MyBatis可以使用简单的XML或注解用于配置和原始映射,将接口和Java的POJO(Plain Old Java Objects,普通的Java对象)映射成数据库中的记录
MyBatis 是一个 半自动的ORM(Object Relation Mapping)框架
创建好maven工程(设置打包方式为jar,引入依赖)
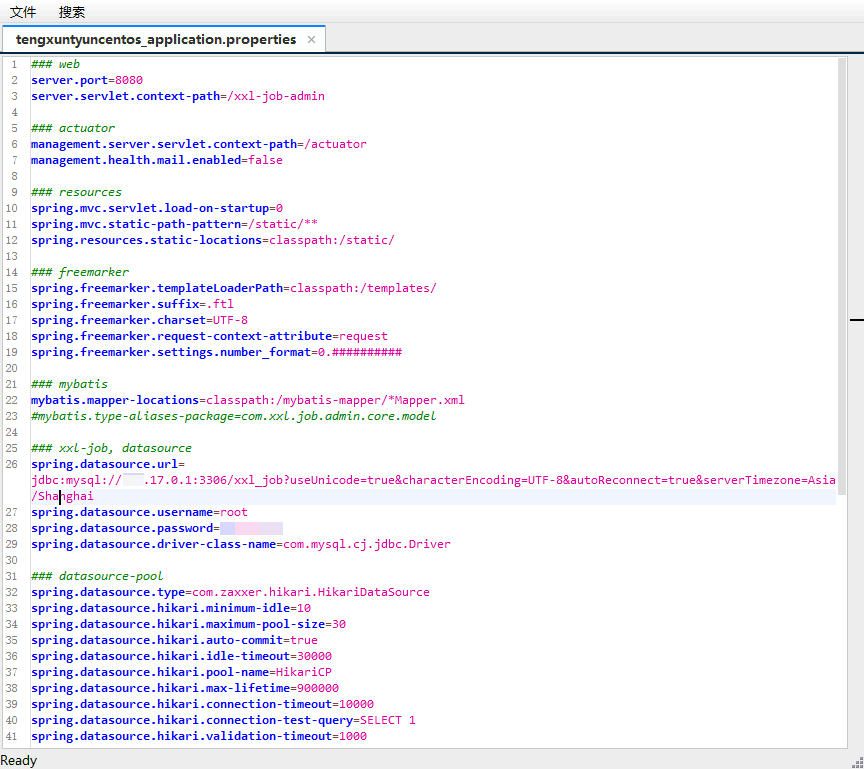
创建MyBatis的核心配置文件(主要用于配置连接数据库的环境以及MyBatis的全局配置信息,存放的位置是src/main/resources目录下
习惯上命名为mybatis-config.xml(将来整合Spring 之后,这个配置文件可以省略
如上在该配置文件的内容
(其中如下路径方式是以main\resources目录为准,如果UserMapper.xml在resources目录下的话,则直接写其名字即可。下面可以看出我的文件路径路径是main\resources\mappers\UserMapper.xml)
<mapper resource="mappers\UserMapper.xml"/>创建mapper接口:MyBatis中的mapper接口相当于以前的dao。但是区别在于,mapper仅仅是接口,我们不需要提供实现类,只需要创建接口,通过mybatis的一些功能来创建一些代理实现类,当我们调用接口中的方法,直接对应其中的sql语句并执行。
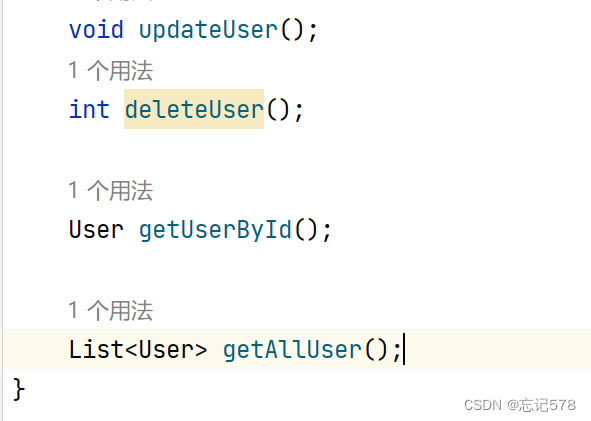
public interface UserMapper { int insertUser(); void updateUser(); int deleteUser(); User getUserById(); List<User> getAllUser(); }(上图的方法,都是下面增删改使用到的方法)
创建完接口后,创建mybatis的映射文件
1、映射文件的命名规则: 表所对应的实体类的类名+Mapper.xml 例如:表t_user,映射的实体类为User,所对应的映射文件为UserMapper.xml
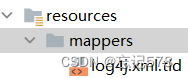
(下为UserMapper.xml文件内容?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE mapper PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN" "http://mybatis.org/dtd/mybatis-3-mapper.dtd"> <!-- 一个映射文件对应一个实体类,对应一张表的操作 MyBatis映射文件用于编写SQL,访问以及操作表中的数据--> <mapper namespace="personal.august.mybatis.mapper.UserMapper"> <!-- MyBatis中可以面向接口操作数据,要保证两个一致: a>mapper接口的全类名和映射文件的命名空间(namespace)保持一致 b>mapper接口中方法的方法名和映射文件中编写SQL的标签的id属性保持一致--> <!--int insertUser(); sql语句对应的方法--> <insert id="insertUser"> insert into t_user values(1,'wang','12345',22,'男','1@q.com') </insert> </mapper>MyBatis映射文件存放的位置是src/main/resources/mappers目录下
(无论映射文件的存放位置如何,都需要在MyBatis的配置文件中正确地指定映射文件的位置。在MyBatis的配置文件中可以使用
<mappers>元素来指定映射文件或映射器接口的位置。public class MybatisTest { @Test public void testInsert() throws IOException { //读取MyBatis的核心配置文件 InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-comfig.xml"); //创建SqlSessionFactoryBuilder对象 SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder(); //通过核心配置文件所对应的字节输入流创建工厂类SqlSessionFactory,生产SqlSession对象 SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(resourceAsStream); //创建SqlSession对象,此时通过SqlSession对象所操作的sql都必须手动提交或回滚事务 //SqlSession sqlSession = sqlSessionFactory.openSession(); //创建SqlSession对象,此时通过SqlSession对象所操作的sql都会自动提交 SqlSession sqlSession = sqlSessionFactory.openSession(true); //通过代理模式创建UserMapper接口的代理实现类对象 UserMapper mapper = sqlSession.getMapper(UserMapper.class); //调用UserMapper接口中的方法,就可以根据UserMapper的全类名匹配元素文件,通过调用的方法名匹配 //映射文件中的SQL标签,并执行标签中的SQL语句 int result = mapper.insertUser(); //提供sql以及的唯一标识找到sql并执行,唯一标识是namespace.sqlId(记得用双引号引起) // int result = sqlSession.insert("personal.august.mybatis.mapper.UserMapper.insertUser"); System.out.println(result); sqlSession.close(); } }(补充:
SqlSession:代表Java程序和数据库之间的会话。(HttpSession是Java程序和浏览器之间的 会话)
SqlSessionFactory:是“生产”SqlSession的“工厂”。
工厂模式:如果创建某一个对象,使用的过程基本固定,那么我们就可以把创建这个对象的 相关代码封装到一个“工厂类”中,以后都使用这个工厂类来“生产”我们需要的对象。
navicat中在表名那里右键点击设计表则可以设置表结构
因为sqlSession的获取是固定的写法,在下面的增删改查操作中会很频繁的使用,所以我们将其创建过程的代码封装成一个工具类

