系列文章目录
【跟小嘉学 Apache Flink】一、Apache Flink 介绍
【跟小嘉学 Apache Flink】二、Flink 快速上手
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 一、创建工程
- 1.1、创建 Maven 工程
- 1.2、log4j 配置
- 二、批处理单词统计(DataSet API)
- 2.1、创建 BatchWordCount 类型
- 2.4、运行结果
- 三、流处理单词统计(DataSet API)
- 3.1、读取文件流
- 3.1.1、过时的写法
- 3.1.2、执行错误的处理
- 3.1.3、执行结果
- 3.1.4、readTextFile 过时问题
- 3.2、读取 socket 网络流
- 3.2.1、读取socket 流代码
- 3.2.2、使用 nc 监听端口
- 3.2.3、执行结果
- 3.2.4、从命令行参数获取主机名和端口号
文章目录
- 系列文章目录
- @[TOC](文章目录)
- 一、创建工程
- 1.1、创建 Maven 工程
- 1.2、log4j 配置
- 二、批处理单词统计(DataSet API)
- 2.1、创建 BatchWordCount 类型
- 2.4、运行结果
- 三、流处理单词统计(DataSet API)
- 3.1、读取文件流
- 3.1.1、过时的写法
- 3.1.2、执行错误的处理
- 3.1.3、执行结果
- 3.1.4、readTextFile 过时问题
- 3.2、读取 socket 网络流
- 3.2.1、读取socket 流代码
- 3.2.2、使用 nc 监听端口
- 3.2.3、执行结果
- 3.2.4、从命令行参数获取主机名和端口号
一、创建工程
1.1、创建 Maven 工程
创建 maven 工程 并且添加如下依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.xiaojia</groupId>
<artifactId>flinkdemo</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<properties>
<maven.compiler.source>19</maven.compiler.source>
<maven.compiler.target>19</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-streaming-java -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java</artifactId>
<version>1.17.1</version>
</dependency>
<!-- https://mvnrepository.com/artifact/org.apache.flink/flink-clients -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients</artifactId>
<version>1.17.1</version>
</dependency>
</dependencies>
</project>
1.2、log4j 配置
在 resource 目录下创建 log4j.properties 文件,写入如下内容
log4j.rootLogger=error,stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%-4r [%t] %-5p %c %x - %m%n
二、批处理单词统计(DataSet API)
2.1、创建 BatchWordCount 类型
package org.xiaojia.demo.wc;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.AggregateOperator;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.FlatMapOperator;
import org.apache.flink.api.java.operators.UnsortedGrouping;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class BatchWordCount {
public static void main(String[] args) {
// 1、创建执行环境
ExecutionEnvironment executionEnvironment = ExecutionEnvironment.getExecutionEnvironment();
// 2、 从文件读取数据
DataSource<String> lineDataSource = executionEnvironment.readTextFile("input/words.txt");
// 3、将每一行数据进行分词,转换为二元组类型
FlatMapOperator<String, Tuple2<String, Long>> wordAndOneTuple = lineDataSource.flatMap((String line, Collector<Tuple2<String, Long>> collector) -> {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4、按照 word 进行分组
UnsortedGrouping<Tuple2<String, Long>> wordAndOneGroup = wordAndOneTuple.groupBy(0);
// 5、分组内进行聚合统计
AggregateOperator<Tuple2<String, Long>> sum = wordAndOneGroup.sum(1);
try {
sum.print();
} catch (Exception e) {
throw new RuntimeException(e);
}
}
}
2.4、运行结果

