项目地址
原论文
Abstract
最近辐射场方法彻底改变了多图/视频场景捕获的新视角合成。然而取得高视觉质量仍需神经网络花费大量时间训练和渲染,同时最近较快的方法都无可避免地以质量为代价。对于无边界的完整场景(而不是孤立的对象)和 1080p 分辨率渲染,目前没有任何方法能达到实时显示率。我们引入了三个关键元素,使得能够达到sota视觉质量同时保证有竞争力的训练时间,而且重要的是可以高质量、实时( ≥ 30 f p s \ge 30 fps ≥30fps)、1080p分辨率的情况下新视角合成。首先,从摄像机校准过程中产生的稀疏点开始,我们用三维高斯来表示场景,既保留了用于场景优化的连续容积辐射场的理想特性,又避免了在空白空间进行不必要的计算;其次,我们对三维高斯进行交错优化/密度控制,特别是优化各向异性协方差(scale & rotation),以实现对场景的精确呈现;第三,我们开发了一种快速可见性感知渲染算法,它支持各向异性拼接,既能加快训练速度,又能进行实时渲染。我们在几个已建立的数据集上展示了最先进的视觉质量和实时渲染。
Introduction
网格和点是最常见的三维场景表示,因为它们是明确的,并且非常适合于快速的基于GPU/CUDA的光栅化(rasterization)。相比之下,最近的神经辐射场(NeRF)方法建立在连续的场景表示上,通常通过体积射线行进优化多层感知器(MLP),用于捕获场景的新视角合成。同样地,迄今为止最有效的辐射场解决方案是通过插值连续表示中存储的值,例如体素[Fridovich-Keil和Yu等,2022年]或哈希[Müller等,2022年]网格或点[Xu等,2022年]。尽管这些方法的连续性有助于优化,但渲染所需的随机采样是昂贵的,并可能导致噪音。我们引入了一种新方法,结合了两者的优势:我们的三维高斯表示允许使用最先进的视觉质量和竞争性训练时间进行优化,而我们的tile-based splatting解决方案确保了1080p分辨率下几个先前发布的数据集的SOTA质量的实时渲染(参见图1)。

我们的方法实现了辐射场的实时渲染,质量与以前质量最高的方法[Barron等人,2022年]相等,同时仅需要与最快的先前方法[Fridovich-Keil和Yu等人,2022年;Müller等人,2022年]相竞争的优化时间。这种性能的关键是一种新颖的3D高斯场景表示,结合实时可微分渲染器,显著加快了场景优化和新视角合成的速度。需要注意的是,在与InstantNGP [Müller等人,2022年]相当的训练时间内,我们的质量与他们的类似;虽然这是他们达到的最高质量,但通过训练51分钟,我们实现了最先进的质量,甚至略优于Mip-NeRF360 [Barron等人,2022年]。(吐槽:怎么感觉最后越说越牵强呢……有我写论文的感觉——只要限定范围足够小我就是最牛的
我们的目标是允许实时渲染多张照片捕获的场景,并在典型真实场景的优化时间内创建表示,速度与最有效的先前方法相当。近期的方法实现了快速训练[Fridovich-Keil等;Müller等],但难以达到当前SOTA NeRF方法获得的视觉质量,即Mip-NeRF360[Barron等人,2022年],该方法需要长达48小时的训练时间。快速但质量较低的辐射场方法可以在不同的场景下实现交互式渲染时间(每秒10-15帧),但无法满足高分辨率的实时渲染要求。哎呀反正就说大家都不行就我最牛了