public class SqlSessionUtil { public static SqlSession getSqlSession() { SqlSession sqlSession = null; try { //获取核心配置文件的输入流 InputStream resourceAsStream = Resources.getResourceAsStream("mybatis-comfig.xml"); //获取SqlSessionFactoryBuilder SqlSessionFactoryBuilder sqlSessionFactoryBuilder = new SqlSessionFactoryBuilder(); //获取SqlSessionFactory SqlSessionFactory sqlSessionFactory = sqlSessionFactoryBuilder.build(resourceAsStream); //获取SqlSession对象 sqlSession = sqlSessionFactory.openSession(true); } catch (IOException e) { e.printStackTrace(); } return sqlSession; } }
加入log4j日志功能
在pom.xml文件中加入相关依赖
加入log4j的配置文件
log4j的配置文件名为log4j.xml,存放的位置是src/main/resources目录下
创建文件发现点小问题,发现后缀为tld,
可以按照如图去创建xml文件的模板。下次新建则可以使用自己创建的模板
新建log4j.xml后将如下内容放入
<?xml version="1.0" encoding="UTF-8" ?> <!DOCTYPE log4j:configuration SYSTEM "log4j.dtd"> <log4j:configuration xmlns:log4j="http://jakarta.apache.org/log4j/"> <appender name="STDOUT" class="org.apache.log4j.ConsoleAppender"> <param name="Encoding" value="UTF-8" /> <layout class="org.apache.log4j.PatternLayout"> <param name="ConversionPattern" value="%-5p %d{MM-dd HH:mm:ss,SSS} %m (%F:%L) \n" /> </layout> </appender> <logger name="java.sql"> <level value="debug" /> </logger> <logger name="org.apache.ibatis"> <level value="info" /> </logger> <root> <level value="debug" /> <appender-ref ref="STDOUT" /> </root> </log4j:configuration>(补充:日志级别
FATAL(致命)>ERROR(错误)>WARN(警告)>INFO(信息)>DEBUG(调试) 从左到右打印的内容越来越详细


Mybatis的增删改查
update更新修改:将wang改为today,密码改为123
在UserMapper中声明方法updateUser()
在UserMapper.xml文件中的对应的namespace下增加sql语句(下图对应id=updateUser(方法名)
<mapper namespace="personal.august.mybatis.mapper.UserMapper">
public void testUpdate(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); mapper.updateUser(); sqlSession.close(); }调用自己封装的工具类SqlSessionUtil创建SqlSession,生成代理类对象mapper,调用updateUser方法。得到如下预期中的修改结果
delete删除:删除id=1的记录
得到如下图的预期结果
select查询:
如果查询结果为一条数据则可以转换为实体类对象,如果是多条数据则转换为实体类对象的集合
查询一个实体类对象
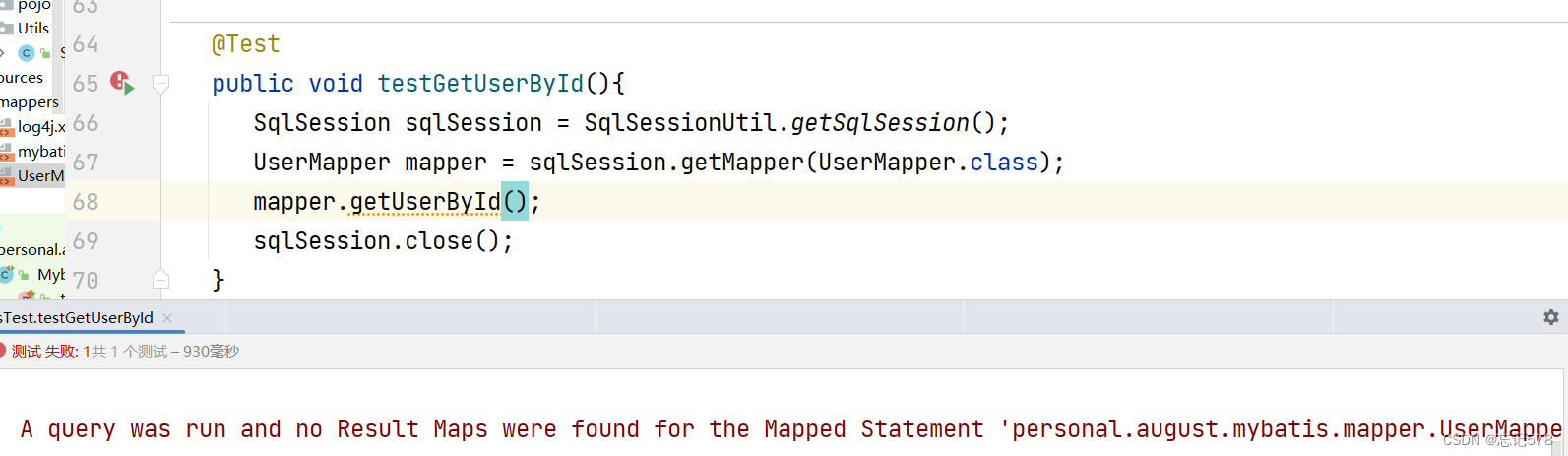
按照之前的增删改操作去实现查询出现如上报错(我们未获得对应的结果集
如下修改(在select的标签下设置resultType属性,如果是多个字段要用resultMap属性
(resultType的类要有唯一路径说明
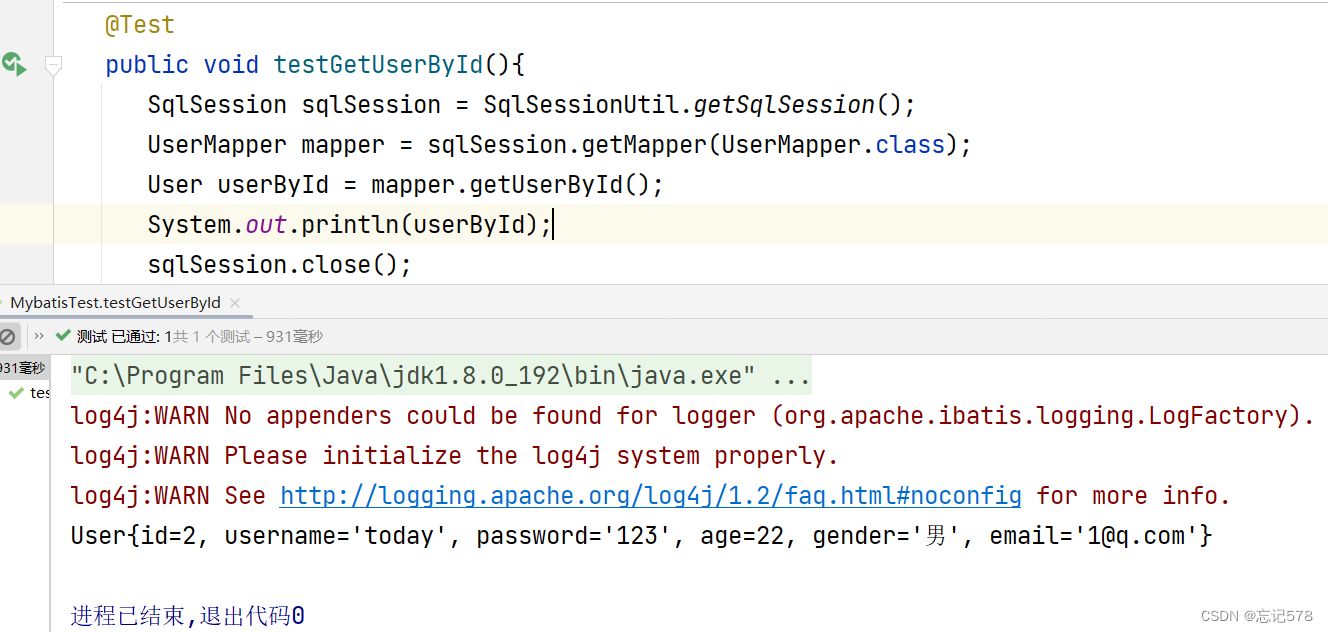
修改后得到如下正确结果
查询集合(查询所有数据)
(这里resultType的值和上面一样是一个类而不是最后呈现的类型list,因为是先把数据先转换为实体类对象后再放入集合)
得到如下查询结果
(注意:
1、查询的标签select必须设置属性resultType或resultMap,用于设置实体类和数据库表的映射关系
resultType:自动映射,用于属性名和表中字段名一致的情况
resultMap:自定义映射,用于一对多或多对一或字段名和属性名不一致的情况(下面内容会涉及)
2、当查询的数据为多条时,不能使用实体类作为返回值,只能使用集合,否则会抛出异常 TooManyResultsException;但是若查询的数据只有一条,可以使用实体类或集合作为返回值









核心配置文件(以我取名示例mybatis-config.xml)
可以创建properties文件方式来写配置文件
(在文件中的内容,不要故意空格,如上加了jdbc的后缀,为了标识和易于理解,如果出现多个相同内容,也可以很好的区分,This is a good habit)
用文件方式来完善内容,则要引入到配置文件中,用标签properties
<configuration> <!--引入properties文件,此时就可以${属性名}的方式访问属性值--> <properties resource="mappers/jdbc.properties"></properties> <environments default="development"> <environment id="development" > <transactionManager type="JDBC"/> <dataSource type="POOLED"> <!--设置驱动类的全类名--> <property name="driver" value="${jdbc.driver}"/> <!--设置连接数据库的连接地址--> <property name="url" value="${jdbc.url}"/> <!--设置连接数据库的用户名--> <property name="username" value="${jdbc.username}"/> <!--设置连接数据库的密码--> <property name="password" value="${jdbc.password}"/> </dataSource> </environment> </environments> <!--引入映射文件--> <mappers> <mapper resource="mappers\UserMapper.xml"/> </mappers> </configuration>(<properties resource="mappers/jdbc.properties"></properties>,如果文件在resources目录下,则直接写文件名即可)
在配置文件中的其他标签
typeAliases
