目录
写在开头
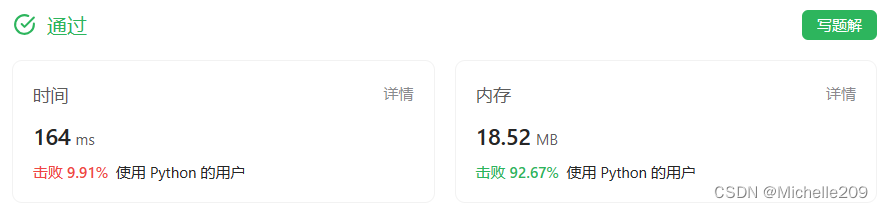
CPU的结构
功能的角度
程序员的角度
寄存器与程序的执行流程
程序计数器
条件分支与循环
函数的调用流程
通过地址和索引实现数组
CPU的处理过程
结尾
写在开头
近期经他人推荐,正在阅读《程序是怎样跑起来的》这本书(作者:矢泽久雄)。感觉这本书虽然出版日期有些老旧,但还是写的很通俗,不愧是计算机组成原理的图解趣味版。作为一个非科班出身的计算机相关从业者而言,感觉本书作为一个计算机组成原理的简易速成教材还是蛮不错的,干脆我就在这里做个读书总结,也重新补一补基础(主要自己还是太菜了)。我阅读本书感觉体验还是比较轻松的,首先这本书不算特别厚,没有很大的阅读心理负担,书中也有很多图表等解释各种概念与原理、也举出了很多例子方便我们理解,总之我也比较推荐。估计沉下心来读的话两三天就能看完。不过咱也不图快,慢慢总结总结,共同进步。

程序的一般运行流程如图1-1。本书第一章主要介绍用于解释和运行程序的CPU(Central Processing Unit中央处理器)。本章主要描述CPU是怎样运行的,核心是寄存器的机制。

CPU的结构
功能的角度
寄存器:可用来暂存指令、数据等处理对象。CPU内部有很多个寄存器。
控制器:负责把内存上的指令、数据等读入寄存器, 并根据指令的执行结果来控制整个计算机。
