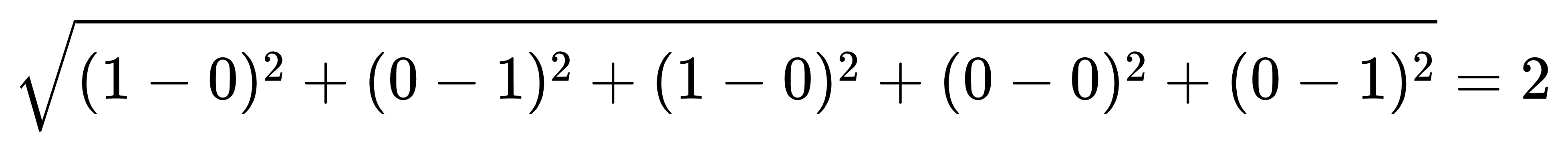机器学习入门教学——标签编码、序号编码、独热编码
1、前言
在机器学习过程中,我们经常需要对特征进行分类,例如:性别有男、女,国籍有中国、英国、美国等,种族有黄、白、黑。 但是分类器并不能直接对字符型数据进行分类,所以我们需要先对数据进行处理。 如果要将其作为机器学习算法的输入,通常我们需要对特征进行数字化处理,常用的方法有:标签编码、独热编码等。 2、标签编码
标签编码(Label Encoding)是把分类类型数据转换为数值编码的一种方法,即直接对类别特征进行了大量映射,每个分类都被赋予唯一的数字编号。 【注】标签编码后的数据并没有大小关系,只是数字替代类别标签。 假设特征取值有n个不同值,即n个类别,那么将按照特征数据的大小将其编码成0~(n-1)之间的整数。 例如:
性别:["男", "女"] => 0, 1 国籍:["中国", "英国", "美国"] => 0, 1, 2 种族:["黄", "白", "黑"] => 0, 1, 2 此时,某个样本的特征为["女", "美国", "白"],就可以用[1, 2, 1]来表示。 当标签过多时,编码会变得很大并使得计算机难以处理,同时,标签编码不能反映分类之间的关系。可以进一步采用独热编码使其转化成有序且连续的数据。 3、序号编码
序号编码(Ordinal Encoding)是一种对分类特征进行编码的方法,它会考虑类别之间的顺序和大小关系,并将其映射到数字中。 例如:
学历:["专科","本科", "硕士", "博士"] => 1, 2, 3, 4 成绩:["D","C", "B", "A"] => 1, 2, 3, 4 可以看到,序号编码保留了类别的顺序信息,专科<本科<硕士<博士,D<C<B<A。 序号编码适用于有明显顺序关系的分类特征,它通过映射序号保留了类别顺序信息。但也需要注意合理设置顺序,否则可能会引入偏差。 2、独热编码
2.1、简介
独热编码(One-Hot Encoding),又称一位有效编码,其方法是使用N位状态寄存器来对N个状态进行编码,每个状态都有它独立的寄存器位,并且在任意时候,其中只有一位有效。即只有一位是1,其余都是零值。 独热编码是利用0和1来表示一些参数,使用N位状态寄存器来对N个状态进行编码。 例如:
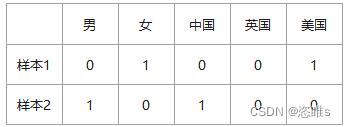
性别:["男", "女"]
国籍:["中国", "英国", "美国"]
中国 => 100 英国 => 010 美国 => 001 种族:["黄", "白", "黑"]
此时,某个样本的特征为["女", "美国", "白"],转换的结果就为:[0, 1, 0, 0, 1, 0, 1, 0] 也就是说,将所有的特征排列在一起,有该特征即为1,没有该特征即为0。 2.2、作用
One-hot编码是用于编码分类变量的技术,可以用于神经网络。对数据进行预处理去偏时,通常要确定2个相似个体特定特征之间的度量距离,One-hot编码能更加合理的计算特征之间的距离,从而达到去偏的效果。 也就是把特征之间距离的问题,转换为了计算向量之间距离的问题。 例如:
性别:["男", "女"]
国籍:["中国", "英国", "美国"]
中国 => 100 英国 => 010 美国 => 001 计算样本1:["女", "美国"]=[0, 1, 0, 0, 1],样本2:["男", "中国"]=[1, 0, 1, 0, 0]之间的距离。 距离=
本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1000213.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!