<typeAliases> <!-- typeAlias:设置某个具体的类型的别名 属性: type:需要设置别名的类型的全类名 alias:设置此类型的别名,若不设置此属性,该类型拥有默认的别名,即类名且不区分大小 写 若设置此属性,此时该类型的别名只能使用alias所设置的值 --> <typeAlias type="personal.august.mybatis.pojo.User"></typeAlias> <!--<typeAlias type="personal.august.mybatis.pojo.User" alias="abc"> </typeAlias>--> <!--以包为单位,设置改包下所有的类型都拥有默认的别名,即类名且不区分大小写--> <!-- <package name="personal.august.mybatis.pojo"/>--> </typeAliases>(<typeAlias type="personal.august.mybatis.pojo.User"></typeAlias>,未指定别名,则默认为类名User,且不区分大小写)
设置别名后,我们在UserMapper.xml文件中引用确切的类时,则可以简写。下图对应如上我们设置的别名
核心配置文件中的标签必须按照固定的顺序: properties?,settings?,typeAliases?,typeHandlers?,objectFactory?,objectWrapperFactory?, reflectorFactory?,plugins?,environments?,databaseIdProvider?,mappers?<mappers> 在mybatis-config.xml文件中映射文件的引用
<mappers> <mapper resource="mappers\UserMapper.xml"/> </mappers>在此之前我们是这样引入的,但是,按照这样的方式会比较麻烦,因为一个类对应一个配置文件,这样要写很多如果后面需要的话。
则我们可以通过包来引入配置文件,注意:
映射文件所在的包和mapper接口所在的包一样
只有用/分开去建文件才可以,因为我们点的是新建目录。personal/august/mybatis这样写才可以得到和接口所在一样的包。如果是用personal.august.mybatis则如下图
可以发现在idea中看不出,但实际上是一整个文件夹名,而不是和接口所在包相同。
如上图,根据我们UserMapper接口所在的包,我们为配置文件也创建相同的包,并放入。
以包的方式引入映射文件,必须满足两个条件 1、mapper接口和映射文件所在的包必须一致 2、mapper接口和映射文件的名字必须一致在满足上述条件后,我们则可以这样引入配置文件(直接写配置文件所在包名即可,且后面还有在该包下的配置文件,也可不必修改。
设置同样的包是为了文件可以在加载完成后放在一起







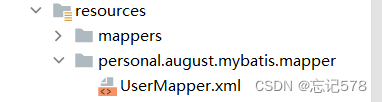


MyBatis获取参数值的两种方式:${}和#{}
${}的本质就是字符串拼接,#{}的本质就是占位符赋值
${}使用字符串拼接的方式拼接sql,若为字符串类型或日期类型的字段进行赋值时,需要手动加单引号;但是#{}使用占位符赋值的方式拼接sql,此时为字符串类型或日期类型的字段进行赋值时,可以自动添加单引号。我们要做的就是在映射文件中获取sql语句对应方法的参数,然后拼接到sql语句中
1、单个字面量类型的参数
若mapper接口中的方法参数为单个的字面量类型
此时可以使用${}和#{}以任意的名称获取参数的值,注意${}需要手动加单引号在UserMapper接口中创建该查询方法: User getUserByUsername(String username); 创建测试类(同名包下)ParameterTest创建测试方法: public void testGetUserByUsername(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User today = mapper.getUserByUsername("today"); System.out.println(today); }
(如上图是使用#{},且查询到的是一条数据的情况,下面会讲到多条数据的处理,
select * from t_user where username=#{username};#里的username可以是任意名字,因为我们获取的参数值,不会识别这个名字,所以即使是abc也可,建议取的有意义一些(但是不同版本mybatis可能不同如果是使用${}则要加‘’,如下
select * from t_user where username='${username}';
2、多个字面量类型的参数
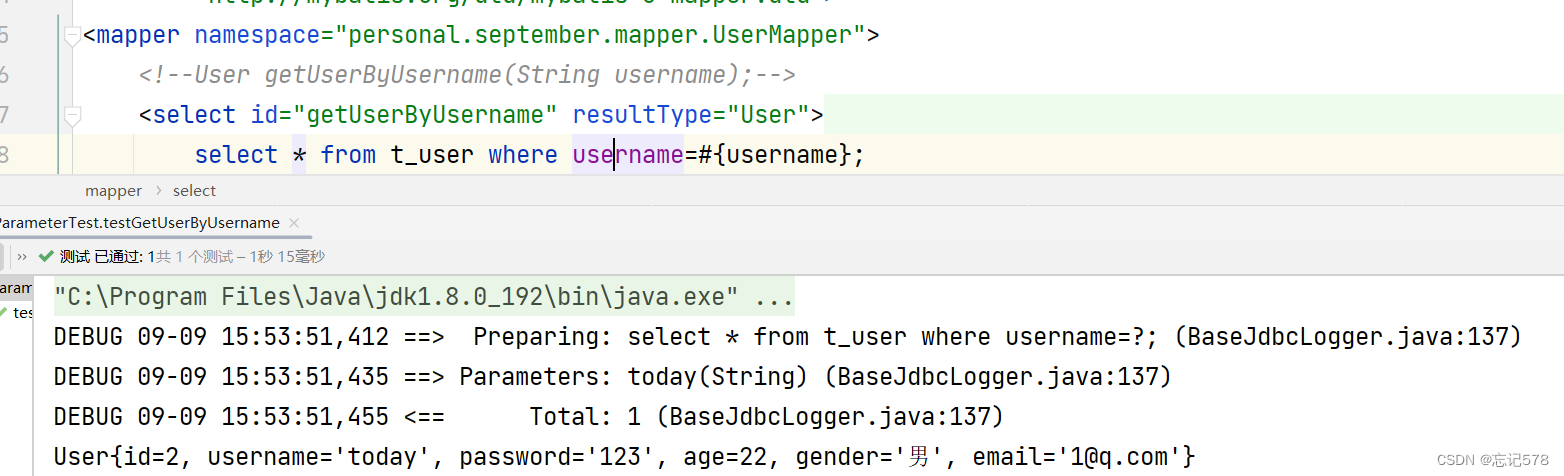
按照第一种情况(只有一个字面量去操作时出现如下报错
在UserMapper接口中创建该查询方法: User checklogin(String username, String password); 创建测试方法: public void testcheckelogin(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.checklogin("haha", "111"); System.out.println(user); }
若mapper接口中的方法参数为多个时
此时MyBatis会自动将这些参数放在一个map集合中,
以arg0,arg1...为键,以参数为值;以param1,param2...为键,以参数为值;
因此只需要通过${}和#{}访问map集合的键就可以获取相对应的值,注意${}需要手动加单引号
可知如下是可以的
select * from t_user where username = #{arg0} and password = #{arg1}; select * from t_user where username = #{param1} and password = #{param2};
上图知,效果等价于: select * from t_user where username = #{arg0} and password = #{arg0}; 而如果想混搭arg和param的正确写法为 select * from t_user where username = #{arg0} and password = #{param2}; select * from t_user where username = #{param1} and password = #{arg1}; (注意param是从1开始,arg是0)如果是${},则记得要加‘’,如下
select * from t_user where username = '${arg0}' and password = '${arg1}';3、map集合类型的参数
若mapper接口中的方法需要的参数为多个时此时可以手动创建map集合,将这些数据放在map中。只需要通过${}和#{}访问map集合的键就可以获取相对应的值,注意${}需要手动加单引号
