在了解FastChat如何完成大模型部署前,先了解下Huggingface提供的Transformer库。
Hugggingface提供的Transformer库
Hugging Face 的 Transformers 库是一个用于自然语言处理(NLP)任务的 Python 库,旨在简化和加速使用预训练语言模型(如BERT、GPT-2等)的开发和应用。这个库的主要作用包括:
预训练模型的加载和使用: Transformers 库提供了易于使用的接口,允许用户加载各种预训练语言模型,如BERT、GPT-2、T5等。这些模型在大规模文本数据上进行了预训练,并可以用于各种自然语言处理任务,如文本分类、命名实体识别、文本生成等。
文本编码和解码: Transformers 库提供了文本编码和解码功能,可以将文本数据转换为模型可以理解的输入,并将生成的输出转换回文本。这对于处理不同任务的输入和输出数据非常有用。
支持多种任务: 该库支持多种自然语言处理任务,并提供了预训练模型的封装,以便用户可以轻松地在这些任务上进行微调和应用。这些任务包括文本分类、情感分析、命名实体识别、机器翻译等。
模型微调: Transformers 库允许用户对预训练模型进行微调,以适应特定的任务或领域。这使得用户可以在有限的数据集上实现高性能的自然语言处理应用。
模型交流和共享: Hugging Face 的 Transformers Hub 提供了一个平台,允许用户分享、发布和发现预训练模型和相关资源。这有助于加速 NLP 社区的发展和合作。
支持多种深度学习框架: Transformers 库支持多种深度学习框架,包括PyTorch、TensorFlow和JAX,以满足不同用户的需求。
以通过HuggingFace提供的Tranformer加载和使用预训练大模型为例,下面的代码加载了Bert模型,首先是加载了Bert模型的BertTokennizer用户后面对输入输出新的encode和decode,接着是通过model_name来加载大模型。
# 安装 Transformers 库(如果尚未安装)
# pip install transformers
from transformers import BertTokenizer, BertForSequenceClassification
import torch
# 1. 加载预训练的BERT模型和标记器
model_name = "bert-base-uncased" # 预训练模型的名称
tokenizer = BertTokenizer.from_pretrained(model_name)
model = BertForSequenceClassification.from_pretrained(model_name)
# 2. 准备输入文本
text = "Hugging Face Transformers库使自然语言处理变得非常容易。"
# 3. 使用标记器对文本进行编码
inputs = tokenizer(text, return_tensors="pt")
# 4. 使用模型进行文本分类
outputs = model(**inputs)
logits = outputs.logits
# 5. 打印分类结果
print(logits)
再看国内开源大模型的部署加载命令,以ChatGLM大模型为例。通过下面的代码可以看到,实际也是通过Huggingface提供的transformer库完成的模型下载和使用。即先将大模型相关信息上传到huggingface,后续任何人要下载启动大模型,就可以通过下面的两行代码完成大模型的下载和部署。
AutoTokenizer.from_pretrained 是 Hugging Face Transformers 库中的一个方法,用于从预训练模型的名称或路径加载适当的标记器(Tokenizer)。
AutoModel.from_pretrained 是 Hugging Face Transformers 库中的一个方法,用于从预训练模型的名称或路径加载适当的模型。
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("THUDM/chatglm-6b", trust_remote_code=True).half().cuda()
model = model.eval()
response, history = model.chat(tokenizer, "你好", history=[])
print(response)查看HuggingFace上面的ChatGLM大模型上传的信息,可以看到大模型的参数文件都可以在Huggingface上查询到,具体如下图所示:

理解了前面的信息后,再来看FastChat如何完成各种开源大模型的部署,本质上就是对原来的开源模型部署命令进行了二次封装。FastChat是通过执行“python3 -m fastchat.serve.model_worker --model-path lmsys/vicuna-7b-v1.3”命令部署模型的,所以先来看一下model_worker这个文件的大致内容。
查看model_worker.py中的内容,部分内容如下图所示,可以看到在接口/v1/chat/completions里面又继续进行的请求调用。

