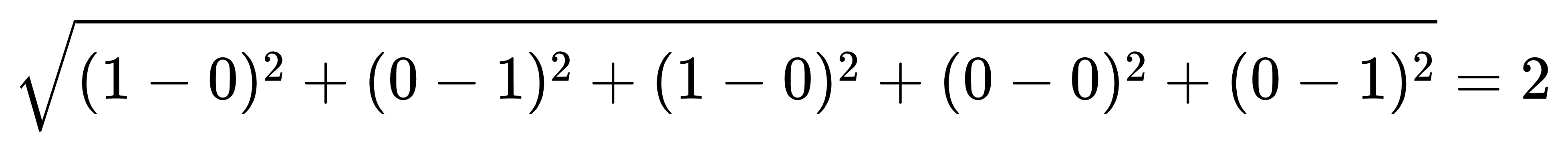今天分享近三年(2021-2023)各大顶会中的视觉Transformer论文,有190+篇,涵盖通用ViT、高效ViT、训练transformer、卷积transformer等细分领域。
全部论文原文及开源代码文末直接领取
General Vision Transformer(通用ViT)
1、GPViT: "GPViT: A High Resolution Non-Hierarchical Vision Transformer with Group Propagation", ICLR, 2023
标题:GPViT: 一种具有组传播的高分辨率非层次结构视觉Transformer
内容:本文提出了一种高效的替代组传播块(GP块)来交换全局信息。在每个GP块中,特征首先由一定数量的可学习组标记分组,然后在组特征间进行组传播以交换全局信息,最后通过一个transformer解码器将更新后的组特征中的全局信息返回到图像特征。作者在各种视觉识别任务上评估了GPViT,包括图像分类、语义分割、目标检测和实例分割。与之前的工作相比,该方法在所有任务上都取得了显著的性能提升,特别是在需要高分辨率输出的任务上,例如在语义分割任务ADE20K上,GPViT-L3的性能比Swin Transformer-B高出2.0 mIoU,而参数数量只有其一半。
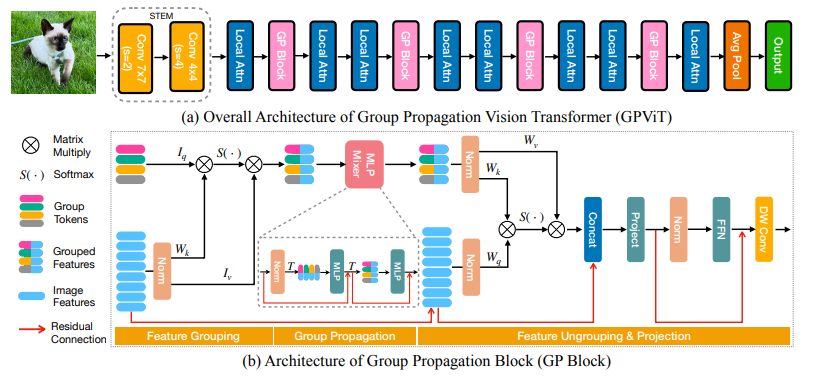
2、CPVT: "Conditional Positional Encodings for Vision Transformers", ICLR, 2023
标题:条件位置编码在视觉transformer中的应用
内容:本文提出了一种针对视觉Transformer的条件位置编码(CPE)方案。与以前预定义且与输入标记无关的固定或可学习位置编码不同,CPE是动态生成的,并取决于输入标记的局部邻域。因此,CPE可以轻松概括到比模型在训练期间见过的更长的输入序列。此外,CPE可以在视觉任务中保持所需的平移等价性,从而提高性能。作者使用一个简单的位置编码生成器(PEG)来实现CPE,并无缝集成到当前的Transformer框架中。基于PEG,作者提出了条件位置编码视觉Transformer(CPVT)。实验证明,CPVT的注意力图与学习到的位置编码非常相似,并取得了优于状态的结果。
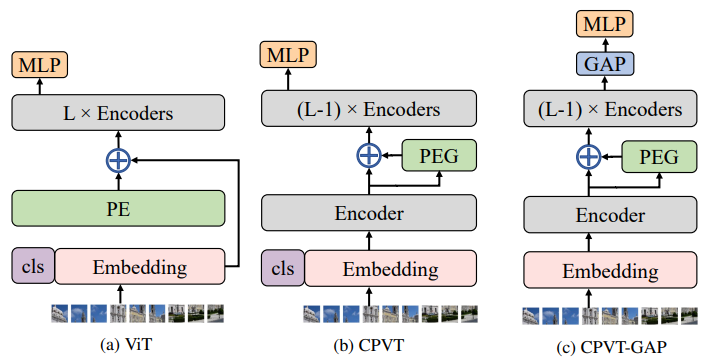
3、LipsFormer: "LipsFormer: Introducing Lipschitz Continuity to Vision Transformers", ICLR, 2023
标题:LipsFormer: 在视觉Transformer中引入Lipschitz连续性
内容:本文提出了一种称为LipsFormer的Lipschitz连续Transformer,在理论和实验上探索了提高基于Transformer的模型训练稳定性的方法。与之前通过学习率预热、层规范化、注意力机制和权重初始化来解决训练不稳定的经验技巧不同,本文认为Lipschitz连续性是确保训练稳定性的更本质的特性。在LipsFormer中,不稳定的Transformer组件模块被Lipschitz连续的对应物替换:LayerNorm被CenterNorm替换,Xavier初始化被谱初始化替换,点积注意力被缩放余弦相似度注意力替换,并引入加权残差连接。作者证明引入的这些模块满足Lipschitz连续性,并导出了LipsFormer的Lipschitz常数上确界。
其他51篇
-
BiFormer: "BiFormer: Vision Transformer with Bi-Level Routing Attention", CVPR, 2023
-
AbSViT: "Top-Down Visual Attention from Analysis by Synthesis", CVPR, 2023
-
DependencyViT: "Visual Dependency Transformers: Dependency Tree Emerges From Reversed Attention", CVPR, 2023
-
ResFormer: "ResFormer: Scaling ViTs with Multi-Resolution Training", CVPR, 2023
-
SViT: "Vision Transformer with Super Token Sampling", CVPR, 2023
-
PaCa-ViT: "PaCa-ViT: Learning Patch-to-Cluster Attention in Vision Transformers", CVPR, 2023
-
GC-ViT: "Global Context Vision Transformers", ICML, 2023
-
MAGNETO: "MAGNETO: A Foundation Transformer", ICML, 2023
-
SMT: "Scale-Aware Modulation Meet Transformer", ICCV, 2023
-
CrossFormer++: "CrossFormer++: A Versatile Vision Transformer Hinging on Cross-scale Attention", arXiv, 2023
-
QFormer: "Vision Transformer with Quadrangle Attention" arXiv, 2023
-
LIT: "Less is More: Pay Less Attention in Vision Transformers", AAAI, 2022
-
DTN: "Dynamic Token Normalization Improves Vision Transformer", ICLR, 2022
-
RegionViT: "RegionViT: Regional-to-Local Attention for Vision Transformers", ICLR, 2022
-