在UserMapper接口中 User checkLoginByMap(Map<String, Object> map); 创建测试方法: public void testcheckeLoginByMap(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); HashMap<String, Object> map = new HashMap<>(); map.put("username", "haha"); map.put("password","111"); User user = mapper.checkLoginByMap(map); System.out.println(user); }
上图可知我们得要使用我们自己设置得参数名才可以,
如果是${},则记得要加‘ ’,如下
select * from t_user where username = '${username}' and password = '${password}';4、实体类类型的参数
若mapper接口中的方法参数为实体类对象时
此时可以使用${}和#{},通过访问实体类对象中的属性名获取属性值,注意${}需要手动加单引号在UserMapper接口中 void insertUser(User user); 创建测试方法: public void testinsertUser(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user= new User(1, "saturday", "1234567", 22, "女", "99@qq.com"); mapper.insertUser(user); } 在UserMapper.xml中 <insert id="insertUser" > insert t_user values(null,#{username},#{password},#{age},#{gender},#{email}); </insert>
5、使用@Param标识参数
可以通过@Param注解标识mapper接口中的方法参数
此时,会将这些参数放在map集合中,以@Param注解的value属性值为键,以参数为值;以
param1,param2...为键,以参数为值;只需要通过${}和#{}访问map集合的键就可以获取相对应的值,注意${}需要手动加单引号在UserMapper接口中 void checkLoginByParam(@Param("username")String username,@Param("password")String password); 创建测试方法: public void testcheckLoginByParam(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); UserMapper mapper = sqlSession.getMapper(UserMapper.class); User user = mapper.checklogin("what", "234"); System.out.println(user); }
在这种方法中,我们有两种访问方式(username,password)(param1,param2)
所以(username,param2)(param1,password)也是可以的
select * from t_user where username = #{username} and password = #{password}; select * from t_user where username = #{param1} and password = #{param2};






MyBatis的各种查询功能
1、查询一个实体类对象
在SelectMapper接口中 User getUserById(@Param("id")Integer id); List<User> getAllUser(); 创建测试类(同名包下)SelectMapperTest 创建测试方法: public void testGetUserById(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SelectMapper mapper = sqlSession.getMapper(SelectMapper.class); User user = mapper.getUserById(1); System.out.println(user); } public void testGetALLUser(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SelectMapper mapper = sqlSession.getMapper(SelectMapper.class); List<User> allUser = mapper.getAllUser(); allUser.forEach(System.out::println); } 在SelectMapper.xml中 <!--User getUserById(@Param("id")Integer id);--> <select id="getUserById" resultType="User"> select * from t_user where id = #{id}; </select> <!--List<User> getAllUser();--> <select id="getAllUser" resultType="User"> select * from t_user; </select>这个其实就是上面出现过的查询,要注意的是,当我们查询的是多条数据时,返回类型不能是一个实体类。
2、查询单个数据
在SelectMapper接口中 Integer getCount(); 创建测试方法: public void testGetCount(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SelectMapper mapper = sqlSession.getMapper(SelectMapper.class); Integer count = mapper.getCount(); System.out.println(count); } 在SelectMapper.xml中 <select id="getCount" resultType="java.lang.Integer"> select count(*) from t_user; </select>select count(*) from t_user; 其中的*可以是任意的数值,但是如果是字段则要注意,当该字段下的值为null时,不计数, <select id="getCount" resultType="java.lang.Integer"> 其中 resultType的值可以是int,integer,大小写不区分 因为在MyBatis中,对于Java中常用的类型都设置了类型别名 * 例如:java.lang.Integer-->int|integer * 例如:int-->_int|_integer * 例如:Map-->map,List-->list(补充,在看到用integer当方法返回值类型,而不是int时,有点疑惑,于是
包装类型和基本类型的差别(由方法返回值想到的问题)_boolean传参传基本类型还是包装类型_早点起床晒太阳的博客-CSDN博客
3、查询一条数据为map集合
