1 Elasticsearch 与 Lucene 的结构理解
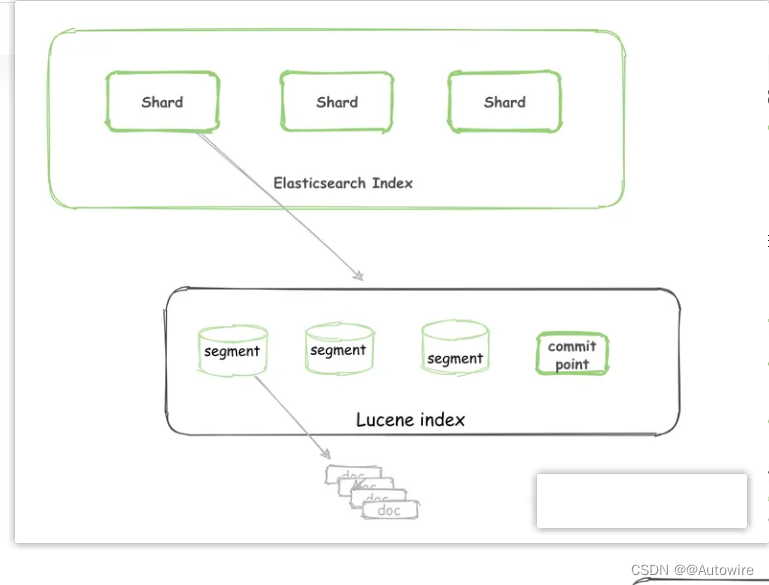
一个Elasticsearch索引由一个或多个分片(shards)组成。这些分片可以是主分片(primary shard)或副本分片(replica shard)。每个分片都是一个独立的Lucene索引,保存了索引数据的一部分。
主分片承载了索引数据的主要部分,而副本分片则是主分片的副本,用于提高搜索和数据存储的可靠性。当主分片发生故障时,副本分片可以充当主分片,保证索引的可用性。
在默认情况下,一个Elasticsearch索引有5个主分片和1个副本分片。但是,这些设置可以根据需求进行修改。在创建索引时,可以指定主分片的数量和副本分片的数量。
当查询一个Elasticsearch索引时,查询请求会被分发到所有分片上执行,然后将各个分片的结果合并得到最终结果。这种分布式架构可以大大提高查询的效率和处理大规模数据的性能。
是的,Lucene中的Lucene索引相当于Elasticsearch中的一个分片(shard)。
Lucene是一个高性能、纯Java编写的全文检索引擎,而Elasticsearch是基于Lucene构建的分布式搜索和分析引擎。在Lucene中,索引是由多个分段(segment)组成的,每个分段都是一个独立的数据集,保存了文档的倒排索引等信息。
在Elasticsearch中,索引是由多个分片(shard)组成的,每个分片都可以在多个节点上分布存储和搜索。每个分片内部实际上使用了Lucene索引的原理,即Lucene index: “a collection of segments plus a commit point”。由一堆 Segment 的集合加上一个提交点组成。因此,可以说Lucene中的Lucene索引相当于Elasticsearch中的一个分片。
需要注意的是,虽然每个Lucene索引和每个Elasticsearch分片在内部结构上相似,但它们在实际使用和管理上存在一定的差异。例如,Elasticsearch的分片可以在不同的节点上动态平衡和调整,以满足系统的负载需求和高可用性要求。
2 ES的写入过程
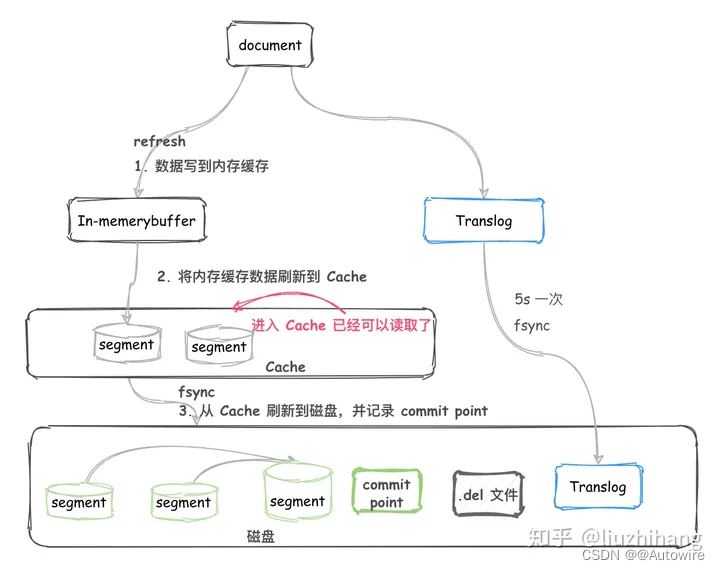
首先,当我们对记录进行修改时,es会把数据同时写到内存缓存区和translog中。而这个时候数据是不能被搜索到的,只有数据形成了segmentFile,才会被搜索到。默认情况下,es每隔一秒钟执行一次refresh,可以通过参数index.refresh_interval来修改这个刷新间隔。
- 不断将 Document 写入到 In-memory buffer (内存缓冲区)。
- 当满足一定条件后内存缓冲区中的 Documents 刷新到 高速缓存(cache)。
- 生成新的 segment ,这个 segment 还在 cache 中。
- 这时候还没有 commit ,但是已经可以被读取了。
数据从 buffer 到 cache 的过程是定期每秒刷新一次。所以新写入的 Document 最慢 1 秒就可以在 cache 中被搜索到。
而 Document 从 buffer 到 cache 的过程叫做 ?refresh 。一般是 1 秒刷新一次,不需要进行额外修改。当然,如果有修改的需要,可以参考文末的相关资料。这也就是为什么说 Elasticsearch 是准实时的。
PUT /test/_doc/1?refresh
{"test": "test"}
// 或者
PUT /test/_doc/2?refresh=true
{"test": "test"}
translog的相当于事务日志,记录着所有对Elasticsearch的操作记录,也是对Elasticsearch的一种备份。因为并不是写到segment就表示数据落到磁盘了,实际上segment是存储在系统缓存(page cache)中的,只有达到一个周期或者数据量达到一定值,才会flush到磁盘上。这个时候如果系统内存中的segment丢失,是可以通过translog来恢复的。
- Document 不断写入到 In-memory buffer,此时也会追加 translog。
- 当 buffer 中的数据每秒 refresh 到 cache 中时,translog 并没有进入到刷新到磁盘,是持续追加的。
- translog 每隔 5s 会 fsync 到磁盘。
- translog 会继续累加变得越来越大,当 translog 大到一定程度或者每隔一段时间,会执行 flush。
flush 操作会分为以下几步执行:
- buffer 被清空。
- 记录 commit point。
- cache 内的 segment 被 fsync 刷新到磁盘。
- translog 被删除。
值得注意的是:
- translog 每 5s 刷新一次磁盘,所以故障重启,可能会丢失 5s 的数据。
- translog 执行 flush 操作,默认 30 分钟一次,或者 translog 太大 也会执行。

![buuctf crypto 【[HDCTF2019]basic rsa】解题记录](https://img-blog.csdnimg.cn/807a32ec2dff4e57a20617a7702cf0e8.png)