我们的解决方案基于三个主要组成部分。首先,我们引入了3D高斯作为灵活且表现力强的场景表示。我们从先前的类似NeRF的方法中采用相同的输入,即由Structure-from-Motion(SfM,我帮同学完成作业时碰巧做过这个实验只用同一物体的多视角图片就能得到三维点云,相当cheap了,就是我做的效果极差)[Snavely等人,2006年]校准的相机,并使用SfM过程中简易(原文居然用free?)产生的稀疏点云初始化3D高斯集。与大多数需要多视图立体匹配(MVS)数据[Aliev等人,2020年;Kopanas等人,2021年;Rückert等人,2022年]的基于点的解决方案不同,我们仅使用SfM点作为输入即可实现高质量的结果。需要注意的是,在NeRF合成数据集中,我们的方法即使进行随机初始化也能实现高质量(意思是不用训练了?)。我们证明了3D高斯是一个很好的选择,因为它们是可微的体积表示,但也可以通过将它们投影到二维并应用标准𝛼混合来进行高效光栅化,使用与NeRF相同的等效图像形成模型(也是MLP咯?)。我们方法的第二个组成部分是优化3D高斯的属性,与自适应密度控制步骤交错,我们在优化过程中添加并偶尔移除3D高斯(sparse的思想)。优化过程产生了一个相对紧凑、非结构化且精确的场景表示(对于所有测试场景,1-5百万高斯)。我们方法的第三个即最后一个元素是我们的实时渲染解决方案,它使用快速GPU排序算法,并受tile-based rasterization的启发,遵循最近的工作[Lassner和Zollhofer,2021年]。然而,由于我们的3D高斯表示,我们可以执行各向异性splatting,遵循可见性排序-通过排序和𝛼混合-并通过跟踪所需数量的已排序splats的遍历来实现快速且准确的向后传播。
总之,我们提供了以下贡献:
• 引入各向异性3D高斯作为辐射场的高质量、非结构化表示。
• 3D高斯属性的优化方法,与自适应密度控制交错,为捕获的场景创建高质量的表示。
• 针对GPU的快速、可微分的渲染方法,它具有可见性感知性,允许各向异性splatting和快速反向传播,从而实现高质量的新视角合成。
我们在先前发布的数据集上的结果表明,我们可以从多视图捕获中优化我们的3D高斯,并获得与最佳先前隐式辐射场方法相等或更好的质量。我们还可以实现与最快方法相似的训练速度和质量,重要的是,为新视角合成提供了第一个实时渲染,质量高。
Related Work
这部分就不详细讲了,作者简要概述了传统reconstruction,讨论了基于点的渲染和辐射场的工作以及相似性。
作为小白值得一提的几个点:
MVS和CNN的缺点

作者提出这个观点的依据是论文中提到的“大多数方法使用基于多视图立体匹配(MVS)的几何信息,这是主要的缺点之一;此外,使用卷积神经网络(CNN)进行最终渲染经常导致时间上的闪烁现象。”这个观点基于两个主要方面:
- MVS-Based Geometry的缺点:作者指出大多数方法使用MVS-Based Geometry作为其几何信息的基础,这会带来主要的缺点。MVS方法在多视图图像中恢复场景几何,但由于深度图重建等过程中的误差积累,可能会导致不准确的几何信息。这可能会影响最终渲染的质量和稳定性,特别是在视角合成时可能会出现不连续性或伪影。
- CNN用于最终渲染的缺点:作者还指出使用CNN进行最终渲染可能会导致时间上的闪烁现象。这可能是因为CNN在逐帧渲染过程中可能会引入一些不稳定性,导致连续帧之间出现明显的亮度或颜色变化。这种闪烁现象可能在动态场景中尤为显著,影响了渲染的视觉质量。(这个倒是显而易见的
Volumetric representations
相关项目
挖个坑……
NeRF加速的三个设计
也是个坑……
Overview
我们方法的输入是一组静态场景图像,以及通过 SfM 校准的相应摄像机,该方法会产生稀疏点云作为副产物(副作用这个说法也太……)。我们从这些点中创建了一组三维高斯,由位置(均值)、协方差矩阵和不透明度𝛼 定义,可以实现非常灵活的优化机制。这使得三维场景的表示相当紧凑,部分原因是高度各向异性的体积splats可以用来紧凑地表示精细结构。辐射场的方向性外观分量(颜色)通过球面谐波(SH)表示,遵循标准做法[Fridovich-Keil 和 Yu 等,2022;Müller 等,2022]。我们的算法通过一系列三维高斯参数的优化步骤,即位置、协方差、𝛼 和 SH 系数,以及高斯密度自适应控制的交错操作,来创建辐射场表示。 我们的方法之所以高效,关键在于我们r tile-based rasterizer,它可以对各向异性的splats进行𝛼 混合,并通过快速排序遵守可见性顺序。快速栅格化器还包括通过跟踪累积的𝛼值实现的快速后向传递,对可接收梯度的高斯数量没有限制。最后一句没看懂了呜呜