CrossFormer: "CrossFormer: A Versatile Vision Transformer Based on Cross-scale Attention", ICLR, 2022
-
CSWin: "CSWin Transformer: A General Vision Transformer Backbone with Cross-Shaped Windows", CVPR, 2022
-
MPViT: "MPViT: Multi-Path Vision Transformer for Dense Prediction", CVPR, 2022
-
Diverse-ViT: "The Principle of Diversity: Training Stronger Vision Transformers Calls for Reducing All Levels of Redundancy", CVPR, 2022
-
DW-ViT: "Beyond Fixation: Dynamic Window Visual Transformer", CVPR, 2022
-
MixFormer: "MixFormer: Mixing Features across Windows and Dimensions", CVPR, 2022
-
DAT: "Vision Transformer with Deformable Attention", CVPR, 2022
-
Swin-Transformer-V2: "Swin Transformer V2: Scaling Up Capacity and Resolution", CVPR, 2022
-
MSG-Transformer: "MSG-Transformer: Exchanging Local Spatial Information by Manipulating Messenger Tokens", CVPR, 2022
-
NomMer: "NomMer: Nominate Synergistic Context in Vision Transformer for Visual Recognition", CVPR, 2022
-
Shunted: "Shunted Self-Attention via Multi-Scale Token Aggregation", CVPR, 2022
-
PyramidTNT: "PyramidTNT: Improved Transformer-in-Transformer Baselines with Pyramid Architecture", CVPRW, 2022
-
ReMixer: "ReMixer: Object-aware Mixing Layer for Vision Transformers", CVPRW, 2022
-
UN: "Unified Normalization for Accelerating and Stabilizing Transformers", ACMMM, 2022
-
Wave-ViT: "Wave-ViT: Unifying Wavelet and Transformers for Visual Representation Learning", ECCV, 2022
-
DaViT: "DaViT: Dual Attention Vision Transformers", ECCV, 2022
-
MaxViT: "MaxViT: Multi-Axis Vision Transformer", ECCV, 2022
-
VSA: "VSA: Learning Varied-Size Window Attention in Vision Transformers", ECCV, 2022
-
LITv2: "Fast Vision Transformers with HiLo Attention", NeurIPS, 2022
-
ViT:An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale (ICLR 2021
-
Perceiver:Perceiver: General Perception with Iterative Attention(ICML 2021)
-
PiT:Rethinking Spatial Dimensions of Vision Transformers(ICCV 2021)
-
VT:Visual Transformers: Where Do Transformers Really Belong in Vision Models?(ICCV 2021)
-
PVT:Pyramid Vision Transformer: A Versatile Backbone for Dense Prediction without Convolutions(ICCV 2021)
-
iRPE:Rethinking and Improving Relative Position Encoding for Vision Transformer(ICCV 2021)
-
CaiT:Going deeper with Image Transformers(ICCV 2021)
-
Swin-Transformer:Swin Transformer: Hierarchical Vision Transformer using Shifted Windows(ICCV 2021)
-
T2T-ViT:Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet(ICCV 2021)
-
DPT:DPT: Deformable Patch-based Transformer for Visual Recognition(ACMMM 2021)
-
Focal: "Focal Attention for Long-Range Interactions in Vision Transformers", NeurIPS, 2021
-
Twins: "Twins: Revisiting Spatial Attention Design in Vision Transformers", NeurIPS, 2021
-