运算器:负责运算从内存读 入寄存器的数据。
时钟:负责发出 CPU 开始计时的时钟信号。不过,也有些计算机的时钟位于 CPU 的外部。
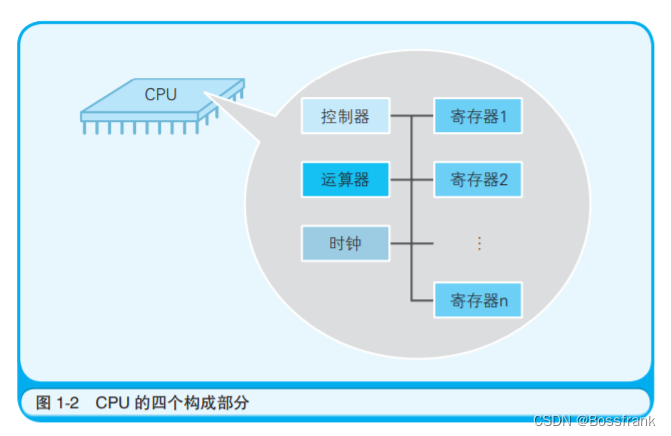
从CPU内部各模块的组成与功能理解程序的运行机制:
程序启动后,根据时钟信号,控制器会从内存中读取指令和数据。通过对这些指令加以解释和执行,运算器就会对数据进行运算,控制器根据运算结果来控制计算机。
所谓控制,大家不要想的太复杂,就是指数据运算外的处理 ,主要是数据输入输出的时机控制,内存和磁盘等媒介的输入输出、键盘鼠标的输入、显示器打印机的输出等。
程序员的角度
CPU是寄存器的集合体。程序员只要关注寄存器即可,因为程序是将寄存器作为对象来描述的。 本书给出了一段代码示例说明这一点:

示例代码中的ebp和eax都是寄存器,由代码示例可以看出,机器语言级别的程序是通过寄存器来处理的。 顺道一提,本书通常采用汇编语言描述程序的逻辑,这是因为机器语言(01010101这种)对于我们人来不太好理解,而汇编语言中与机器语言基本上是一一对应的,因此虽然CPU实际解释执行的是01这样的机器语言,本书还是采用汇编语言对程序逻辑进行描述。