优化从稀疏的 SfM 点云开始,并创建一组 3D 高斯。然后,我们对这组高斯的密度进行优化和自适应控制。在优化过程中,我们使用fast tile-based renderer,与 SOTA 快速辐射场方法相比,训练时间更短。 训练完成后,我们的渲染器就可以对各种场景进行实时渲染(居然用的是navigation……。

把经过优化后的3D Gaussians缩小60%并可视化出来,可以看到anisotropic shapes of 3D Gaussians表征了复杂的几何特征。(原文说clearly,真是日了狗了,哪里clearly了?
Differentiable 3D Gaussian Splatting
我们的目标是优化场景表示法,以便从无法线(without normals,即不带方向的点)的稀疏 (SfM) 点集合出发,进行高质量的新颖视图合成。为此,我们需要一种基元,它继承了可微分体积表示法的特性,同时又是非结构化的、明确的,可以进行非常快速的渲染。我们选择三维高斯,因为它是可微分的,可以很容易地投射到2D splats上,从而实现快速的 α \alpha α混合渲染。
我们的表示方法与之前使用2D点的方法[Kopanas et al. 2021; Yifan et al. 2019]有相似之处:假设每个点都是一个带有法线的小平面圆。但是鉴于SfM点的极度稀疏性,估计法线非常困难。同样地,从这样的估计中优化非常嘈杂的法线将是非常具有挑战性的。所以,我们将几何形状建模为一组不需要法线的三维高斯函数。我们的高斯函数由一个在世界坐标系中定义的完整的3D协方差矩阵 Σ Σ Σ定义,以点(均值) μ \mu μ为中心[Zwicker et al. 2001a]:
G ( x ) = e − 1 2 ( x ) T Σ − 1 ( x ) G(x) = e^{-\frac{1}{2}(x)^TΣ^{-1}(x)} G(x)=e−21(x)TΣ−1(x)
最后在blending过程中乘以透明度 α \alpha α.
不过,我们需要将三维高斯投影到二维空间,以便进行渲染。 Zwicker 等人 [2001a] 演示了如何将三维高斯投影到图像空间。给定视图变换 W W W,摄像机坐标中的协方差矩阵 Σ ′ Σ ^′ Σ′ 如下所示:
Σ ′ = J W Σ W T J T Σ ^′ = JW Σ W^TJ^T Σ′=JWΣWTJT
其中, J J J 是投影变换仿射近似的Jacobian。Zwicker 等人[2001a]的研究还表明,如果我们跳过 Σ ′ Σ ^′ Σ′ 的第三行和第三列,就会得到一个 2×2 方差矩阵,其结构和性质与以前的工作[Kopanas 等人,2021]中从有法线的平面点所得的矩阵相同。
一种显而易见的方法是直接优化协方差矩阵 Σ Σ Σ,以获得代表辐射场的三维高斯。 然而,协方差矩阵只有在positive semi-definite(正半定)时才具有物理意义。在对所有参数进行优化时,我们使用梯度下降法,但这种方法并不容易产生有效的矩阵,而且更新步骤和梯度很容易产生无效的协方差矩阵。
因此,我们选择了一种更直观、但具有同等表达能力的优化表示方法。三维高斯的协方差矩阵 Σ Σ Σ 类似于描述一个椭球体的构型。给定缩放矩阵 S S S 和旋转矩阵 R R R,我们就能找到相应的 Σ Σ Σ:(抽查矩阵正定的知识点!)