ARM: "Blending Anti-Aliasing into Vision Transformer", NeurIPS, 2021
-
DVT: "Not All Images are Worth 16x16 Words: Dynamic Vision Transformers with Adaptive Sequence Length", NeurIPS, 2021
-
TNT: "Transformer in Transformer", NeurIPS, 2021
-
ViTAE: "ViTAE: Vision Transformer Advanced by Exploring Intrinsic Inductive Bias", NeurIPS, 2021
-
DeepViT: "DeepViT: Towards Deeper Vision Transformer", arXiv, 2021
-
LV-ViT: "All Tokens Matter: Token Labeling for Training Better Vision Transformers", NeurIPS, 2021
Efficient Vision Transformer(高效VIT)
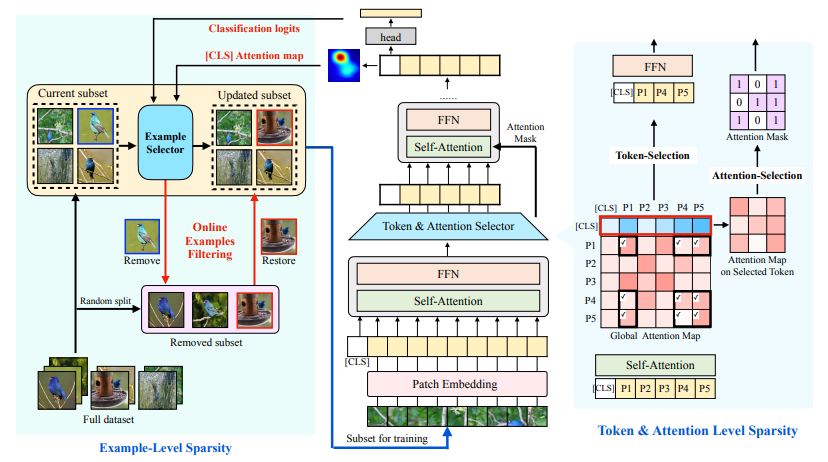
1、Tri-Level: "Peeling the Onion: Hierarchical Reduction of Data Redundancy for Efficient Vision Transformer Training", AAAI, 2023
标题:一层一层剥开洋葱:用于高效视觉Transformer训练的数据冗余分层降低
内容:本文从三个稀疏角度提出了一种端到端高效训练框架,称为Tri-Level E-ViT。具体来说,作者利用分层数据冗余降低方案,通过在三个级别探索稀疏性:数据集中的训练示例数,每个示例中的patch(token)数,以及位于注意力权重中的token间的连接数。通过大量实验,证明了所提出的技术可以显著加速各种ViT架构的训练,同时保持准确率。
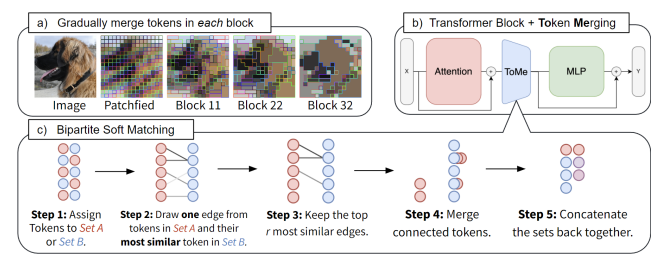
2、ToMe: "Token Merging: Your ViT But Faster", ICLR, 2023
标题:Token融合:你的ViT变得更快
内容:作者提出了Token Merging (ToMe),这是一种简单的方法,可以在不需要训练的情况下增加现有ViT模型的吞吐量。ToMe使用一个通用且轻量级的匹配算法逐步合并transformer中相似的token,其速度与剪枝相当,但更准确。开箱即用,ToMe可以使最先进的ViT-L @ 512和ViT-H @ 518模型在图像上的吞吐量提高2倍,在视频上的ViT-L吞吐量提高2.2倍,其准确率仅下降0.2-0.3%。ToMe也可以轻松地在训练期间应用,在实践中将MAE在视频上的微调速度提高近2倍。 ToMe训练可以进一步最小化准确率下降,在音频上使ViT-B的吞吐量提高2倍,准确率仅下降0.4% mAP。 从定性上看,作者发现ToMe可以将对象部分合并为一个token,甚至可以跨多个视频帧。总体而言,ToMe的准确率和速度在图像、视频和音频方面与最先进的技术相当。
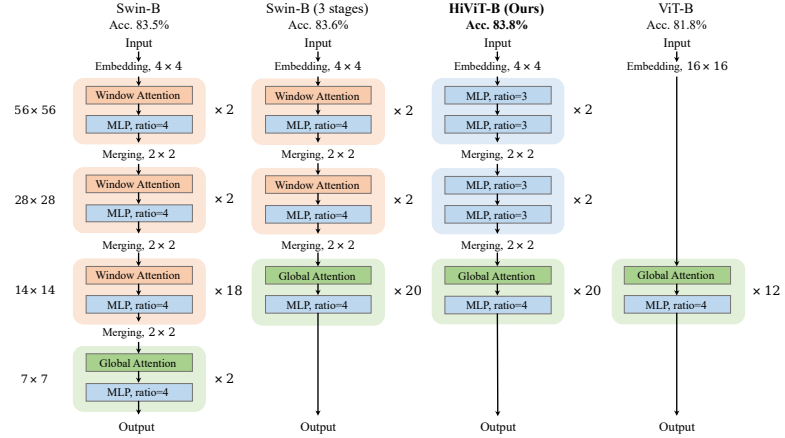
3、HiViT: "HiViT: A Simpler and More Efficient Design of Hierarchical Vision Transformer", ICLR, 2023
标题:HiViT:一种更简单、更高效的分层视觉Transformer设计
内容:在本文中,作者提出了一种新的分层视觉Transformer设计,称为HiViT(Hierarchical ViT的缩写),它在MIM中同时具有高效率和良好性能。 关键是删除不必要的“局部单元间操作”,导出结构简单的分层视觉Transformer,其中掩蔽单元可以像普通视觉Transformer一样串行化。 为此,作者从Swin Transformer开始,(i)将掩蔽单元大小设置为Swin Transformer主阶段的标记大小,(ii)在主阶段之前关闭单元间自注意力,(iii)消除主阶段之后的所有操作。
其他39篇
-
STViT: "Making Vision Transformers Efficient from A Token Sparsification View", CVPR, 2023
-
SparseViT: "SparseViT: Revisiting Activation Sparsity for Efficient High-Resolution Vision Transformer", CVPR, 2023
-
Slide-Transformer: "Slide-Transformer: Hierarchical Vision Transformer with Local Self-Attention", CVPR, 2023
-
RIFormer: "RIFormer: Keep Your Vision Backbone Effective While Removing Token Mixer", CVPR, 2023
-
EfficientViT: "EfficientViT: Memory Efficient Vision Transformer with Cascaded Group Attention", CVPR, 2023
-
Castling-ViT: "Castling-ViT: Compressing Self-Attention via Switching Towards Linear-Angular Attention During Vision Transformer Inference", CVPR, 2023
-
ViT-Ti: "RGB no more: Minimally-decoded JPEG Vision Transformers", CVPR, 2023
-
LTMP: "Learned Thresholds Token Merging and Pruning for Vision Transformers", ICMLW, 2023
-