不同类型的CPU其内部的寄存器数量、种类、寄存器存储的数值范围都有所不同。寄存器中存储的内容既可以是指令也可以是数据,数据又分为“用于运算的数值”(往往放在累加寄存器器中)和“表示内存地址的数值”(通常存放在基址寄存器和变址寄存器中)。寄存器的主要分类和功能如表1-1:
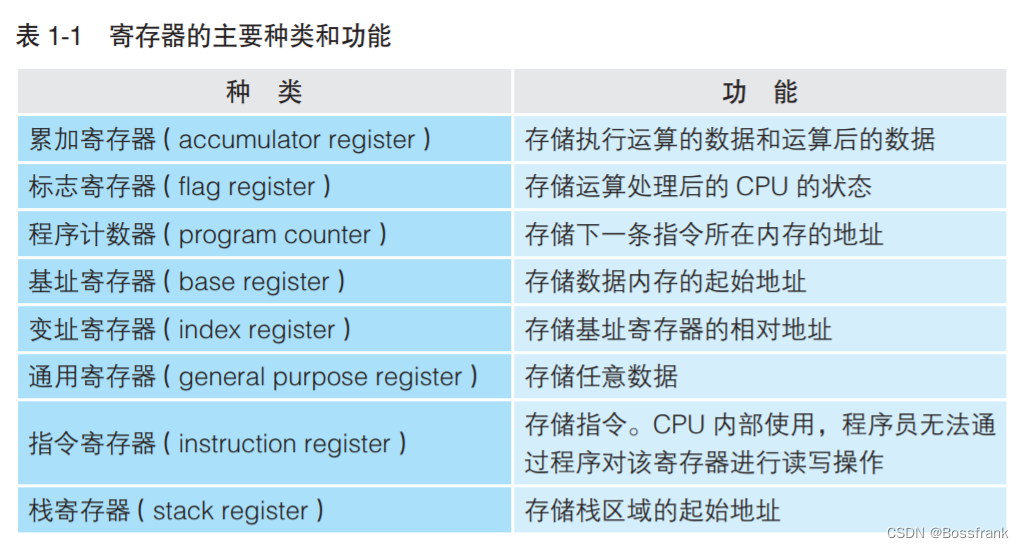
而需要程序员需要关注的寄存器如下:
 程序员主要关注这六个寄存器即可。
程序员主要关注这六个寄存器即可。
寄存器与程序的执行流程
程序计数器
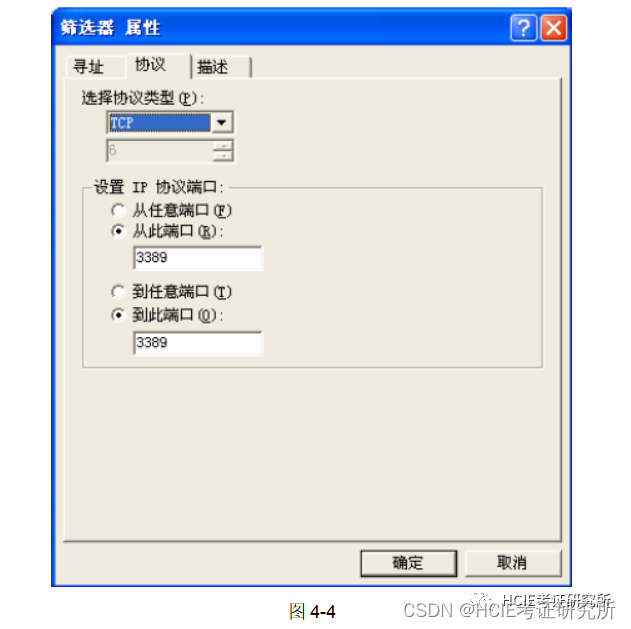
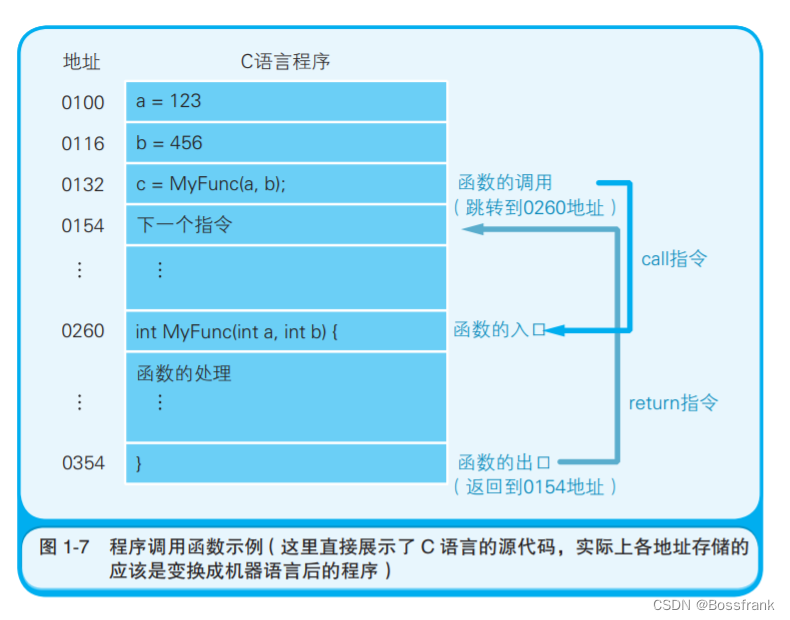
程序计数器存储了下一条指令所在内存的地址,CPU的控制器就会参照程序计数器的数值,从内 存中读取命令并执行(CPU每执行一条指令,程序计数器就会增加与指令内存长度相应的数值)。也就是说,程序计数器决定着程序的流程。图1-4给出了一个程序的运行流程:
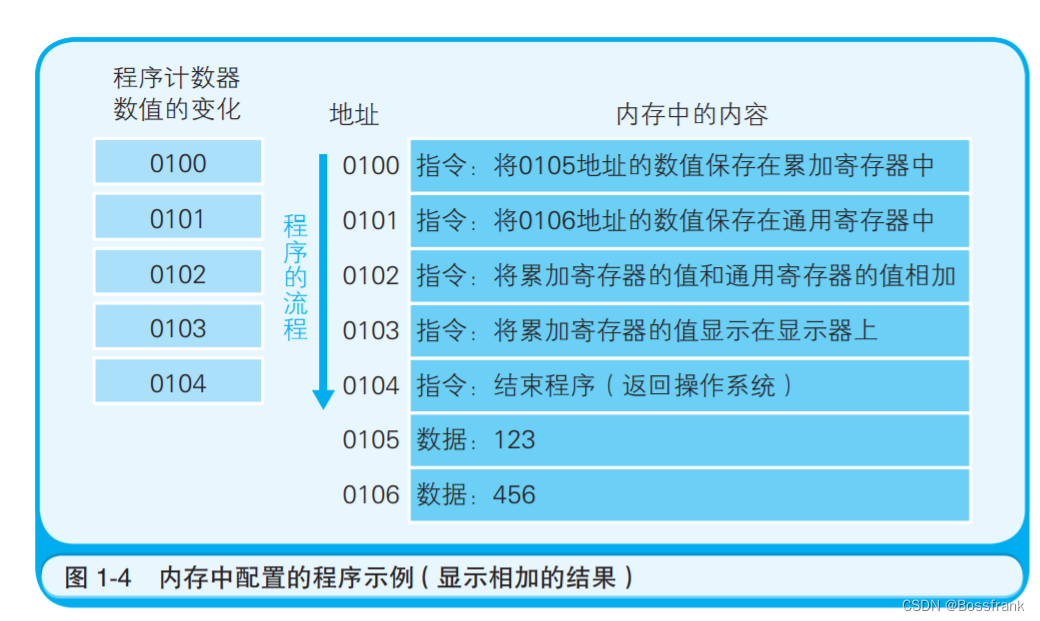
这个程序实现了将123和456两个数值相加,并将结果输出到显示器上。用户发出启动程序的指示 后,Windows 等操作系统会把硬盘中保存的程序复制到内存中。 由于使用机器语言难以清晰地表明各地址存储的内容,因此这里作者对各地址的存储内容添加了注释。实际上,一个命令和数据通常被存储在多个地址上,但为了便于说明,图 1-4 中把指令、数据分配到了一个地址中。