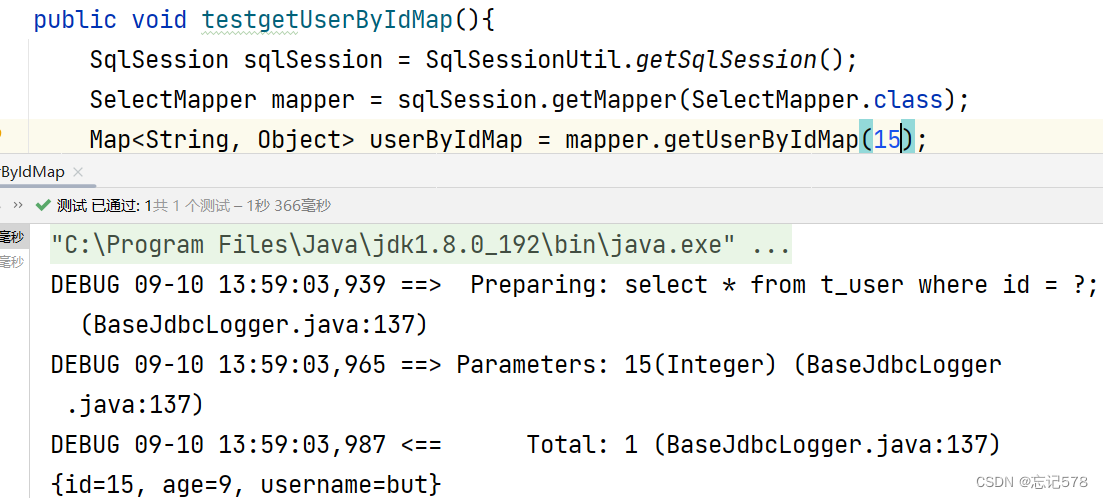
在SelectMapper接口中 Map<String,Object> getUserByIdMap(@Param("id")Integer id); 创建测试方法: public void testgetUserByIdMap(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SelectMapper mapper = sqlSession.getMapper(SelectMapper.class); Map<String, Object> userByIdMap = mapper.getUserByIdMap(2); System.out.println(userByIdMap); } 在SelectMapper.xml中 <select id="getUserByIdMap" resultType="map"> select * from t_user where id = #{id}; </select>
我们要想清楚查询的返回值类型到底是什么,如果是实体类,则其内容就是按照实体类属性呈现,而如果是map集合,不是对应固定的属性输出,有什么内容就输出什么,例如
我创建了最后一条数据,用map集合查询,输出情况如下
4、查询多条数据为map集合(每个数据都是map集合
方式一:
将表中的数据以map集合的方式查询,一条数据对应一个map;若有多条数据,就会产生多个map集合,此时可以将这些map放在一个list集合中获取
在SelectMapper接口中 List<Map<String,Object>> getALlUserToMap(); 创建测试方法: public void testgetALlUserToMap(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SelectMapper mapper = sqlSession.getMapper(SelectMapper.class); List<Map<String, Object>> aLlUserToMap = mapper.getALlUserToMap(); System.out.println(aLlUserToMap); } 在SelectMapper.xml中 <select id="getALlUserToMap" resultType="map"> select * from t_user; </select>
方式二:
将表中的数据以map集合的方式查询,一条数据对应一个map;若有多条数据,就会产生多个map集合,并且最终要以一个map的方式返回数据,此时需要通过@MapKey注解设置map集合的键,值是每条数据所对应的map集合
在SelectMapper接口中 @MapKey("id") Map getALlUserToMap1(); 创建测试方法: public void testgetALlUserToMap(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SelectMapper mapper = sqlSession.getMapper(SelectMapper.class); Map aLlUserToMap1 = mapper.getALlUserToMap1(); System.out.println(aLlUserToMap1); } 在SelectMapper.xml中 <select id="getALlUserToMap1" resultType="map"> select * from t_user; </select>
@MapKey("id"),即是设置以id为键,来输出查询到的多条map数据,以键值对的形式输出, 又因为map的键必须唯一,所以要用主键或唯一索引




特殊SQL的执行
1、模糊查询
在SpecialSQLMapper接口中 List<User> getUserByLike(@Param("mohu") String mohu); 创建测试类(同名包下)SpecialSQLMapperTest 创建测试方法: public void testgetUserByLike(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SpecialSQLMapper mapper = sqlSession.getMapper(SpecialSQLMapper.class); List<User> t = mapper.getUserByLike("t"); System.out.println(t); } 在SpecialSQLMapper.xml中 <select id="getUserByLike" resultType="User"> select * from t_user where username like '%${mohu}%'; </select>
#{}相当于占位符,如上图被解析成问号
方法一:
用${}
select * from t_user where username like '%${mohu}%'; select * from t_user where username like concat('%','${mohu}','%');
在这里使用List集合是因为如果查询多条实体类数据才不会出错
方法二,三:
select * from t_user where username like concat('%',#{mohu},'%'); select * from t_user where username like "%"#{mohu}"%";2、批量删除
在SpecialSQLMapper接口中 void deleteMoreUser(@Param("id")String ids); 创建测试方法: public void testdeleteMoreUser(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SpecialSQLMapper mapper = sqlSession.getMapper(SpecialSQLMapper.class); mapper.deleteMoreUser("14,15"); }error:在SpecialSQLMapper.xml中
<delete id="deleteMoreUser">
delete from t_user where id in(#{id});
</delete>如果是如上用#{id},则最后会被解析成delete from t_user where id in(’14,15‘);加上了单引号。会报错
可以用${},
在SpecialSQLMapper.xml中 <delete id="deleteMoreUser"> delete from t_user where id in(${id}); </delete>
除了这种方法,后面学的动态SQL还可以用它的foreach标签实现如下,达到等同效果
delete from t_user where id = 14 or id =15;3、动态设置表名