实际上在 Flink 里面已经做到流批处理统一,官方推荐使用 DateStream API,在跳任务时通过执行模式设置为 Batch 来进行批处理
bin/fliink run -Dexecution.runtime-mode=BATCH BatchWordCount.jar
三、流处理单词统计(DataSet API)
使用 DataSet API可以很容易实现批处理。对于Flink而言,流处理才是处理逻辑的底层核心,所以流批统一之后的 DataStream API 更加强大,可以直接处理批处理和流处理的所有场景。
在 Flink 的视角里,一切数据都可以认为是流,流数据是无界流,而批数据是有界流。所以批处理,其实可以看作是有界流的处理。
3.1、读取文件流
3.1.1、过时的写法
package org.xiaojia.demo.wc.stream;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class BoundStreamWordCount {
public static void main(String[] args) throws Exception {
// 1、创建流式的执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取文件
DataStreamSource<String> lineDataStreamSource = streamExecutionEnvironment.readTextFile("input/words.txt");
// 3、将每一行数据进行分词,转换为二元组类型
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> collector) -> {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4、按照 word 进行分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyStream = wordAndOneTuple.keyBy((data) -> data.f0);
// 5、求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyStream.sum(1);
// 6、打印
sum.print();
// 7、执行等待
streamExecutionEnvironment.execute();
}
}
3.1.2、执行错误的处理
Unable to make field private final byte[] java.lang.String.value accessible: module java.base does not "opens java.lang" to unnamed module
@7ce6a65d
如果出现上述类似错误,解决方案,通过添加 VM参数打开对应模块的对应模块包
--add-opens java.base/java.lang=ALL-UNNAMED
--add-opens java.base/java.util=ALL-UNNAMED

3.1.3、执行结果

3.1.4、readTextFile 过时问题

解决方案可以按照提示给出的 使用 FileSource(需要用到Flink的连接器)
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-files</artifactId>
<version>${flink.version}</version>
</dependency>
3.2、读取 socket 网络流
3.2.1、读取socket 流代码
package org.xiaojia.demo.wc.stream;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1、创建流式的执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取socket流
String hostname = "127.0.0.1";
int port = 8888;
DataStreamSource<String> lineDataStreamSource = streamExecutionEnvironment.socketTextStream(hostname, port);
// 3、将每一行数据进行分词,转换为二元组类型
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> collector) -> {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4、按照 word 进行分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyStream = wordAndOneTuple.keyBy((data) -> data.f0);
// 5、求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyStream.sum(1);
// 6、打印
sum.print();
// 7、执行等待
streamExecutionEnvironment.execute();
}
}
3.2.2、使用 nc 监听端口
(base) xiaojiadeMacBook-Pro:~ xiaojia$ nc -lk 8888
hello java
hello flink
hello world
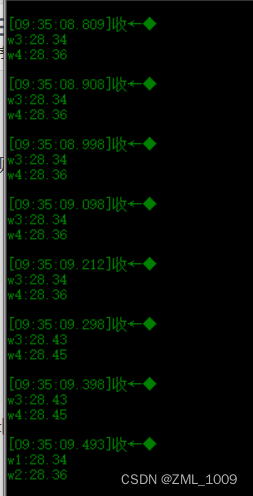
3.2.3、执行结果