Evo-ViT: "Evo-ViT: Slow-Fast Token Evolution for Dynamic Vision Transformer", AAAI, 2022
-
PS-Attention: "Pale Transformer: A General Vision Transformer Backbone with Pale-Shaped Attention", AAAI, 2022
-
ShiftViT: "When Shift Operation Meets Vision Transformer: An Extremely Simple Alternative to Attention Mechanism", AAAI, 2022
-
EViT: "Not All Patches are What You Need: Expediting Vision Transformers via Token Reorganizations", ICLR, 2022
-
QuadTree: "QuadTree Attention for Vision Transformers", ICLR, 2022
-
Anti-Oversmoothing: "Anti-Oversmoothing in Deep Vision Transformers via the Fourier Domain Analysis: From Theory to Practice", ICLR, 2022
-
QnA: "Learned Queries for Efficient Local Attention", CVPR, 2022
-
LVT: "Lite Vision Transformer with Enhanced Self-Attention", CVPR, 2022
-
A-ViT: "A-ViT: Adaptive Tokens for Efficient Vision Transformer", CVPR, 2022
-
Rev-MViT: "Reversible Vision Transformers", CVPR, 2022
-
ATS: "Adaptive Token Sampling For Efficient Vision Transformers", ECCV, 2022
-
EdgeViT: "EdgeViTs: Competing Light-weight CNNs on Mobile Devices with Vision Transformers", ECCV,2022
-
SReT: "Sliced Recursive Transformer", ECCV, 2022
-
SiT: "Self-slimmed Vision Transformer", ECCV, 2022
-
M(3)ViT: "M(3)ViT: Mixture-of-Experts Vision Transformer for Efficient Multi-task Learning with Model-Accelerator Co-design", NeurIPS, 2022
-
ResT-V2: "ResT V2: Simpler, Faster and Stronger", NeurIPS, 2022
-
EfficientFormer: "EfficientFormer: Vision Transformers at MobileNet Speed", NeurIPS, 2022
-
GhostNetV2: "GhostNetV2: Enhance Cheap Operation with Long-Range Attention", NeurIPS, 2022
-
DeiT: "Training data-efficient image transformers & distillation through attention", ICML, 2021
-
ConViT: "ConViT: Improving Vision Transformers with Soft Convolutional Inductive Biases", ICML, 2021
-
HVT: "Scalable Visual Transformers with Hierarchical Pooling", ICCV, 2021
-
CrossViT: "CrossViT: Cross-Attention Multi-Scale Vision Transformer for Image Classification", ICCV, 2021
-
ViL: "Multi-Scale Vision Longformer: A New Vision Transformer for High-Resolution Image Encoding", ICCV, 2021
-
Visformer: "Visformer: The Vision-friendly Transformer", ICCV, 2021
-
MultiExitViT: "Multi-Exit Vision Transformer for Dynamic Inference", BMVC, 2021
-
SViTE: "Chasing Sparsity in Vision Transformers: An End-to-End Exploration", NeurIPS, 2021
-
DGE: "Dynamic Grained Encoder for Vision Transformers", NeurIPS, 2021
-
GG-Transformer: "Glance-and-Gaze Vision Transformer", NeurIPS, 2021
-
DynamicViT: "DynamicViT: Efficient Vision Transformers with Dynamic Token Sparsification", NeurIPS, 2021
-
ResT: "ResT: An Efficient Transformer for Visual Recognition", NeurIPS, 2021
-
SOFT: "SOFT: Softmax-free Transformer with Linear Complexity", NeurIPS, 2021