条件分支与循环
程序的执行流程大家肯定都知道,这里列一下:
顺序执行:是指按照地址内容的顺序执行指令。每执行一个指令程序计数器的值就自动加1,此处的1表示内存单位。
条件分支:是指根据条件执行任意地址的指令。
循环:是指重复执行同一地址的指令。
这里给出一个条件分支的程序执行流程示例,如图1-5:
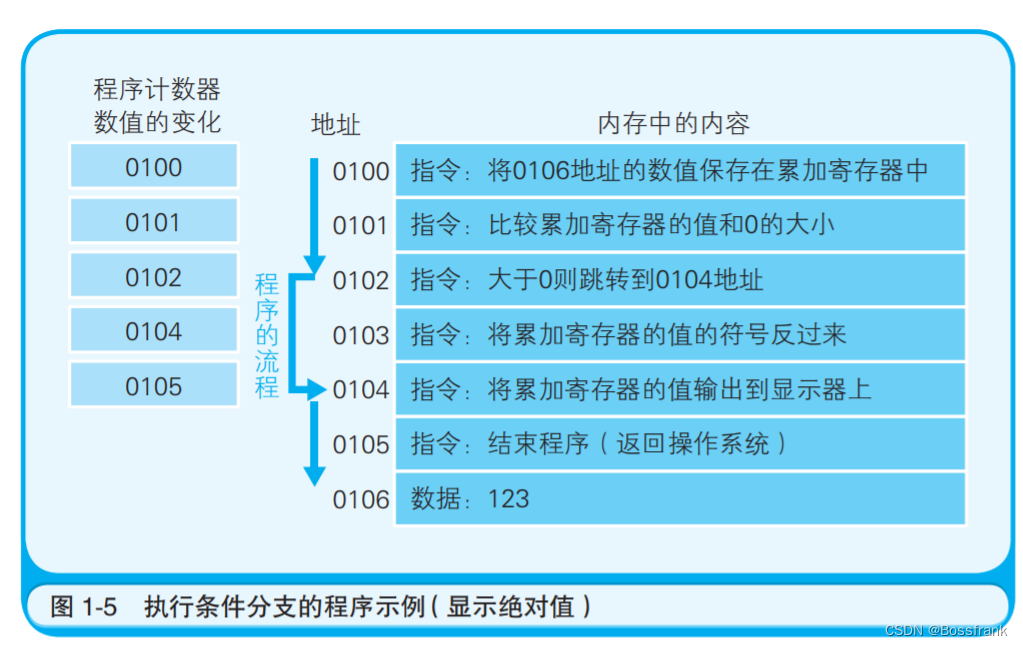
本图表示把内存中存储的数值(示例中是 123)的绝对值输出到显示器的程序的内存状态。程序运行的开始位置是 0100 地址。随着程序计数器数值的增加,当到达 0102 地址时,如果累加寄存器的值是正数,则执行跳转指令(jump 指令)跳转到 0104 地址。此时,由于累加寄存器的值是123,为正数,因此 0103 地址的指令被跳过,程序的流程直接跳转到了 0104 地址。也就是说,“跳转到 0104 地址”这个指令间接执行了“将程序计数器设定成 0104 地址”这个操作。 条件分支在跳转指令前会进行比较运算。至于是否执行跳转指令,则由 CPU 在参考标志寄存器的数值后进行判断。运算结果的正、零、负三种状态由标志寄存器的三个位表示:
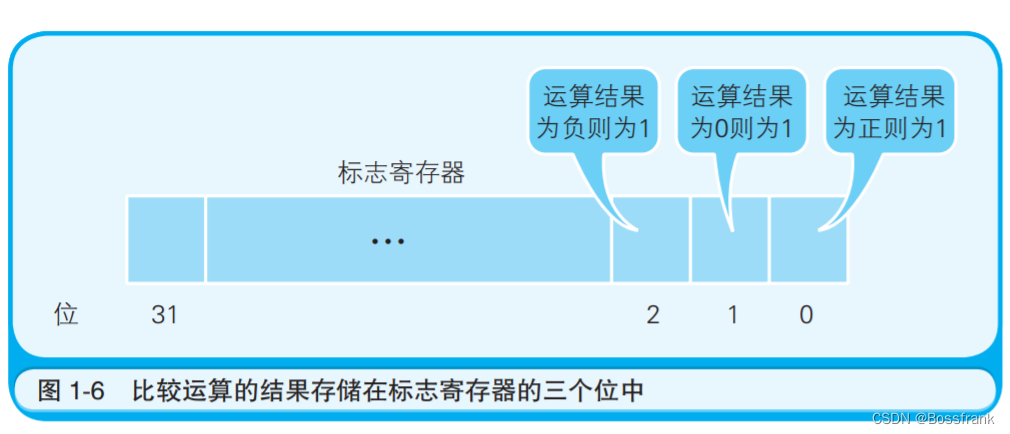
