测方法采用Prophet实现,3-sigma可以借助历史的波动数据来估计,例如我们将时间往前推数周,得到间隔不同周的同一时刻的数据;将时间往前推1~7天,得到同一周内不同天的同一时刻的数值。计算这些数值的标准差,作为sigma的估计。在Prophet的预测上下界的基础上分别加上和减去3-sigma得到数据波动 的合理范围,超出范围用异常标注。
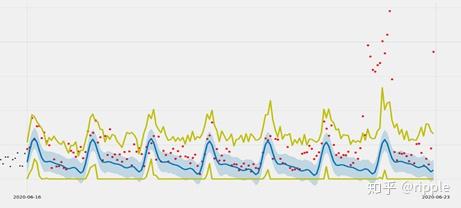

实验效果:考虑了时间维度的相关性,准确、高效。
–预测+直接异常检测的方法
去除时间序列的趋势和周期性。用预测模型 给出的预测值与真实值相减计算序列的残差,残差不包含周期性和趋势性,可以用作后续的异常检测。


当然为了提升模型的稳定性,我们可以在预测步骤采取多种预测方法,检测部分我们也可以用到pyod里面提供的多种方法,最终投票决定最终的结果。
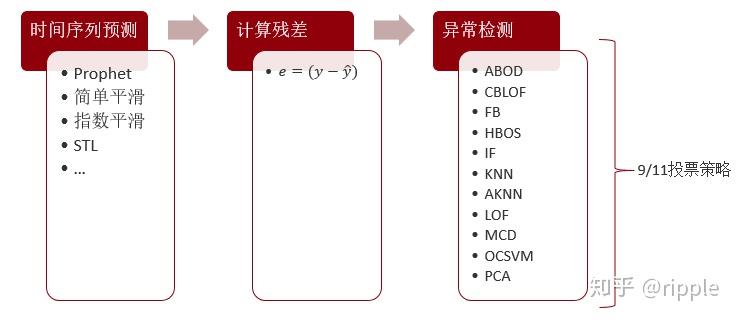


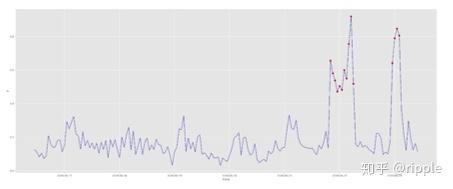

实验效果:较好。
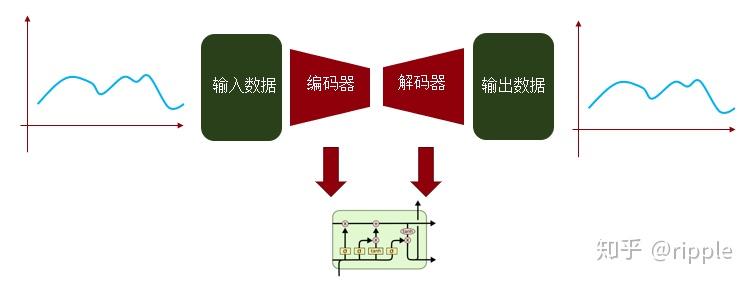
–深度学习生成模型
这里我们尝试了LSTM-AE的方法,效果不错。
总体思路:将高维数据压缩 至某一个特定维度大小,再还原至与原始数据 同样的维度。训练模型使得复原数据和原数据差距尽可能小。不能良好复原的点被认为是异常点。


总结
第3、4、5模型效果较好,对于时间序列检测问题可以尝试。




注:实验结果并非答主一人完成,也感谢当时一起参与项目的小伙伴此为原创内容,转载请注明原文链接