Σ = R S S T R T Σ = RSS^TR^T Σ=RSSTRT
为了对这两个因素进行独立优化,我们将它们分开存储:三维向量 s s s用于缩放,四元数 q q q表示旋转。我们可以将它们转换为各自的矩阵并进行组合,同时确保对 q q q进行归一化处理,以获得有效的单位四元数。
-
为了避免在训练过程中自动微分带来的巨大开销,我们明确推导出了所有参数的梯度。
解释一下其中的关键点:
- Significant Overhead due to Automatic Differentiation: 自动求导是深度学习训练中的关键技术,它能够自动计算损失函数对于模型参数的梯度,从而实现参数的更新。然而,在某些情况下,自动求导可能会引起计算上的开销,特别是在涉及大量参数和复杂计算的模型时。
- Derive Gradients Explicitly: 这句话提到的方法是显式地计算梯度,而不是通过自动求导功能来计算。也就是说,我们会手动推导出损失函数相对于每个参数的梯度,而不是依赖于自动求导的方式。
这种适合优化的各向异性协方差表示法,使我们能够优化三维高斯,以适应拍摄场景中不同形状的几何图形,从而获得相当紧凑的表示法。
Optimization with Adaptive Density Control of 3D Gaussians
我们方法的核心是优化步骤,它创建了一组密集的三维高斯,准确地代表了用于自由视角合成的场景。除了位置 p p p、 α \alpha α和协方差 Σ Σ Σ之外,我们还优化了代表每个高斯的颜色 c c c的SH系数,以正确捕捉视角相关的场景外观。这些参数的优化与控制高斯密度的步骤交错进行,以更好地表现场景。
Optimization
优化基于连续的迭代渲染,并将生成的图像与捕获数据集中的训练视图进行比较。由于三维到二维投影的不确定性,几何体的位置难免会不正确。因此,我们的优化需要能够创建几何图形,并在几何图形被错误定位时将其销毁或移动。三维高斯协方差参数的质量对表示的紧凑性至关重要,因为只需少量各向异性的large高斯就能捕捉到大面积的同质区域。
我们采用随机梯度下降技术进行优化,充分利用标准的 GPU 加速框架,并按照最近的最佳实现[Fridovich-Keil 和 Yu 等人,2022;Sun 等人,2022],为某些操作添加定制的 CUDA 内核。特别是,我们的快速光栅化对我们的优化效率至关重要,因为它是优化的主要计算瓶颈。
我们为 α \alpha α使用了一个 sigmoid 激活函数,以将其限制在 [ 0 − 1 ) [0 - 1) [0−1) 范围内,并获得平滑的梯度。
我们将初始协方差矩阵估计为各向同性高斯矩阵,其轴等于最近三点距离的平均值。 我们使用了与 Plenoxels [Fridovich-Keil 和 Yu 等人,2022 年] 类似的标准指数衰减调度技术,但只针对位置。损失函数是 L1 与 D-SSIM 项相结合:
L 1 = ( 1 − λ ) L 1 + λ L D − S S I M L_1 = (1-\lambda)L_1+\lambda L_{D-SSIM} L1=(1−λ)L1+λLD−SSIM
所有实验中设置 λ = 0.2 \lambda = 0.2 λ=0.2
Adaptive Control of Gaussians
我们从 SfM 的初始稀疏点集开始,然后应用我们的方法自适应地控制单位体积内的高斯数和高斯密度(和NeRF的密度 σ \sigma σ不同!),使我们能够从初始稀疏的高斯集变为更密集的高斯集,从而以正确的参数更好地表现场景。在优化预热之后,我们每迭代 100 次就会进行一次高斯密度化处理,并删除基本透明的高斯,即 α \alpha α小于阈值 ϵ α \epsilon_\alpha ϵα 的高斯。