在SpecialSQLMapper接口中 List<User> getUserList(@Param("tableName")String tablename); 创建测试方法: public void testGetUserList(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SpecialSQLMapper mapper = sqlSession.getMapper(SpecialSQLMapper.class); List<User> t_user = mapper.getUserList("t_user"); t_user.forEach(System.out::println); } 在SpecialSQLMapper.xml中 <select id="getUserList" resultType="User"> select * from ${tableName}; </select>
记得用了注解后,名字一般都是使用注解取的名为键,如上报错显示param1也可(报错因为我的注解名叫tableName,而我写成select * from ${tablename};
4、添加功能获取自增的主键
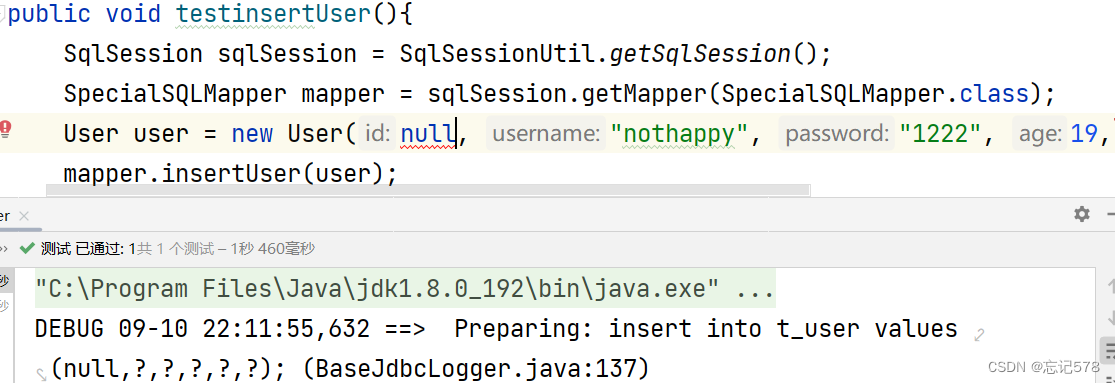
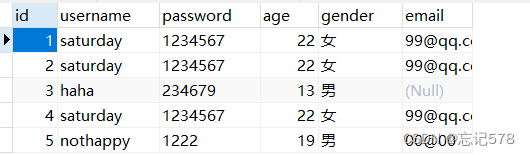
在SpecialSQLMapper接口中 void insertUser(User user); 创建测试方法: public void testinsertUser(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); SpecialSQLMapper mapper = sqlSession.getMapper(SpecialSQLMapper.class); User user = new User(0, "i'm not happy", "1889", 29, "男", "00@00"); mapper.insertUser(user); } 在SpecialSQLMapper.xml中 <insert id="insertUser" useGeneratedKeys="true" keyProperty="id"> insert into t_user values (null,#{username},#{password},#{age},#{gender},#{email}); </insert>useGeneratedKeys:设置使用自增的主键 keyProperty:因为增删改有统一的返回值是受影响的行数, 因此只能将获取的自增的主键放在传输的参数user对象的某个属性中在navicat中创表一开始没有设置自增和自增值为1,发现到后面改不了,而且如下图,无法实现输入null,实现自增功能而不报错
但是还是没找到设置方式,即使重新建表也没有解决。(想要达到那种id输入null,在数据表中插入的数据可以自增。
发现如果null不行,那就每次插入操作都填0就可,在数据表中可以实现自增,且值不为空。







自定义映射resultMap
1、resultMap处理字段和属性的映射关系
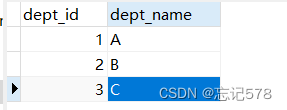
若字段名和实体类中的属性名不一致,则可以通过resultMap设置自定义映射首先我们有如下表t_emp,t_dept
两表对应的实体类中属性名如下
按照我们之前的操作直接查询
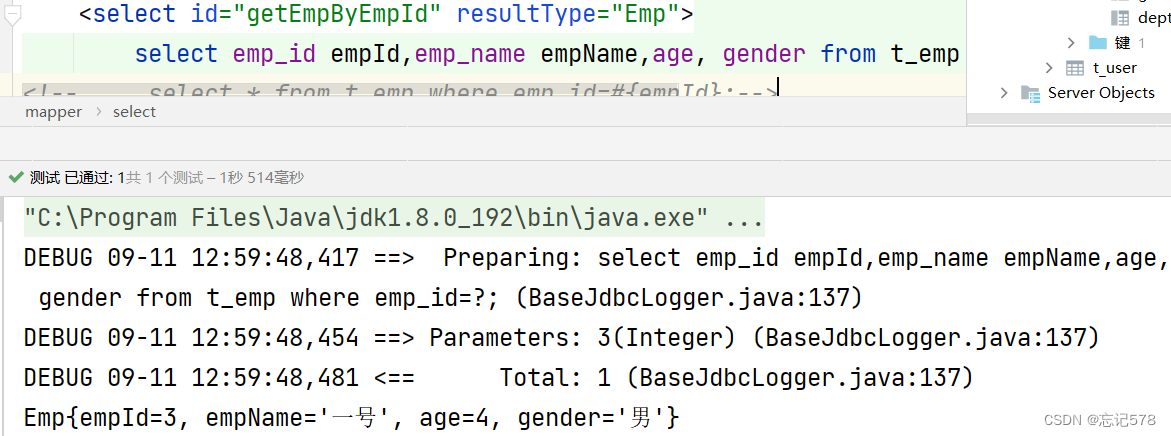
在EmpMapper接口中 Emp getEmpByEmpId(@Param("empId") Integer empId); 创建测试类(同名包下)EmpMapperTest 创建测试方法: public void testgetEmpByEmpId(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); EmpMapper mapper = sqlSession.getMapper(EmpMapper.class); Emp empByEmpId = mapper.getEmpByEmpId(3); System.out.println(empByEmpId); } 在SpecialSQLMapper.xml中 <select id="getEmpByEmpId" resultType="Emp"> select * from t_emp where emp_id=#{empId}; </select>
可以发现并没有完整查询出id为3的那行记录。但是age、gender可以,因为字段名和属性名相同,而其他不同,没有映射关系。(所以我们需要通过如下方法处理映射关系)
方法一:
如下解决,通过取别名的方式,对应属性名
<select id="getEmpByEmpId" resultType="Emp"> select emp_id empId,emp_name empName,age, gender from t_emp where emp_id=#{empId}; </select>
(注意注解用<!-- -->,刚这个select标签下用#注解一条信息,在运行时出错。
方法二:
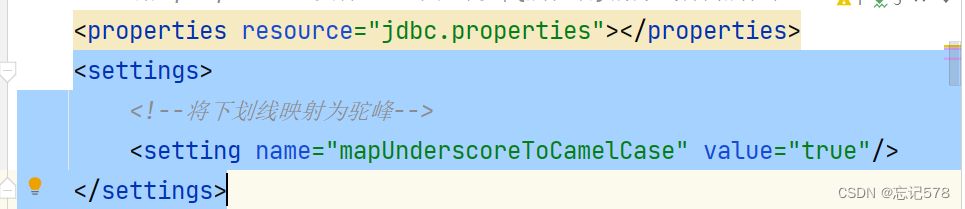
可以在MyBatis的核心配置文件中设置一个全局配置信息mapUnderscoreToCamelCase,可
以在查询表中数据时,自动将_类型的字段名转换为驼峰
例如:字段名user_name,设置了mapUnderscoreToCamelCase,此时字段名就会转换为
userName在mybatis-config.xml文件中,注意标签放置顺序
在EmpMapper.xml文件中: <select id="getEmpByEmpId" resultType="Emp"> select * from t_emp where emp_id=#{empId}; </select>就可以顺利查询,但是这只是实现了取名用_取名的相似特点来转换名字,还是有点缺陷,需要和字段很好的对应。
方法三:
使用resultMap自定义映射处理
在EmpMapper.xml文件中:利用resultMap标签,为字段和属性建立映射关系
<!--resultMap:设置自定义映射 属性: id:表示自定义映射的唯一标识 type:查询的数据要映射的实体类的类型 子标签: id:设置主键的映射关系 result:设置普通字段的映射关系 association:设置多对一的映射关系 collection:设置一对多的映射关系 属性: property:设置映射关系中实体类中的属性名 column:设置映射关系中表中的字段名 --> <resultMap id="empResultMap" type="Emp"> <id column="emp_id" property="empId"></id> <result column="emp_name" property="empName"></result> </resultMap> <!--Emp getEmpByEmpId(@Param("empId") Integer empId);--> <select id="getEmpByEmpId" resultMap="empResultMap"> select * from t_emp where emp_id=#{empId}; </select>主要是要注意一些属性的用法