Conv + Transformer(卷积+Transformer)
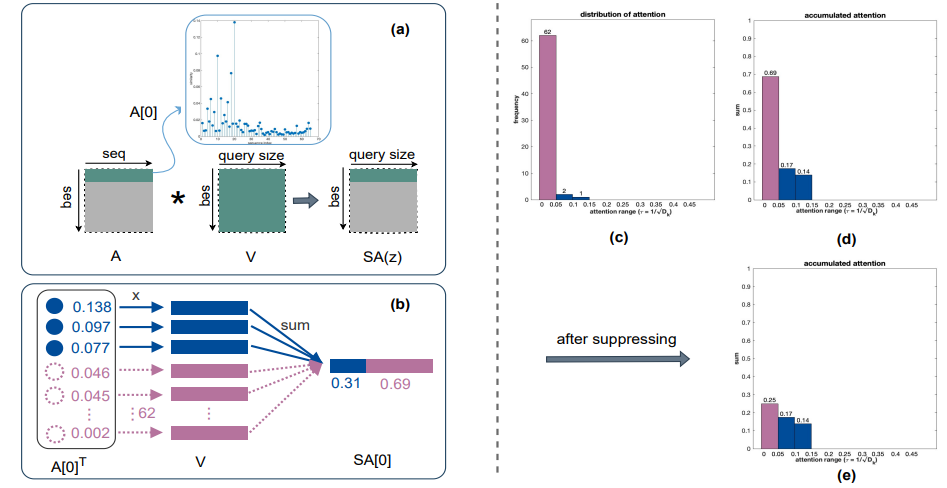
1、SATA: "Accumulated Trivial Attention Matters in Vision Transformers on Small Datasets", WACV, 2023
标题:小数据集上视觉Transformer中的累积微不足道的注意力非常重要
内容:作者提出通过阈值将注意力权重划分为微不足道和非微不足道,然后通过所提出的Trivial WeIghts Suppression Transformation (TWIST)抑制累积的微不足道注意力权重,以减少注意力噪音。在CIFAR-100和Tiny-ImageNet数据集上的大量实验表明,作者的抑制方法将Vision Transformer的准确率提高了高达2.3%。
2、SparK: "Sparse and Hierarchical Masked Modeling for Convolutional Representation Learning", ICLR, 2023
标题:卷积表示学习的稀疏分层遮挡建模
内容:作者识别并克服了将BERT风格的预训练或遮蔽图像建模扩展到卷积网络(convnets)的两个关键障碍:(i) 卷积操作无法处理不规则的、随机遮蔽的输入图像,(ii) BERT预训练的单尺度性质与convnet的层次结构不一致。 对于(i),作者将未遮蔽的像素视为3D点云的稀疏voxel,并使用稀疏卷积进行编码。 这是2D遮蔽建模中首次使用稀疏卷积。 对于(ii),作者开发了一个分层解码器,用于从多尺度编码特征重构图像。 该方法称为稀疏遮蔽建模(SparK),它是通用的:可以直接用于任何卷积模型,无需backbone修改。
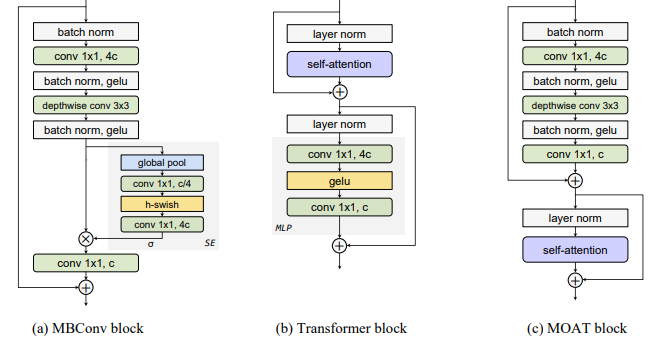
3、MOAT: "MOAT: Alternating Mobile Convolution and Attention Brings Strong Vision Models", ICLR, 2023
标题:MOAT: 交替移动卷积和注意力产生强大的视觉模型
内容:本文提出了MOAT,这是一类建立在移动卷积(即逆残差块)和注意力机制之上的神经网络。与当前将移动卷积块和transformer块分开堆叠的工作不同,作者有效地将它们合并成一个MOAT块。从一个标准的Transformer块开始,用移动卷积块替换其多层感知机,并进一步在自注意力操作之前对其进行重排序。移动卷积块不仅增强了网络的表示能力,还产生了更好的下采样特征。概念简单的MOAT网络出人意料地有效,在ImageNet-1K上取得了89.1%的top-1准确率,在ImageNet-1K-V2上取得了81.5%的top-1准确率,均使用了ImageNet22K预训练。
其他14篇
-
InternImage: "InternImage: Exploring Large-Scale Vision Foundation Models with Deformable Convolutions", CVPR, 2023
-
PSLT: "PSLT: A Light-weight Vision Transformer with Ladder Self-Attention and Progressive Shift", TPAMI, 2023
-
MobileViT: "MobileViT: Light-weight, General-purpose, and Mobile-friendly Vision Transformer", ICLR, 2022
-
Mobile-Former: "Mobile-Former: Bridging MobileNet and Transformer", CVPR, 2022
-
TinyViT: "TinyViT: Fast Pretraining Distillation for Small Vision Transformers", ECCV, 2022
-
ParC-Net: "ParC-Net: Position Aware Circular Convolution with Merits from ConvNets and Transformer", ECCV, 2022
-
?: "How to Train Vision Transformer on Small-scale Datasets?", BMVC, 2022
-
DHVT: "Bridging the Gap Between Vision Transformers and Convolutional Neural Networks on Small Datasets", NeurIPS, 2022
-
iFormer: "Inception Transformer", NeurIPS, 2022
-
LeViT: "LeViT: a Vision Transformer in ConvNet's Clothing for Faster Inference", ICCV, 2021
-
CeiT: "Incorporating Convolution Designs into Visual Transformers", ICCV, 2021
-
Conformer: "Conformer: Local Features Coupling Global Representations for Visual Recognition", ICCV, 2021
-
CoaT: "Co-Scale Conv-Attentional Image Transformers", ICCV, 2021
-
CvT: "CvT: Introducing Convolutions to Vision Transformers", ICCV, 2021
Training + Transformer(训练+Transformer)
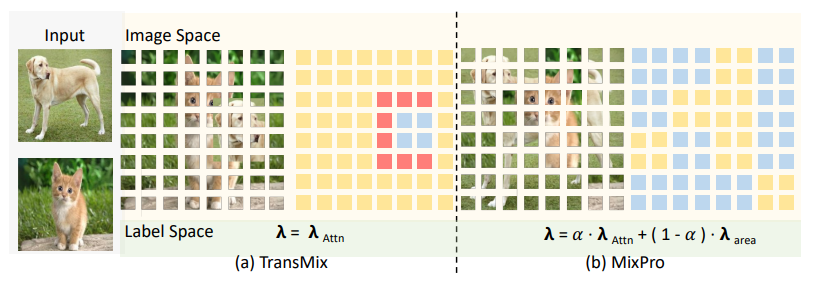
1、MixPro: "MixPro: Data Augmentation with MaskMix and Progressive Attention Labeling for Vision Transformer", ICLR, 2023