我们对高斯的自适应控制需要填充空白区域。它不仅关注几何特征缺失的区域(“重建不足”),也关注高斯覆盖场景中大面积的区域(通常对应于 “重建过度”)。 我们观察到,两者都有较大的视空间位置梯度。 直观地说,这可能是因为它们对应的区域还没有得到很好的重构,而优化试图移动高斯来纠正这一点。
由于这两种情况都适合进行高斯密集化处理,我们会对视图空间位置梯度的平均值高于阈值 τ p o s \tau _{pos} τpos 的高斯进行密集化处理,我们在测试中将阈值设为 0.0002 0.0002 0.0002。 接下来我们将详细介绍这一过程,如图 4 所示。
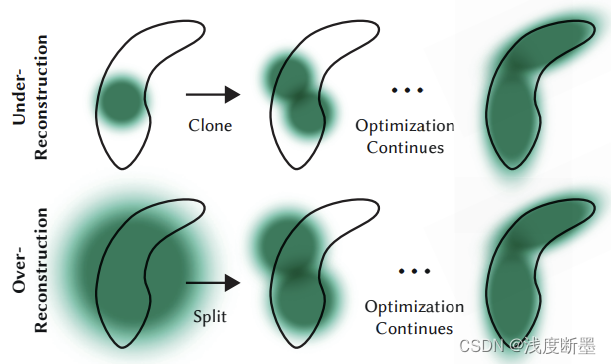
我们的自适应高斯密集化方案。顶行(重建不足): 当小尺度几何图形(黑色轮廓)覆盖不足时,我们会克隆相应的高斯。下一行(过度重构): 如果小尺度几何图形由一个大拼接块表示,我们就将其一分为二。
对于处于未完全重建区域的小高斯,我们需要覆盖必须创建的新几何体。为此,我们最好克隆高斯,只需创建一个相同大小的副本,并沿位置梯度方向移动即可。
另一方面,高方差区域的大高斯需要分割成小高斯。我们用两个新的高斯来替换这些高斯,并用实验确定的系数 ϕ = 1.6 \phi = 1.6 ϕ=1.6 来划分它们的比例。我们还使用原始三维高斯作为采样的 PDF 来初始化它们的位置。
在第一种情况下,我们会检测并处理增加系统总体积和高斯数量的需求;而在第二种情况下,我们会保留总体积,但增加高斯数量。与其他体积表示法类似,我们的优化可能会陷入浮点靠近输入摄像头的情况;在我们的任务中,这可能会导致高斯密度的不合理增加。减缓高斯数量增加的有效方法是,每迭代 N = 3000 N = 3000 N=3000 次,将 α \alpha α 值设置为接近零。优化后,高斯的 α \alpha α值会在需要时增加,同时允许我们的剔除方法删除 α \alpha α小于 ϵ α \epsilon_{\alpha} ϵα的高斯,如上所述。高斯可能会缩小或增大,并与其他高斯有相当程度的重叠,但我们会定期删除世界空间中非常大的高斯和视图空间中占地面积大的高斯。这种策略可以很好地控制高斯总数。我们模型中的高斯在任何时候都是欧几里得空间中的基元;与其他方法不同[Barron 等人,2022;Fridovich-Keil 和 Yu 等人,2022],我们不需要对遥远或大型高斯进行空间压缩、扭曲或投影策略。
Fast Differentiable Rasterizer for Gaussians
我们的目标是实现快速的整体渲染和快速排序,以允许近似的 α \alpha α混合(包括各向异性的拼接),并避免对可接收梯度的拼接数量的硬性限制,这种限制存在于之前的工作中[Lassner 和 Zollhofer 2021]。
为了实现这些目标,我们设计了一种tile-based高斯splats光栅化器,其灵感来自于最近的软件光栅化方法[Lassner 和 Zollhofer 2021],可以一次对整个图像的基元进行预排序,避免了之前的 α \alpha α混合解决方案[Kopanas 等人 2022, 2021]中每个像素排序的开销。我们的快速光栅化器可以对任意数量的混合高斯进行高效的反向传播,额外内存消耗低,只需要每个像素的恒定开销。我们的光栅化流水线是完全可微分的,在投影到二维的情况下,可以对各向异性的splats进行光栅化,类似于之前的二维splatting方法[Kopanas 等人,2021 年]。