程序中所谓比较大小本质都是做差,将结果的正/负/零保存在标志寄存器中。程序中的比较指令,就是在CPU内部做减法运算。
函数的调用流程
函数的调用流程和条件分支、循环的机制有所不同,因为单纯的跳转指令无法实现函数的调用。函数的调用需要在完成函数内部的处理后,处理流程再返回到函数调用点(函数调用指令的下一个地址)。因此,如果只是跳转到函数的入口地址,处理流程就不知道应该返回至哪里了。 函数的调用包含call和return两个过程,具体描述如下:
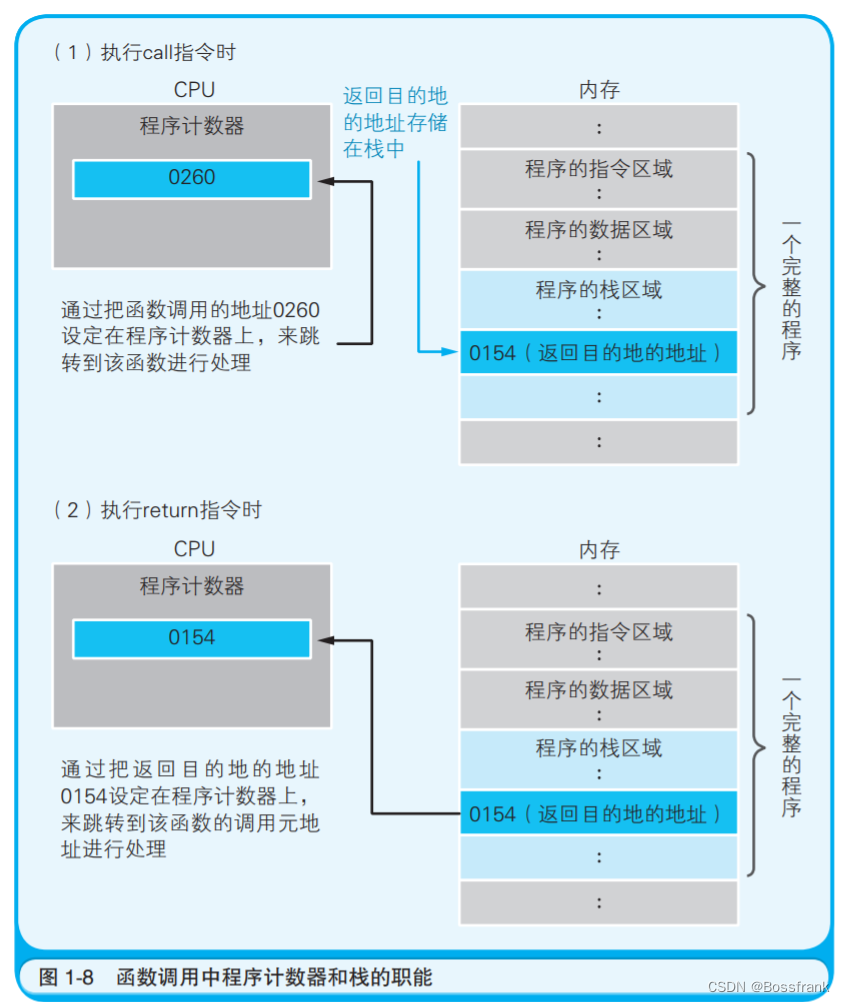
函数调用使用的是call指令,而不是跳转指令。 在将函数的入口地址设定到程序计数器之前,call 指令会把调用函数后要执行的指令地址存储在名为栈的主存内(说白了就是先将返回地址压栈)。函数处理完毕后,再通过函数的出口来执行return命令。return 命令的功能是把保存在栈中的地址设定到程序计数器中。
 MyFunc 函数被调用之前,0154地址保存在栈中。MyFunc 函数的处理完毕后,栈中的0154地址 就会被读取出来,然后再被设定到程序计数器中(图1-8)。在编译高级编程语言的程序后,函数调用的处理会转换成 call 指令,函数结束的处理则会转换成 return 指令。这样一来,程序的运行也 就变得非常流畅。