2、多对一映射处理
比如:查询员工信息以及员工所对应的部门信息
如下图,我们可以发现,按照之前的操作,我们得出dept=null(在emp实体类中添加了Dept dept这个成员变量)
因为我们查询的是dept_id和dept_name这两个属性,其映射的是deptId和deptName这两个属性,但是上述操作直接映射到Dept这个类型。但是我们查询到的没有可以和实体类型Dept对应的,所以该值为null。
方法一:
级联方式处理映射关系
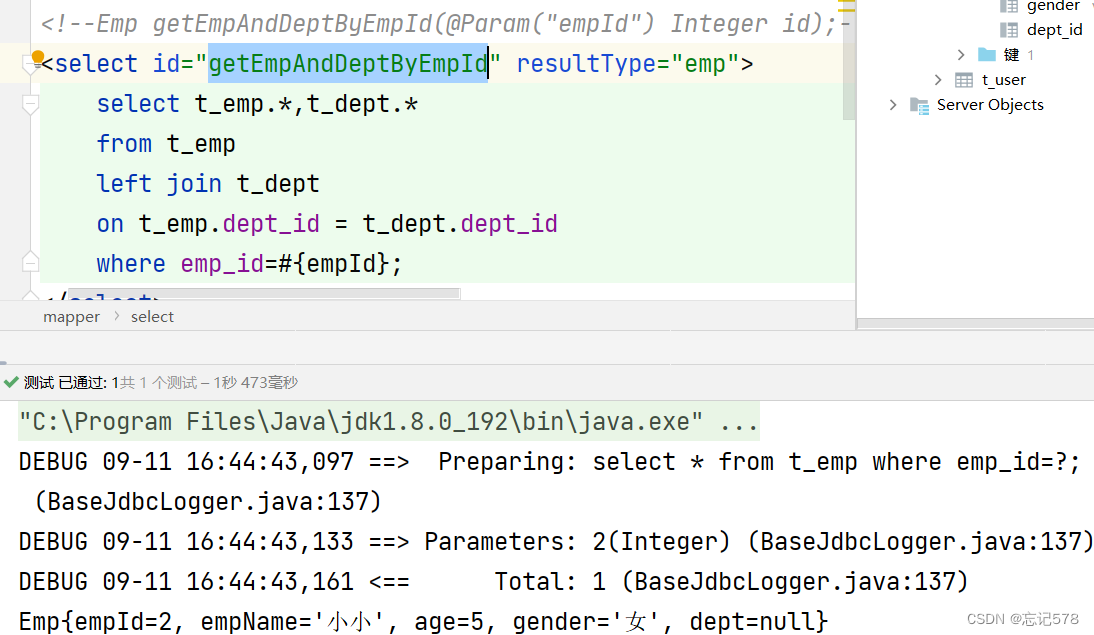
在EmpMapper接口中 Emp getEmpAndDeptByEmpId(@Param("empId") Integer id); 创建测试方法: public void testgetEmpAndDeptByEmpId(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); EmpMapper mapper = sqlSession.getMapper(EmpMapper.class); Emp empByEmpId = mapper.getEmpAndDeptByEmpId(2); System.out.println(empByEmpId); } 在SpecialSQLMapper.xml中 <resultMap id="empAndDeptResultMap" type="Emp"> <id column="emp_id" property="empId"></id> <result column="emp_name" property="empName"></result> <result column="age" property="age"></result> <result column="gender" property="gender"></result> <result column="dept_id" property="dept.deptId"></result> <result column="dept_name" property="dept.deptName"></result> </resultMap> <!--Emp getEmpAndDeptByEmpId(@Param("empId") Integer id);--> <select id="getEmpAndDeptByEmpId" resultMap="empAndDeptResultMap"> select t_emp.*,t_dept.* from t_emp left join t_dept on t_emp.dept_id = t_dept.dept_id where emp_id=#{empId}; </select>
(试了一下不把所有属性列出来其实也可以,因为本来名字就一样,在操作时发现可以查询到age,gender。)
方法二:
使用association处理映射关系
<resultMap id="empAndDeptResultMap" type="Emp"> <id column="emp_id" property="empId"></id> <result column="emp_name" property="empName"></result> <result column="age" property="age"></result> <result column="gender" property="gender"></result> <!-- association:处理一对多的映射关系(处理实体类类型的属性) property:设置需要处理映射关系的属性的属性名 javaType:设置要处理的属性的类型 --> <association property="dept" javaType="Dept"> <id column="dept_id" property="deptId"></id> <result column="dept_name" property="deptName"></result> </association> </resultMap>方法三:
分步查询
创建一个DeptMapper接口,映射文件DeptMapper.xml,
在DeptMapper接口中 Dept getEmpAndDeptByStepTwo(@Param("deptId") Integer deptId); 创建测试方法: public void testgetEmpAndDeptByStep(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); EmpMapper mapper = sqlSession.getMapper(EmpMapper.class); Emp empByEmpId = mapper.getEmpAndDeptByStepOne(2); System.out.println(empByEmpId); } 在DeptMapper.xml中 <select id="getEmpAndDeptByStepTwo" resultType="Dept"> select * from t_dept where dept_id=#{deptId}; </select>(需要注意的是在Dept查询部分,我们使用的是设置驼峰来实现字段和属性的映射,可能上面的信息没有体现出来)
在Emp查询部分中:
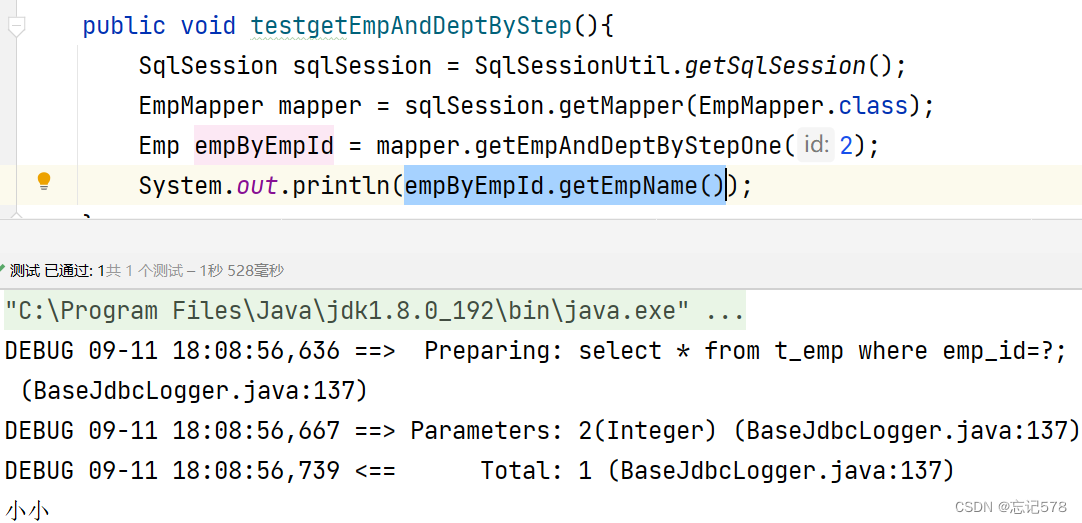
在EmpMapper接口中 Emp getEmpAndDeptByStepOne(@Param("empId") Integer id); 在EmpMapper.xml中 <resultMap id="empAndDeptByStepResultMap" type="Emp"> <id column="emp_id" property="empId"></id> <result column="emp_name" property="empName"></result> <result column="age" property="age"></result> <result column="gender" property="gender"></result> <association property="dept" select="personal.september.resultmap.mapper.DeptMapper.getEmpAndDeptByStepTwo" column="dept_id"></association> </resultMap> <!--Emp getEmpAndDeptByStepOne(@Param("empId") Integer id);--> <select id="getEmpAndDeptByStepOne" resultMap="empAndDeptByStepResultMap"> select * from t_emp where emp_id=#{empId}; </select>Emp查询部分为第一步查询,在association中的select填写的是sql的唯一标识(namespace.sqlid),其实就是当前接口的全类名.方法名。(设置分步查询,查询某个属性的值的sql的标识)