标题:MixPro: 使用MaskMix和渐进式注意力标记的数据增强,用于视觉Transformer
内容:作者分别在图像空间和标签空间中提出了MaskMix和渐进式注意力标记(PAL)。具体来说,从图像空间的角度来看,作者设计了MaskMix,它根据网格状遮罩混合两张图像。每个遮罩补丁的大小是可调的,并且是图像补丁大小的整数倍,这确保每个图像补丁只来自一张图像并包含更多的全局内容。从标签空间的角度来看,作者设计了PAL,它利用渐进因子动态重新加权混合注意力标签的注意力权重。最后,作者将MaskMix和渐进式注意力标记组合起来,作为新的数据增强方法,命名为MixPro。
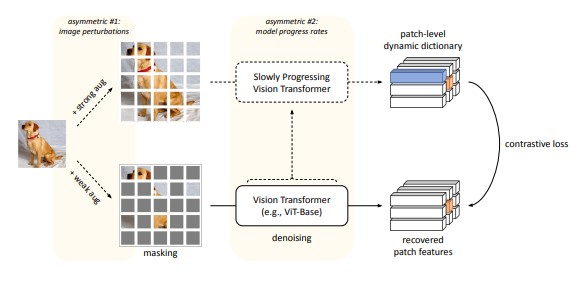
2、ConMIM: "Masked Image Modeling with Denoising Contrast", ICLR, 2023
标题:Masked Image Modeling with Denoising Contrast
内容:MIM最近在视觉Transformers(ViTs)上取得了state-of-the-art的表现,其核心是通过去噪自动编码机制增强网络对图像块级上下文的建模能力。与之前的工作不同,作者没有额外增加图像标记器的训练阶段,而是发掘了对比学习在去噪自动编码上的巨大潜力,并提出了一种纯MIM方法ConMIM,它产生简单的图像内部块间对比约束作为遮挡补丁预测的唯一学习目标。作者进一步通过非对称设计增强了去噪机制,包括图像扰动和模型进度率,以改进网络预训练。
3、MFM: "Masked Frequency Modeling for Self-Supervised Visual Pre-Training", ICLR, 2023
标题:基于遮挡的频域建模用于自监督视觉预训练
内容:作者提出了遮挡频率建模(MFM),这是一种基于频域的统一方法,用于视觉模型的自监督预训练。它与在空间域中随机插入遮挡令牌到输入嵌入不同,MFM从频域的角度出发。具体来说,MFM首先遮挡输入图像的一部分频率分量,然后在频谱上预测缺失的频率。作者的关键洞见是,在频域中预测遮挡的组件比在空间域中预测遮挡的补丁更适合揭示潜在的图像模式,因为存在大量的空间冗余。该发现表明,在遮挡预测策略的正确配置下,高频分量中的结构信息和低频分量中的低级统计信息对于学习良好的表示都很有用。
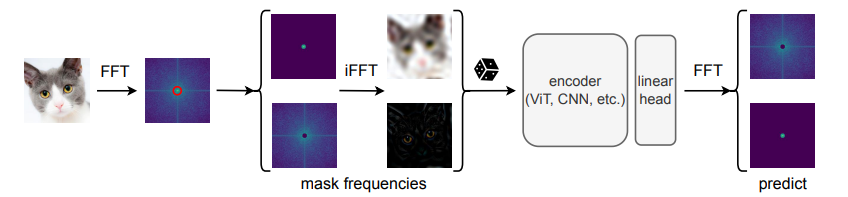
其他46篇
-
VisualAtom: "Visual Atoms: Pre-training Vision Transformers with Sinusoidal Waves", CVPR, 2023
-
LGSimCLR: "Learning Visual Representations via Language-Guided Sampling", CVPR, 2023
-
DisCo-CLIP: "DisCo-CLIP: A Distributed Contrastive Loss for Memory Efficient CLIP Training", CVPR, 2023
-
MaskCLIP: "MaskCLIP: Masked Self-Distillation Advances Contrastive Language-Image Pretraining", CVPR, 2023
-
MAGE: "MAGE: MAsked Generative Encoder to Unify Representation Learning and Image Synthesis", CVPR, 2023 (Google).
-
MixMIM: "MixMIM: Mixed and Masked Image Modeling for Efficient Visual Representation Learning", CVPR, 2023
-
iTPN: "Integrally Pre-Trained Transformer Pyramid Networks", CVPR, 2023
-
DropKey: "DropKey for Vision Transformer", CVPR, 2023
-
FlexiViT: "FlexiViT: One Model for All Patch Sizes", CVPR, 2023
-
CLIPPO: "CLIPPO: Image-and-Language Understanding from Pixels Only", CVPR, 2023
-
DMAE: "Masked Autoencoders Enable Efficient Knowledge Distillers", CVPR, 2023
-
HPM: "Hard Patches Mining for Masked Image Modeling", CVPR, 2023
-
MaskAlign: "Stare at What You See: Masked Image Modeling without Reconstruction", CVPR, 2023
-
RILS: "RILS: Masked Visual Reconstruction in Language Semantic Space", CVPR, 2023
-
FDT: "Revisiting Multimodal Representation in Contrastive Learning: From Patch and Token Embeddings to Finite Discrete Tokens", CVPR, 2023
-
OpenCLIP: "Reproducible scaling laws for contrastive language-image learning", CVPR, 2023
-
DiHT: "Filtering, Distillation, and Hard Negatives for Vision-Language Pre-Training", CVPR, 2023
-