MyFunc 函数被调用之前,0154地址保存在栈中。MyFunc 函数的处理完毕后,栈中的0154地址 就会被读取出来,然后再被设定到程序计数器中(图1-8)。在编译高级编程语言的程序后,函数调用的处理会转换成 call 指令,函数结束的处理则会转换成 return 指令。这样一来,程序的运行也 就变得非常流畅。
通过地址和索引实现数组
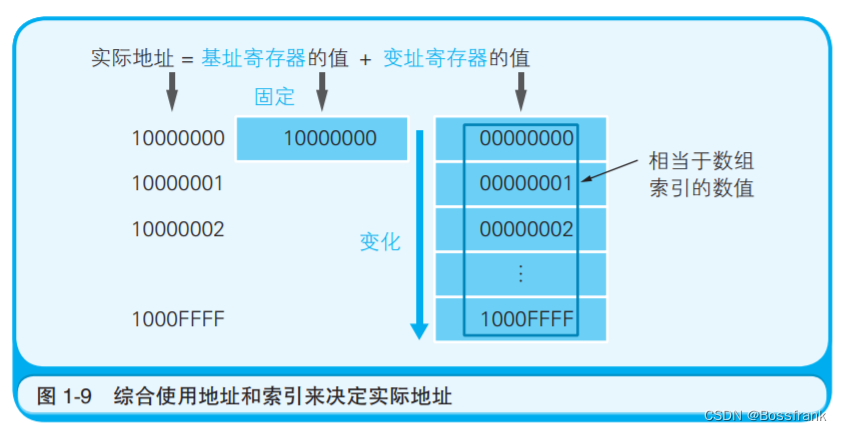
通过基址寄存器和变址寄存器这两个寄存器,我们可以对主内存上特定的内存区域进行划分,从而 实现类似于数组的操作。 变址寄存器的值就相当于高级编程语言 程序中数组的索引功能。如图1-9,一图胜千言。
CPU的处理过程
表 1-2 按照功能对 CPU 能执行的机器语言指令进行了大体分类。这里没有列出指令的具体名称(汇编语言的助记符)。原来 CPU 可以进行的处理非常少。虽然高级编程语言编写的程序看起来非常复杂,但 CPU 实际处理的事情就是这么简单。

结尾
这篇文章就总结到这里吧,后面两章关于二进制和小数运算的内容我可能不会详细总结,回头一笔带过吧。然后可能近期会完成对这本书的读书总结,下一篇可能会重点讲第四章内存相关的知识。
除此之外还会进一步更新红队打靶的解析和渗透测试相关的技术分享,恳请希望读者们多多支持。