我们的方法首先将屏幕分割成 16 × 16 16×16 16×16 块,然后根据视场和每块瓷砖的情况筛选三维高斯。具体来说,我们只保留置信区间为 99 % 99\% 99% 且与视锥(view frustum)相交的高斯。此外,我们还使用保护带(guard band)来剔除极端位置的高斯(即均值接近近平面但远离视锥的高斯),因为计算它们的投影二维协方差将是不稳定的。然后,我们根据每个高斯重叠的tiles数将其实例化,并为每个实例分配一个结合了视图空间深度和tile ID 的键。然后,我们使用单个快速 GPU Radix 排序(Merrill 和 Grimshaw,2010 年)根据这些键对高斯进行排序。需要注意的是,没有额外的按像素排序的点,混合是基于这种初始排序执行的。因此,在某些配置中,我们的 α \alpha α-blending可能是近似的。不过,当splat的大小接近单个像素时,这些近似值就可以忽略不计了。我们发现,这种选择大大提高了训练和渲染性能,而且在融合场景中不会产生明显的人工痕迹。
在对高斯进行排序后,我们会通过识别第一个和最后一个深度排序的entry来为每个tile生成一个列表,这些entry会splat到给定的tile上。在光栅化过程中,我们为每个tile启动一个thread block。每个thread block首先协同将高斯数据包加载到共享内存中,然后针对给定像素,通过前后遍历列表来累积颜色和 α \alpha α值,从而最大限度地提高数据加载/共享和处理的并行性。当某个像素达到目标饱和度 α \alpha α时,相应的线程就会停止。每隔一段时间,我们就会对一个tile中的线程进行查询,当所有像素都达到饱和(即 α \alpha α变为 1)时,整个tile的处理就会终止。
在光栅化过程中, α \alpha α的饱和度是唯一的停止标准。与之前的工作不同,我们不限制接受梯度更新的混合基元的数量。我们强制执行这一特性,是为了让我们的方法能够处理具有任意不同深度复杂度的场景,并准确地学习它们,而无需诉诸特定场景的超参数调整。因此,在后向处理过程中,我们必须恢复前向处理过程中每个像素混合点的完整序列。一种解决方案是在全局内存中存储每个像素任意长的混合点列表(Kopanas 等人,2021 年)。为了避免隐含的动态内存管理开销,我们选择再次遍历per-tile 表;我们可以重复使用前向遍历中的高斯排序数组和tile范围。为了方便梯度计算,我们现在从后向前遍历它们。
遍历从影响tile中任何像素的最后一个点开始,并再次以协作方式将点加载到共享内存中。此外,每个像素只有在其深度小于或等于前向遍历过程中对其颜色有影响的最后一个点的深度时,才会开始(昂贵的)重叠测试和点处理。计算上文所述的梯度需要原始混合过程中每一步累积的不透明度值。我们可以只存储前向传递结束时的总累积不透明度,而不是在后向传递中遍历一个逐渐缩小的不透明度的显式列表,从而恢复这些中间不透明度。具体来说,每个点在前向过程中存储最终累积的不透明度 α \alpha α;我们在后向遍历中将其除以每个点的 α \alpha α,以获得梯度计算所需的系数。
clone下来try try
Train and test on tandt/trunk
第一张图是gt,第二张是render的结果,真他妈神了


Evaluate test results
SSIM : 0.8776215
PSNR : 25.3630562
LPIPS: 0.1481234
比论文里的数据还吊……感觉被拿原图骗了也说不定……