M3I-Pretraining: "Towards All-in-one Pre-training via Maximizing Multi-modal Mutual Information", CVPR, 2023
-
SN-Net: "Stitchable Neural Networks", CVPR, 2023
-
MAE-Lite: "A Closer Look at Self-supervised Lightweight Vision Transformers", ICML, 2023
-
GHN-3: "Can We Scale Transformers to Predict Parameters of Diverse ImageNet Models?", ICML, 2023
-
A(2)MIM: "Architecture-Agnostic Masked Image Modeling - From ViT back to CNN", ICML, 2023
-
PQCL: "Patch-level Contrastive Learning via Positional Query for Visual Pre-training", ICML, 2023
-
DreamTeacher: "DreamTeacher: Pretraining Image Backbones with Deep Generative Models", ICCV, 2023
-
BEiT: "BEiT: BERT Pre-Training of Image Transformers", ICLR, 2022
-
iBOT: "Image BERT Pre-training with Online Tokenizer", ICLR, 2022
-
AutoProg: "Automated Progressive Learning for Efficient Training of Vision Transformers", CVPR, 2022
-
MAE: "Masked Autoencoders Are Scalable Vision Learners", CVPR, 2022
-
SimMIM: "SimMIM: A Simple Framework for Masked Image Modeling", CVPR, 2022
-
SelfPatch: "Patch-Level Representation Learning for Self-Supervised Vision Transformers", CVPR, 2022
-
Bootstrapping-ViTs: "Bootstrapping ViTs: Towards Liberating Vision Transformers from Pre-training", CVPR, 2022
-
TransMix: "TransMix: Attend to Mix for Vision Transformers", CVPR, 2022
-
data2vec: "data2vec: A General Framework for Self-supervised Learning in Speech, Vision and Language", ICML, 2022
-
SSTA: "Self-supervised Models are Good Teaching Assistants for Vision Transformers", ICML, 2022
-
MP3: "Position Prediction as an Effective Pretraining Strategy", ICML, 2022
-
CutMixSL: "Visual Transformer Meets CutMix for Improved Accuracy, Communication Efficiency, and Data Privacy in Split Learning", IJCAI, 2022
-
BootMAE: "Bootstrapped Masked Autoencoders for Vision BERT Pretraining", ECCV, 2022
-
TokenMix: "TokenMix: Rethinking Image Mixing for Data Augmentation in Vision Transformers", ECCV, 2022
-
?: "Locality Guidance for Improving Vision Transformers on Tiny Datasets", ECCV, 2022
-
HAT: "Improving Vision Transformers by Revisiting High-frequency Components", ECCV, 2022
-
AttMask: "What to Hide from Your Students: Attention-Guided Masked Image Modeling", ECCV, 2022
-
SLIP: "SLIP: Self-supervision meets Language-Image Pre-training", ECCV, 2022
-
mc-BEiT: "mc-BEiT: Multi-Choice Discretization for Image BERT Pre-training", ECCV, 2022
-
SL2O: "Scalable Learning to Optimize: A Learned Optimizer Can Train Big Models", ECCV, 2022
-
TokenMixup: "TokenMixup: Efficient Attention-guided Token-level Data Augmentation for Transformers", NeurIPS, 2022
-
GreenMIM: "Green Hierarchical Vision Transformer for Masked Image Modeling", NeurIPS, 2022
Robustness + Transformer(鲁棒性+Transformer)16篇
-
RobustCNN: "Can CNNs Be More Robust Than Transformers?", ICLR, 2023