column填写的是查询条件,由下一步作为查询条件的字段,从第一个sql语句查询出来的结果中的某个字段作为下一个查询条件。而这里需要作为条件查询的就是dept_id。(将sql以及查询结果中的某个字段设置为分步查询的条件)
延迟加载:
分步查询的优点:可以实现延迟加载,但是必须在核心配置文件中设置全局配置信息: lazyLoadingEnabled:延迟加载的全局开关。当开启时,所有关联对象都会延迟加载 aggressiveLazyLoading:当开启时,任何方法的调用都会加载该对象的所有属性。 否则,每个属性会按需加载 此时就可以实现按需加载,获取的数据是什么,就只会执行相应的sql。此时可通过association和collection中的fetchType属性设置当前的分步查询是否使用延迟加载,fetchType="lazy(延迟加载)|eager(立即加载)"当我们只是查询员工的名字时,设置了延迟加载出现的结果如下:
没有设置则是
如上可以看出,设置了延迟加载只会运行我们需要查询的,而没有设置则是全部代码都运行了(第一步可以得到我们想要的结果,没有延迟加载时,两步都执行了)
在开启了延迟加载的环境中,通过该属性设置当前分布查询是否使用延迟加载
fetchType="lazy(延迟加载)|eager(立即加载)"
所以可以在settings标签中加上如下最后两条内容即可(它们两个默认值为false
如果按需加载为true,则不管要查询什么,即使是开启了延迟加载,都会将所有代码都执行。所以延迟加载的设置即使只要lazyLoadingEnabled就可以开启,但是也和aggressiveLazyLoading有关。
3、一对多映射处理
比如:根据部门id查新部门以及部门中的员工信息
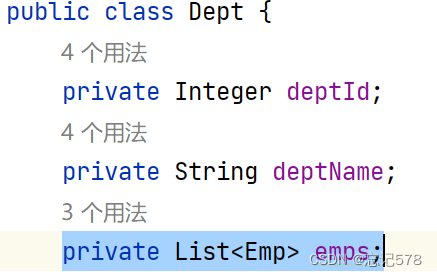
(按照对一,对应对象,对多对应集合的说法,所以一对多是对应集合,我们要在Dept实体类中新增一个集合,
方法一:
用collection处理映射关系
在DeptMapper接口中 Dept getDeptAndEmptByDeptId(@Param("deptId") Integer deptId); 在DeptMapper.xml中 <resultMap id="deptAndEmpResultMap" type="Dept"> <id column="dept_id" property="deptId"></id> <result column="dept_name" property="deptName"></result> <!-- ofType:设置collection标签所处理的集合属性中存储数据的类型 --> <collection property="emps" ofType="Emp"> <id column="emp_id" property="empId"></id> <result column="emp_name" property="empName"></result> <result column="age" property="age"></result> <result column="gender" property="gender"></result> </collection> </resultMap> <!--Dept getDeptAndEmptByDeptId(@Param("deptId") Integer deptId);--> <select id="getDeptAndEmptByDeptId" resultMap="deptAndEmpResultMap"> select * from t_dept left join t_emp on t_dept.dept_id =t_emp.dept_id where t_dept.dept_id=#{deptId}; </select> 创建测试方法: public void testgetDeptAndEmptByDeptId(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); DeptMapper mapper = sqlSession.getMapper(DeptMapper.class); Dept deptAndEmptByDeptId = mapper.getDeptAndEmptByDeptId(1); System.out.println(deptAndEmptByDeptId); }
方法二:
分步查询
第一步查询部门信息
在Dept部分查询中
在DeptMapper接口中 Dept getDeptAndEmpByStepOne(@Param("deptId") Integer deptId); 在DeptMapper.xml中 <resultMap id="deptAndEmpByStep" type="Dept"> <id column="dept_id" property="deptId"></id> <result column="dept_name" property="deptName"></result> <collection property="emps" select="personal.september.resultmap.mapper.EmpMapper.getDeptAndEmpByStepTwo" column="dept_id"></collection> </resultMap> <!--Dept getDeptAndEmpByStepOne(@Param("deptId") Integer deptId);--> <select id="getDeptAndEmpByStepOne" resultMap="deptAndEmpByStep"> select * from t_dept where dept_id=#{deptId}; </select> 创建测试方法: public void testgetDeptAndEmpByStepOne(){ SqlSession sqlSession = SqlSessionUtil.getSqlSession(); DeptMapper mapper = sqlSession.getMapper(DeptMapper.class); Dept deptAndEmpByStepOne = mapper.getDeptAndEmpByStepOne(1); System.out.println(deptAndEmpByStepOne); }第二步,根据部门id查询部门中的所有员工
在Emp查询部分中
在EmpMapper接口中 List<Emp> getDeptAndEmpByStepTwo(@Param("deptId") Integer id); 在EmpMapper.xml中 <select id="getDeptAndEmpByStepTwo" resultType="Emp"> select * from t_emp where dept_id=#{deptId}; </select>(注意:
在接口中的这个方法的返回值是List集合,我们选择的类型要和Dept实体类中创造的List<Emp> emps类型相对应。因为我们是把在collection标签的select属性中查询出的结果赋值给emps,所以类型是要相同的。
还有在mybatis-config.xml文件中我们已经设置了将下划线映射为驼峰,所以emp中属性名
和字段可以一一对应)
最后得到结果