按照调用的方法一层一层往下看,会发现model_work.py中的代码调用了controller文件中的代码。controller.py文件中的部分代码内容如下图所示:
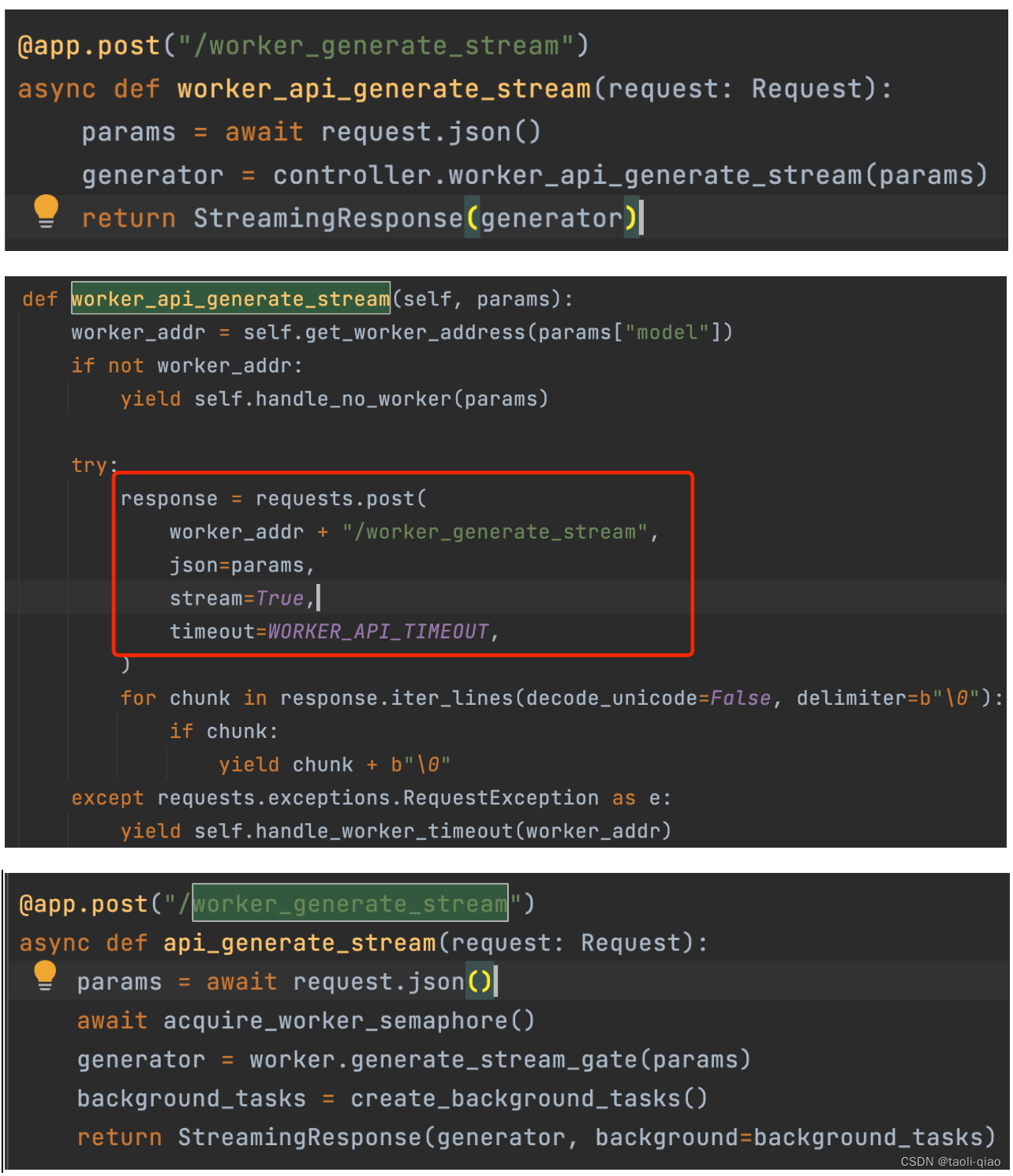
在查看controller.py中的代码时,会发现该文件中方法调用了model_adapter.py文件中的方法,而model_adapter又调用了model_chatglm.py文件中方法。以初始化model为例子,层层往下看后,会发现最终load_model方法中的内容,和直接编写脚本load model的方式一样,具体内容如下图红框所示,红框中的内容和大模型官网本身提供的部署命令相同。

除了初始化加载启动大模型,FastChat还封装了api,如果从model_work中查看,一层层往下看,最终会看到如下的代码,下面的代码通过调用model.chat()方法与大模型交互。FastChat提供了兼容OpenAPI的接口,本质上也是进行了二次封装而已。

查看FastChat官网给出的架构图,可以知道,当有用户的请求发送过来时,首先到Gradio Server,也就是前端UI服务,再通过Controller与Worker交互。

从源代码层面来看,主要的代码集中在controller.py,model_worker.py,model_adapter.py,model_xxx.py几个文件中。

通过上面的分析可以看到,FastChat在支持大模型部署和提供兼容OpenAPI的接口方面,主要是对原有的开源大模型进行了二次封装,让用户在通过FastChat进行大模型部署和使用时更加方便。

![[论文阅读]Visual Attention Network原文翻译](https://img-blog.csdnimg.cn/b8d180791c6842fea3903e3234786f9f.png)
![怎样获取字符串数组的长度_使用sizeof(array) / sizeof(array[0])](https://img-blog.csdnimg.cn/04274023ac8c40b2b8b92698ae9a139e.png)






![buuctf crypto 【[GXYCTF2019]CheckIn】解题记录](https://img-blog.csdnimg.cn/13db7a3a1ff542399b1ad14636b5ea1f.png)