-
DMAE: "Denoising Masked AutoEncoders are Certifiable Robust Vision Learners", ICLR, 2023
-
TGR: "Transferable Adversarial Attacks on Vision Transformers with Token Gradient Regularization", CVPR, 2023
-
?: "Vision Transformers are Robust Learners", AAAI, 2022
-
PNA: "Towards Transferable Adversarial Attacks on Vision Transformers", AAAI, 2022
-
MIA-Former: "MIA-Former: Efficient and Robust Vision Transformers via Multi-grained Input-Adaptation", AAAI, 2022
-
Patch-Fool: "Patch-Fool: Are Vision Transformers Always Robust Against Adversarial Perturbations?", ICLR, 2022
-
Smooth-ViT: "Certified Patch Robustness via Smoothed Vision Transformers", CVPR, 2022
-
RVT: "Towards Robust Vision Transformer", CVPR, 2022
-
VARS: "Visual Attention Emerges from Recurrent Sparse Reconstruction", ICML, 2022
-
FAN: "Understanding The Robustness in Vision Transformers", ICML, 2022
-
CFA: "Robustifying Vision Transformer without Retraining from Scratch by Test-Time Class-Conditional Feature Alignment", IJCAI, 2022
-
?: "Understanding Adversarial Robustness of Vision Transformers via Cauchy Problem", ECML-PKDD, 2022
-
ViP: "ViP: Unified Certified Detection and Recovery for Patch Attack with Vision Transformers", ECCV, 2022
-
?: "When Adversarial Training Meets Vision Transformers: Recipes from Training to Architecture", NeurIPS, 2022
-
RobustViT: "Optimizing Relevance Maps of Vision Transformers Improves Robustness", NeurIPS, 2022
Model Compression + Transformer(模型压缩 + Transformer)12篇
-
TPS: "Joint Token Pruning and Squeezing Towards More Aggressive Compression of Vision Transformers", CVPR, 2023
-
BinaryViT: "BinaryViT: Pushing Binary Vision Transformers Towards Convolutional Models", CVPRW, 2023
-
OFQ: "Oscillation-free Quantization for Low-bit Vision Transformers", ICML, 2023
-
UPop: "UPop: Unified and Progressive Pruning for Compressing Vision-Language Transformers", ICML, 2023
-
COMCAT: "COMCAT: Towards Efficient Compression and Customization of Attention-Based Vision Models", ICML, 2023
-
UVC: "Unified Visual Transformer Compression", ICLR, 2022
-
MiniViT: "MiniViT: Compressing Vision Transformers with Weight Multiplexing", CVPR, 2022
-
SPViT: "SPViT: Enabling Faster Vision Transformers via Soft Token Pruning", ECCV, 2022
-
PSAQ-ViT: "Patch Similarity Aware Data-Free Quantization for Vision Transformers", ECCV, 2022
-
Q-ViT: "Q-ViT: Accurate and Fully Quantized Low-bit Vision Transformer", NeurIPS, 2022
-
VTC-LFC: "VTC-LFC: Vision Transformer Compression with Low-Frequency Components", NeurIPS, 2022
-
PSAQ-ViT-V2: "PSAQ-ViT V2: Towards Accurate and General Data-Free Quantization for Vision Transformers", arXiv, 2022
关注下方《学姐带你玩AI》🚀🚀🚀
回复“ViT200”获取全部论文+代码合集
码字不易,欢迎大家点赞评论收藏!