此时,只要有数据进来,就会统计
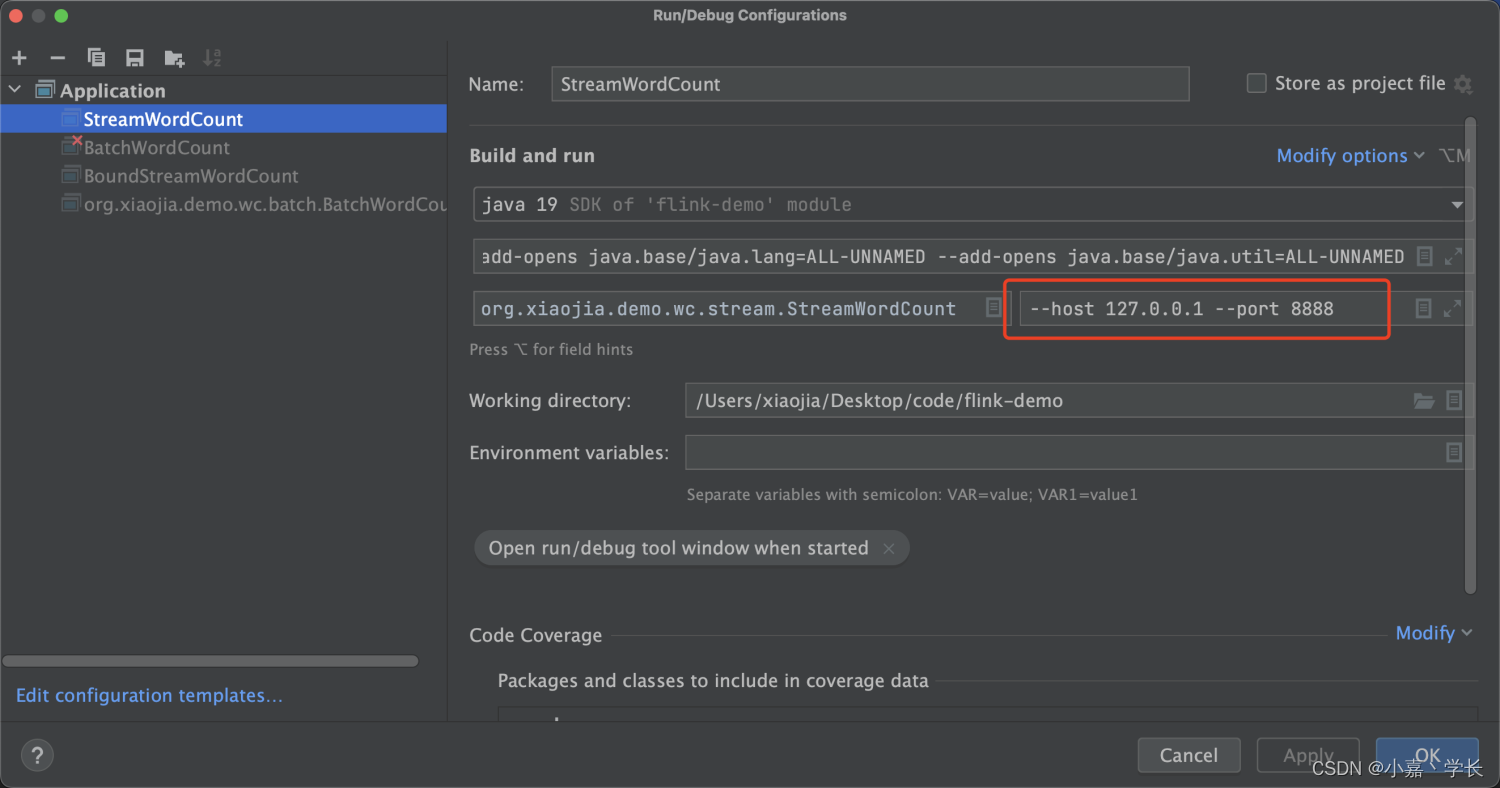
3.2.4、从命令行参数获取主机名和端口号
package org.xiaojia.demo.wc.stream;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.api.java.utils.ParameterTool;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.datastream.KeyedStream;
import org.apache.flink.streaming.api.datastream.SingleOutputStreamOperator;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.util.Collector;
public class StreamWordCount {
public static void main(String[] args) throws Exception {
// 1、创建流式的执行环境
StreamExecutionEnvironment streamExecutionEnvironment = StreamExecutionEnvironment.getExecutionEnvironment();
// 2、读取socket流
ParameterTool parameterTool = ParameterTool.fromArgs(args);
String hostname = parameterTool.get("host");
int port = parameterTool.getInt("port");
DataStreamSource<String> lineDataStreamSource = streamExecutionEnvironment.socketTextStream(hostname, port);
// 3、将每一行数据进行分词,转换为二元组类型
SingleOutputStreamOperator<Tuple2<String, Long>> wordAndOneTuple = lineDataStreamSource.flatMap((String line, Collector<Tuple2<String, Long>> collector) -> {
String[] words = line.split(" ");
for (String word : words) {
collector.collect(Tuple2.of(word, 1L));
}
}).returns(Types.TUPLE(Types.STRING, Types.LONG));
// 4、按照 word 进行分组
KeyedStream<Tuple2<String, Long>, String> wordAndOneKeyStream = wordAndOneTuple.keyBy((data) -> data.f0);
// 5、求和
SingleOutputStreamOperator<Tuple2<String, Long>> sum = wordAndOneKeyStream.sum(1);
// 6、打印
sum.print();
// 7、执行等待
streamExecutionEnvironment.execute();
}
}
命令行参数传递