一 准备
1.启动集群 /hive/mysql
start-all.sh
2.启动spark-shell
spark-shell \
--master yarn \
//--packages org.apache.hudi:hudi-spark3.1-bundle_2.12:0.12.2 \
--jars /opt/software/hudi-spark3.1-bundle_2.12-0.12.0.jar \
--conf 'spark.serializer=org.apache.spark.serializer.KryoSerializer' \
--conf 'spark.sql.extensions=org.apache.spark.sql.hudi.HoodieSparkSessionExtension'3.导入依赖包
import org.apache.hudi.DataSourceWriteOptions._
import org.apache.hudi.config.HoodieWriteConfig._
import org.apache.spark.sql.functions._
import org.apache.spark.sql.{SaveMode, SparkSession}
val tableName="demotable"
val hudiBasePath="hdfs://bigdata1:9000//user/hudi/hudi_ods.db/" + tableName二 查询mysql数据
val DB_URL="jdbc:mysql://bigdata1:3306/ds_db01?allowPublicKeyRetrieval=true&serverTimezone=UTC&useSSL=false"连接mysql
val df21 = spark.read.format("jdbc")
.option("driver", "com.mysql.jdbc.Driver") // mysql驱动程序类名
.option("url", DB_URL) // 连接url
.option("dbtable", "customer_inf") // 要读取的表
.option("user", "root") // 连接账户,需修改为自己的
.option("password","123456") // 连接密码,需修改为自己的
.option("fetchsize","50") // 每轮读取多少行
.load()
-------------------- 转换Transform-增加静态分区列 ------------- import spark.implicits._
查询
println(df21.count()) df21.show(10)

三 追加写入Hudi
val df22 = df21.withColumn("etl_date",lit("20220816"))
// val df22 = df21.withColumn("etl_date",date_format(date_sub(current_date(),1),"yyyyMMdd"))
val dfWithTs = df22.withColumn("ts", current_timestamp())
dfWithTs.write.format("hudi")
.mode(SaveMode.Overwrite)
.option("hoodie.insert.shuffle.parallelism","2")//操作并行度为2
.option("hoodie.upsert.shuffle.parallelism","2")
.option(RECORDKEY_FIELD.key(), "customer_inf_id")//记录键的字段名,作为hudi的主键
.option(PARTITIONPATH_FIELD.key(), "etl_date")
.option(TBL_NAME.key(), tableName)
.save(hudiBasePath)
.option(PRECOMBINE_FIELD.key(), "InPutTime")//预聚合字段名
.option("hoodie.timestamp.field","modified_time")
.option("hoodie.timestamp.field","birthday")
.option("hoodie.timestamp.field","etl_date")
.option("hoodie.timestamp.field","register_time")查询
val env_data_df=spark.read.format("org.apache.hudi").load(hudiBasePath)
println(env_data_df.count())
env_data_df.show()

四 外接Hive
val sql_create_table =
s"""
|create table hudi_demo.demotable(
|customer_inf_id int,
| customer_id int,
| customer_name string ,
| identity_card_type tinyint ,
| identity_card_no string,
| mobile_phone string,
| customer_email string ,
| gender string ,
| customer_point int,
| register_time timestamp ,
| birthday date ,
| customer_level tinyint ,
| customer_money decimal,
| modified_time string,
| ts timestamp,
| etl_date string
|)
|using hudi
|tblproperties(
| primaryKey = 'customer_inf_id',
| type = 'cow'
|)
| options (
| hoodie.metadata.enable = 'true'
| )
|partitioned by (etl_date)
|location '$hudiBasePath'
|""".stripMargin
spark.sql(sql_create_table)查询分区
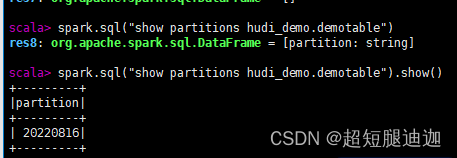
hive查询
FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.hudi.hadoop.HoodieParquetInputFormat
87308 [a3eed69d-1888-48fb-82f7-7254909d770f main] ERROR org.apache.hadoop.hive.ql.Driver - FAILED: RuntimeException java.lang.ClassNotFoundException: org.apache.hudi.hadoop.HoodieParquetInputFormat
报错Hudi集成Hive时的异常解决方法 java.lang.ClassNotFoundException: org.apache.hudi.hadoop.HoodieParquetInputFormat_田昕峣 Richard的博客-CSDN博客
原因
缺少相应的jar包org.apache.hudi.hadoop.HoodieParquetInputFormat
查看hudi的pom文件发现hive版本为2.3.1
重新编译构建